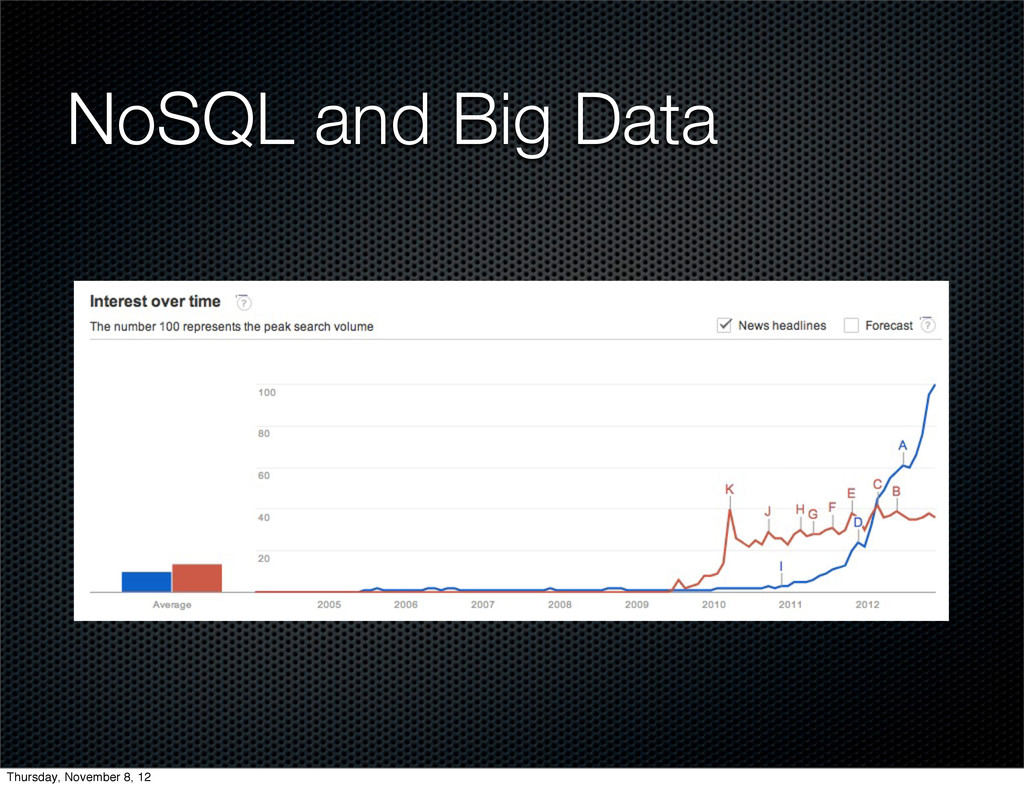
October 2012 marks the five year anniversary of Amazon's seminal Dynamo paper, which inspired most of the NoSQL databases that appeared shortly after its publication, including Riak. This talk reflects on five years of involvement with Riak and distributed databases and discuss what went right, what went wrong, and what the next five years may hold for Riak as we outgrow our Dynamo roots.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}