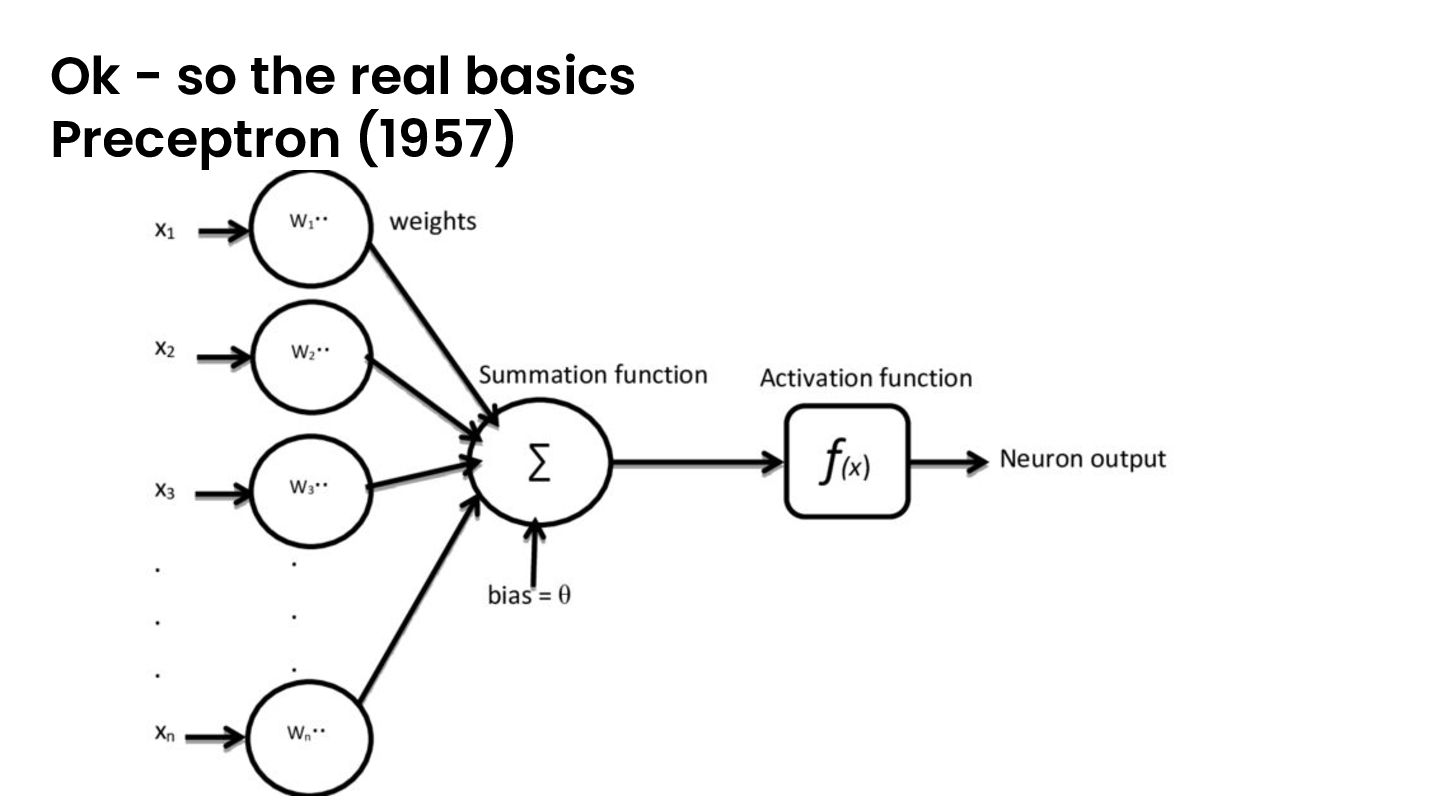
head number, and 𝑓 is some function like RELU or whatever and the 𝐛s are biases (𝑀 is the attention mask and 𝑑 𝐸is the size of the embedding). the output of layer 𝑙∈1...𝐋, 𝐗𝐥 is ,
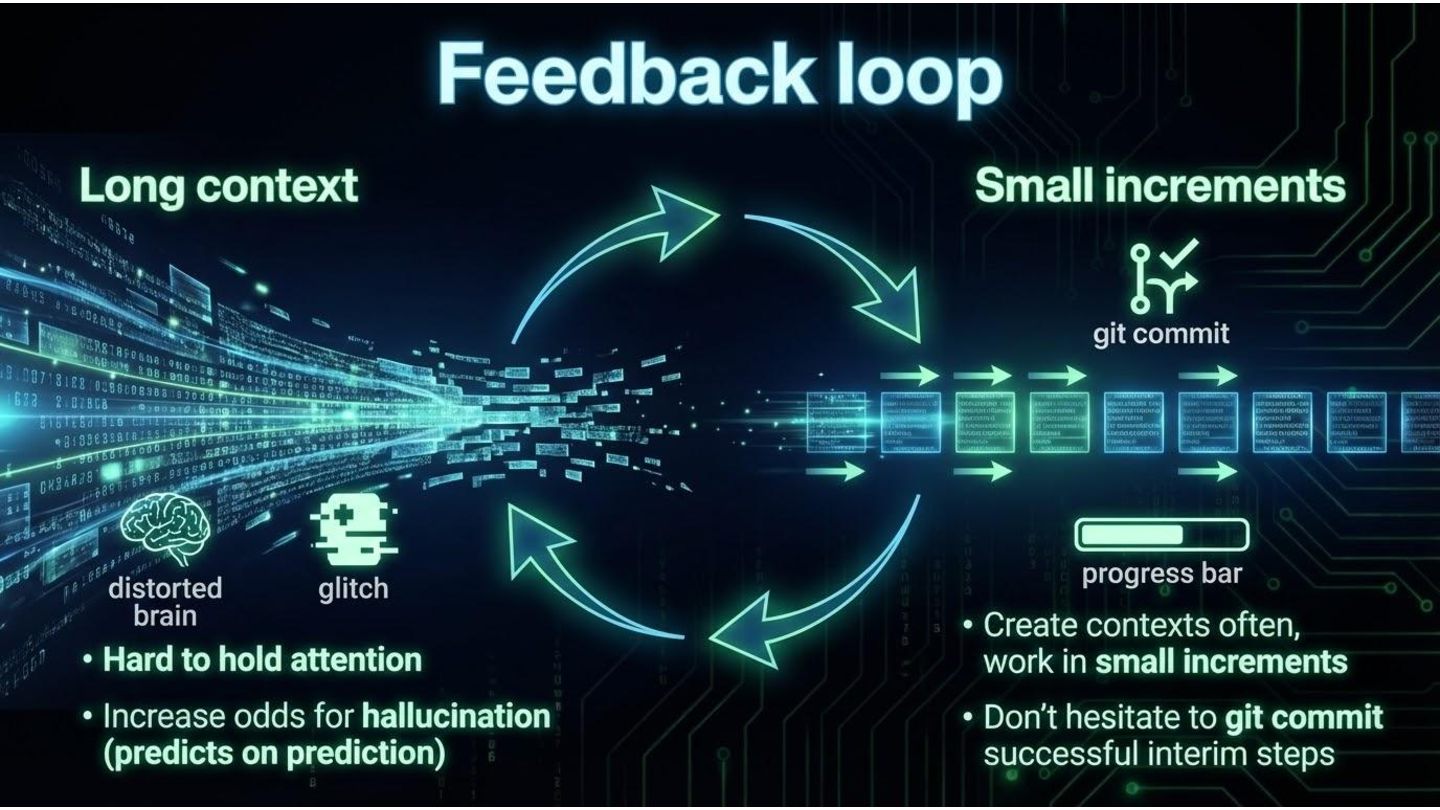
window is computationally expensive. • High attention to the start of the input • High attention to the end of the input • Low-to-no attention to the middle https://arxiv.org/pdf/2406. https://www.linkedin.com/pulse/real-limits-ai-attention-u- shaped-truth-context-windows-sergeyev-bk8oc/
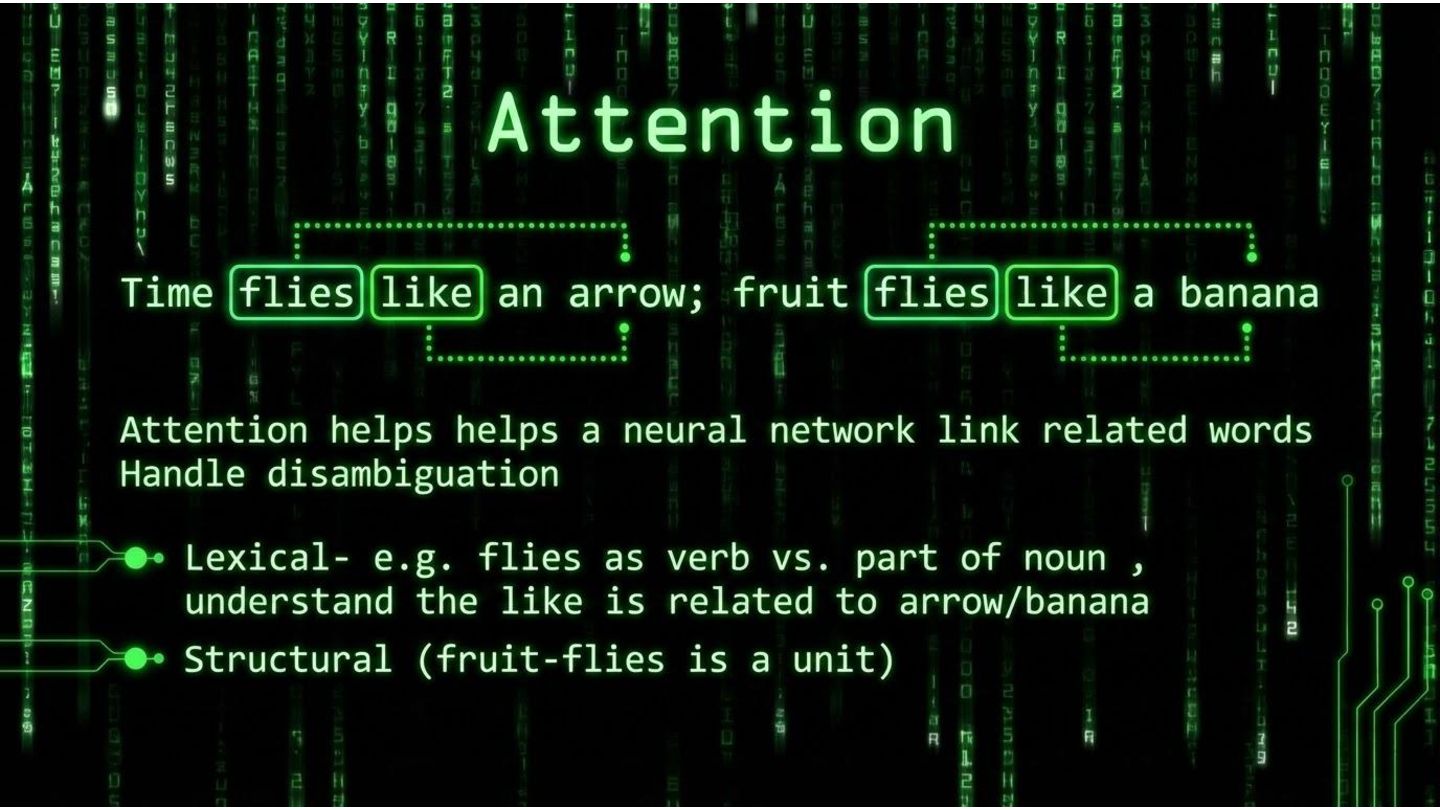
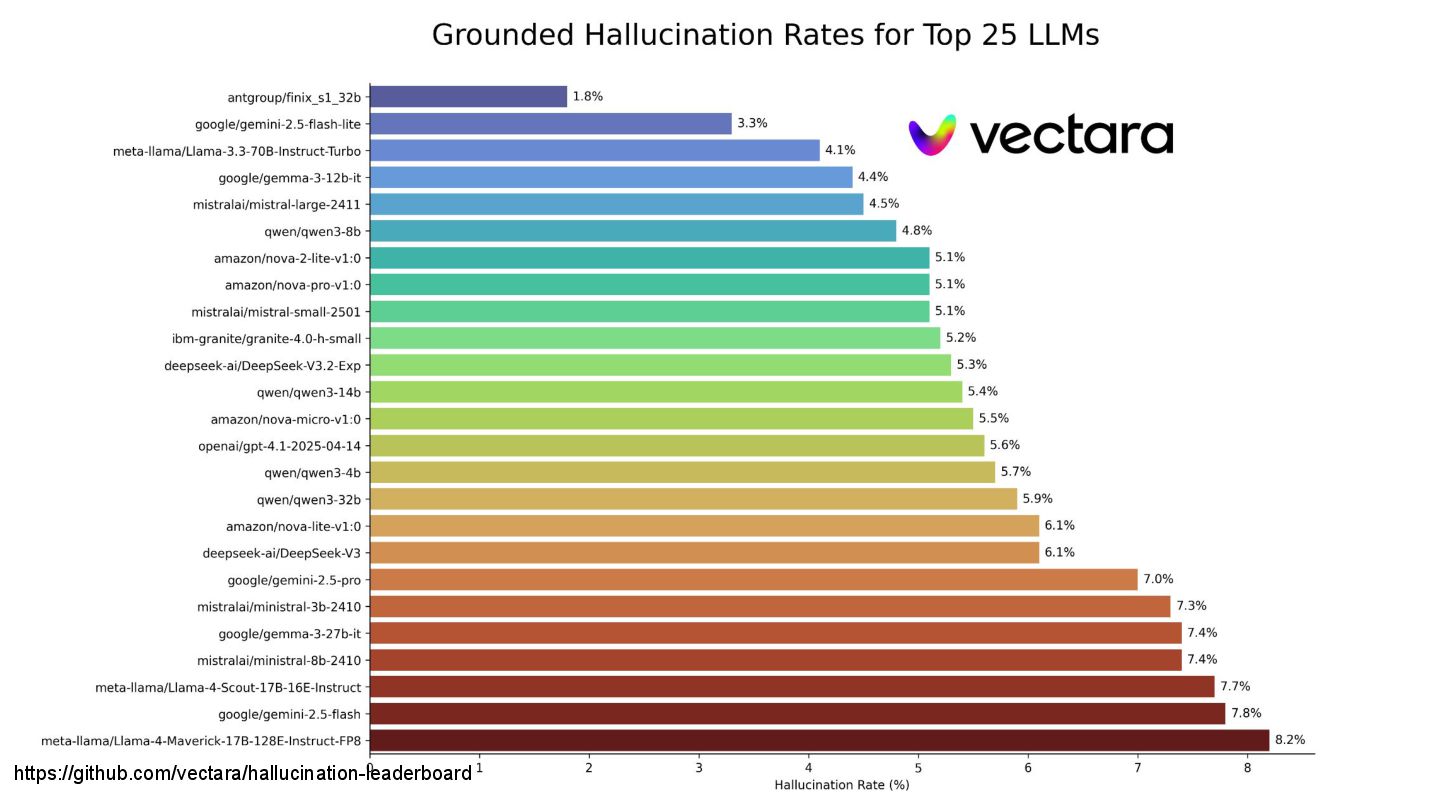
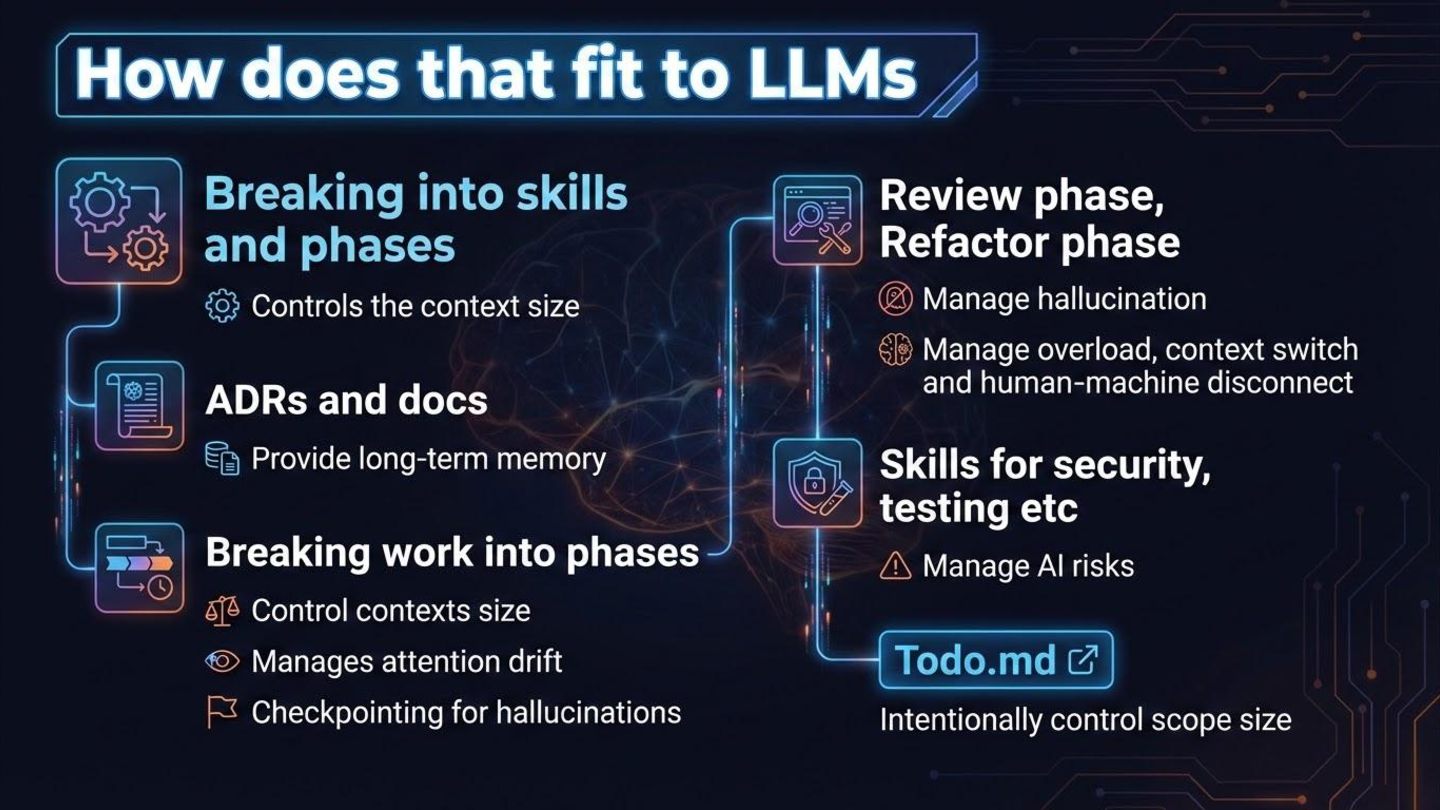
of word) prediction ◦ What we get is an option • Common things are easy - if you are using common practices, working on areas that have a lot of good example, chances are AI can really push you fast ◦ The corollary is that if you have unique patterns in your code, completely novel area AI will struggle • Getting exactly what you want is hard • Probable != Correct (aka “hellucinations”) • CONTEXT is king ◦ Control size ◦ Manage attention
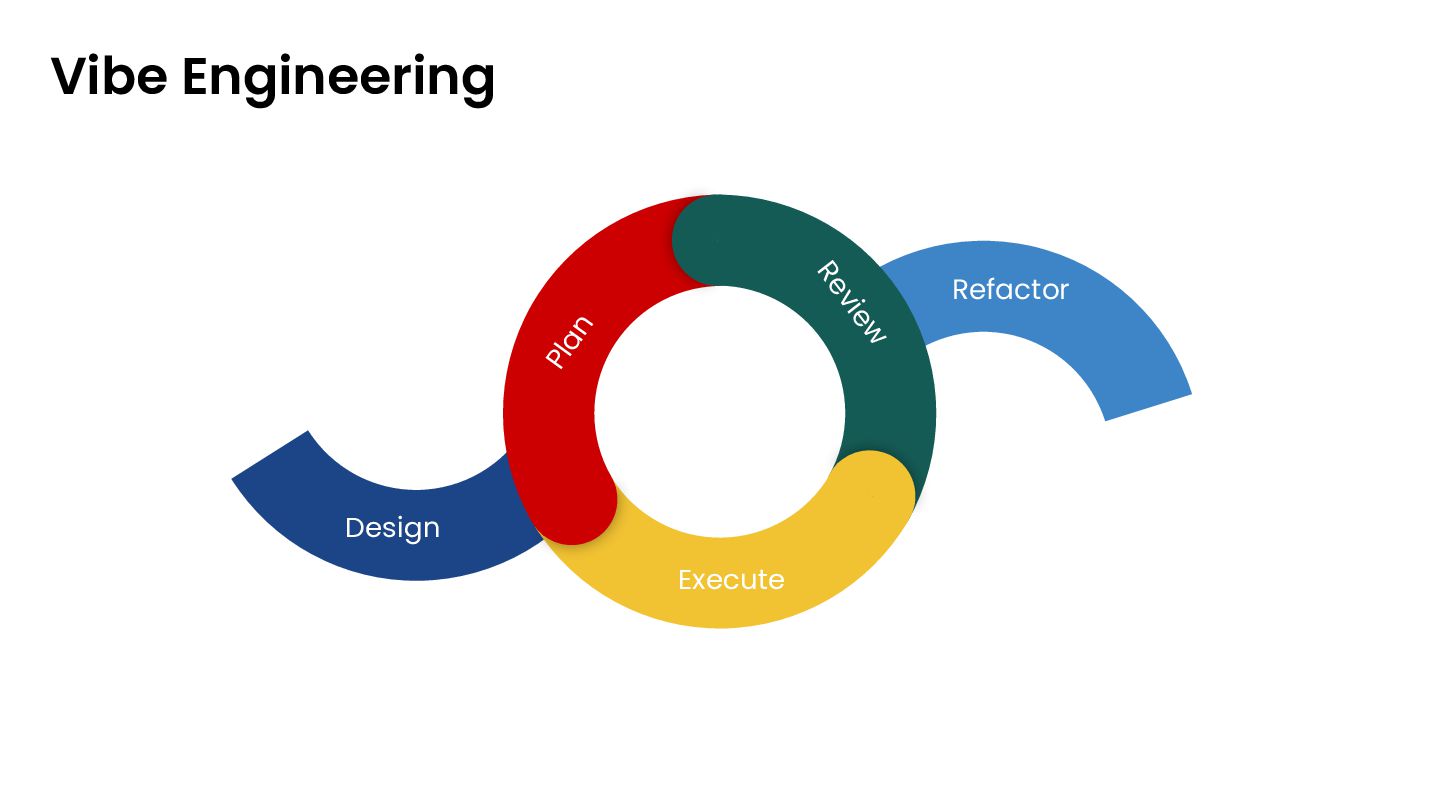
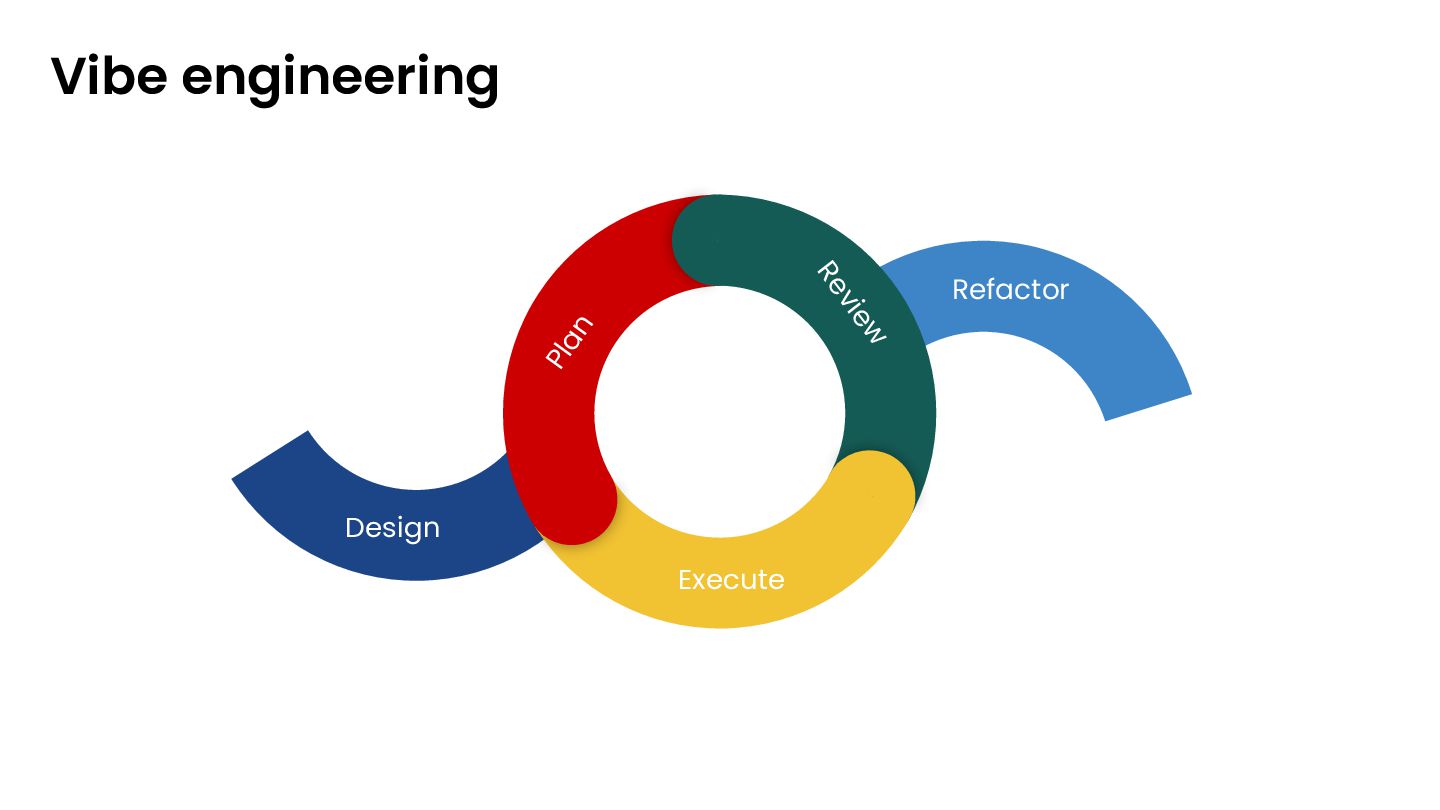
claude Opus 4.5 (cursor/claude code) • Why? ◦ Make the high-level plan more actionable • How? ◦ Ask for gaps and challenges ◦ Verify vs. existing codebase ◦ Use multiple models ◦ Decided on scope (defer stuff to todo.md for later) ◦ Align with ADRs ◦ Can use the cc/cursor plan mode • Persist in the memory-bank for tracking and verification
4.5 (claude code/ cursor) ▪ Gemini 3 pro (cursor) ◦ Grunt work ▪ Chatgpt 5.2 -seems to have more attention to detail • Why? ◦ As long as we don’t care for costs - better models yield better results ▪ Slow and steady wins the race - but we can augment by running multiple tasks in parallel • How? ◦ Scan through blurb - notice shortcuts and challenge them ◦ Remind models about testing and running tests • Probably worth looking at worktrees (different “branch” for each agent)
use in coding • Why? ◦ Different perspective • How? ◦ Verify assumptions ◦ Ask model to describe what the code does ◦ Ask models to verify ADRs and plan ◦ Check for todos ◦ Update-docs - (skill/rules) to look at all the changes and how they affect our memory-bank • Map out what’s left - think if you need a new prompt/agent or can continue conversation
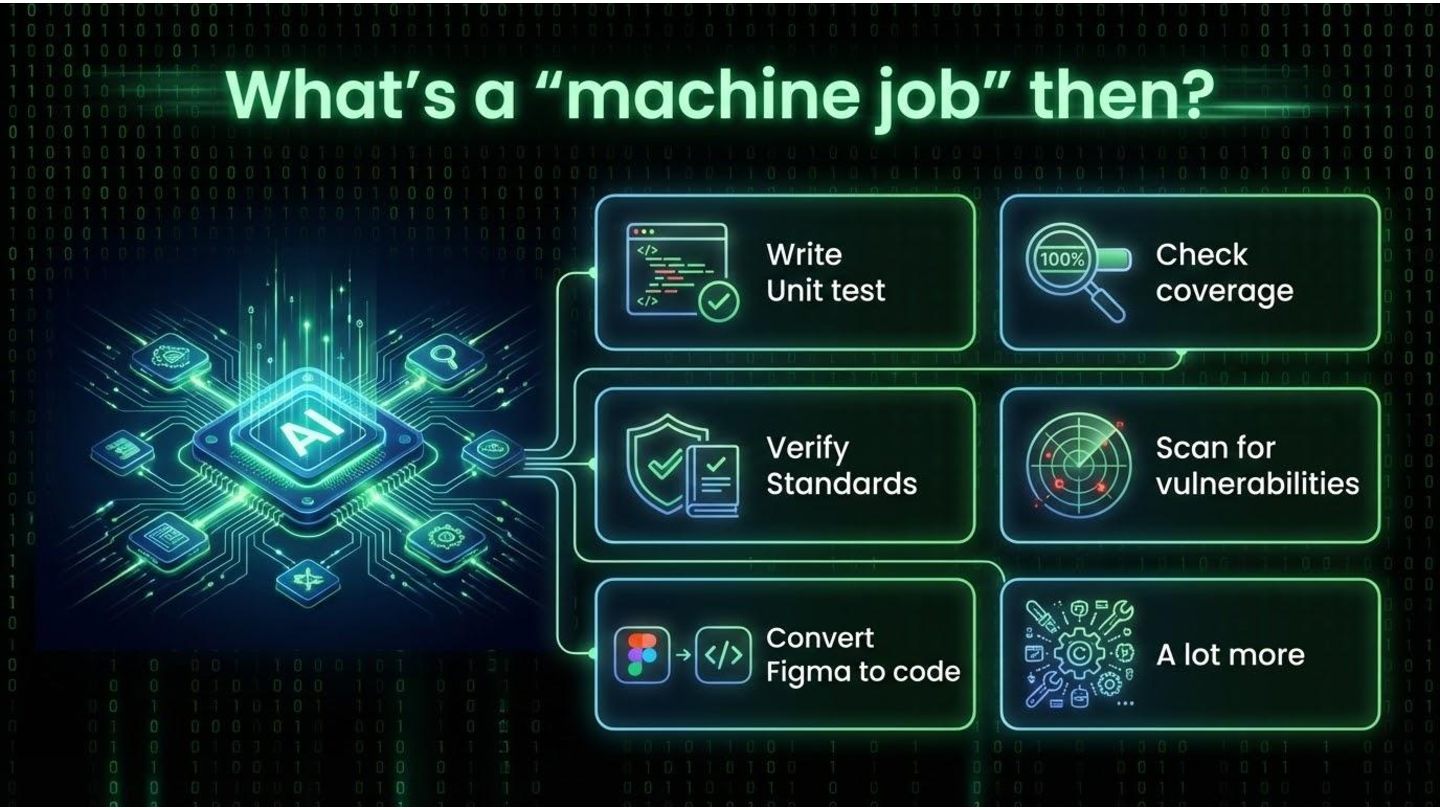
all the mods • Why? ◦ Models hallucinate and cheat • How? ◦ Review all the changes by yourself ◦ Ask models to produce documentation (sequences, block diagrams etc.) ◦ Ask models to explain how things work based on code ◦ Ask models to find gaps, todos, “for now” , “fix later”s etc. • Maybe not each cycle but a must
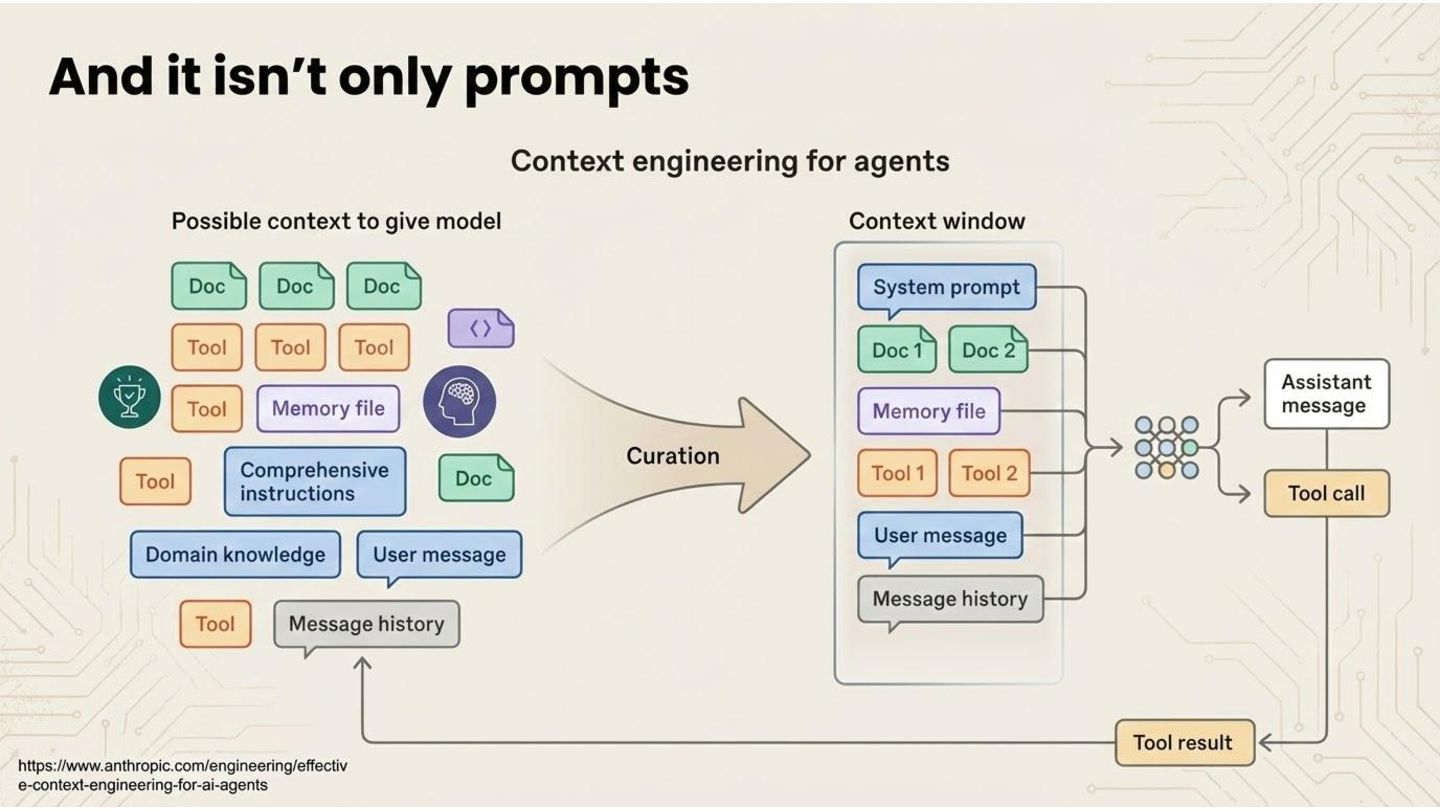
Claude.md, agents.md ◦ always in context (cursor let’s you scope them with glob) ◦ claude let’s you scope them by folder • skills/commands - prompt + scripts + templates - loaded as needed • Mcp - remove or local code execution of ready-made commands
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}