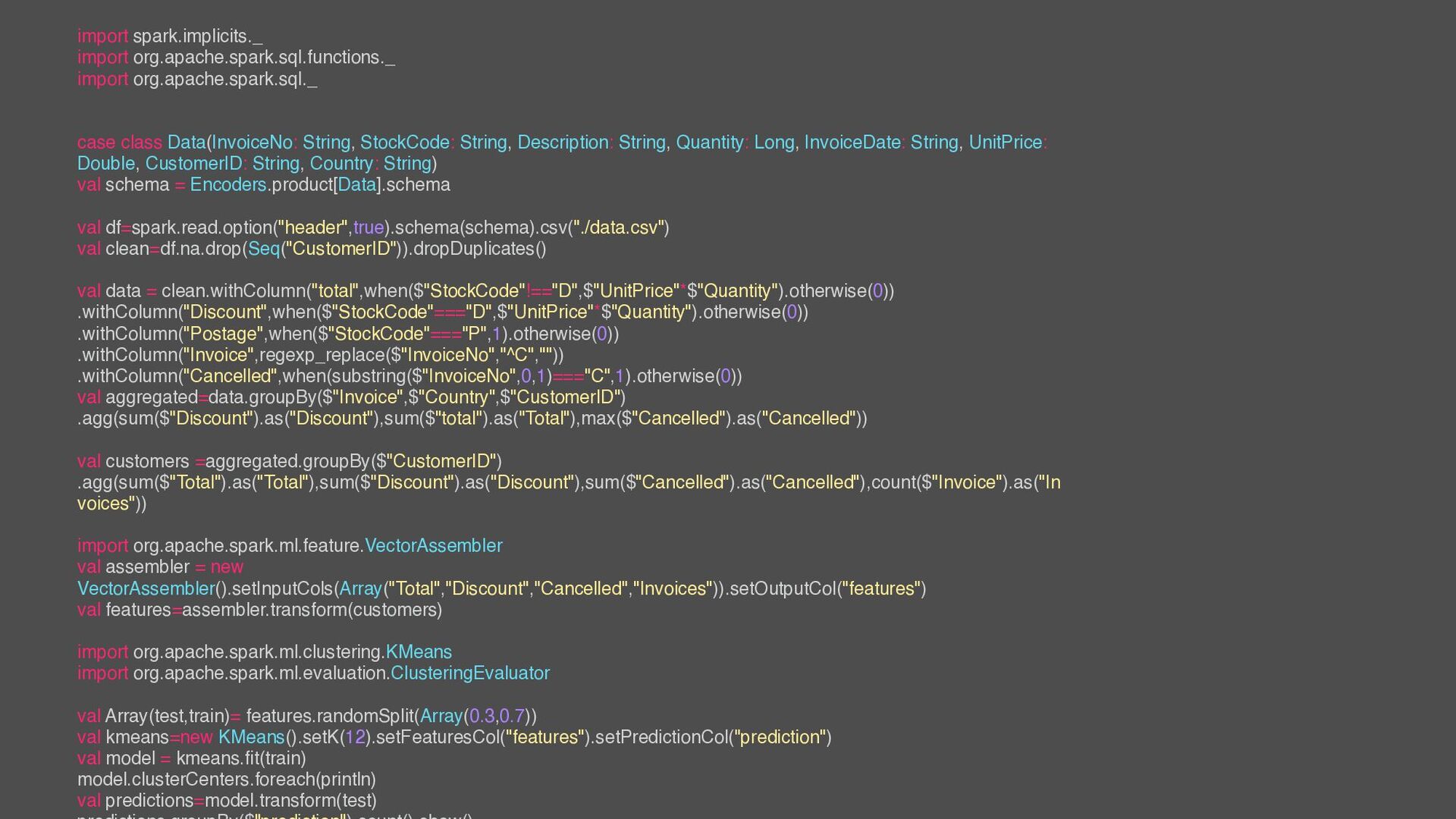
Data(InvoiceNo: String, StockCode: String, Description: String, Quantity: Long, InvoiceDate: String, UnitPrice: Double, CustomerID: String, Country: String) val schema = Encoders.product[Data].schema
val df=spark.read.option("header",true).schema(schema).csv("./data.csv") val clean=df.na.drop(Seq("CustomerID")).dropDuplicates()
val data = clean.withColumn("total",when($"StockCode"!=="D",$"UnitPrice"*$"Quantity").otherwise(0)) .withColumn("Discount",when($"StockCode"==="D",$"UnitPrice"*$"Quantity").otherwise(0)) .withColumn("Postage",when($"StockCode"==="P",1).otherwise(0)) .withColumn("Invoice",regexp_replace($"InvoiceNo","^C","")) .withColumn("Cancelled",when(substring($"InvoiceNo",0,1)==="C",1).otherwise(0)) val aggregated=data.groupBy($"Invoice",$"Country",$"CustomerID") .agg(sum($"Discount").as("Discount"),sum($"total").as("Total"),max($"Cancelled").as("Cancelled"))
val customers =aggregated.groupBy($"CustomerID") .agg(sum($"Total").as("Total"),sum($"Discount").as("Discount"),sum($"Cancelled").as("Cancelled"),count($"Invoice").as("In voices"))
import org.apache.spark.ml.feature.VectorAssembler val assembler = new VectorAssembler().setInputCols(Array("Total","Discount","Cancelled","Invoices")).setOutputCol("features") val features=assembler.transform(customers)
import org.apache.spark.ml.clustering.KMeans import org.apache.spark.ml.evaluation.ClusteringEvaluator
val Array(test,train)= features.randomSplit(Array(0.3,0.7)) val kmeans=new KMeans().setK(12).setFeaturesCol("features").setPredictionCol("prediction") val model = kmeans.fit(train) model.clusterCenters.foreach(println) val predictions=model.transform(test)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
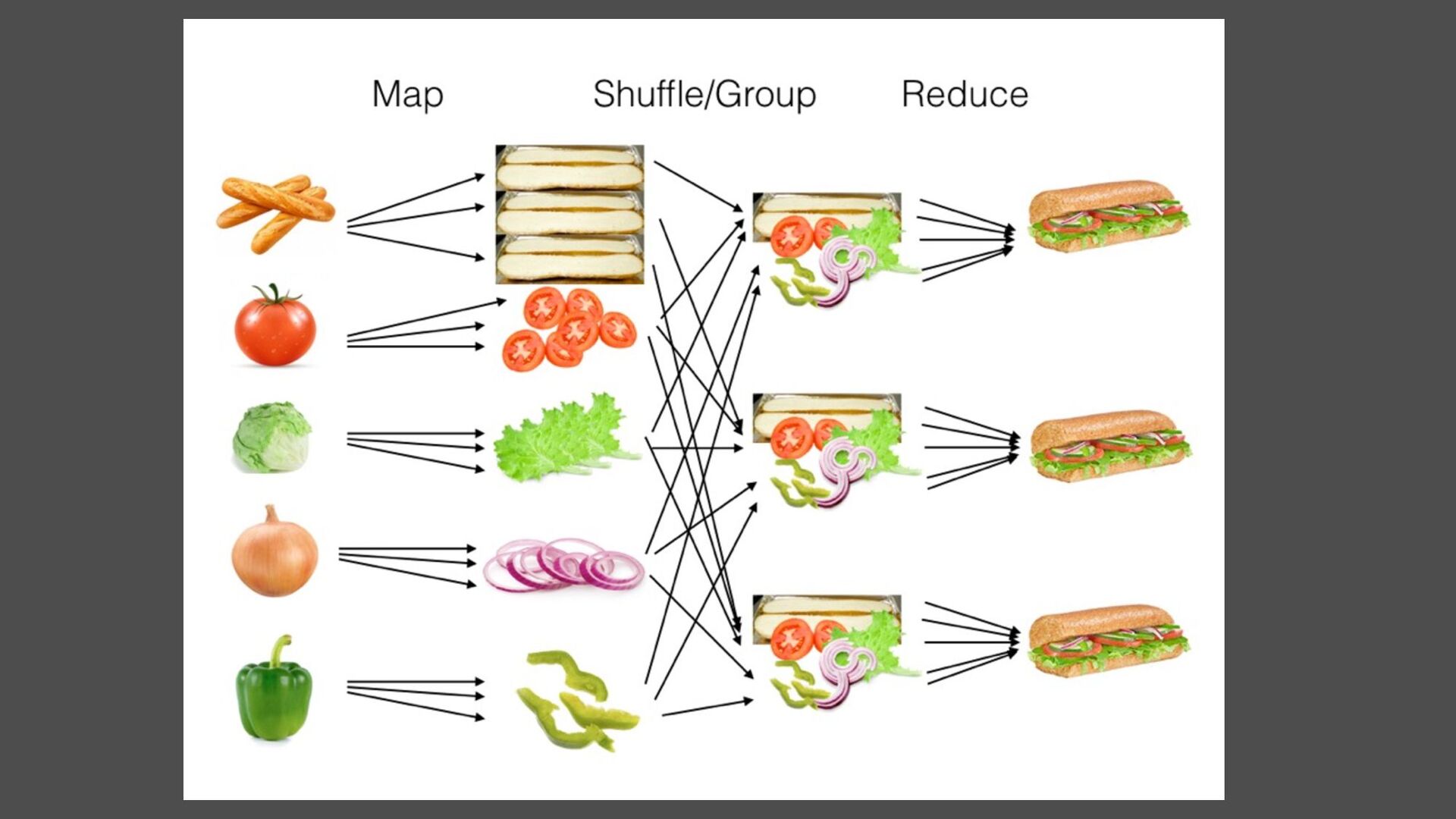{kind=link}
{kind=link}
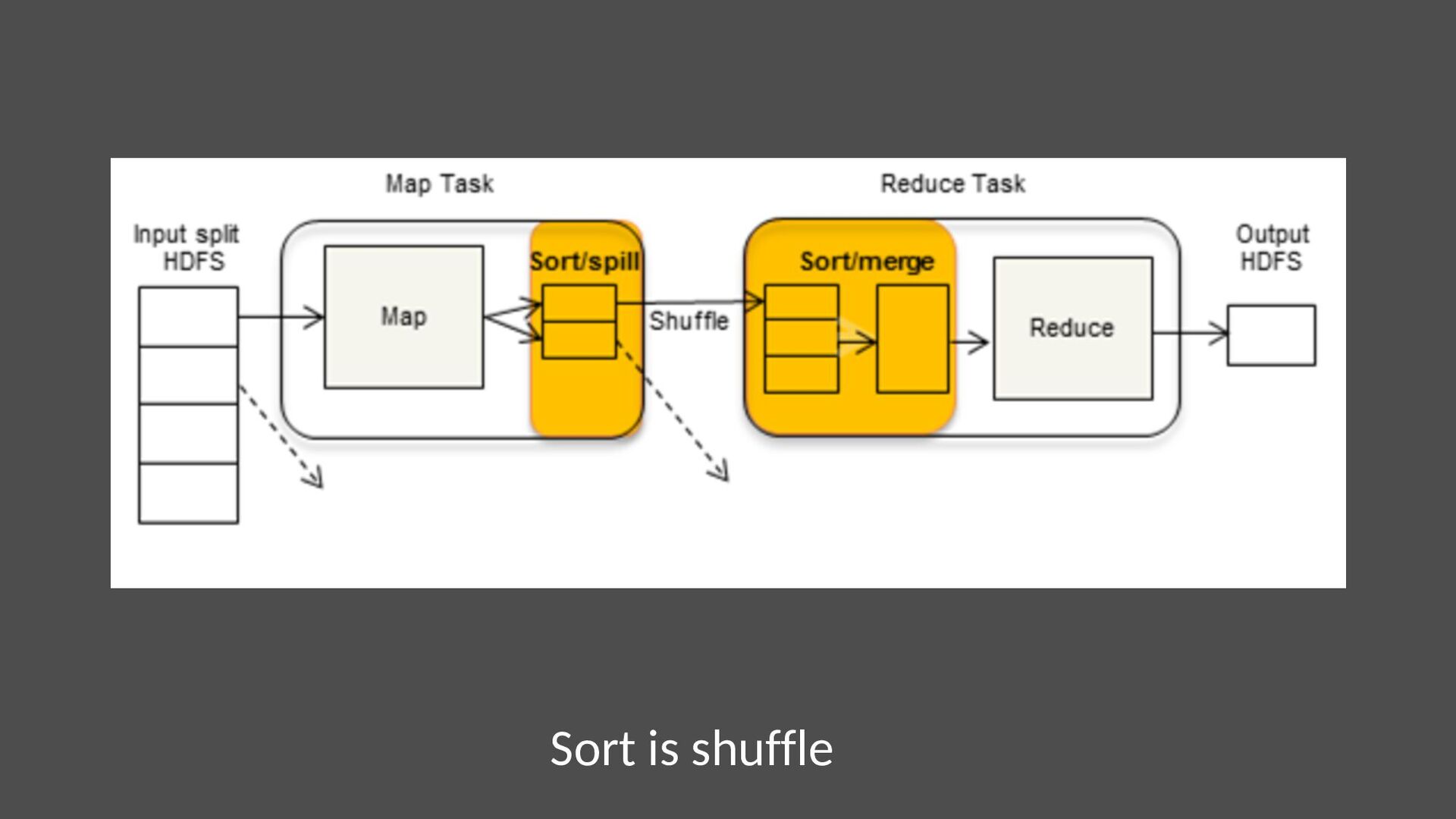{kind=link}
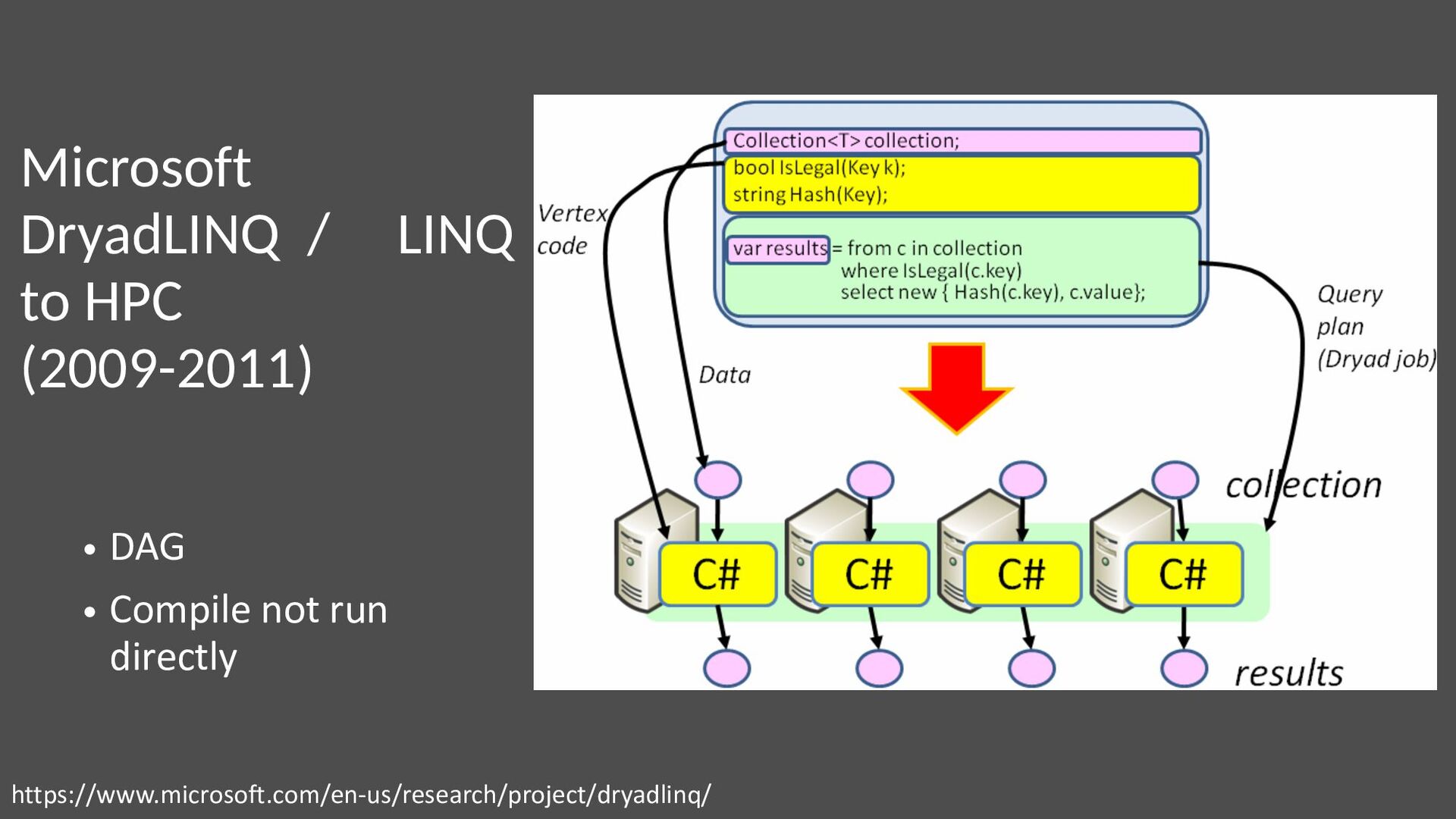{kind=link}
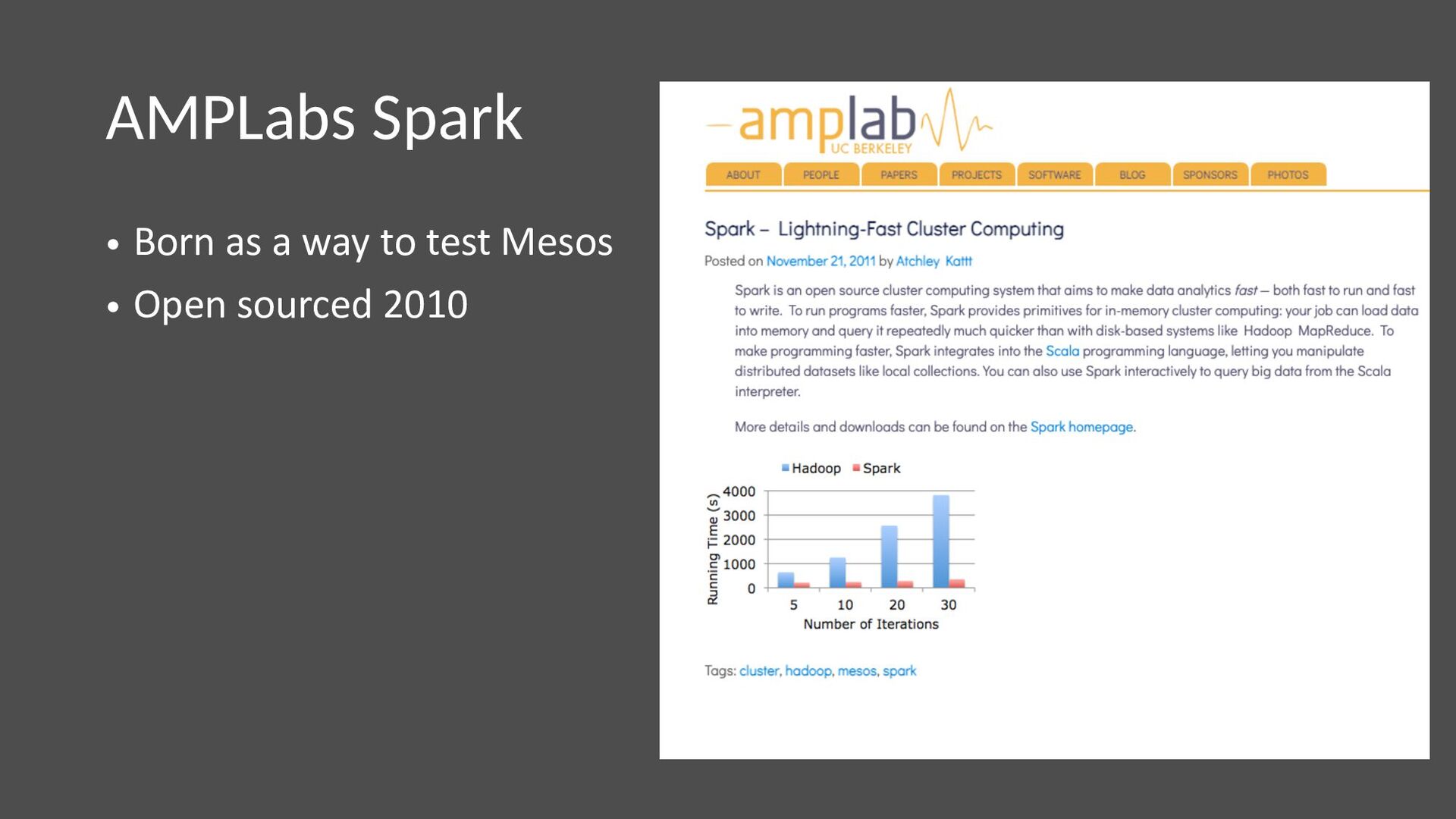{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
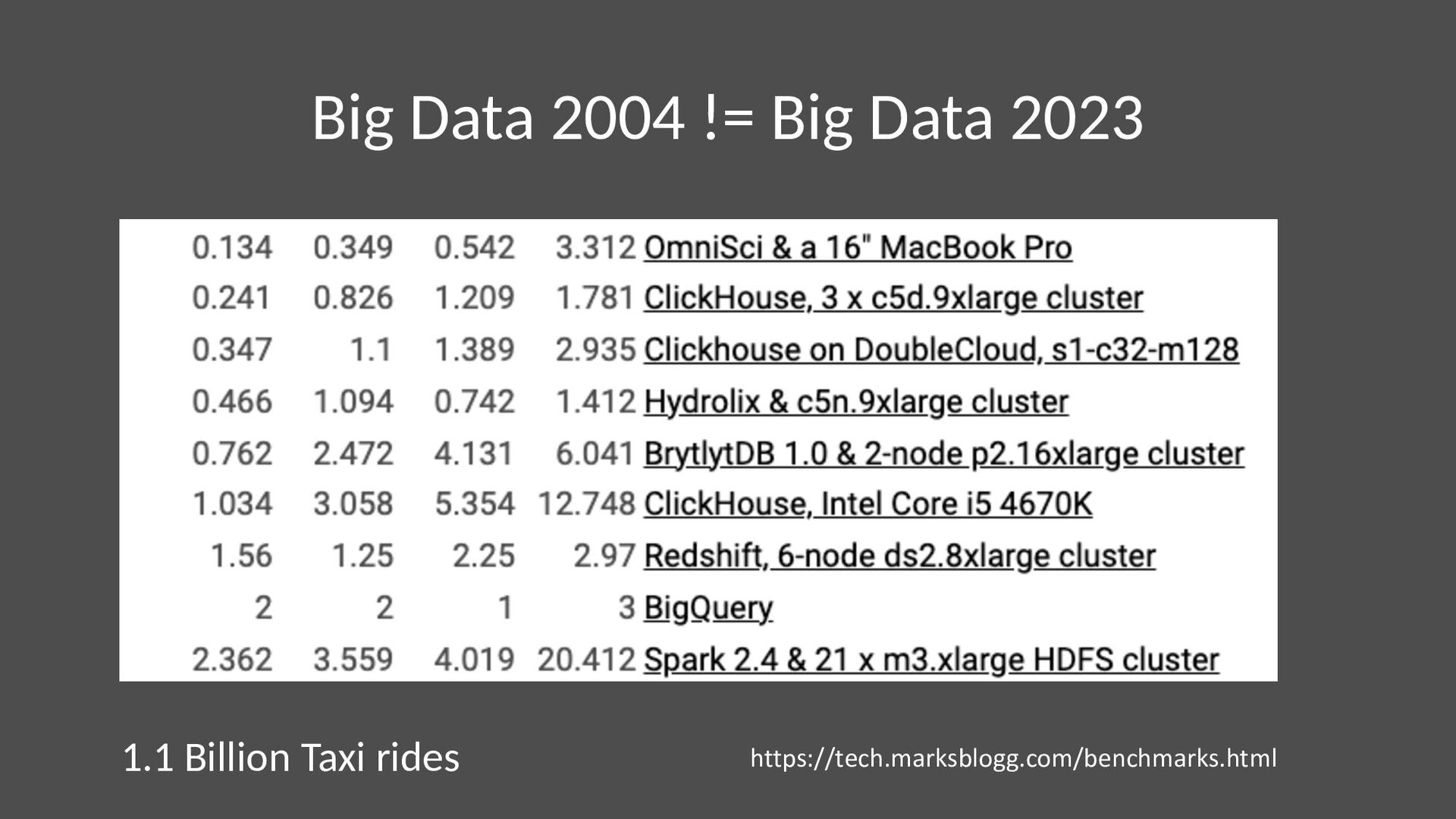{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}