Data 4. Crystal Representations 5. Classical Learning 6. Deep Learning 7. Building a Model from Scratch 8. Accelerated Discovery 9. Generative Artificial Intelligence 10. Future Directions
Policy Environment Reward Use data to choose the next best experiment (or simulation) Action Feedback Observation Example: “Choose next anneal temperature to maximise conductivity”
workflows (fixed platform or mobile) DIGIBAT: In collaboration with Magda Titirici, Ifan Stephens, and others (ICL) Usually a mix of proprietary code, with GUI and Python API for user control
artificial intelligence to interact with their environment S. Eppel et al, ACS Central Science 6, 1743 (2020) Adapting computer vision models for laboratory settings GT = ground truth Pred = predicted
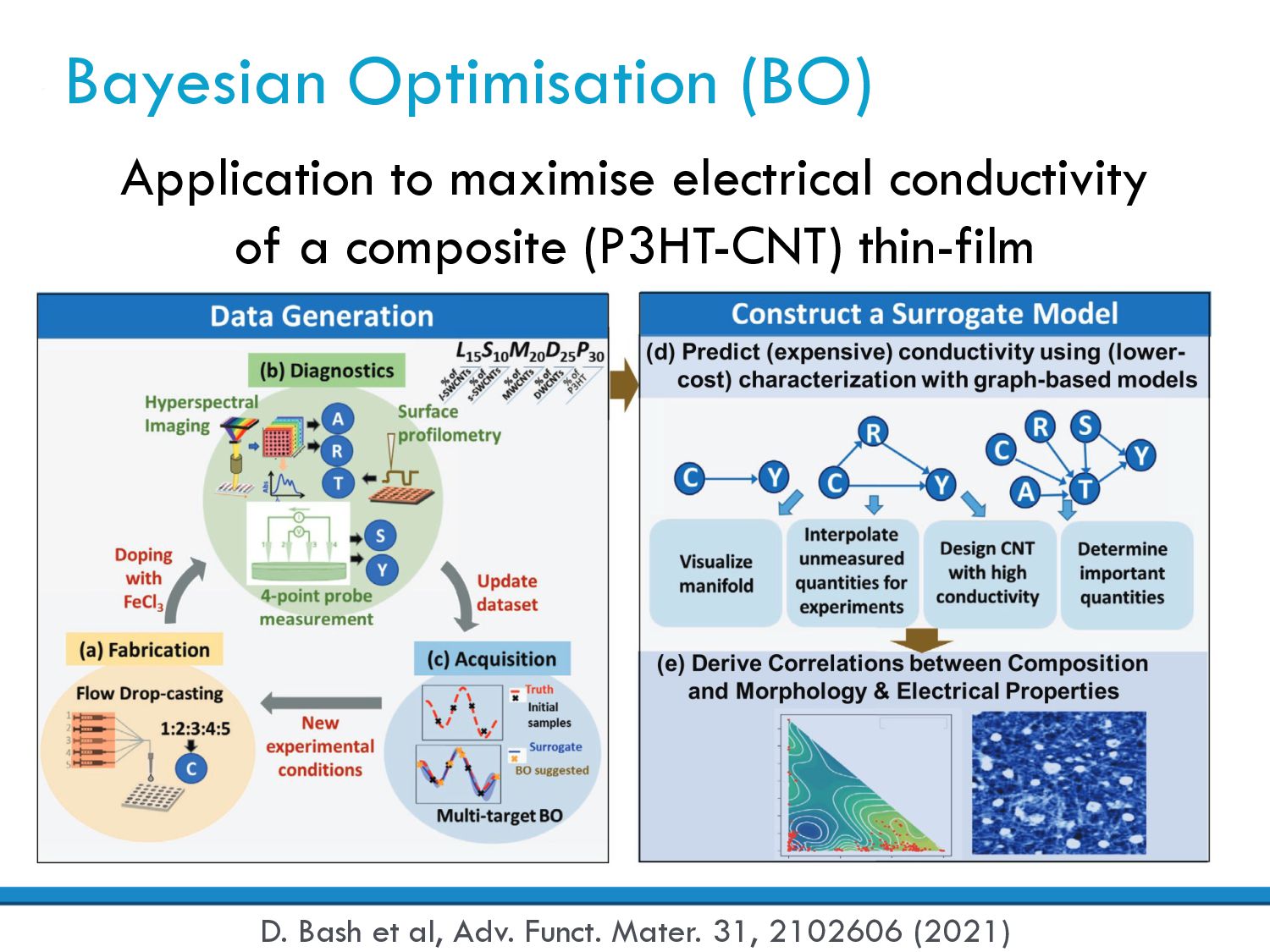
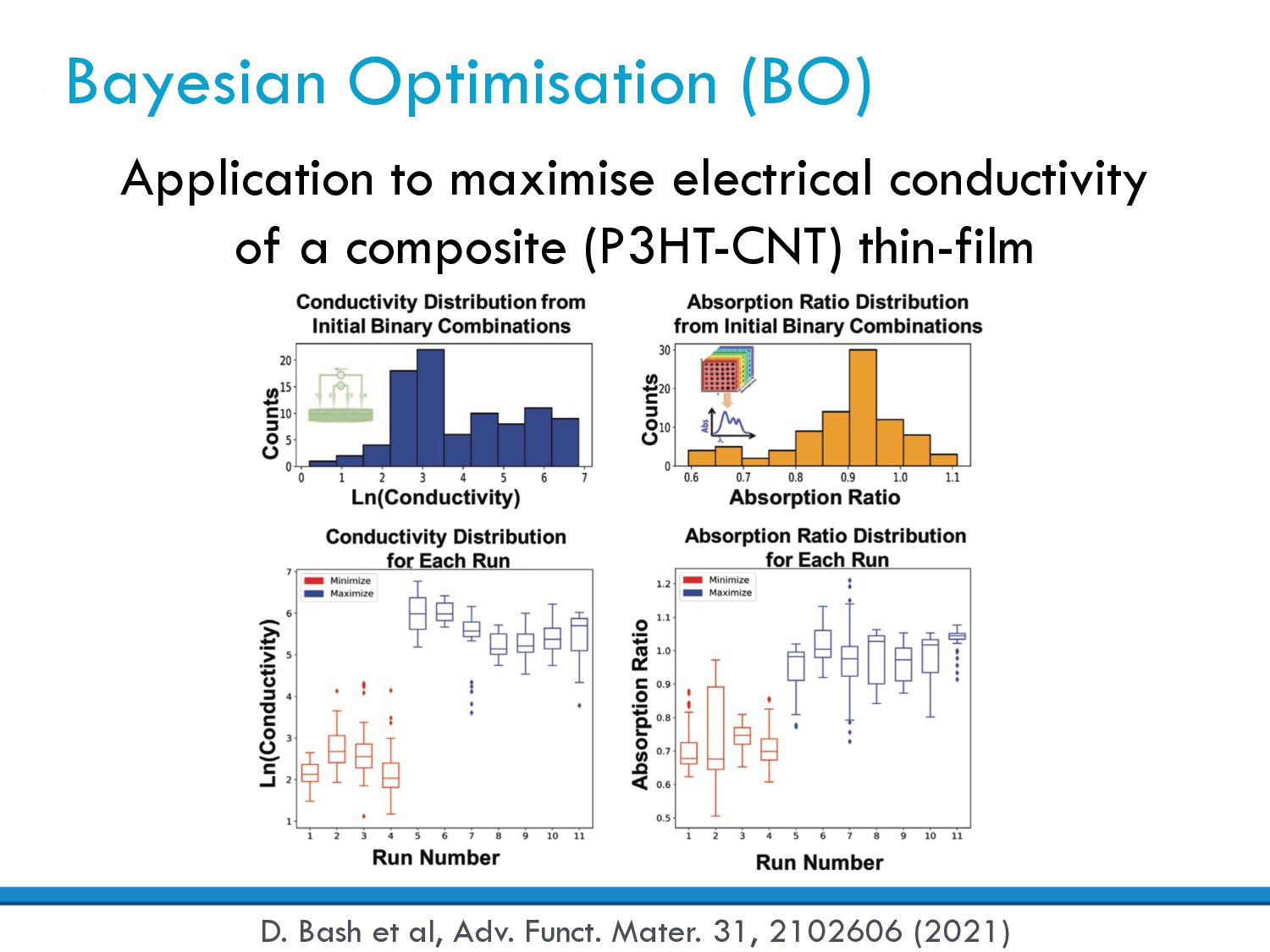
Objective function (O): Materials properties or device performance criteria, e.g. battery lifetime Parameter selection: Variables that can be controlled, e.g. temperature, pressure, composition Data acquisition: How the data is collected, e.g. instruments, measurements, automation
a limited region of the parameter space (x) Gradient based: iterate in the direction of the steepest gradient (∇O), e.g. gradient descent Hessian based: use information from the second derivatives (∇2O), e.g. quasi-Newton O x x1 xn Local minimum The same concepts are involved in ML model training
across the entire parameter space Numerical: iterative techniques to explore parameter space, e.g. downhill simplex, simulated annealing Probabilistic: incorporate probability distributions, e.g. Markov chain Monte Carlo, Bayesian optimisation O x Global minimum xn x1 The same concepts are involved in ML model training
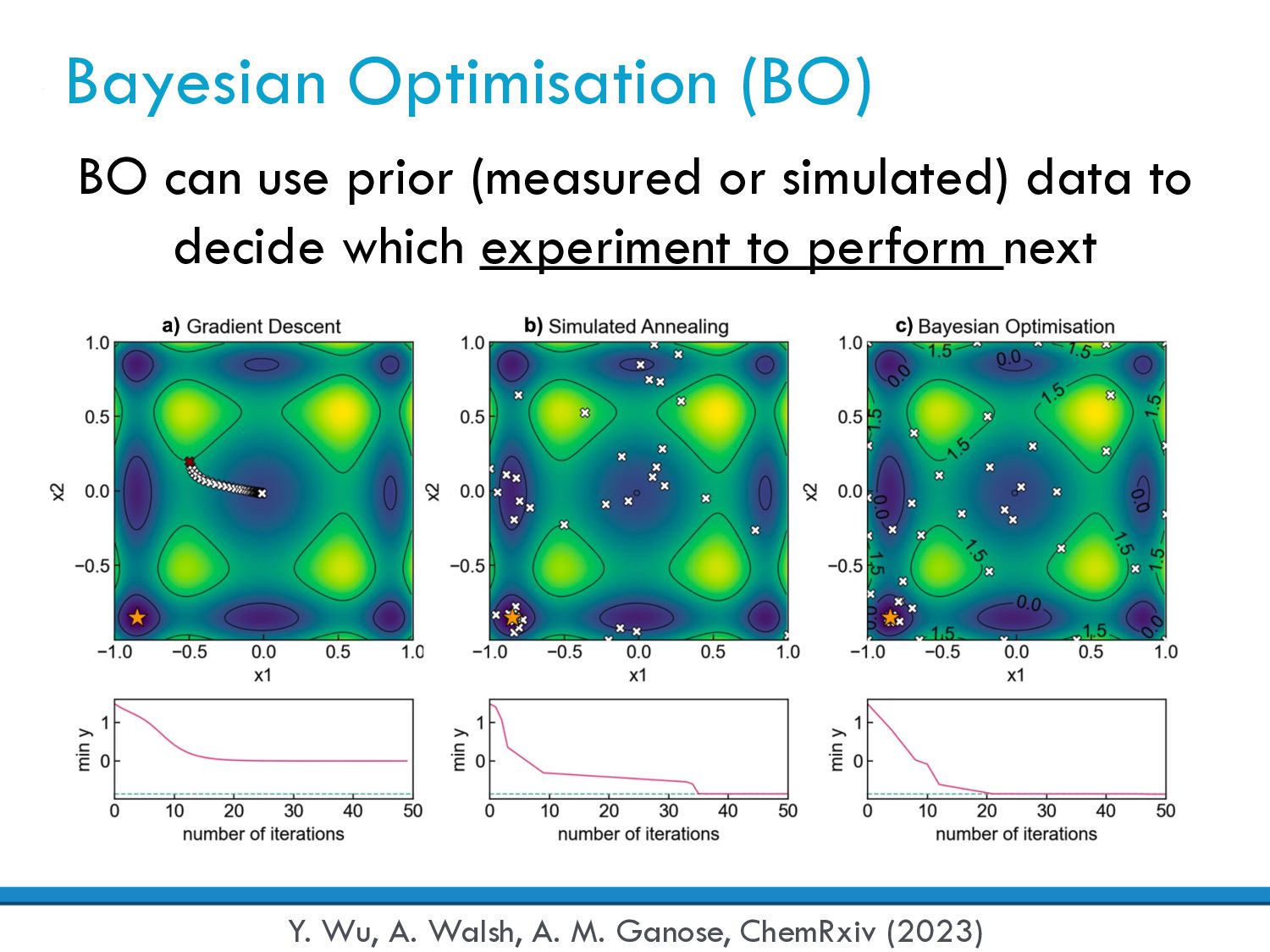
decide which experiment to perform next J. Močkus, Optimisation Techniques 1, 400 (1974) Probabilistic (Surrogate) Model Approximation of the true objective function O(x) ~ f(x), e.g. Gaussian process, GP(x,x') Acquisition Function Selection of the next sample point, e.g. upper confidence bound (UCB), probability of improvement (PI), expected improvement (EI) known new (parameters to sample)
decide which experiment to perform next J. Močkus, Optimisation Techniques 1, 400 (1974) Probabilistic (Surrogate) Model (parameters to sample) Gaussian process: f(x) ~ GP(μ(x), k(x,xʹ)) mean function Gaussian kernel function k(x,xʹ) measures the similarity points x and xʹ • Kernel controls function smoothness and uncertainty • Similar x share information • Dissimilar x default to the mean with high uncertainty known new
Exploration–Exploitation Tradeoff xnext = max( μ(x) + βσ(x) ) Prediction based on prior knowledge Weighted Uncertainty What to do next N. Srinivas et al, IEEE Transactions on Information Theory, 58 (2012) x β < 1 focus on exploitation β ~ 1 balance risk and reward β > 1 focus on exploration A tunable (learnable) hyperparameter of UCB
function AL: find inputs that minimise uncertainty Epistemic uncertainty* Posterior samples Target unknown regions that can improve the model Gaussian process is updated with new observations to yield revised function values and uncertainty *Epistemic = data-limited (reducible) uncertainty; Aleatoric = noise (irreducible)
(maximise score), finance (profit), and robotics (task completion) Nintendo An agent interacts with an environment to learn decision-making strategies that achieve a specific goal
Data-driven decision making that adapts over time Probability of action at given state st Expected reward for action at Effective temperature for exploration/exploitation balance Sum over all possible actions Q(s,a) is the expected reward from taking action a in state s, following policy π
search - Simple to implement and understand - Inefficient for high-dimensional spaces - Maximises experiments and dataset size Bayesian Optimisation - Efficiently exploit data - Works with noisy and expensive evaluations - Surrogate model & acquisition selection - Struggle with high- dimensional spaces Reinforcement Learning - Learns optimal policies through feedback - Can handle dynamic and complex environments - Sample hungry - Slow to converge
compositions, processing sensitivity • Data quality and reliability: errors and inconsistencies waste resources • Cost of automation: major investment required in infrastructure and training • Adaptability: systems and workflows may be difficult to reconfigure for new problems
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}