extremely resourceful. They see magic as a complex system waiting to be decoded and controlled. Proficiencies (recommended) Chrome Developer Tools, Lighthouse, Google Search Console, webcrawlers Technical SEOs Class Details #brightonSEO @Jammer_Volts
used to rank the quality and value of your site content against other sites and what people are searching for with Google Search. How Google Search Works, Search Console Help Center Rendering’s role in Rank #brightonSEO @Jammer_Volts
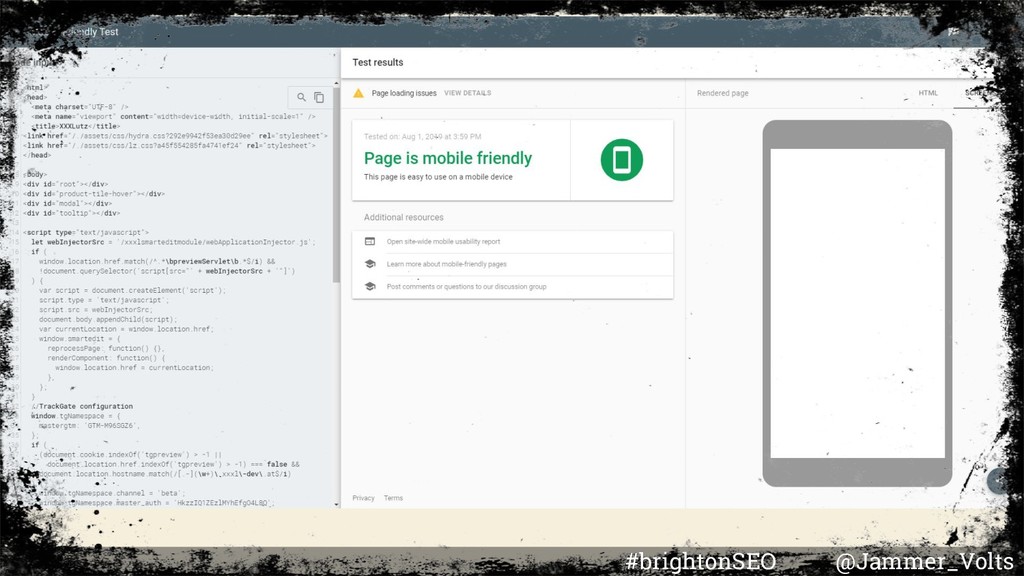
becomes more difficult to understand your web content because we are missing key visual layout information about your web pages. As a result, the visibility of your site content in Google Search can suffer. Rendering Risks #brightonSEO @Jammer_Volts
thread. A thread is a single connection. It sequentially moves through each action, one at a time, until it’s task is complete. Features & Traits Actions Equipment #brightonSEO @Jammer_Volts
the number of simultaneous parallel connections Googlebot may use to crawl the site, as well as the time it has to wait between the fetches.” What Crawl Budget Means for Googlebot, Google Webmaster Blog Features & Traits Actions Equipment #brightonSEO @Jammer_Volts
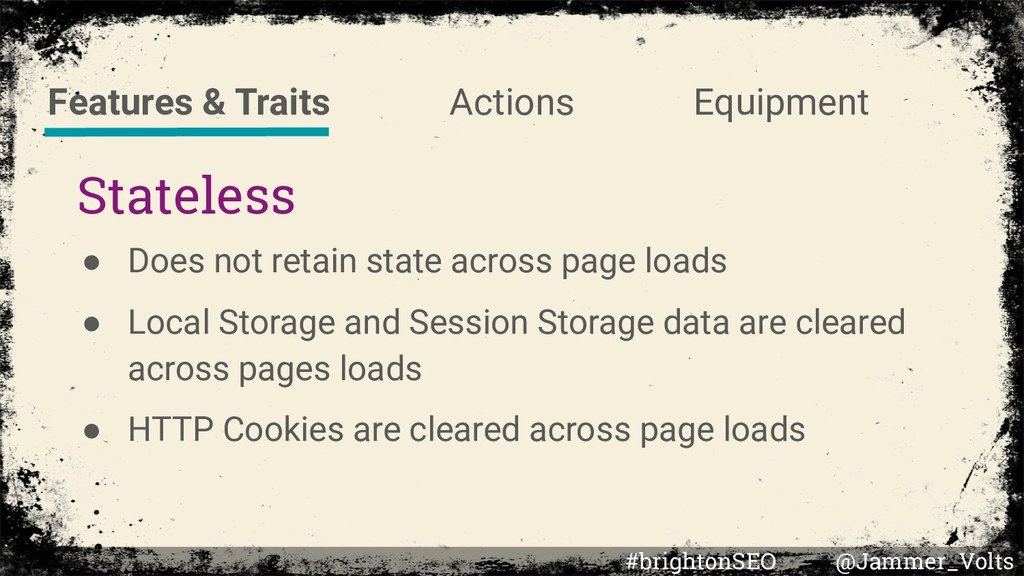
Local Storage and Session Storage data are cleared across pages loads • HTTP Cookies are cleared across page loads Features & Traits Actions Equipment #brightonSEO @Jammer_Volts
and buy a healing potion. If they have shields, buy 2. “ Googlebot comes back with 2 potions. Features & Traits Actions Equipment #brightonSEO @Jammer_Volts
making sure it doesn't degrade the experience of users visiting the site. We call this the "crawl rate limit," which limits the maximum fetching rate for a given site. What Crawl Budget Means for Googlebot, Google Webmaster Central Blog Features & Traits Actions Equipment #brightonSEO @Jammer_Volts
asked for exist? A. HTTP Status Codes Q. Anything I should know before looking at this? A. Cache-Control, and Directives Features & Traits Actions Equipment #brightonSEO @Jammer_Volts
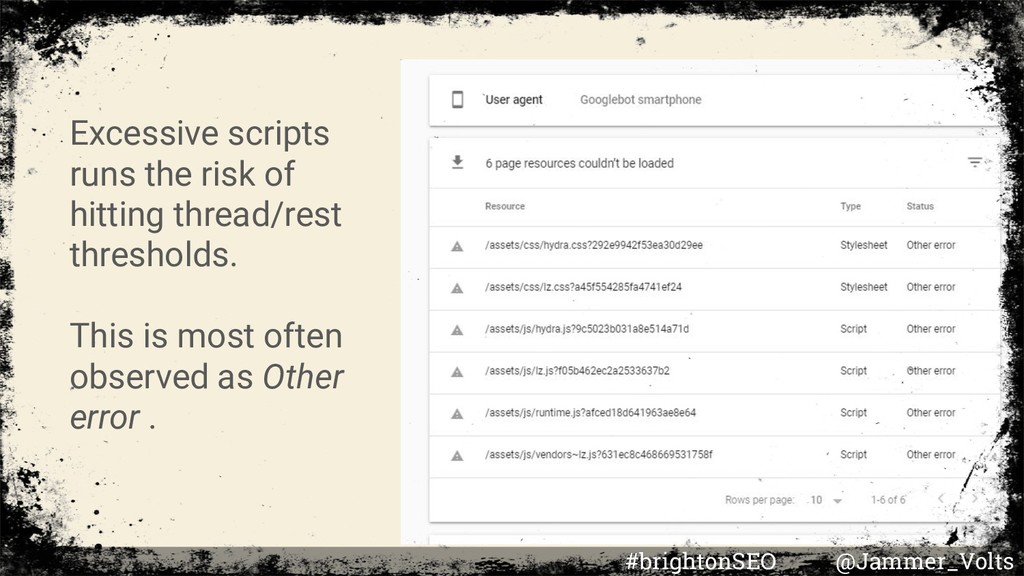
It feeds identified resources into the crawling queue. Features & Traits Actions Equipment Use Network tab to see how many resources a page calls #brightonSEO @Jammer_Volts
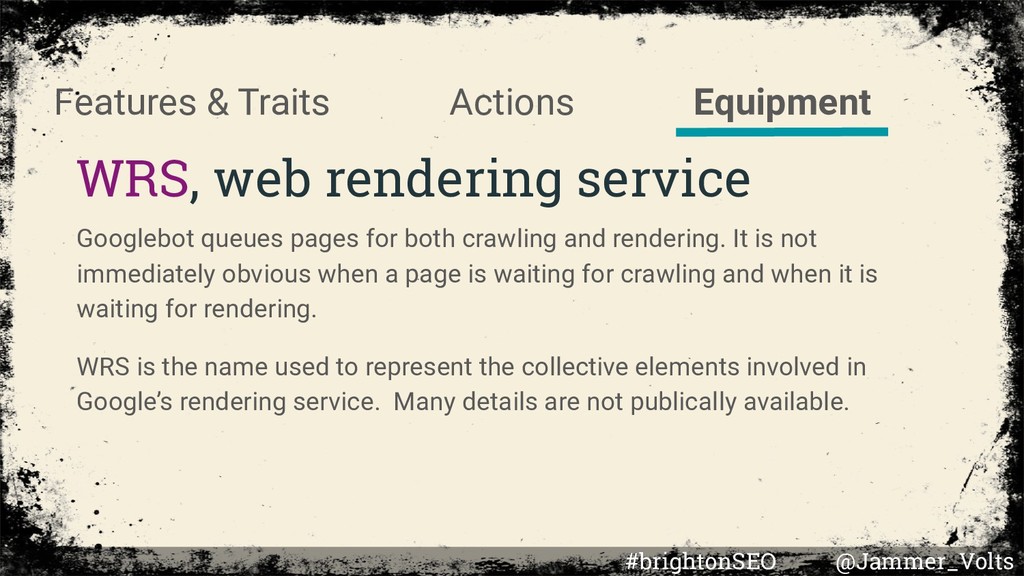
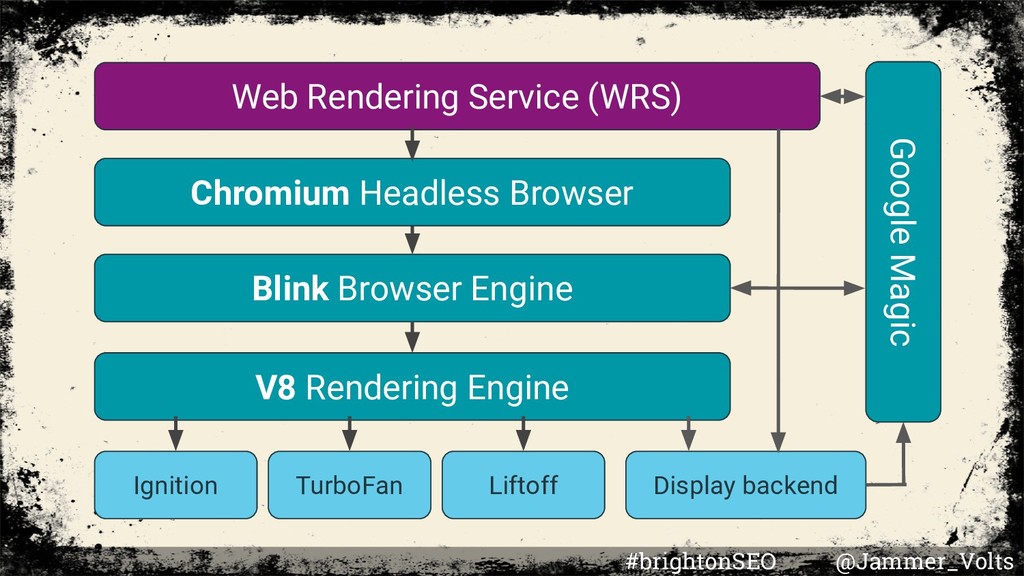
queues pages for both crawling and rendering. It is not immediately obvious when a page is waiting for crawling and when it is waiting for rendering. WRS is the name used to represent the collective elements involved in Google’s rendering service. Many details are not publically available. #brightonSEO @Jammer_Volts
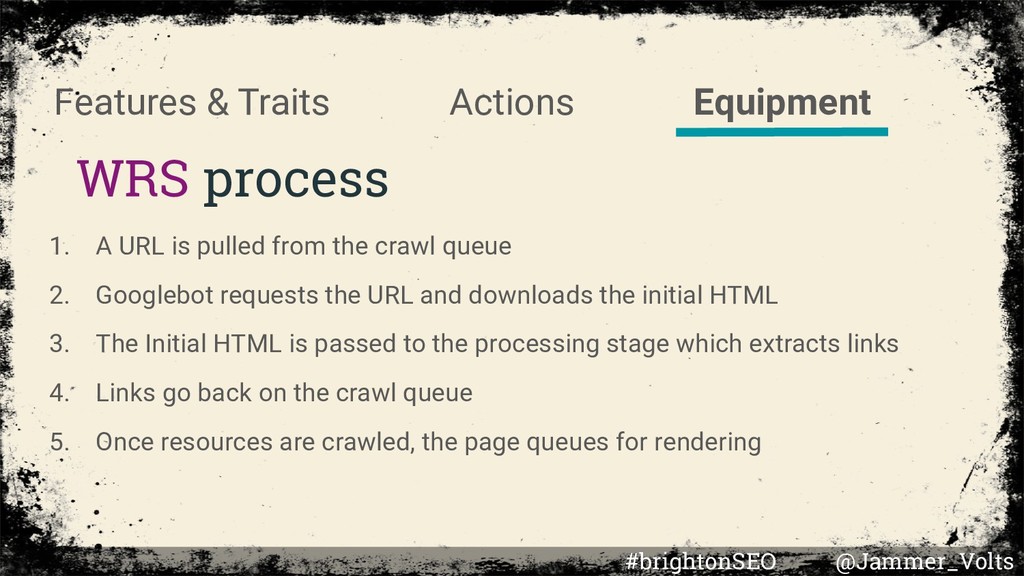
is pulled from the crawl queue 2. Googlebot requests the URL and downloads the initial HTML 3. The Initial HTML is passed to the processing stage which extracts links 4. Links go back on the crawl queue 5. Once resources are crawled, the page queues for rendering #brightonSEO @Jammer_Volts
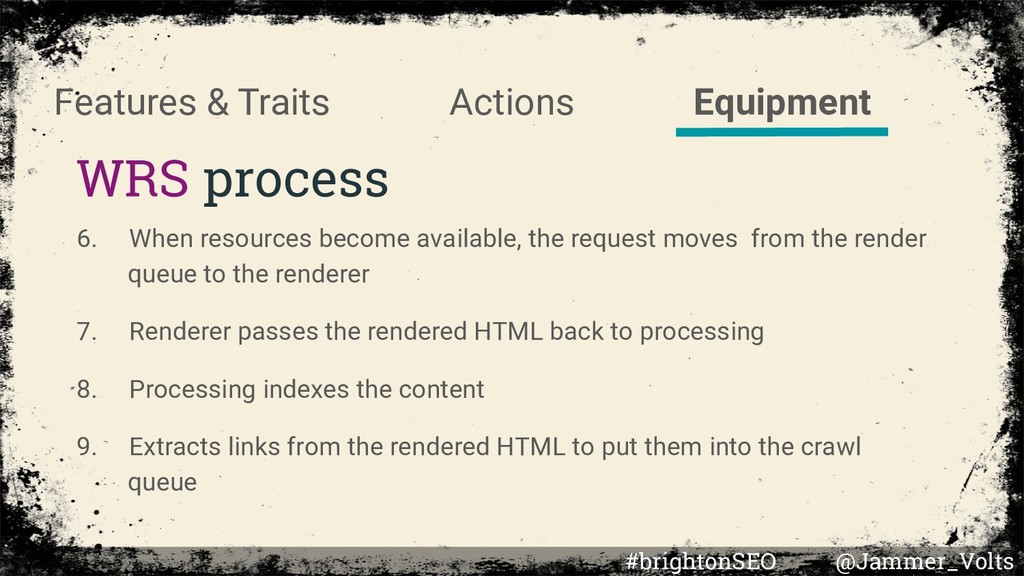
become available, the request moves from the render queue to the renderer 7. Renderer passes the rendered HTML back to processing 8. Processing indexes the content 9. Extracts links from the rendered HTML to put them into the crawl queue #brightonSEO @Jammer_Volts
means that there is no GUI (visual representation) • Used to load web pages and extract metadata • reading from and writing to the DOM • observing network events • capturing screenshots • inspecting worker scripts • recording Chrome Traces #brightonSEO @Jammer_Volts
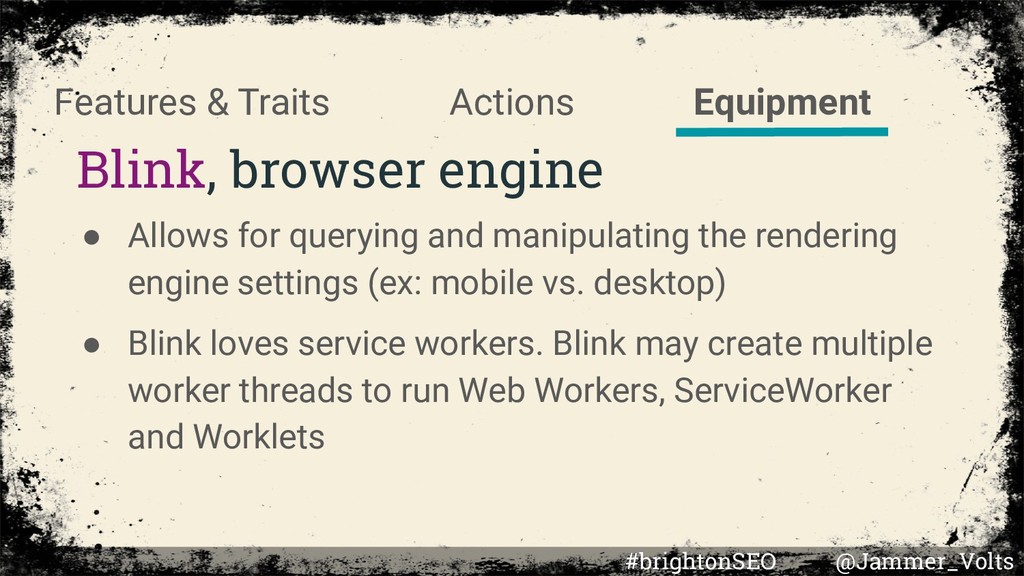
rendering engine settings (ex: mobile vs. desktop) • Blink loves service workers. Blink may create multiple worker threads to run Web Workers, ServiceWorker and Worklets Equipment Actions Features & Traits #brightonSEO @Jammer_Volts
Memory heap: stores the result of script execution (Memory Heap results are added to DOM.) Call stack: queue of sequential next steps (Each entry in the call stack is called a Stack Frame.) Equipment Actions Features & Traits #brightonSEO @Jammer_Volts
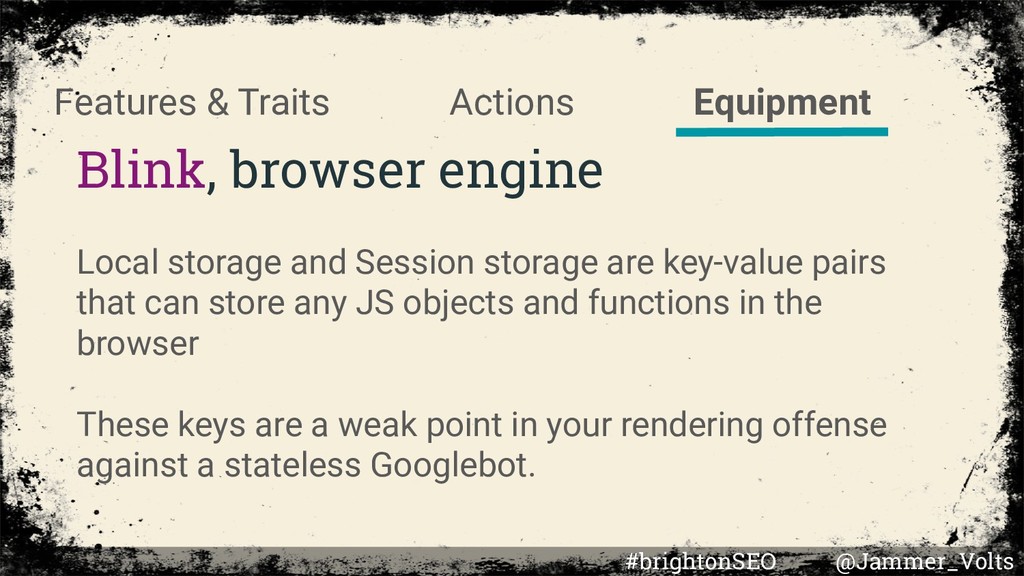
pairs that can store any JS objects and functions in the browser These keys are a weak point in your rendering offense against a stateless Googlebot. Equipment Actions Features & Traits #brightonSEO @Jammer_Volts
entry or execution step is a stack frame. Googlebot can opt run simultaneous parallel connections. Equipment Actions Features & Traits #brightonSEO @Jammer_Volts
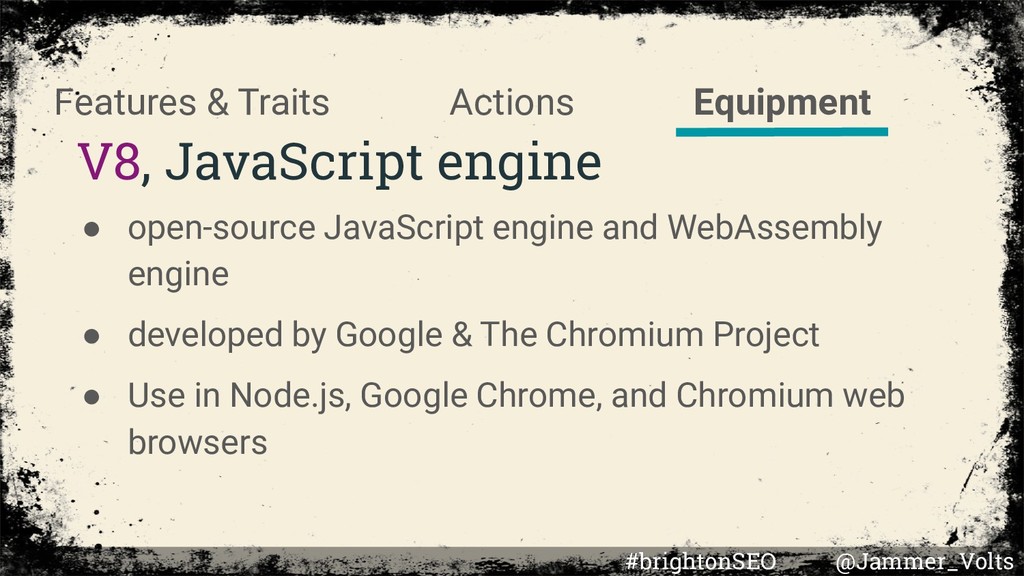
• developed by Google & The Chromium Project • Use in Node.js, Google Chrome, and Chromium web browsers Equipment Actions Features & Traits #brightonSEO @Jammer_Volts
written using the backend of TurboFan • TurboFan, one of V8’s optimizing compilers • Liftoff, a new baseline compiler for WebAssembly Equipment Actions Features & Traits #brightonSEO @Jammer_Volts
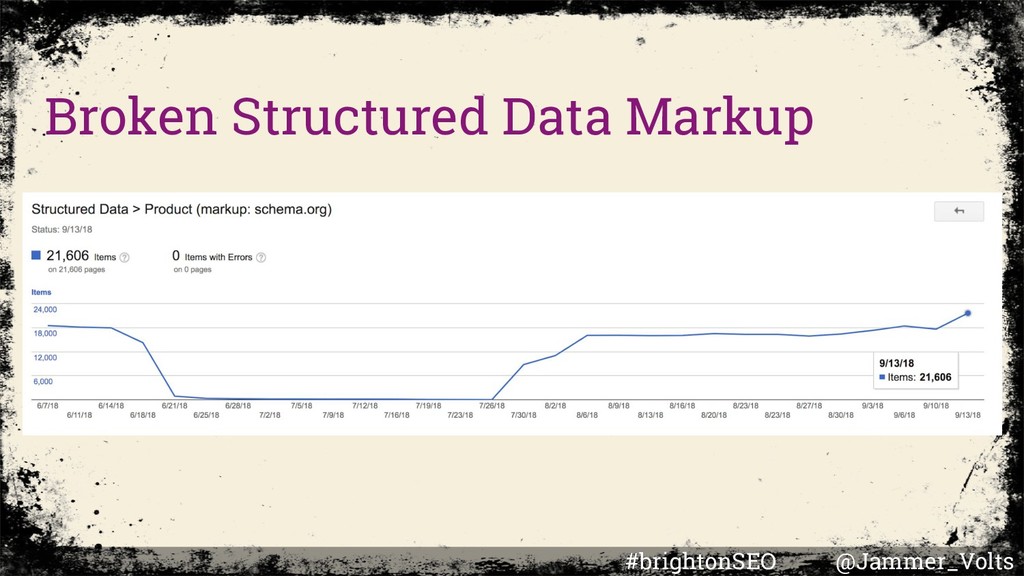
directive in initial HTML to see an index placed in DOM. Duplicative content without a canonical in initial HTML is crawl waste until rendering. Inconsistent title tags and descriptions can result from overwriting the initial HTML with rendered HTML. #brightonSEO @Jammer_Volts
valuable to the construction of the page, add a nofollow directive to resources that are not necessary or beneficial to page construction. #brightonSEO @Jammer_Volts
be fetched independently before the page can be accurately rendered. This is a major part of the issue with client-side rendering. More client-side calls mean more blindspots for you. #brightonSEO @Jammer_Volts
50MB per system If your CSR resources are too large, you risk hitting the upper limit. Elements in queue once the limit is reached may not be considered by Googlebot. #brightonSEO @Jammer_Volts
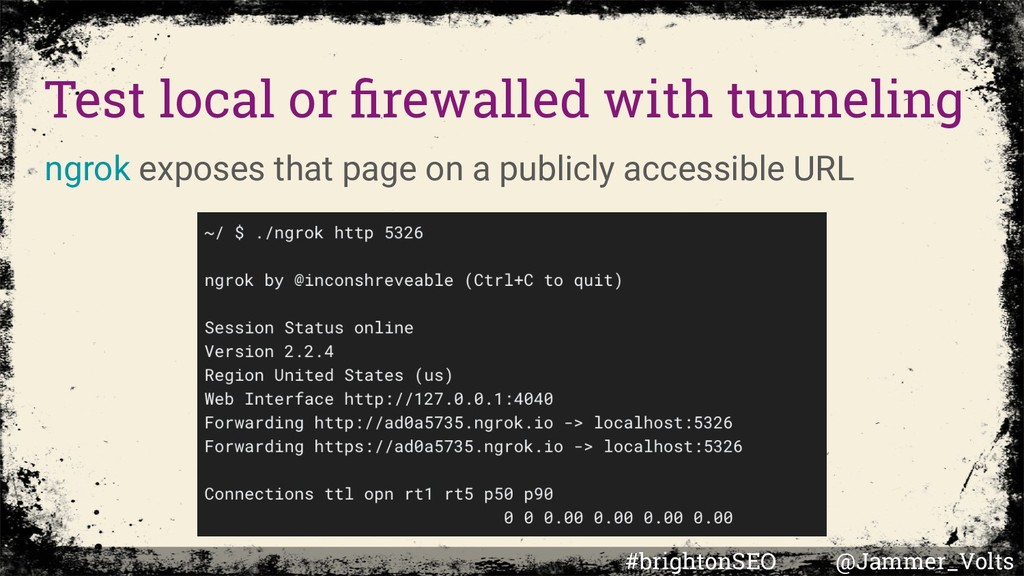
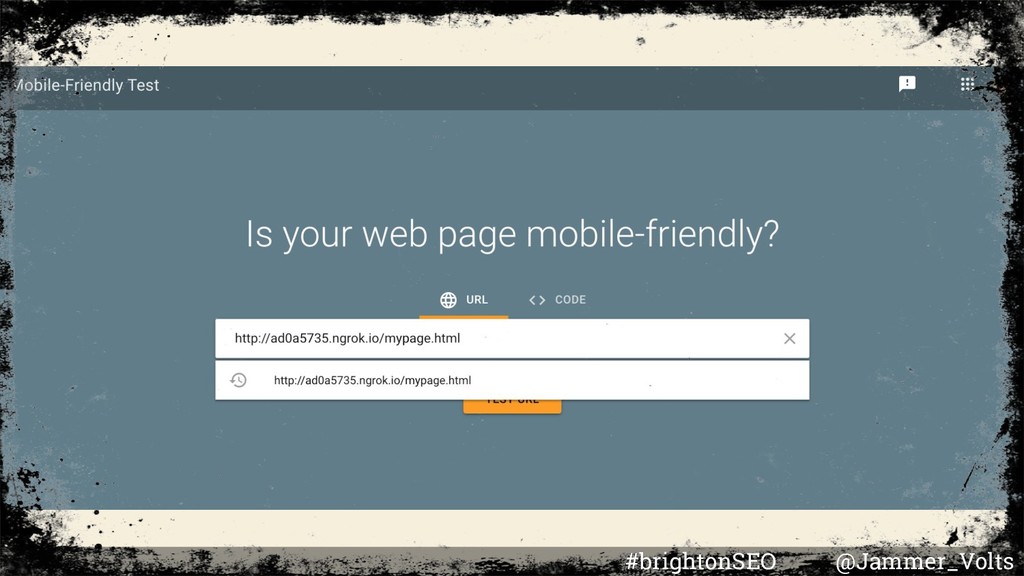
Parsing Standards • Debugging your pages • SimpleHTTPServer • Ngrok • Fix Search-related JavaScript problems • TurboFan overview • Liftover overview • Tame the Bots Portals • Blink Rendering, life of a pixel • The Rendering Critical Path • JavaScript Sites in Search Working Group #brightonSEO @Jammer_Volts
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![SEOs call this Crawl Budget “Simply put, [crawl budget] represents](https://files.speakerdeck.com/presentations/b2a1858a32d04aad8f81231cd77ec313/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}