Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
人工知能学会 データ解析コンペティション振り返り
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
moonlight-aska
July 26, 2018
200
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
人工知能学会 データ解析コンペティション振り返り
2018年7月26日開催の「大阪Pythonの会#16」のLT資料です.
moonlight-aska
July 26, 2018
More Decks by moonlight-aska
See All by moonlight-aska
Create Your Own AI with Dify×Gemma3
aska
0
70
Generative AI Prototyping
aska
0
28
【入門】プロンプトの書き方のコツ / Tips for writing prompts
aska
0
230
CHATGPT。はじめの一歩 / ChatGPT. Get Started
aska
0
150
「Kingyo AI Navi」アプリ / Kingyo AI Navi App
aska
0
280
Kingo AI Navi LINEをもっと使い倒せ!!
aska
0
160
Depth画像で物体検知やってみたー。/ Objects Detection with Depth Images
aska
0
840
Kingyo AI Naviアプリ開発 / Kingyo AI Navi App
aska
0
460
AutoML Vision Edgeで金魚分類モデルを学習してみた / Kingyo Classification Model with AutoML Vision Edge
aska
0
590
Featured
See All Featured
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.9k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
970
Prompt Engineering for Job Search
mfonobong
0
380
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
610
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.7k
A Soul's Torment
seathinner
6
3.1k
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
390
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
620
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Utilizing Notion as your number one productivity tool
mfonobong
4
430
Game over? The fight for quality and originality in the time of robots
wayneb77
1
220
Transcript
JSAI Cup 2018 人工知能学会 データ解析コンペティション振り返り 2018/7/26 Moonlight明日香 大阪Pythonの会 #16 LT
自己紹介 鶴田 彰 外資系メーカー勤務 昔は, ・パターン認識(音声, 文字, etc) ・ユーザ適応(レコメンド, etc)
なども・・・ 最近は, 週末プログラマとして また機械学習に再チャレンジ中! Facebook :moonlight.aska Twitter :@moonlight_aska Blog :みらいテックラボ http://mirai-tec.hatenablog.com
コンテスト概要(1) テーマ:画像認識 クックパッド様の提供する画像データを使用して, 食材の分類の 画像認識アルゴリズムの作成に挑戦 データと評価関数 55種類の食材カテゴリの1つに分類 [学習データ] [テストデータ] ・11,995枚
・3,995枚 [評価関数] Accuracy = :集合Aの要素数 :サンプル数 :i番目の真値 :i番目の予測値 ( = = 1,2, … , )
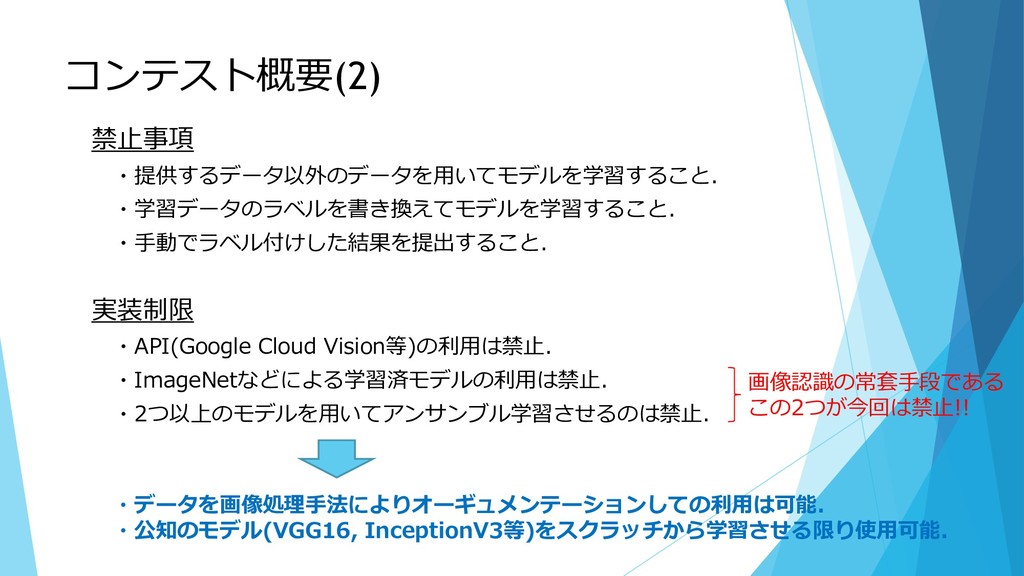
コンテスト概要(2) 禁止事項 ・提供するデータ以外のデータを用いてモデルを学習すること. ・学習データのラベルを書き換えてモデルを学習すること. ・手動でラベル付けした結果を提出すること. 実装制限 ・API(Google Cloud Vision等)の利用は禁止. ・ImageNetなどによる学習済モデルの利用は禁止.
・2つ以上のモデルを用いてアンサンブル学習させるのは禁止. 画像認識の常套手段である この2つが今回は禁止!! ・データを画像処理手法によりオーギュメンテーションしての利用は可能. ・公知のモデル(VGG16, InceptionV3等)をスクラッチから学習させる限り使用可能.
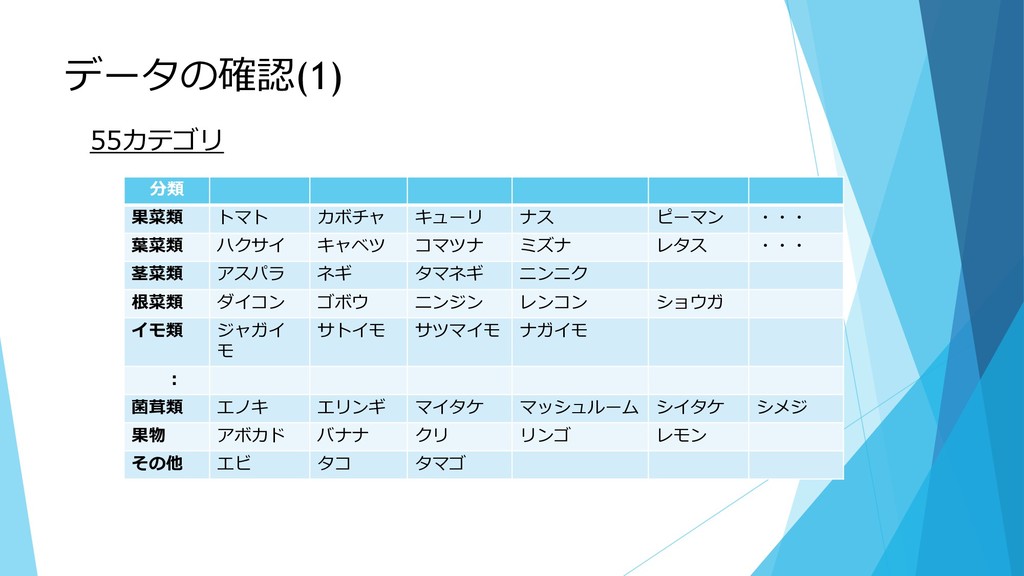
データの確認(1) 55カテゴリ 分類 果菜類 トマト カボチャ キューリ ナス ピーマン ・・・
葉菜類 ハクサイ キャベツ コマツナ ミズナ レタス ・・・ 茎菜類 アスパラ ネギ タマネギ ニンニク 根菜類 ダイコン ゴボウ ニンジン レンコン ショウガ イモ類 ジャガイ モ サトイモ サツマイモ ナガイモ : 菌茸類 エノキ エリンギ マイタケ マッシュルーム シイタケ シメジ 果物 アボカド バナナ クリ リンゴ レモン その他 エビ タコ タマゴ
データの確認(2) データの一例 注) クックパッド様に画像の使用許諾取得済
取組み方針 画像認識で性能upする方法 前処理(高解像度, 正規化, ほか) Data Augmentation
転移学習(FineTuning) Ensemble学習(複数モデル, 複数入力) モデル構造の改良 ハイパーパラメータの調整 : ・公知モデルの使用 ・データオーギュメンテーション ・複数入力によるアンサンブル (Test Time Augmentation)
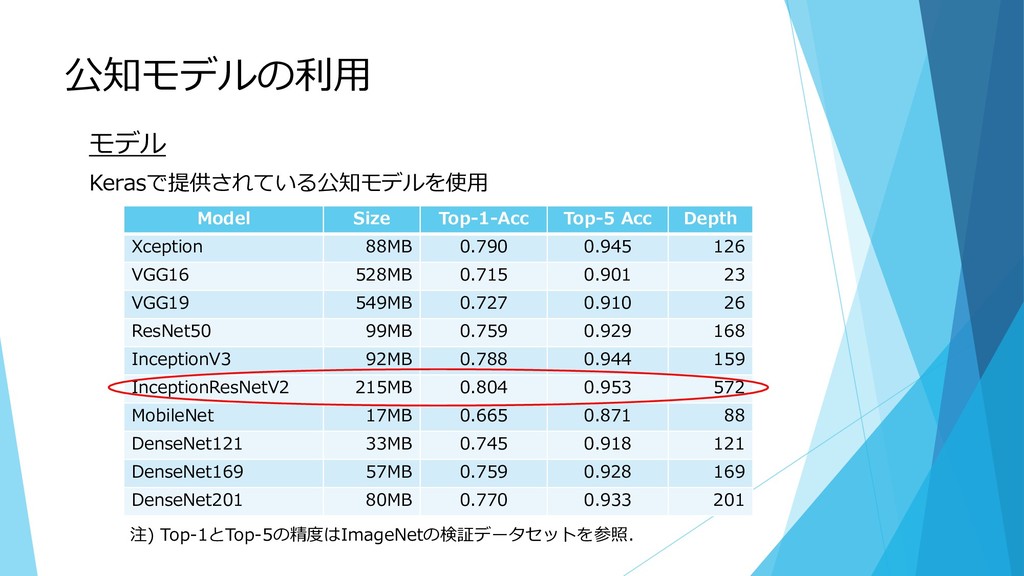
公知モデルの利用 モデル Kerasで提供されている公知モデルを使用 Model Size Top-1-Acc Top-5 Acc Depth Xception
88MB 0.790 0.945 126 VGG16 528MB 0.715 0.901 23 VGG19 549MB 0.727 0.910 26 ResNet50 99MB 0.759 0.929 168 InceptionV3 92MB 0.788 0.944 159 InceptionResNetV2 215MB 0.804 0.953 572 MobileNet 17MB 0.665 0.871 88 DenseNet121 33MB 0.745 0.918 121 DenseNet169 57MB 0.759 0.928 169 DenseNet201 80MB 0.770 0.933 201 注) Top-1とTop-5の精度はImageNetの検証データセットを参照.
Data Augmentation(1) Γ=0.75 Γ=1.5 Original ガンマ補正 平滑化(ぼかし) ホモグラフィ変換 2x2, 4x4
学習データ15倍に!!
Data Augmentation(2) Kerasで提供されている機能を利用 train_data_generator = ImageDataGenerator( preprocessing_function=preprocess_input, rotation_range=90, width_shift_range=0.2, height_shift_range=0.2,
shear_range = 0.2, zoom_range = [0.9, 1.3], fill_mode='nearest', horizontal_flip = True, vertical_flip = True) ・・・90度まで回転 ・・・20%まで水平シフト ・・・20%まで垂直シフト ・・・0.2ラジアンまでシアー変換 ・・・0.9~1.3までズーム ・・・水平方向に反転 ・・・垂直方向に反転
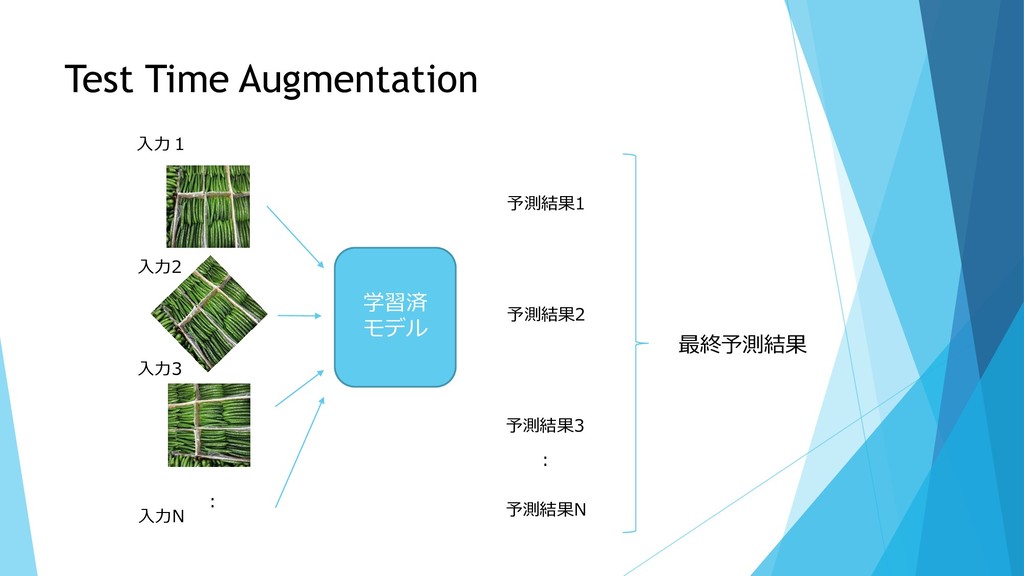
Test Time Augmentation 学習済 モデル : 予測結果1 予測結果2 予測結果3 入力1
入力2 入力3 入力N 予測結果N : 最終予測結果
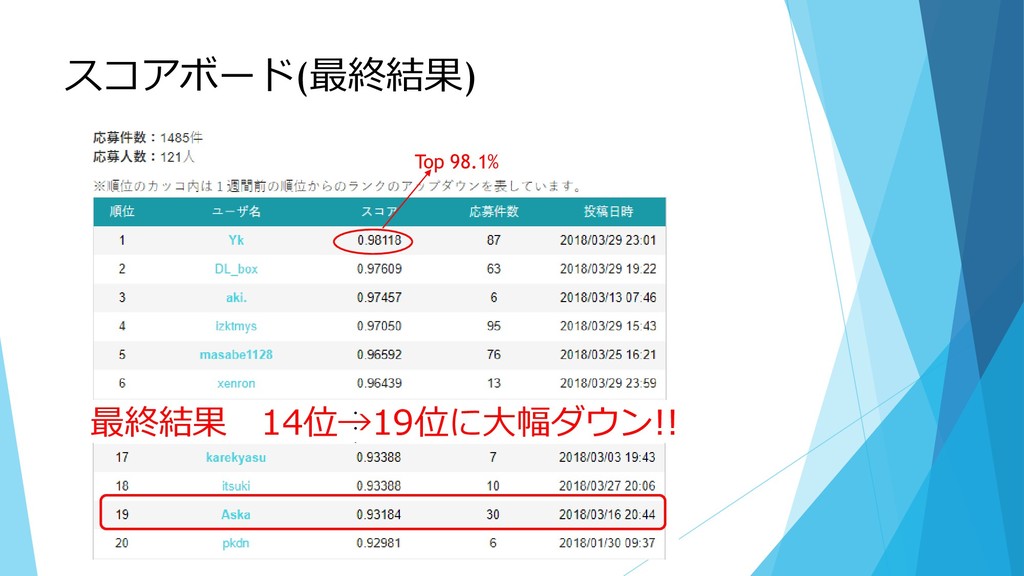
スコアボード(最終結果) ・ ・ ・ 最終結果 14位→19位に大幅ダウン!! Top 98.1%
記事をもとに振り返り http://tech.nikkeibp.co.jp/atcl/nxt/column/18/00323/061600003/?P=1
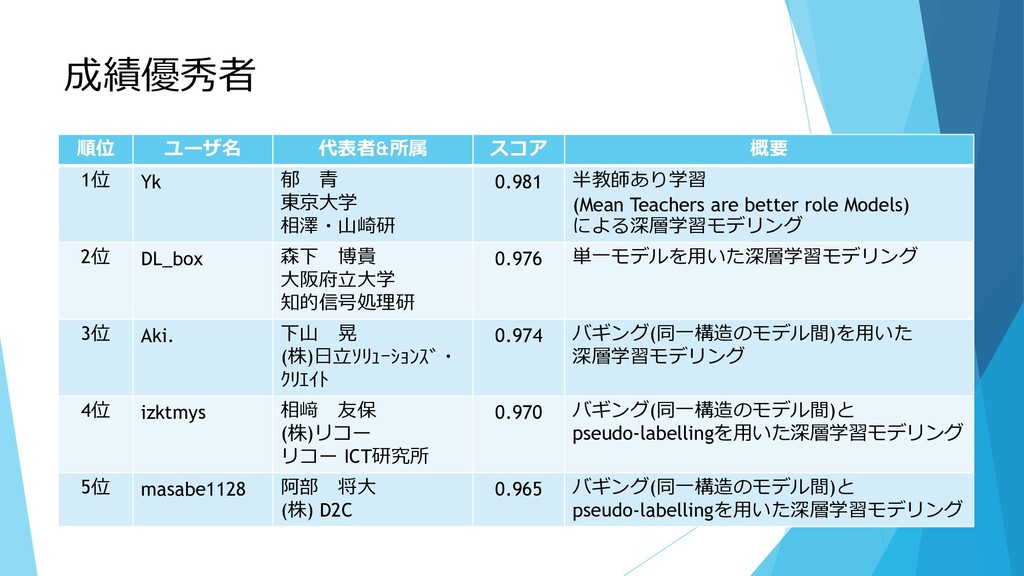
成績優秀者 順位 ユーザ名 代表者&所属 スコア 概要 1位 Yk 郁 青
東京大学 相澤・山崎研 0.981 半教師あり学習 (Mean Teachers are better role Models) による深層学習モデリング 2位 DL_box 森下 博貴 大阪府立大学 知的信号処理研 0.976 単一モデルを用いた深層学習モデリング 3位 Aki. 下山 晃 (株)日立ソリューションズ・ クリエイト 0.974 バギング(同一構造のモデル間)を用いた 深層学習モデリング 4位 izktmys 相﨑 友保 (株)リコー リコー ICT研究所 0.970 バギング(同一構造のモデル間)と pseudo-labellingを用いた深層学習モデリング 5位 masabe1128 阿部 将大 (株) D2C 0.965 バギング(同一構造のモデル間)と pseudo-labellingを用いた深層学習モデリング
入賞者の手法(1) Data Augmentation 1. Random Erasing Data Augmentation (2017/8) 2.
mixup : Beyond Empirical Risk Minimization (2017/10) 0.7 * dog + 0.3 * cat
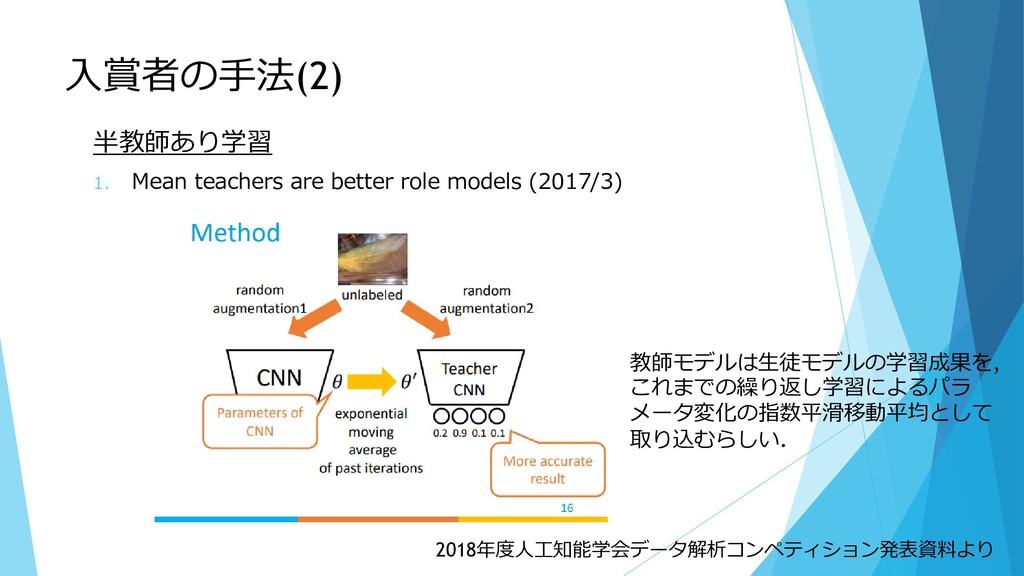
入賞者の手法(2) 半教師あり学習 1. Mean teachers are better role models (2017/3)
教師モデルは生徒モデルの学習成果を, これまでの繰り返し学習によるパラ メータ変化の指数平滑移動平均として 取り込むらしい. 2018年度人工知能学会データ解析コンペティション発表資料より
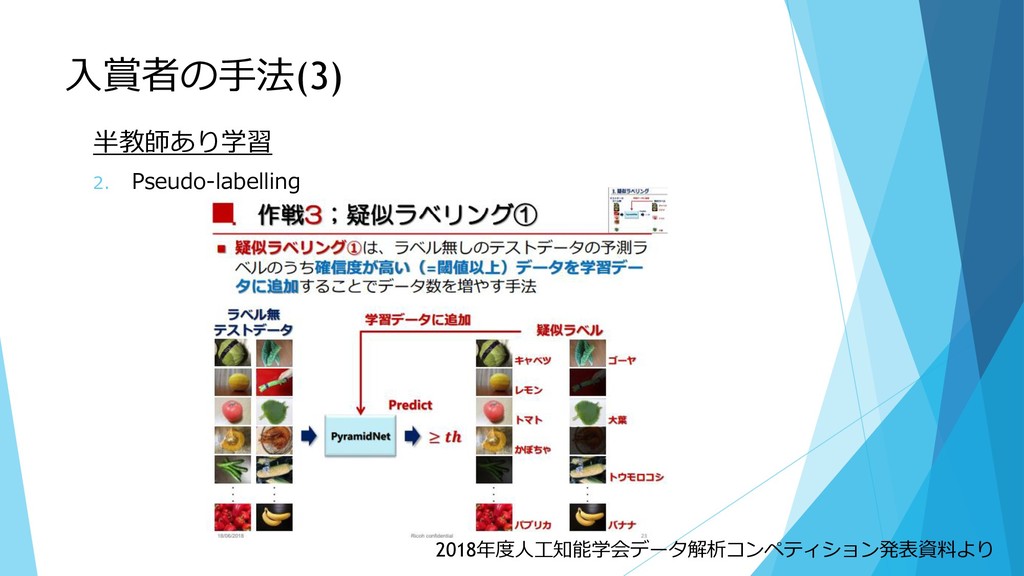
入賞者の手法(3) 半教師あり学習 2. Pseudo-labelling 2018年度人工知能学会データ解析コンペティション発表資料より
振り返って思うこと Data Augmentationで頑張ること自体は間違っていな かった. 最新手法のキャッチアップは重要!! テストデータを学習に使うという発想が出なかった. (Pseudo-labelling自体は, 昨年のコンペで活用済)
Thank You!
{kind=link}
{kind=link}
![コンテスト概要(1) テーマ:画像認識 クックパッド様の提供する画像データを使用して, 食材の分類の 画像認識アルゴリズムの作成に挑戦 データと評価関数 55種類の食材カテゴリの1つに分類 [学習データ] [テストデータ] ・11,995枚](https://files.speakerdeck.com/presentations/2e39362ec1bc4726b4f50947fe9073f3/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}