Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
在庫の最適化を実現する SaaSデータ基盤の裏側
Search
Atsushi Yokota
December 12, 2023
Programming
250
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
在庫の最適化を実現する SaaSデータ基盤の裏側
[大阪オフィス現地開催] 目指せ日本の西海岸!関西スタートアップの AWS 活用事例 登壇資料
Atsushi Yokota
December 12, 2023
More Decks by Atsushi Yokota
See All by Atsushi Yokota
Athenaで実現する時系列データのパフォーマンス改善
atsuyokota
0
240
Rust on Lambda 大きめCSV生成
atsuyokota
3
1.6k
Other Decks in Programming
See All in Programming
なぜ関数型プログラミングで「型」と「証明」が語られるのか #fp_matsuri
kajitack
3
1k
変わらないものが、変わるものを決める — 意図駆動開発 × イベントソーシング × イミュータブル | What Doesn't Change Decides What Can — IDD × Event Sourcing × Immutability
tomohisa
0
320
The Past, Present, and Future of Enterprise Java
ivargrimstad
0
400
才能?センス?知らん、 続けたもん勝ちだ。-- 結婚・出産・癌を越えてなお、私がプロダクトを創り続ける理由
16bitidol
2
910
AI時代の仕事技芸論〜ソフトウェア開発で「遊ぶように働く」職人的熟達のすすめ(スクフェス仙台 2026バージョン)
kuranuki
0
720
ITヒヤリハットを整理してみた ~ライフサイクルと原因から考える再発防止策~
koukimiura
1
110
AWS CDK を「作」ってみた 〜フルスクラッチで見えた CDK の裏側〜 / aws-cdk-from-scratch
gotok365
3
2.4k
継続モナドとリアクティブプログラミング
yukikurage
3
640
Go言語とトイモデルで学ぶTransformerの気持ち / fukuokago23-transformer
monochromegane
0
140
任せる範囲はこう広がった / How the Scope of AI Delegation Has Expanded
nrslib
1
280
音楽のための関数型プログラミング言語mimiumにおける多段階計算の活用
tomoyanonymous
1
360
Claude Opus 4.6以後の受託開発エンジニアの変化(Claude Code開発ノウハウ大公開スペシャルbyクラスメソッド)
iidatakuma
1
860
Featured
See All Featured
Java REST API Framework Comparison - PWX 2021
mraible
34
9.5k
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
The Curious Case for Waylosing
cassininazir
1
440
A designer walks into a library…
pauljervisheath
211
24k
Designing Powerful Visuals for Engaging Learning
tmiket
1
460
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
WENDY [Excerpt]
tessaabrams
11
39k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
390
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
220
Technical Leadership for Architectural Decision Making
baasie
3
450
Transcript
在庫の最適化を実現する SaaSデータ基盤の裏側 フルカイテン株式会社 横田
Atsushi Yokota バックエンドエンジニア 2 • 2020年10月よりフルカイテンに参画。 • FULL KAITEN V3の新規開発に携わり、Rustによる
GraphQLサーバーの構築やデータ基盤の構築を担当 • バックエンドグループマネージャー 自己紹介
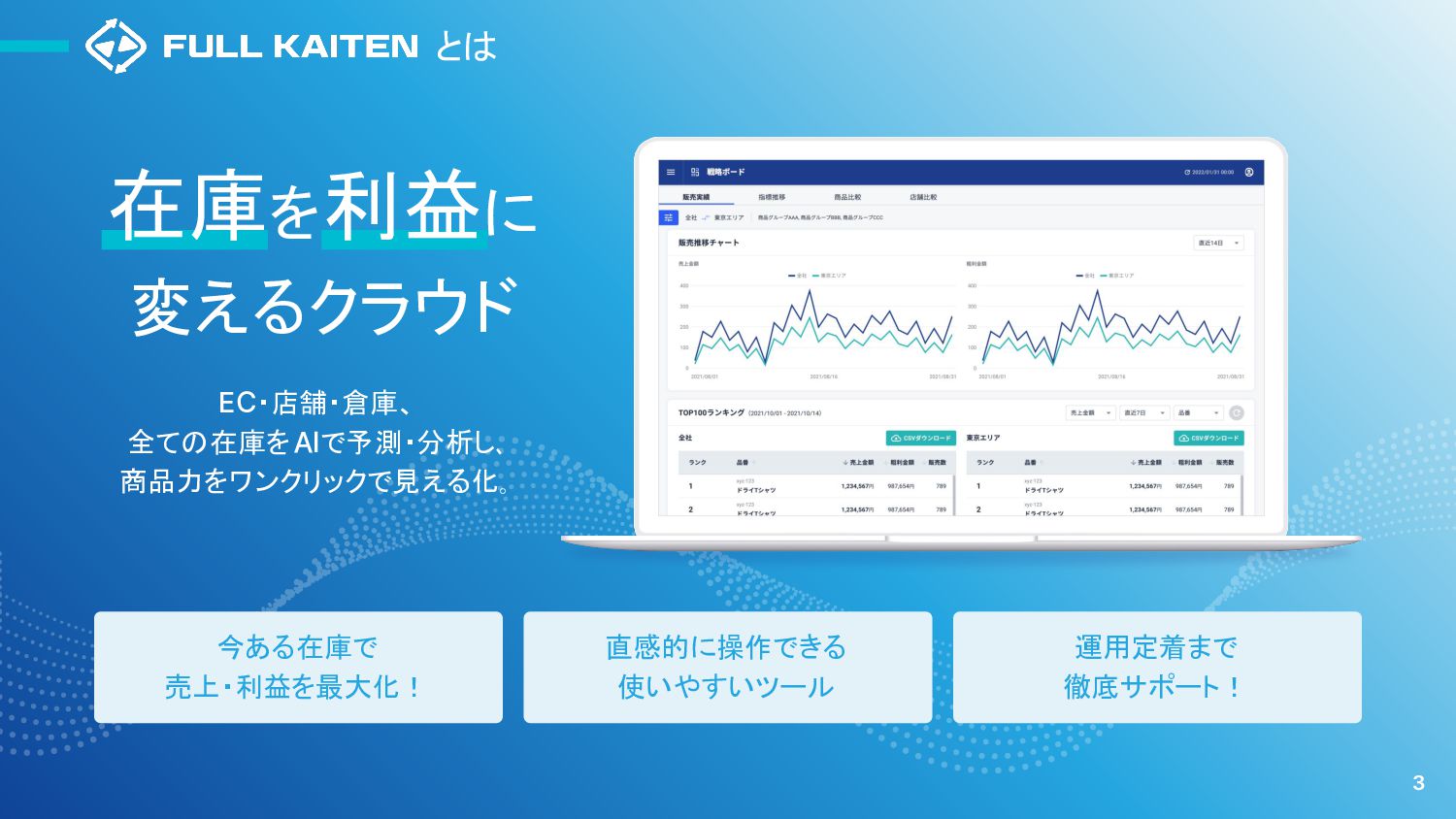
3 在庫を利益に 変えるクラウド 今ある在庫で 売上・利益を最大化! 直感的に操作できる 使いやすいツール 運用定着まで 徹底サポート! EC・店舗・倉庫、
全ての在庫をAIで予測・分析し、 商品力をワンクリックで見える化。 とは
4 導入実績 ※一部抜粋/順不同 ※2023年10月時点
1. データ基盤の重要ポイント 2. リリース当初のアーキテクチャー 3. 刷新後のアーキテクチャー 4. 刷新の結果 5. 今後の展望
Agenda
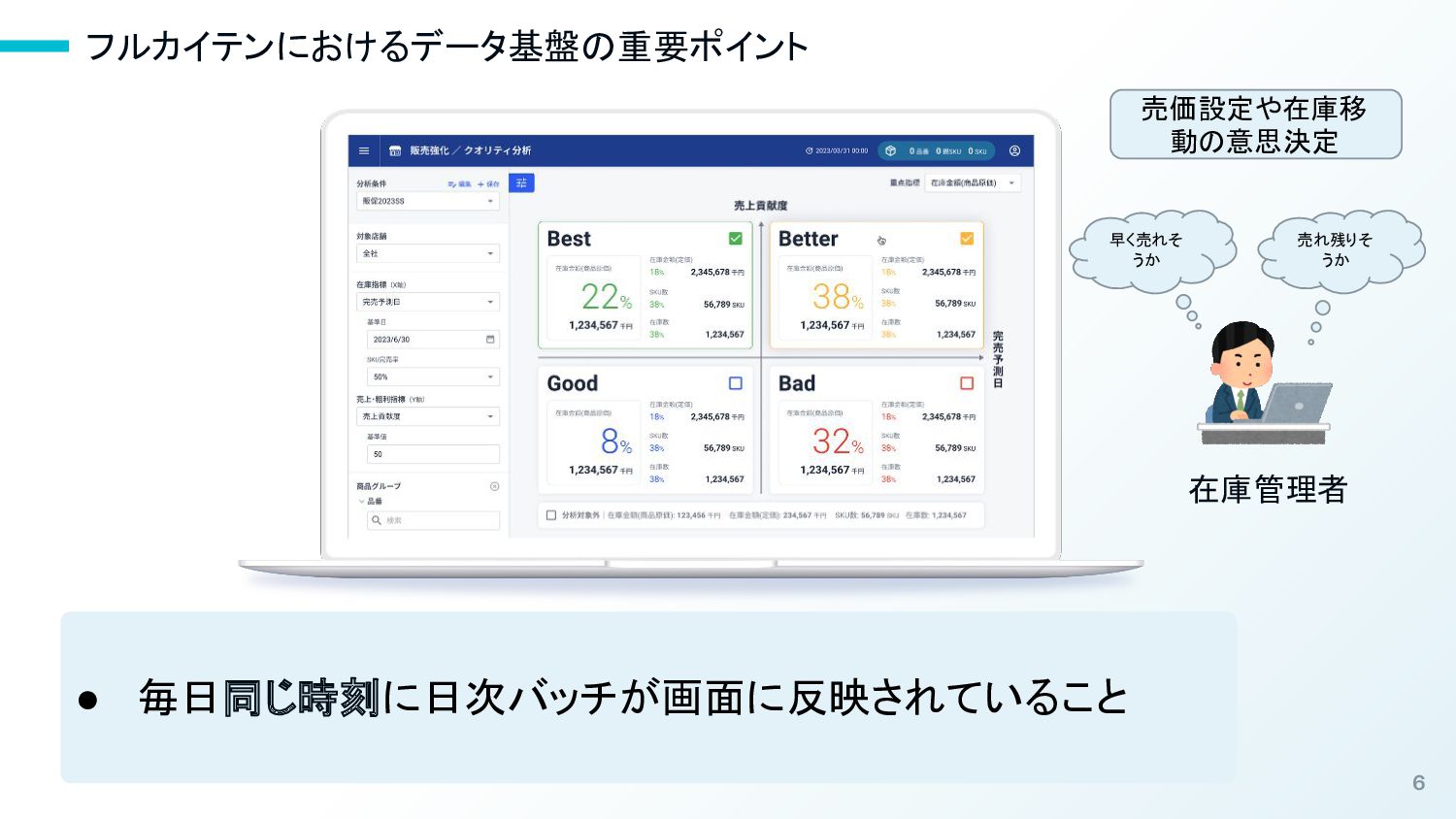
6 フルカイテンにおけるデータ基盤の重要ポイント • 毎日同じ時刻に日次バッチが画面に反映されていること 在庫管理者 売価設定や在庫移 動の意思決定 早く売れそ うか 売れ残りそ
うか
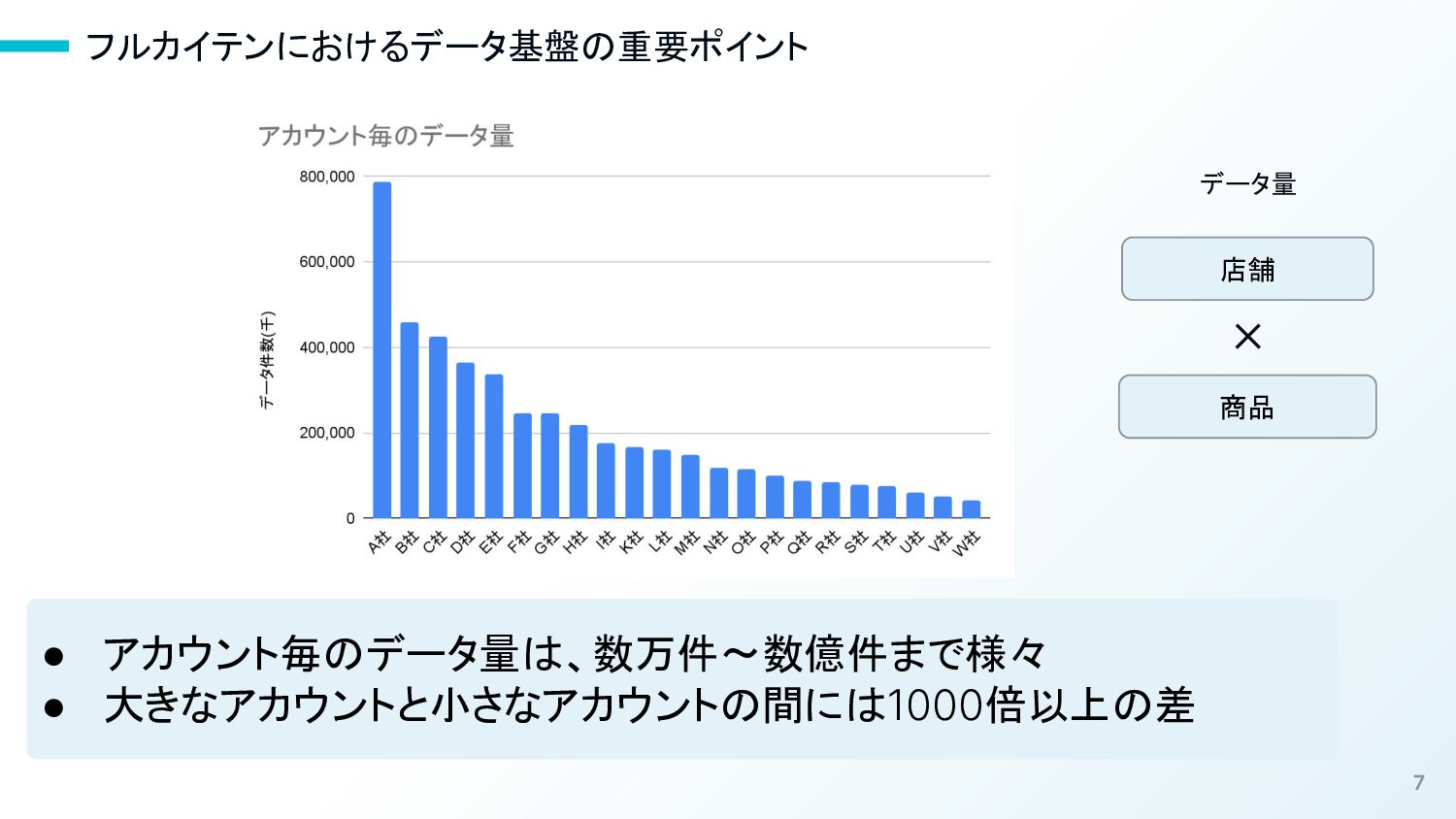
7 フルカイテンにおけるデータ基盤の重要ポイント • アカウント毎のデータ量は、数万件〜数億件まで様々 • 大きなアカウントと小さなアカウントの間には1000倍以上の差 店舗 商品 ✕ データ量
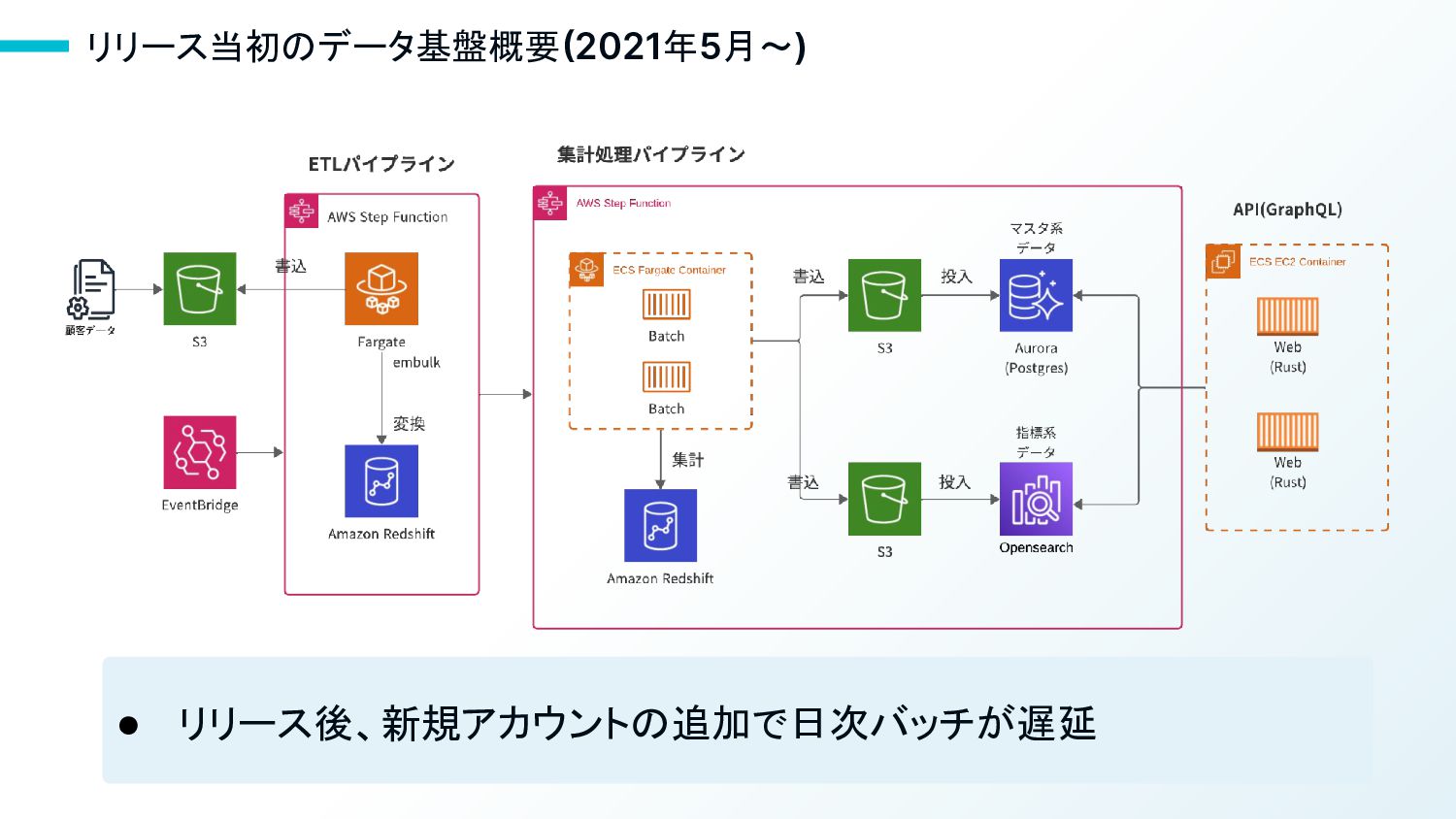
8 リリース当初のデータ基盤概要(2021年5月〜)
リリース当初のデータ基盤概要(2021年5月〜) • リリース後、新規アカウントの追加で日次バッチが遅延
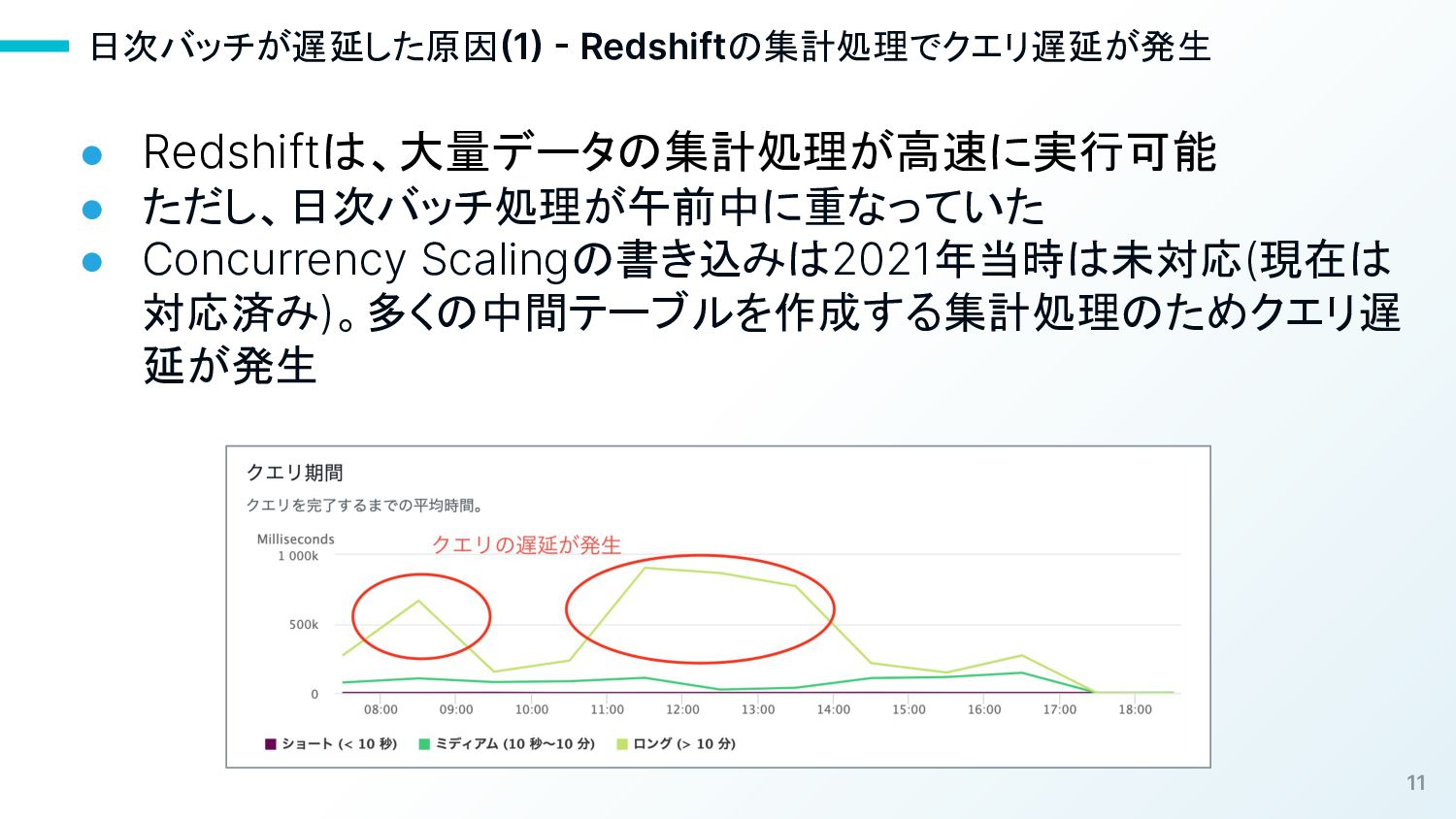
日次バッチが遅延した原因(1) Redshiftの集計処理でクエリ遅延が発生
11 日次バッチが遅延した原因(1) - Redshiftの集計処理でクエリ遅延が発生 • Redshiftは、大量データの集計処理が高速に実行可能 • ただし、日次バッチ処理が午前中に重なっていた • Concurrency
Scalingの書き込みは2021年当時は未対応(現在は 対応済み)。多くの中間テーブルを作成する集計処理のためクエリ遅 延が発生
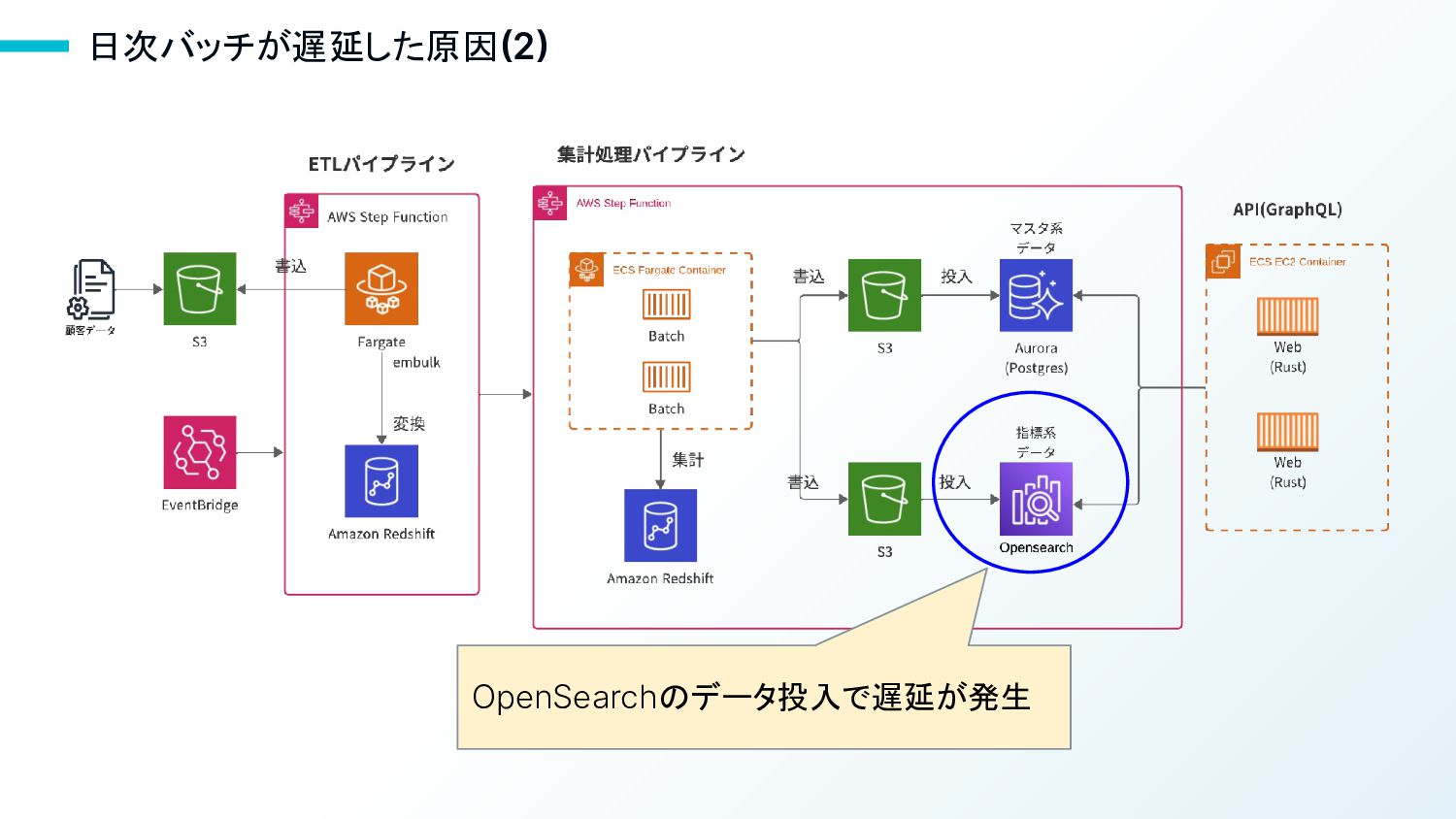
日次バッチが遅延した原因(2) OpenSearchのデータ投入で遅延が発生
13 日次バッチが遅延した原因(2) - OpenSearchのデータ投入で遅延が発生 • 大量データのソート、フィルタリングは非常に高速 • ただし、インデックス作成に時間がかかり、大量データの投入が重な るとエラーが発生することがある •
結果、データの投入待ち時間が長くなり、日次バッチにかかる時間の 40%を占める状況になった
14 問題点のまとめ • 新規アカウントが増加するにつれて、リソースの奪い合いが発生 • 大きめのアカウント(約3.5億件)で画面反映まで、毎日15時間もかかる 状態 • データ量の小さなお客様もバッチ処理の反映が遅くなるようになっ た。。
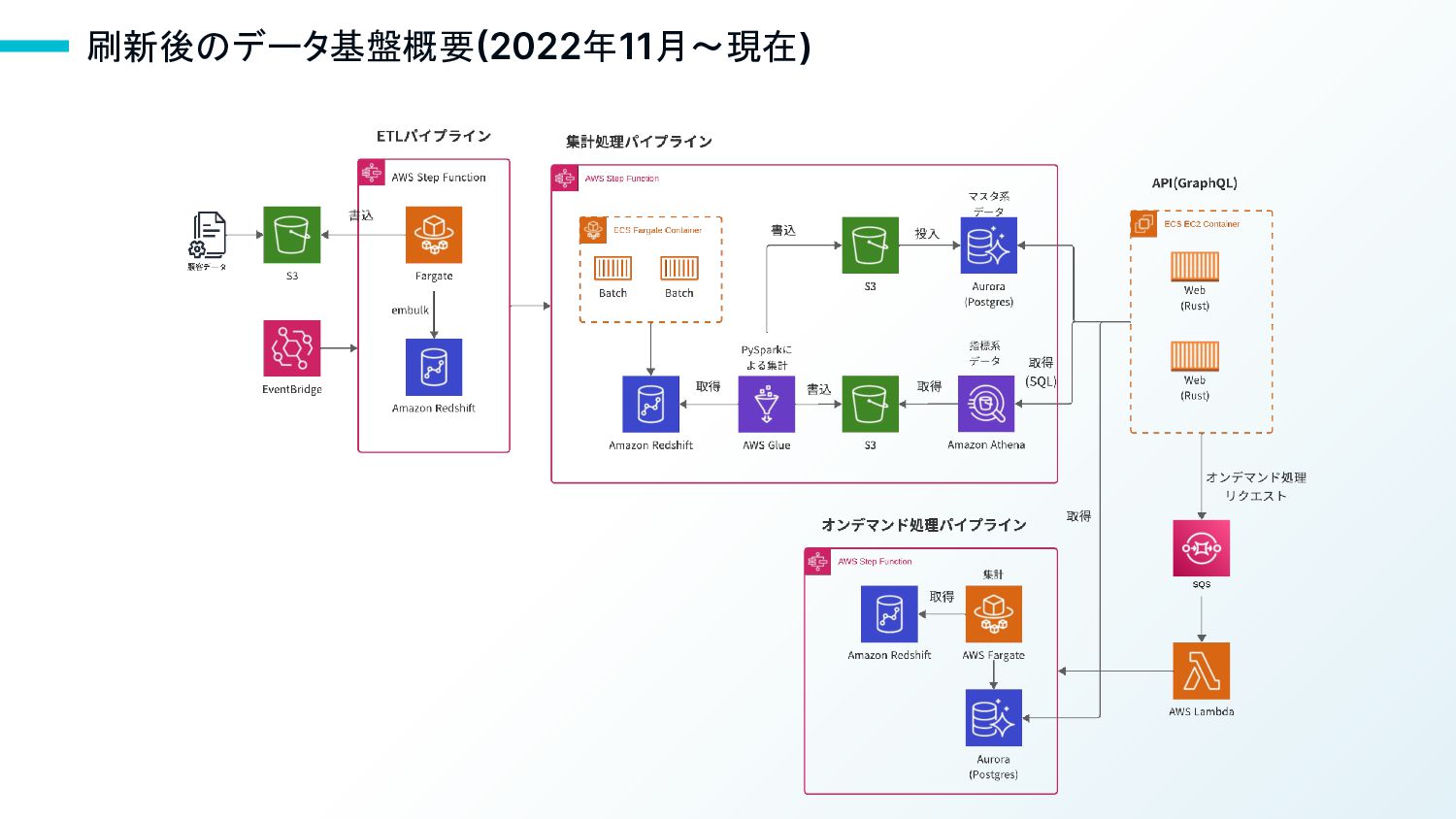
15 刷新後のデータ基盤概要(2022年11月〜現在)
刷新後のデータ基盤概要(2022年11月〜現在)
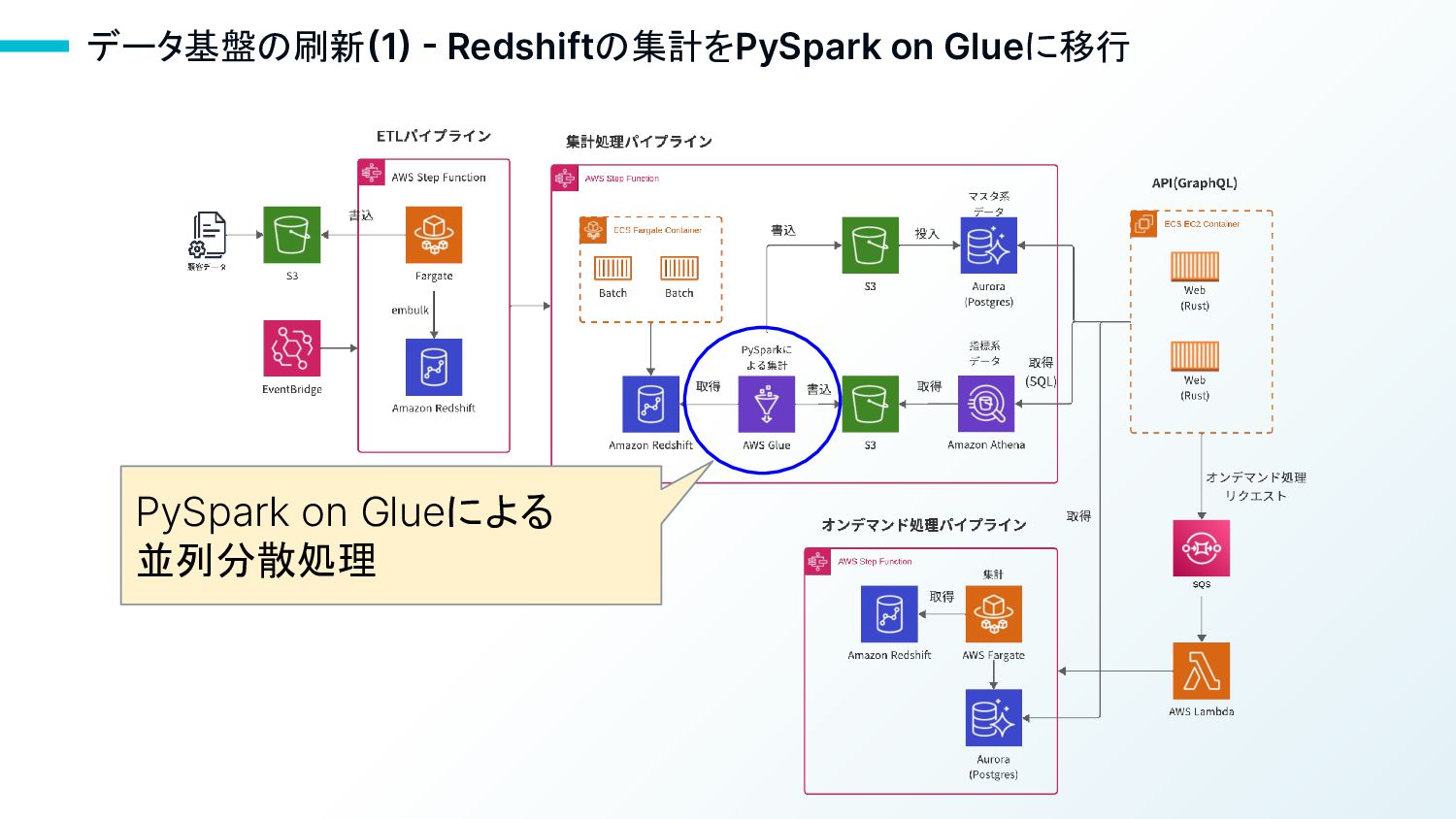
データ基盤の刷新(1) - Redshiftの集計をPySpark on Glueに移行 PySpark on Glueによる 並列分散処理
18 Redshiftの集計をPySpark on Glueに移行した理由 • 複雑な集計処理が多く、中間テーブルの作成が必要であるため、メモ リ上での集計を行うPySpark on Glueの方が処理速度が速い •
サーバレスのGlueを使用することで、他のアカウントの影響を受 けることなく、並列分散処理が可能 • アカウント毎にワーカー数を指定することで、インフラコストを最適化 することが可能
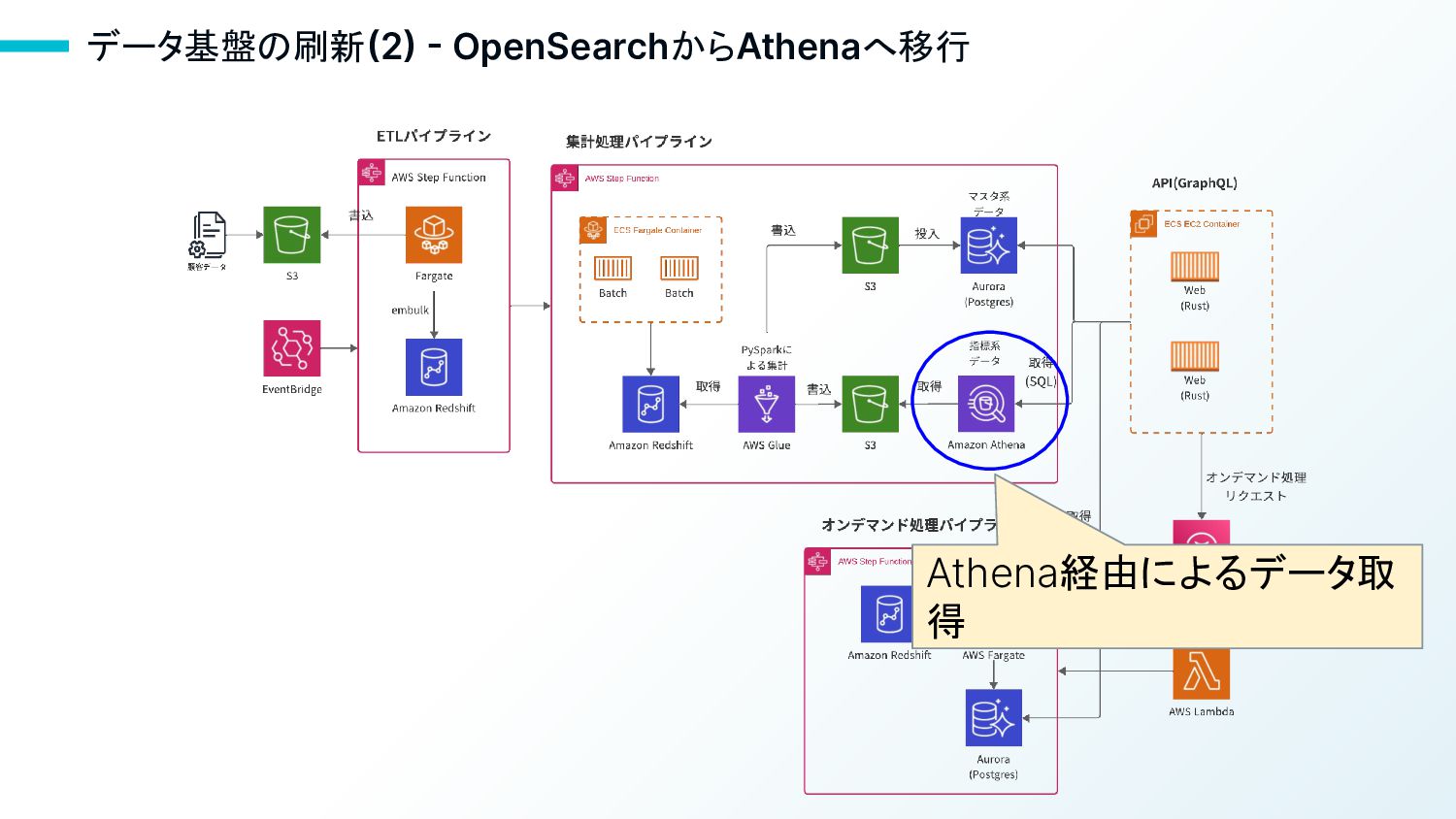
データ基盤の刷新(2) - OpenSearchからAthenaへ移行 Athena経由によるデータ取 得
20 OpenSearchからAthenaへ移行した理由 • S3に格納されたデータを直接SQLでリクエストできるため、データ投入が 不要 • リクエスト毎にリソースが割り当てられるため、重いリクエストも並列で実行す ることが可能 • FederatedQueryを使用することで、Auroraを含む他のデータストアと結合
可能 書込 Parquet ファイル Glue Athena 取得 SQL Aurora
Athena導入の注意点 • ソートやフィルタリング処理は、OpenSearchの方が速いことが多い • 少量のデータに対してもレスポンス時間がかかる ◦ S3のExpress One Zoneで早くなるらしい トレードオフがあるので、
ユースケースに合わせた検討が必要
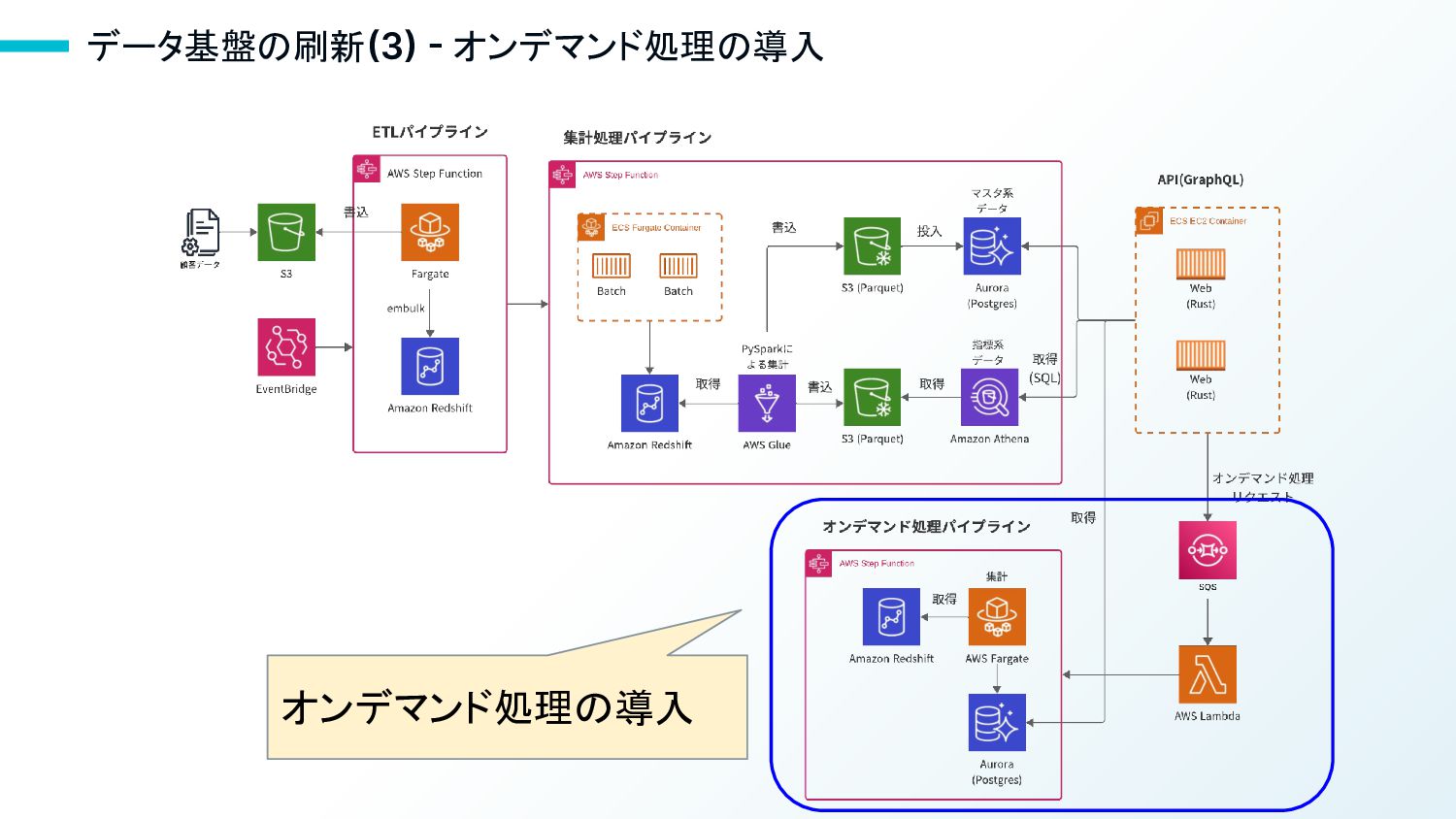
データ基盤の刷新(3) - オンデマンド処理の導入 オンデマンド処理の導入
23 オンデマンド処理の導入理由 • ユーザーからのリクエストに応じて、必要な集計処理を行うオンデマ ンド処理に対応 • 日次バッチを待たずにアドホックな分析が可能になり、ユーザー体験 が向上した • 参照頻度の低い日次集計をオンデマンド処理に移行
• Fargateの最大vCPU16個、メモリ128GiBに大幅拡張(2022年9 月)。これにより、ある程度のデータ量でもPandasで処理できるように なった。
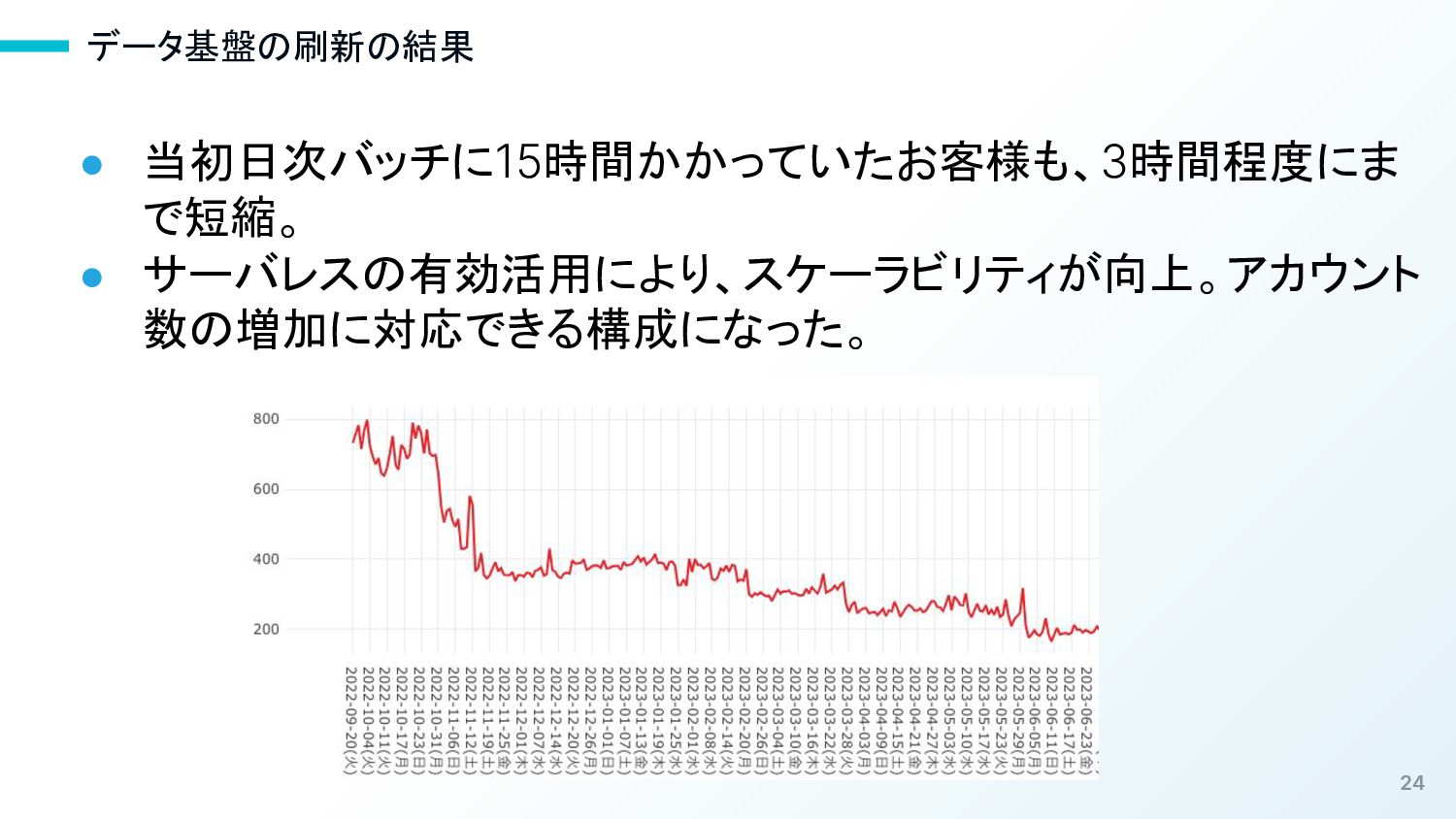
24 データ基盤の刷新の結果 • 当初日次バッチに15時間かかっていたお客様も、3時間程度にま で短縮。 • サーバレスの有効活用により、スケーラビリティが向上。アカウント 数の増加に対応できる構成になった。
25 今後の展望 • アーキテクチャーの再編 ◦ オンデマンド処理への移行 ◦ Glueジョブの分割 • パフォーマンス・チューニング
◦ データ構造の見直し ◦ Glueのworkerの自動設定 • 機械学習のライフサイクル管理 • サービスとして横断的なデータ解析 プロダクトの状況は日々変化する データ基盤の作り替えも積極的に行う
エンジニア募集中! 一緒に世界の大量廃棄問題を解決しましょう! https://note.com/fullkaiten_re フルカイテン公式note
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}