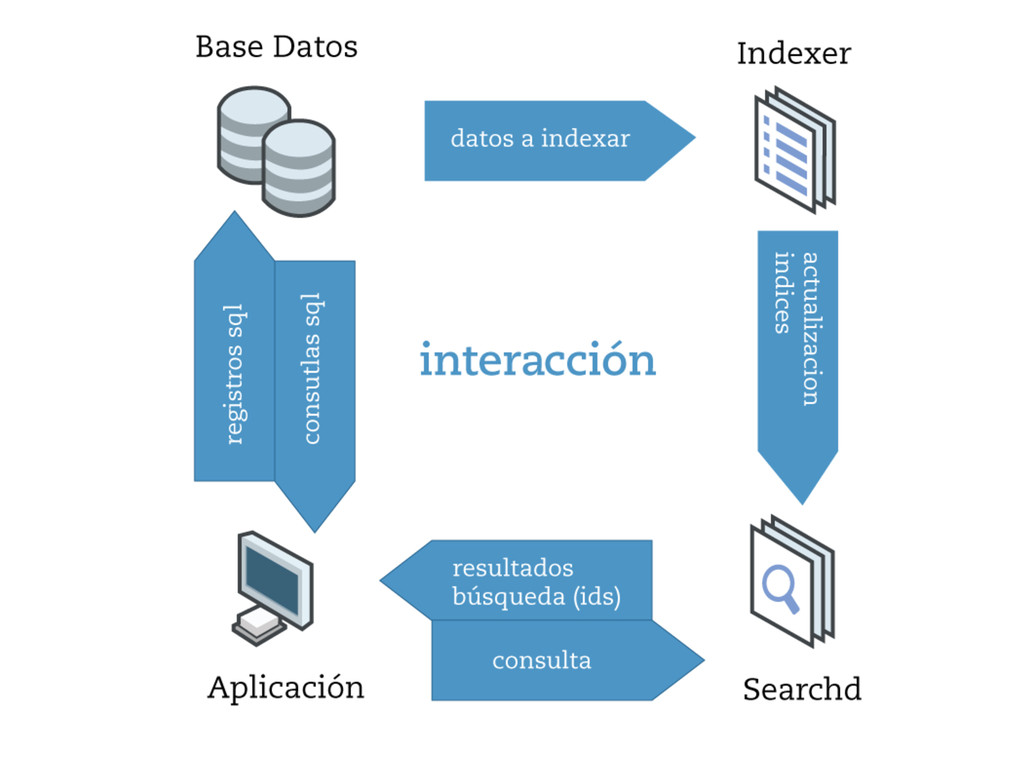
• no solo indexa textos (atributos numericos para filtrar) • puede trabajar como reemplazo de mysql para ordenar y agrupar • selección de operadores y “matching modes”
MySQL • no actualiza los índices solo • sphinx solo devuelve ids • permite ordenar por relevancia • exact search / boolean search / … • API en varios lenguajes • implementa protocolo MySQL
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
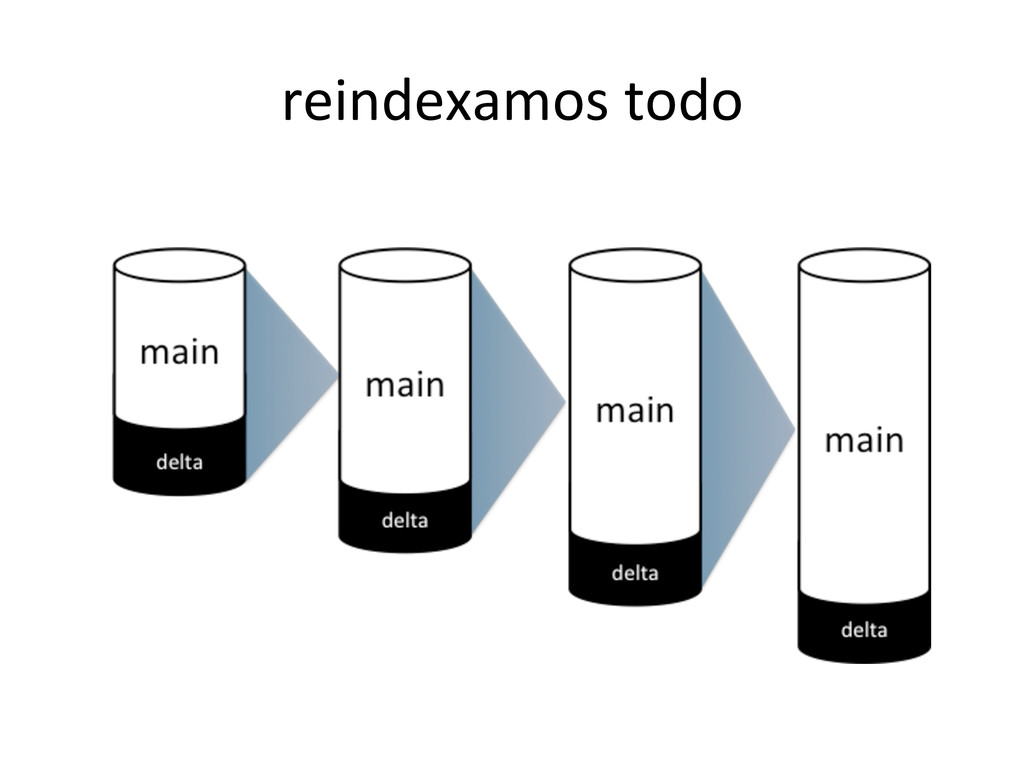{kind=link}
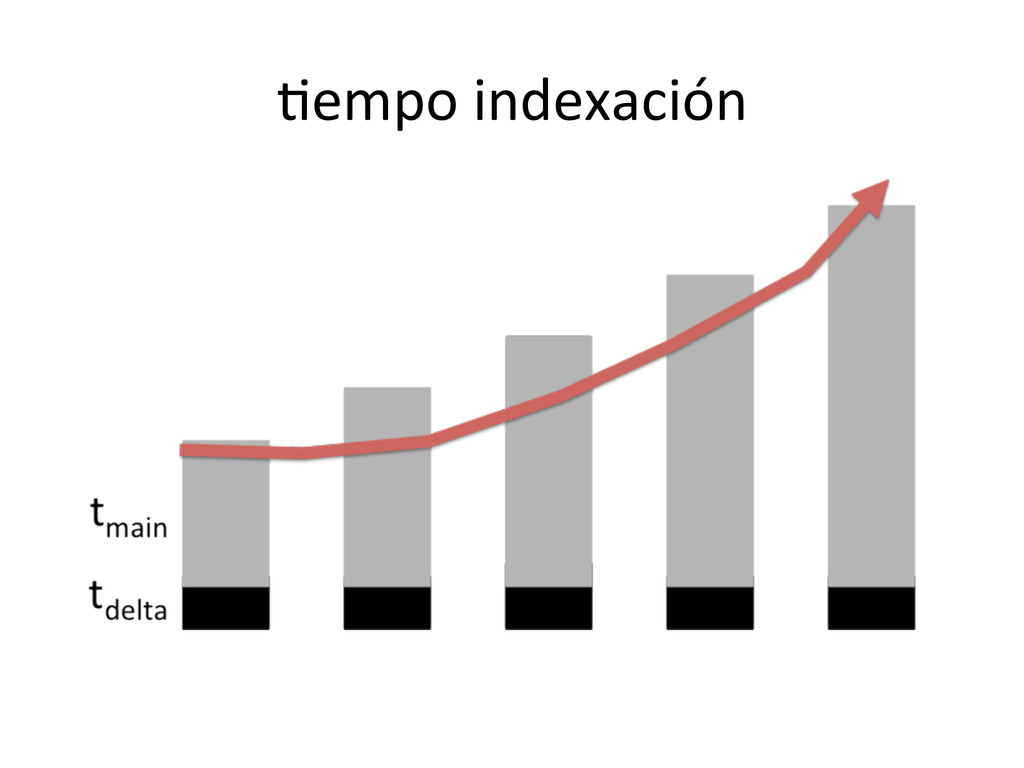{kind=link}
{kind=link}
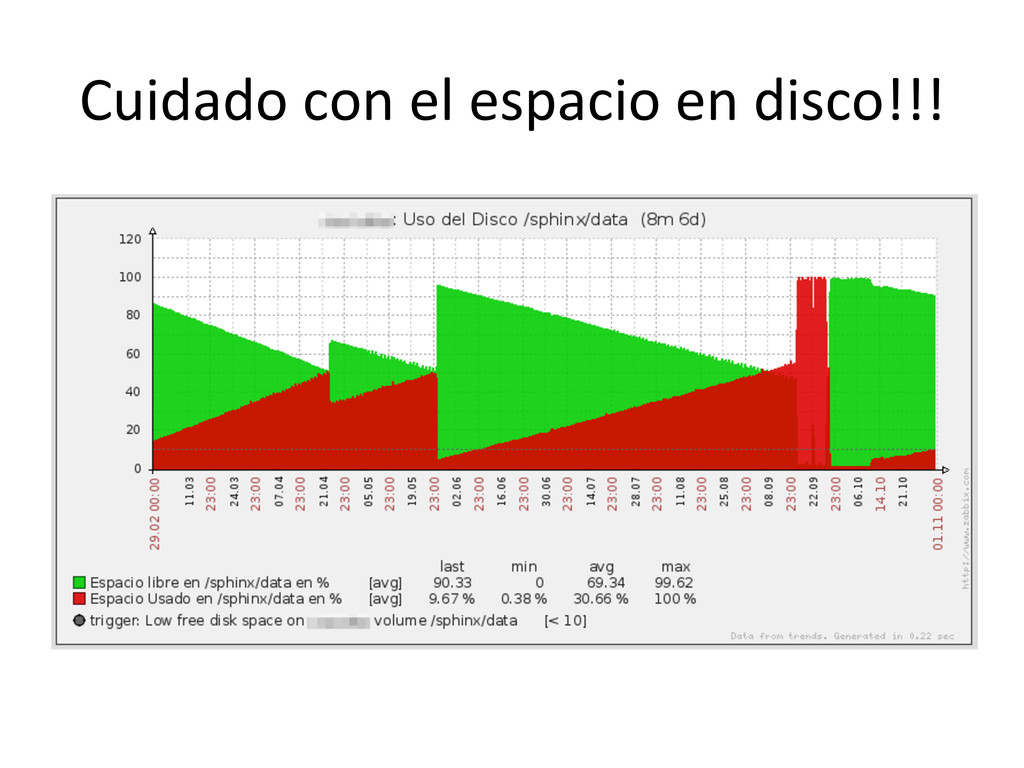{kind=link}
{kind=link}
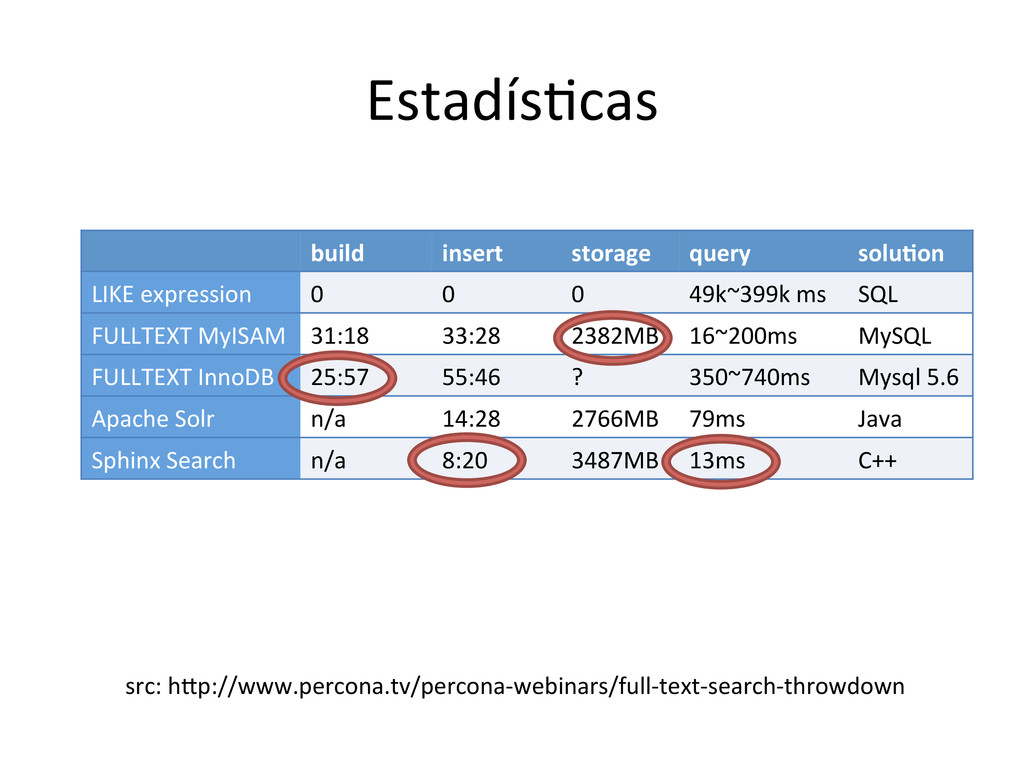{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}