new users each month • Static storage is over 150TB of data – Adding over 1TB of files every day • 3 Data centers + 2 Clouds (Google AE, Amazon) – Around 300 servers • Over 100,000,000 Server API calls per day • Over 450 people work at Wix – ~ 150 people in R&D 07:29
OS level, not application level* • Does not know when there is a problem with the application (the majority of problems) • Hard to manage in a large scale environment Pros • Monitor machine health • Built-in integration with Graphite • Custom checks
to read, Not friendly to developers • Pinpointing the problem takes long time • Server cluster need log aggregation • Helpful mostly in retrospect investigation • Most developers don’t know how to configure logs properly Pros • Verbose and flexible
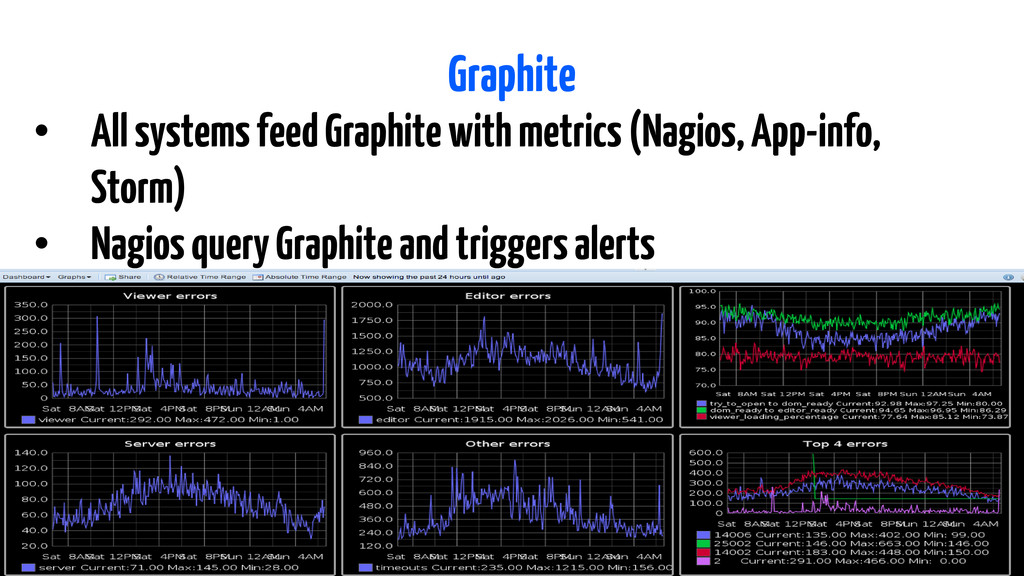
dashboard on top of it) • Design data schema (hierarchy) in advance • Difficult to get scaling right Pros • Numerous formulas available • Share graphs • Easy to create new graphs
• Service level overview (both cluster and single server) • Customizable dashboards • JVM profiler on production • Code instrumentation • Real User Monitoring • Hardware monitoring
specific server • No exception classification • A lot of false alarms due to misbehaving bots • False alarms for low throughput services • Hard to pinpoint a problematic server / operation
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
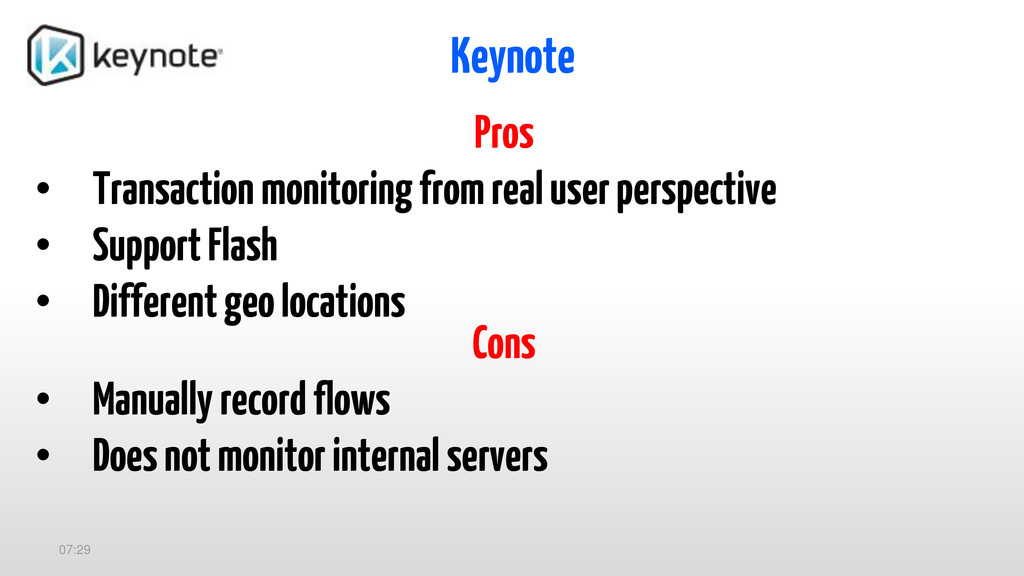{kind=link}
{kind=link}
{kind=link}
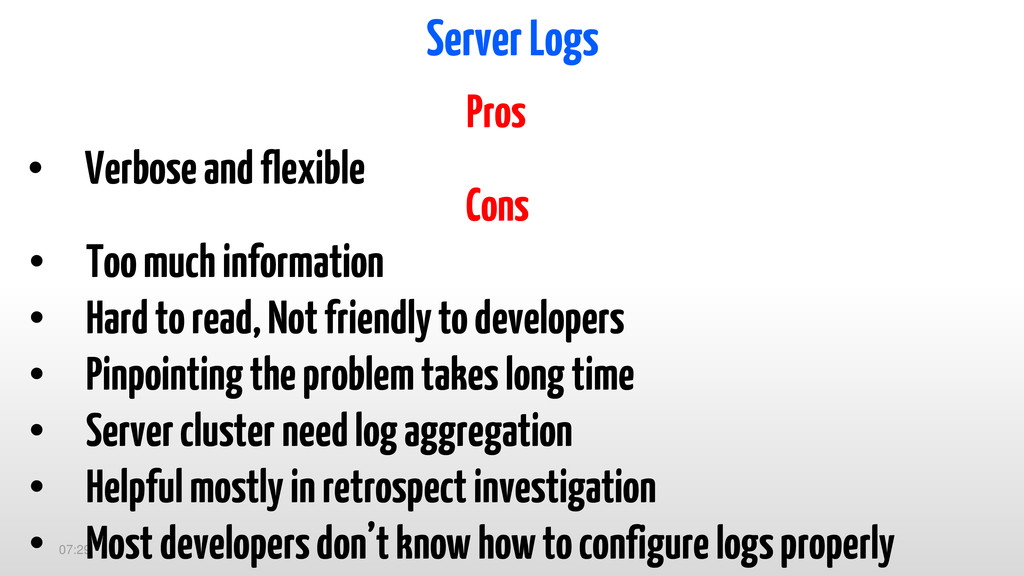{kind=link}
{kind=link}
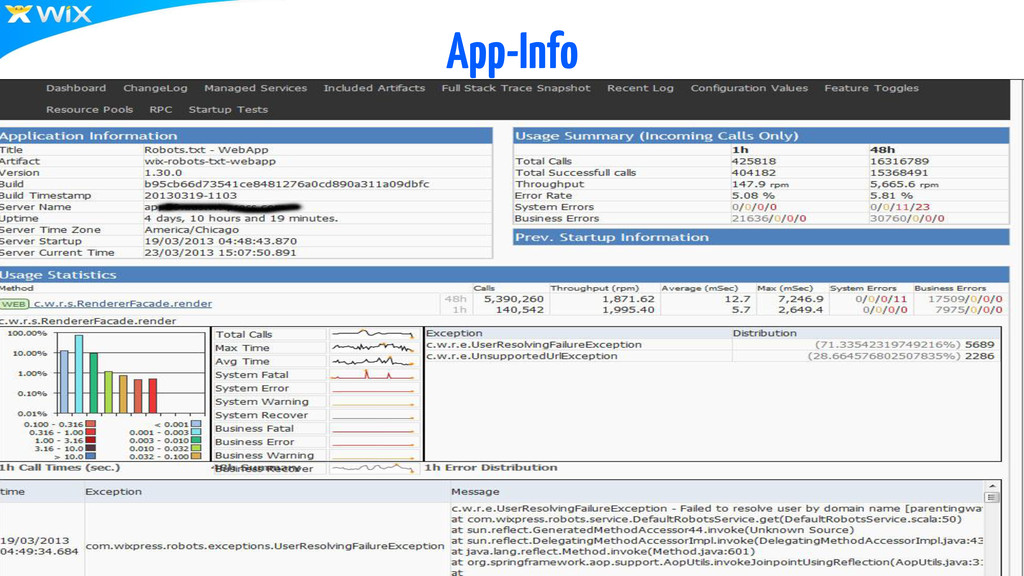{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}