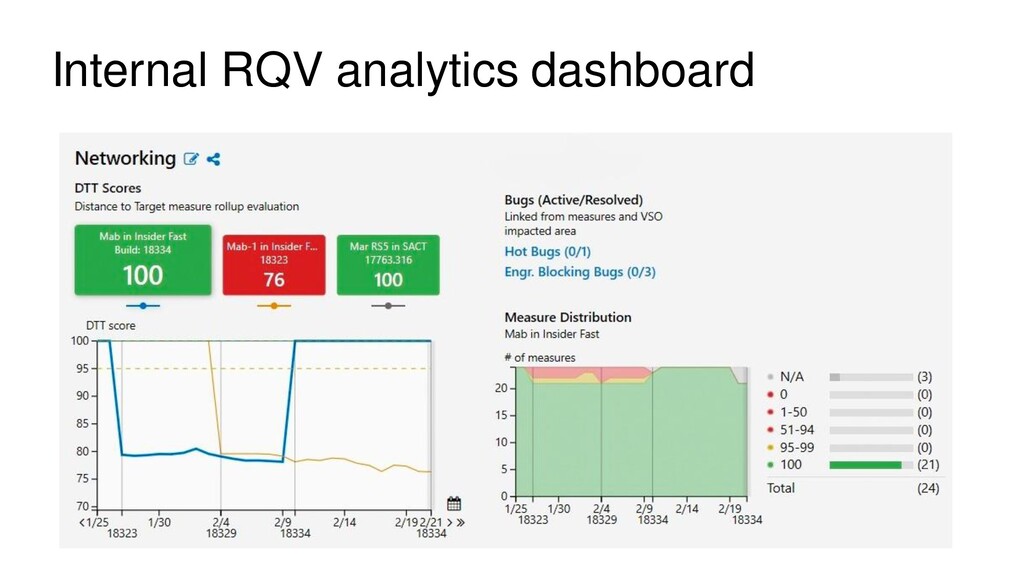
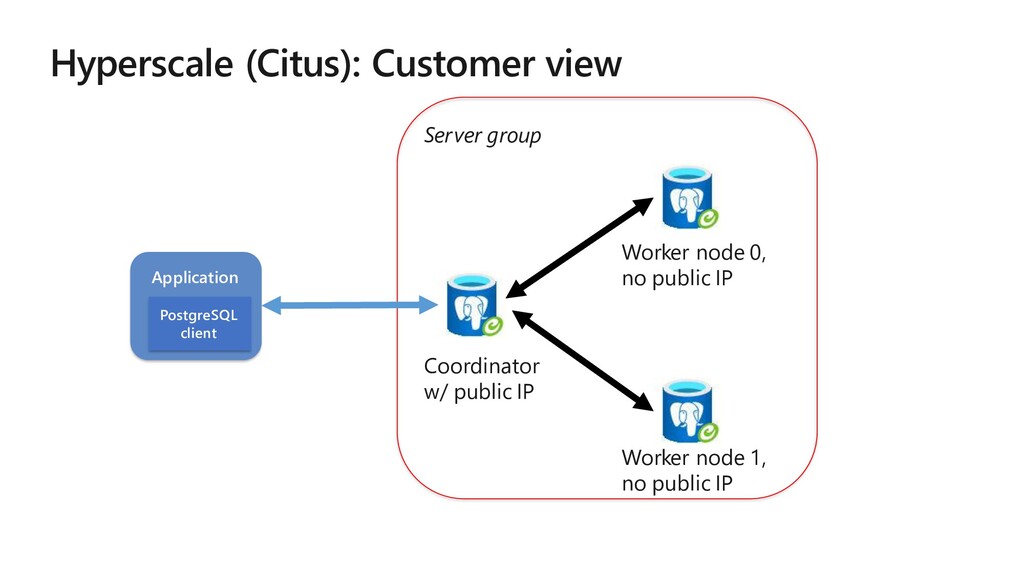
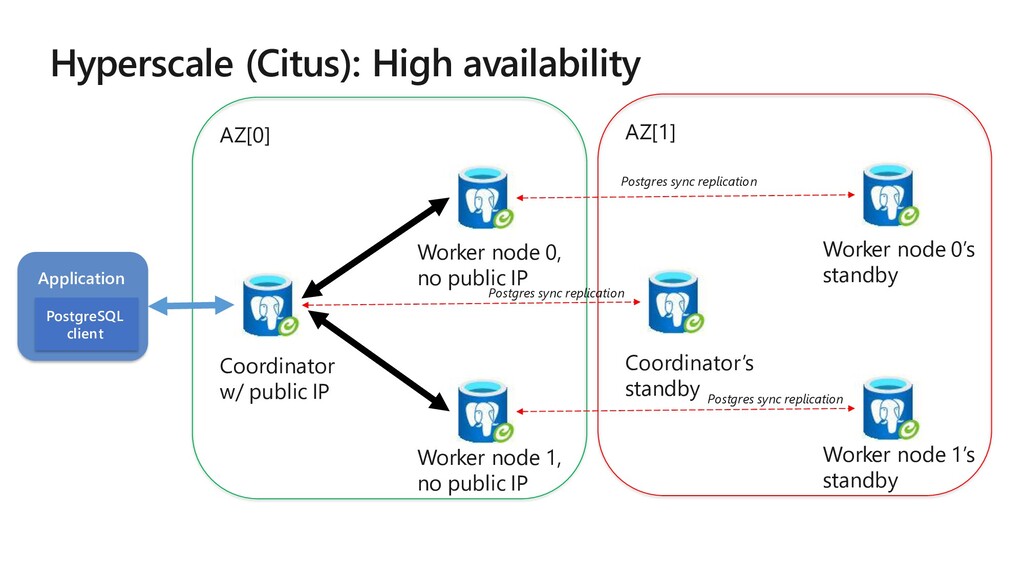
The story about powering a 1.5 petabyte analytics application with 2816 cores and 18.7 TB of memory in the Citus cluster at the Microsoft. The Windows team measures the quality of new software builds by scrutinizing 20,000 diagnostic metrics based on data flowing in from 800 million Windows devices. At the same time, the team evaluates feedback from Microsoft engineers who are using pre-release versions of Windows updates. At Microsoft, the Windows diagnostic metrics are displayed on a real-time analytics dashboard called “Release Quality View” (RQV), which helps the internal “ship-room” team assess the quality of the customer experience before each new Windows update is released. Given the importance of Windows for Microsoft’s customers, the RQV analytics dashboard is a critical tool for Windows engineers, program managers, and execs.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
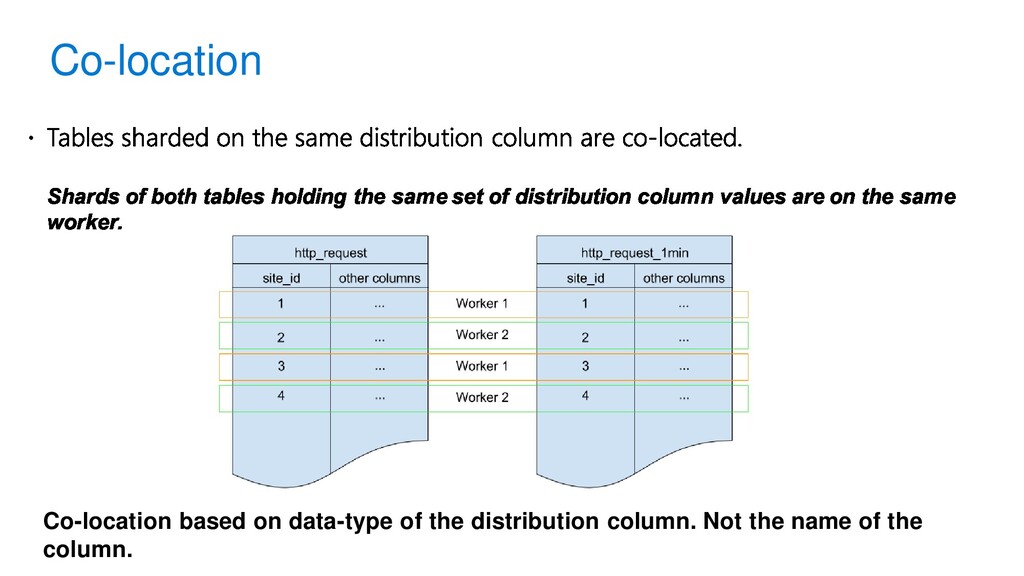{kind=link}
{kind=link}
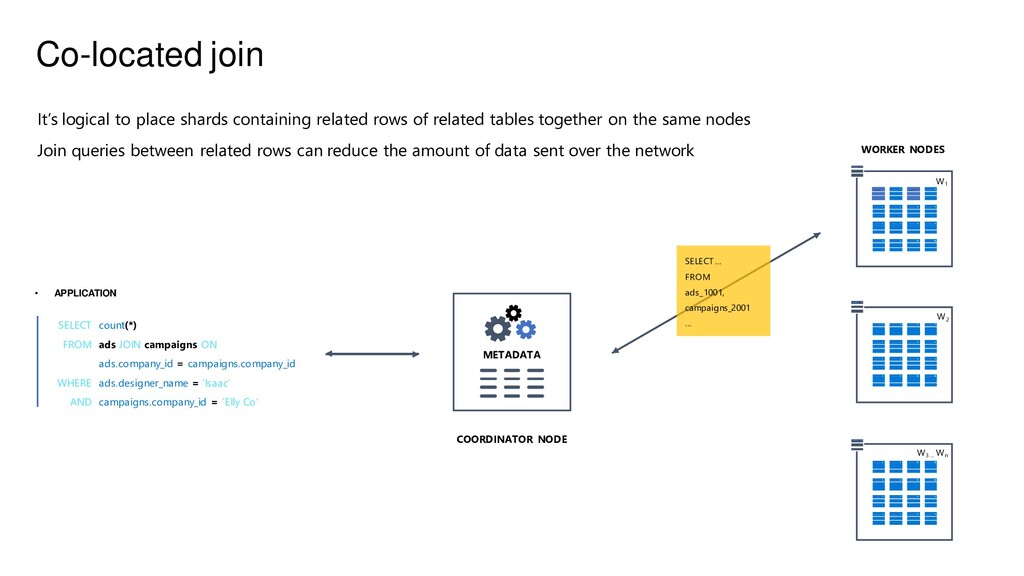{kind=link}
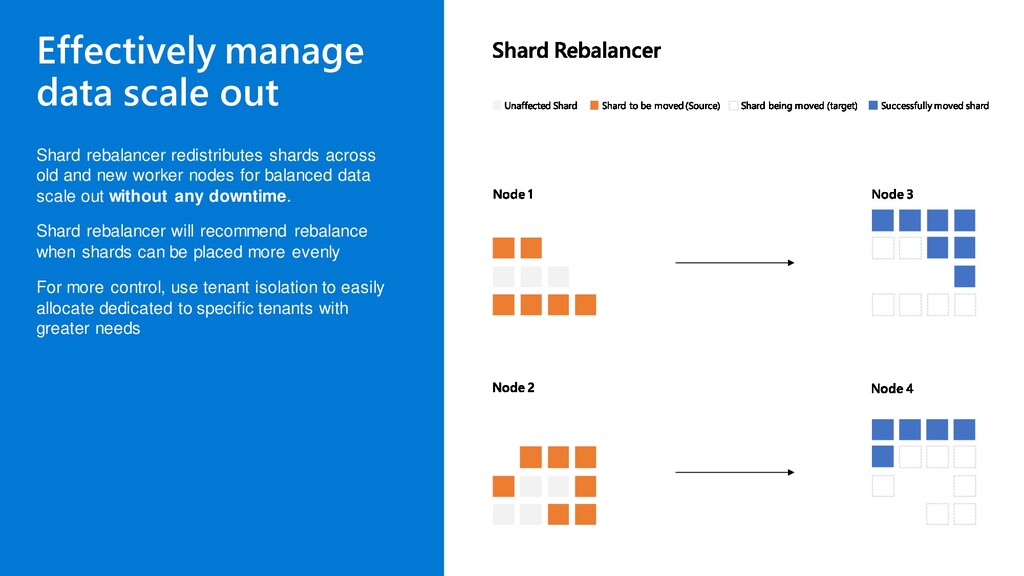{kind=link}
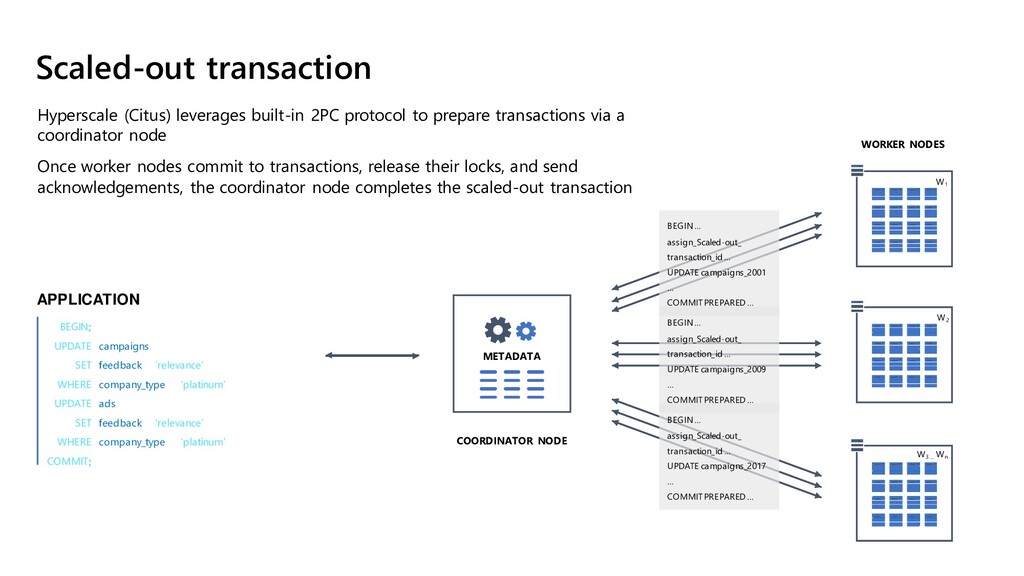{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}