The story about a challenging PoC that proved that Postgres can achieve the same performance as Oracle Exadata.
In this talk we want to present how Microsoft team composed of people from two different teams approached the project and solved the migration issues using ora2pg and was able to prove that Postgres Single Server can perform equally well as Oracle Exadata. We will present our ways of working and also some main technical challenges that we faced including migration of BULK COLLECT’s, hierarchical queries, refcursors and others more complicated Oracle constructs.
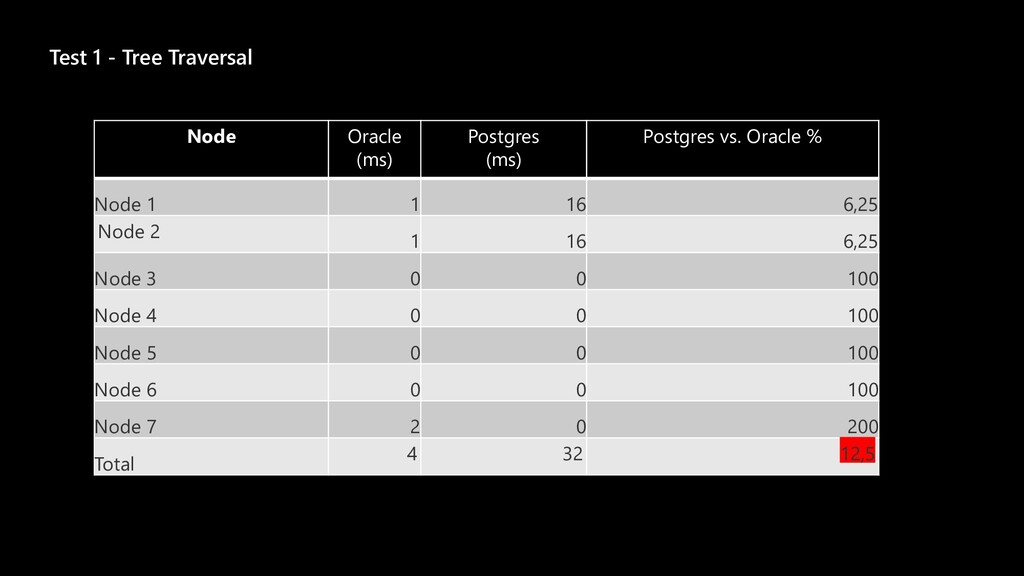
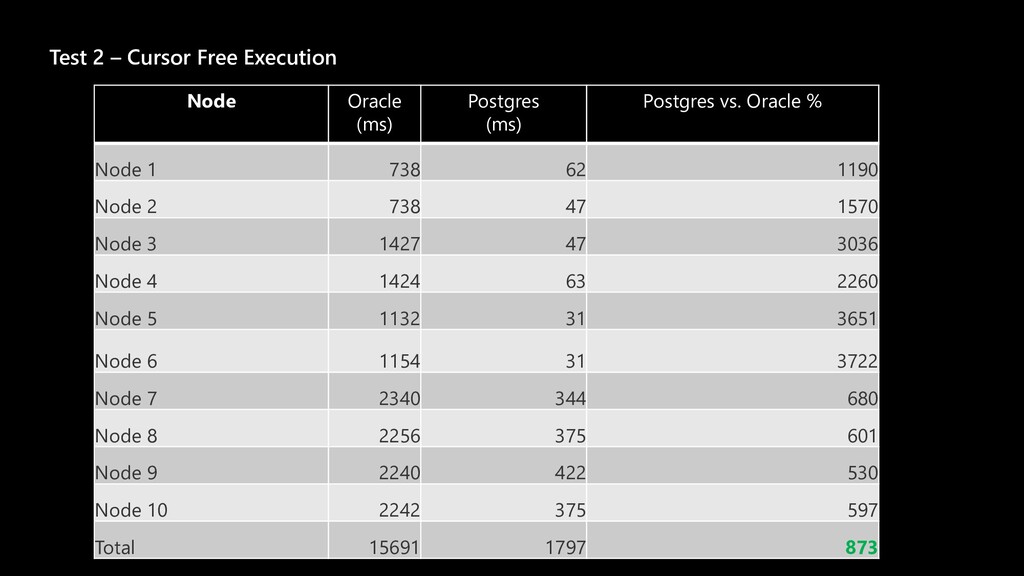
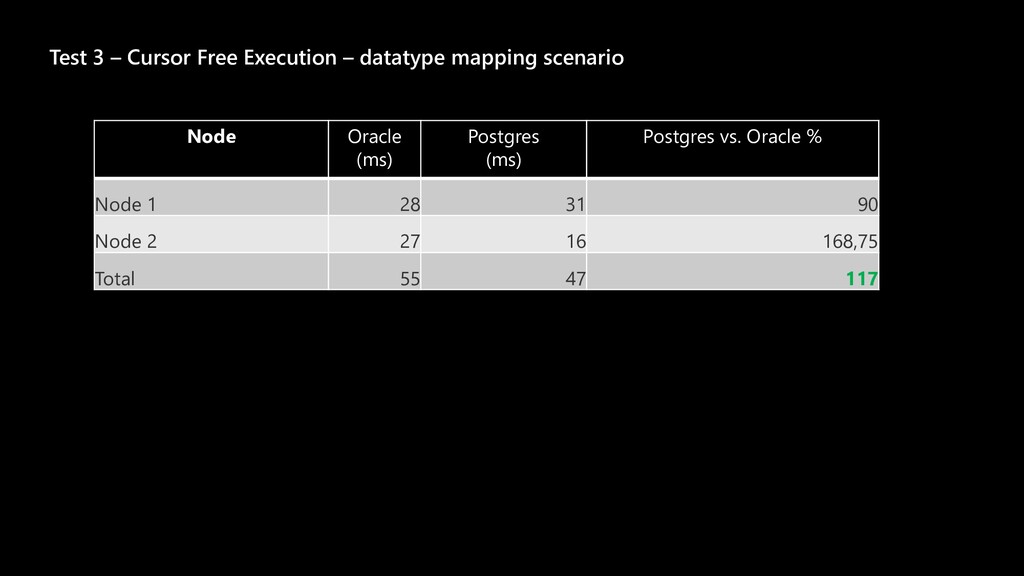
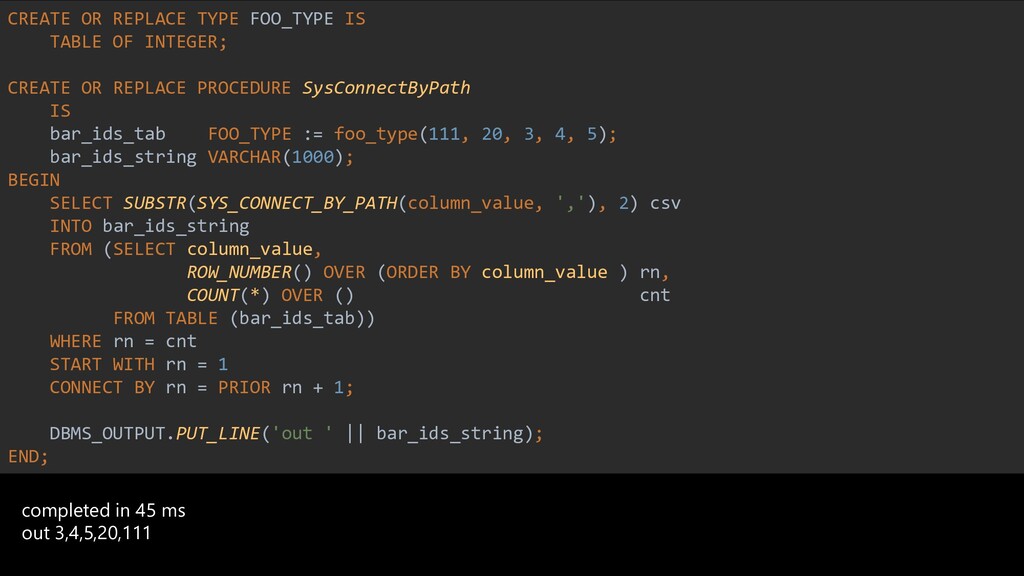
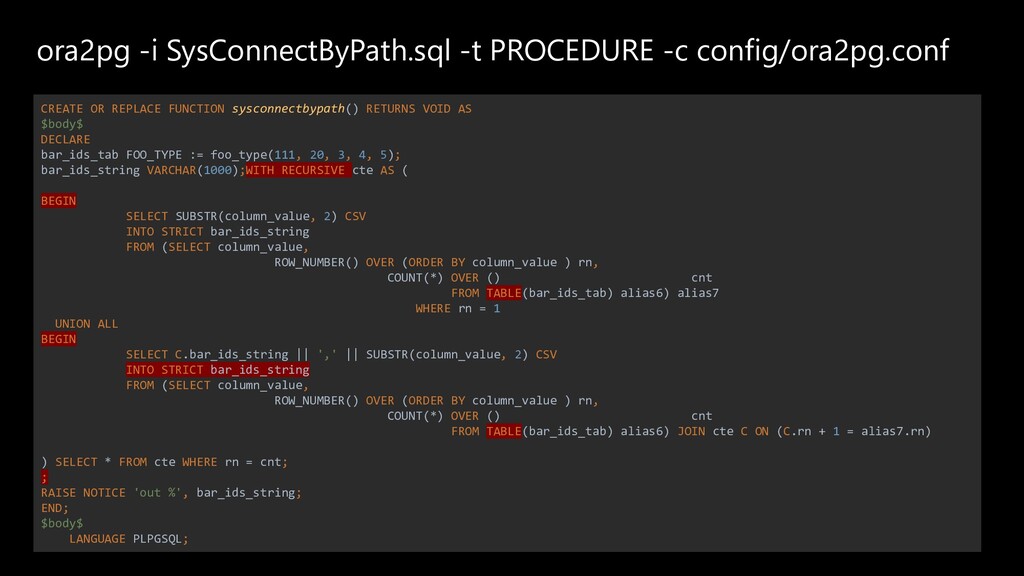
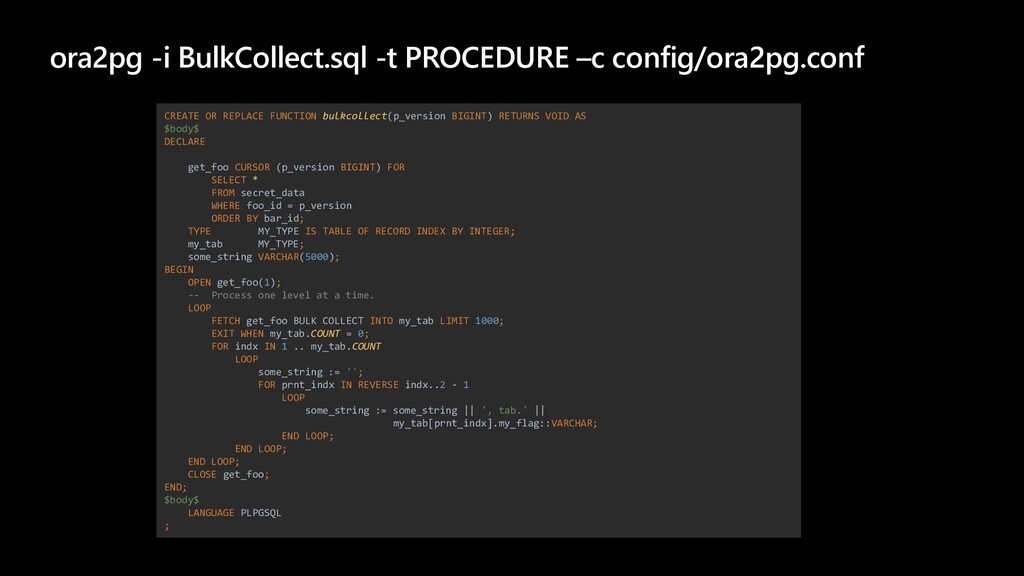
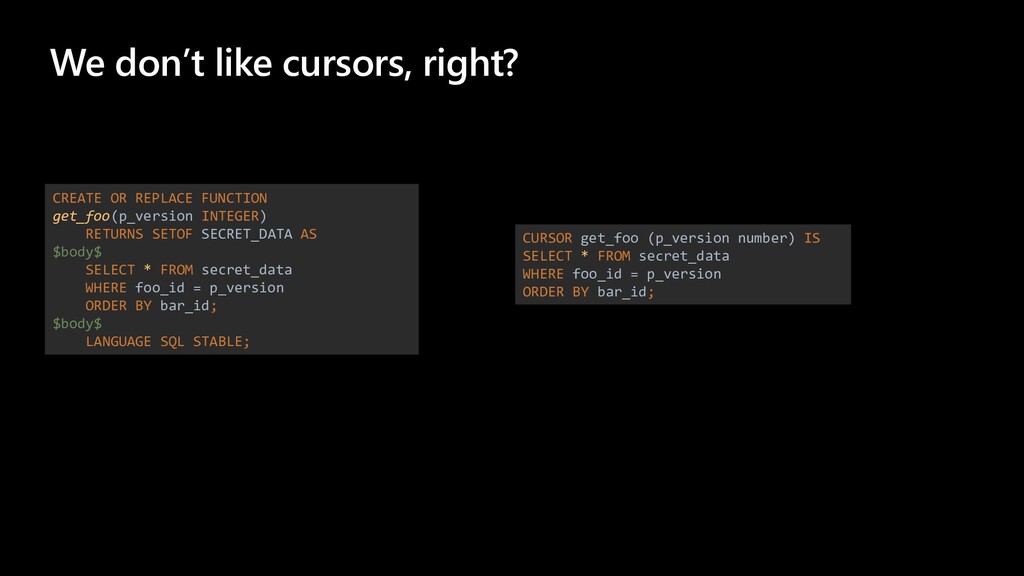
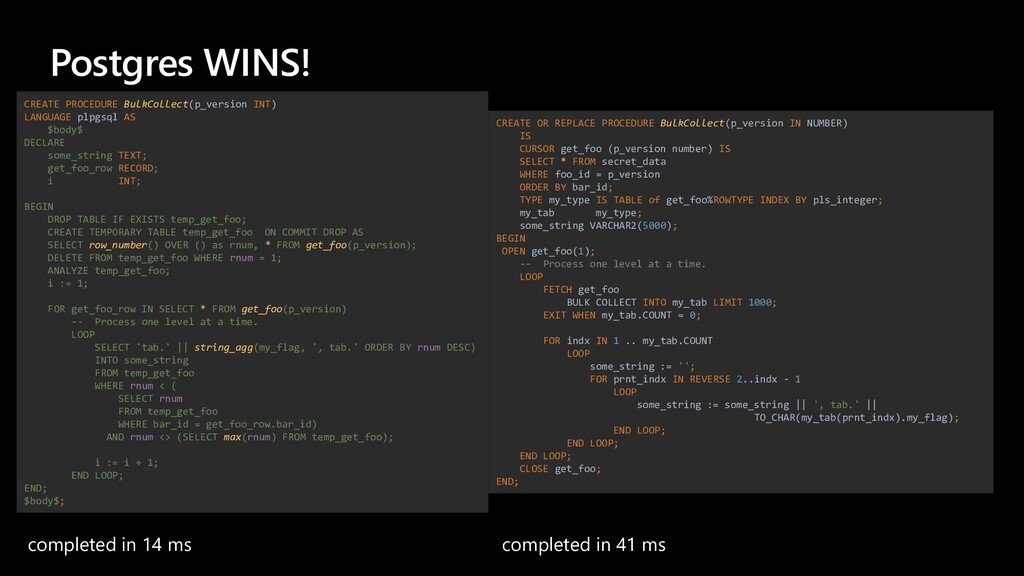
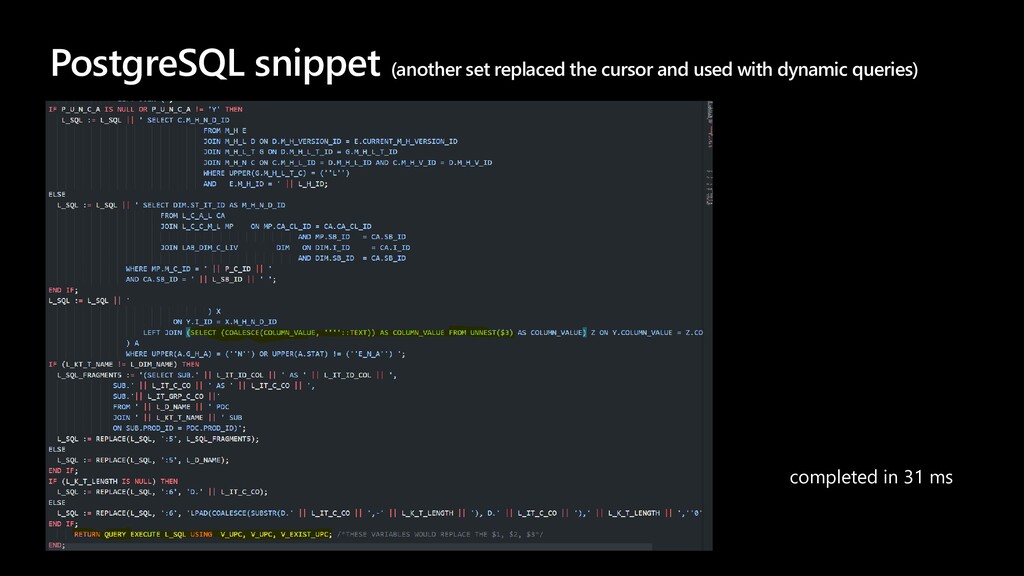
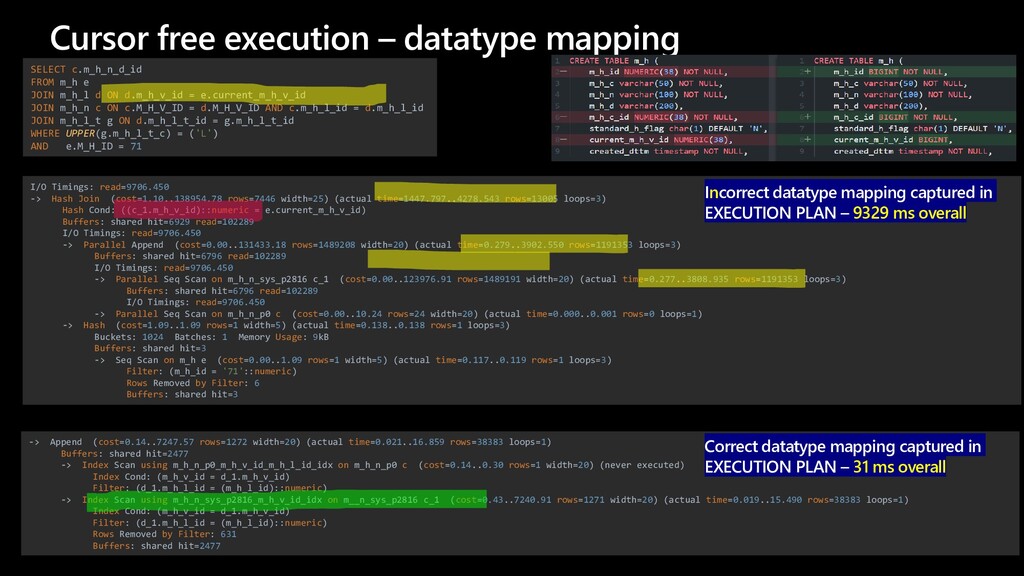
The story about a challenging PoC that proved that Postgres can achieve the same performance as Oracle Exadata. The schema that was migrated wasn’t the simplest one you might see. It was quite the opposite. The code was loaded with dynamic queries, BULK COLLECT’s, nested loops, CONNECT BY statements, global variables and lot of dependencies. Ora2pg did a great job converting the schema but left a lot of work to do manually. Also estimates produced by the tool were highly inaccurate since the logic required not the migration but total re-architecture of the code. In this talk we want to present how Microsoft team composed of people from two different teams approached the project and solved the migration issues using ora2pg and was able to prove that Postgres Single Server can perform equally well as Oracle Exadata. We will present our ways of working and also some main technical challenges that we faced including: • How estimates do (not) work • How we handled BULK COLLECT’s • Why we got rid of refcursors • How we got stuck with testing of one the packages and how the help from a friend solved the problem • How we handled hierarchical queries and drilling down the hierarchy
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Postgres WINS! DO $$ DECLARE bar_ids_tab NUMERIC[]; bar_ids_string TEXT; BEGIN](https://files.speakerdeck.com/presentations/45a01b75149340eaa28d9dba9dfb9c76/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Migrations https://aka.ms/postgres-migration-tutorial [email protected] Citus open source packages on GitHub—also, Email](https://files.speakerdeck.com/presentations/45a01b75149340eaa28d9dba9dfb9c76/slide_31.jpg){kind=link}
{kind=link}