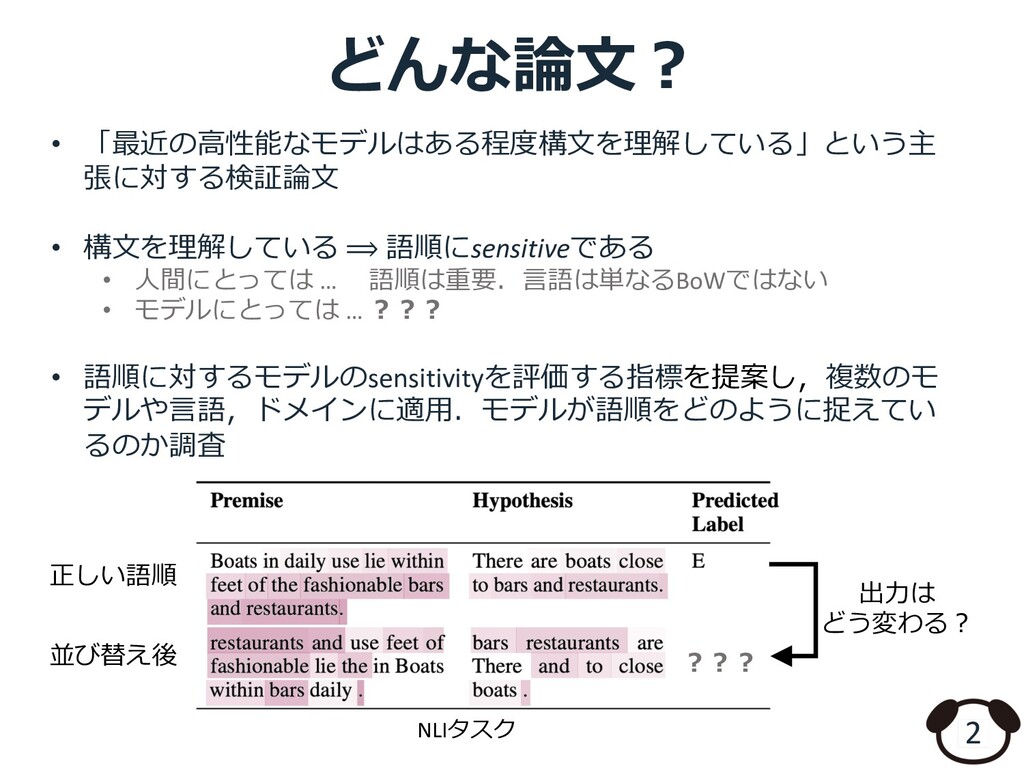
2019] Transformerベースのモデルはある程度構⽂を獲得できている︖ • 内部表現から構⽂チックな特徴が読み取れる • 同様の議論はTransformerだけではなくRNN , CNNでも⾏われてきた しかし実際に構⽂を理解できているかは疑問 • ⼀般的に⾔語現象によって性能にムラがある • Transformerモデルの含意認識はヒューリスティックなルールに依存 • The 𝑁! 𝑃 the 𝑁" 𝑉. ↛ The 𝑁" 𝑉. • The lawyer by the actor ran. ↛ The actor ran. • ⽂法的に正しいか否かを判定するタスクでの性能は⼈間に遠く及ばない [Tom McCoy et al., 2019] [Warstadt et al., 2019b]
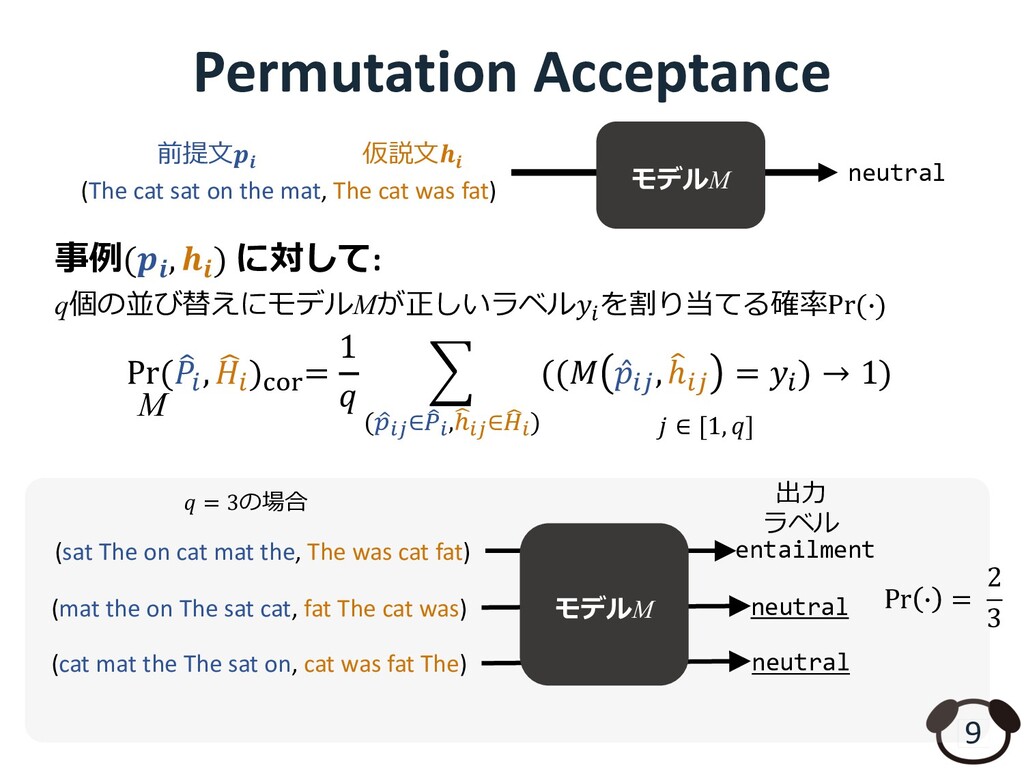
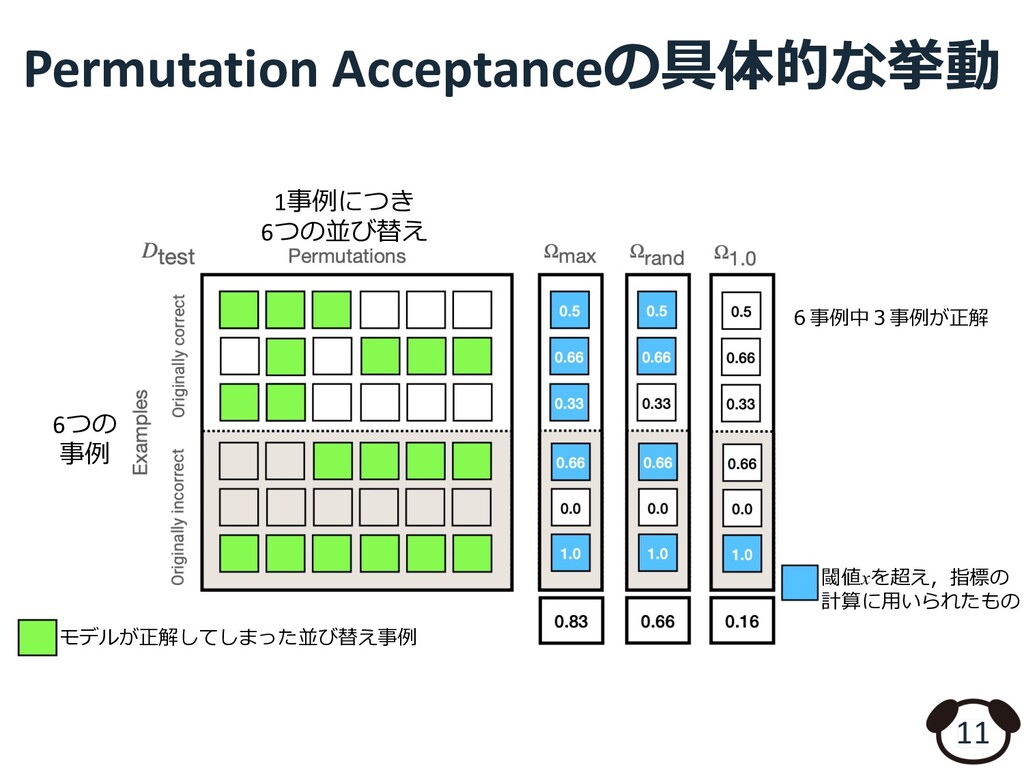
cat mat the, The was cat fat) (mat the on The sat cat, fat The cat was) (cat mat the The sat on, cat was fat The) 𝑞 = 3の場合 Pr( ( 𝑃+, * 𝐻+),-.= 1 𝑞 / ( 0 1!"∈ 3 4!,6 7!"∈6 8!) ((𝑀 ̂ 𝑝+:, ( ℎ+: = 𝑦+) → 1) M 𝑗 ∈ [1, 𝑞] neutral entailment neutral Pr & = 2 3 出⼒ ラベル 9 モデルM neutral (The cat sat on the mat, The cat was fat) 仮説⽂𝒉𝒊 前提⽂𝒑𝒊 モデルM
{kind=link}
{kind=link}
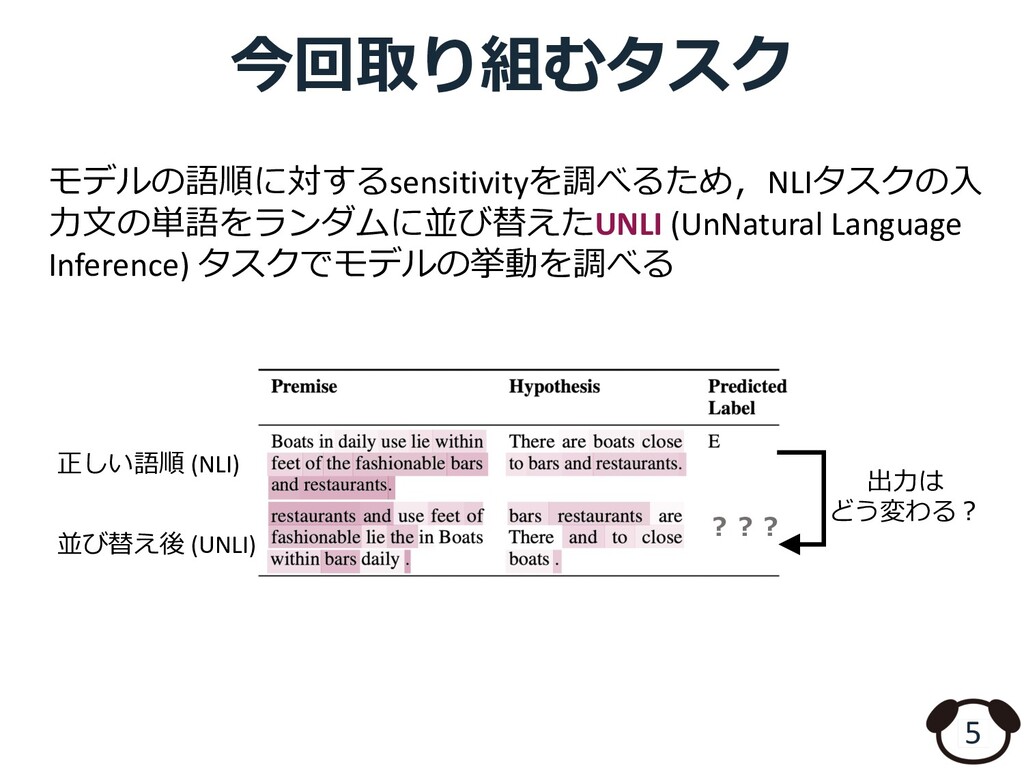
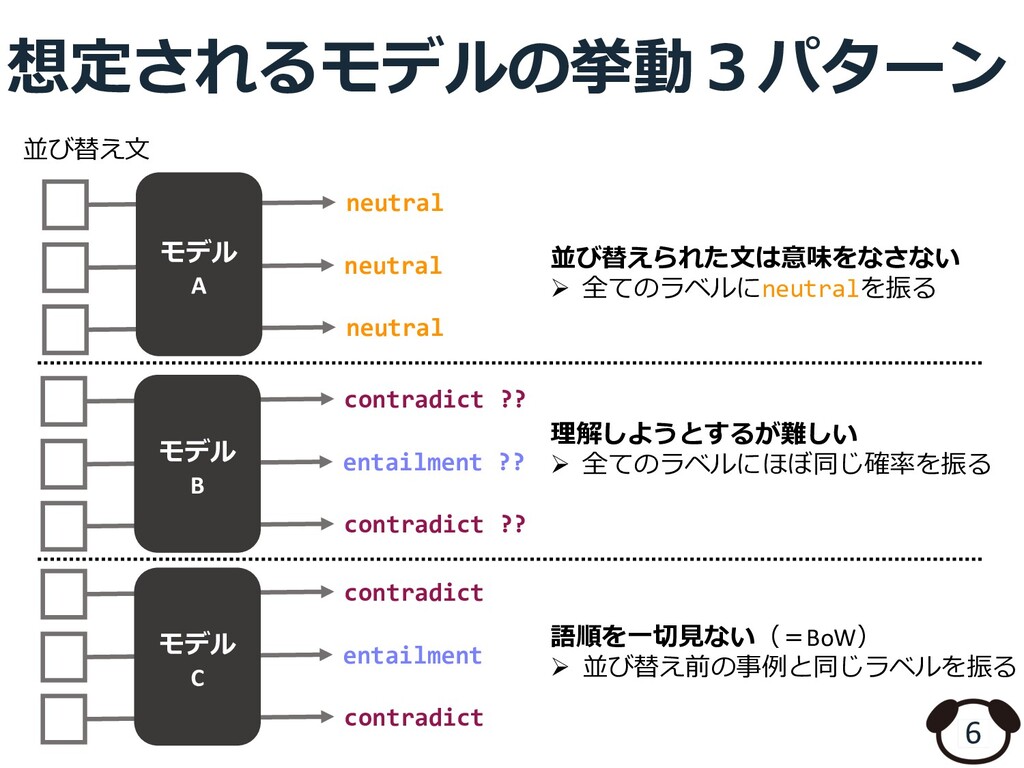
![Transformerベースのモデル×構⽂知識 3 [Wu et al., 2020] [John Hewitt et al.,](https://files.speakerdeck.com/presentations/d7c343003e464e76a325e6be3f8d9ecf/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
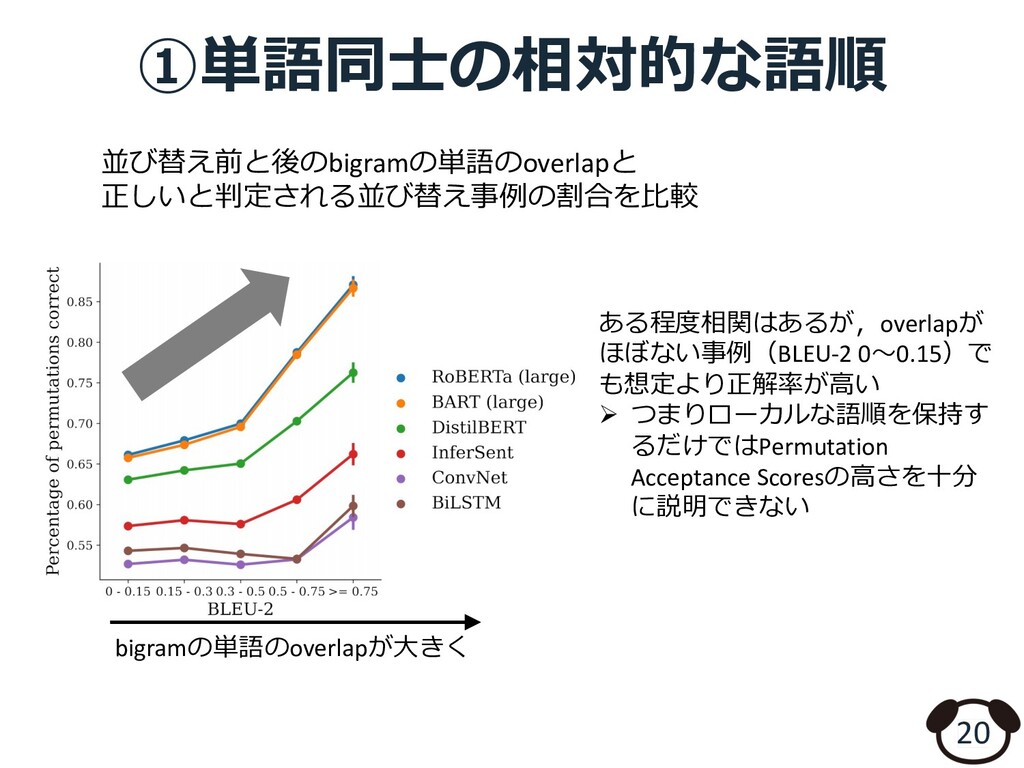{kind=link}
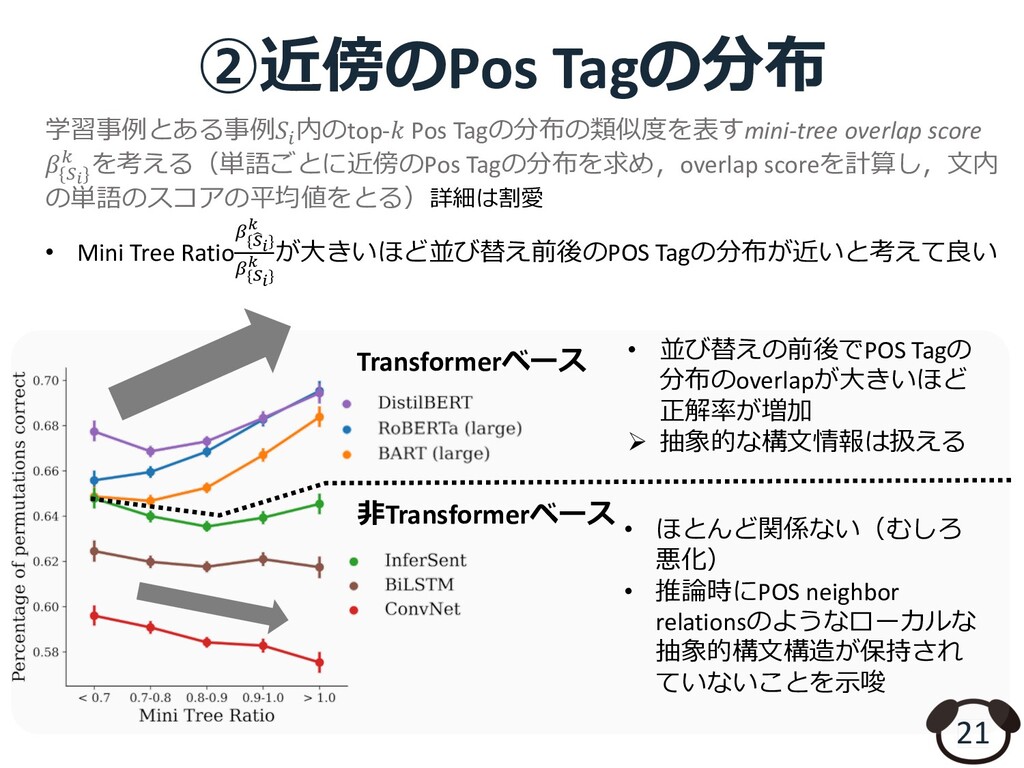{kind=link}
{kind=link}
{kind=link}
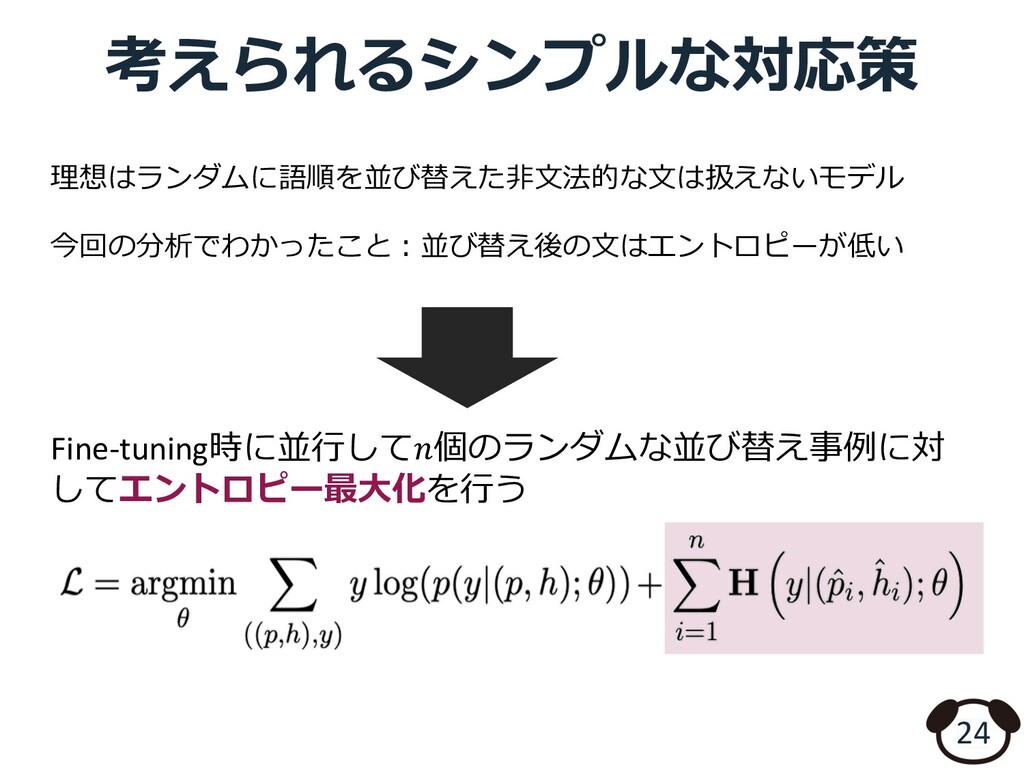{kind=link}
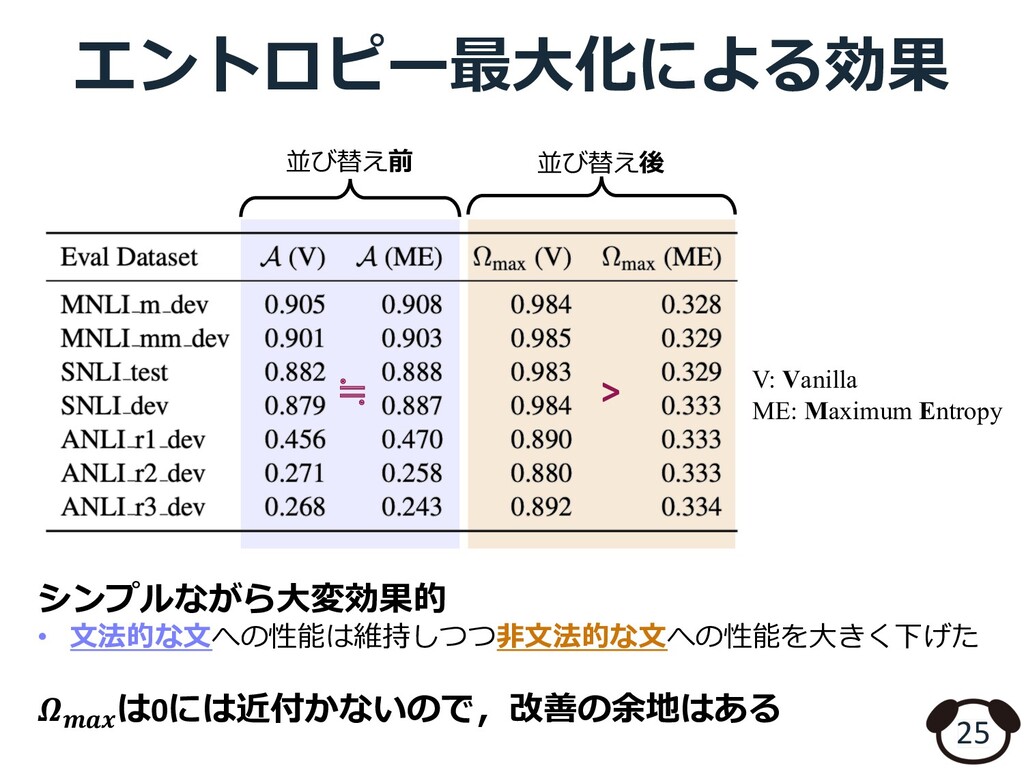{kind=link}
{kind=link}