Share
2022-9-26 第14回最先端NLP勉強会の発表資料です。 https://sites.google.com/view/snlp-jp/home/2022
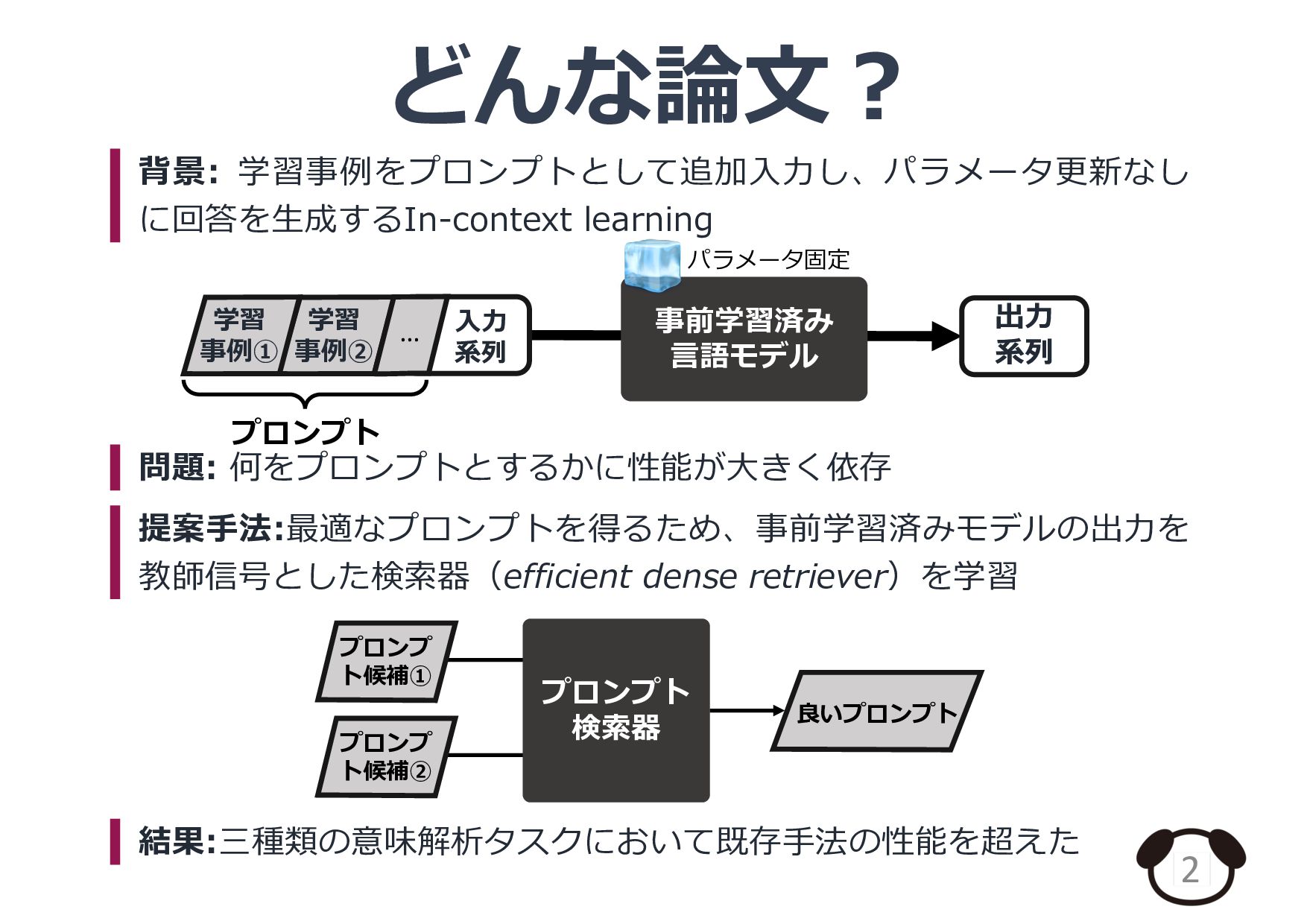
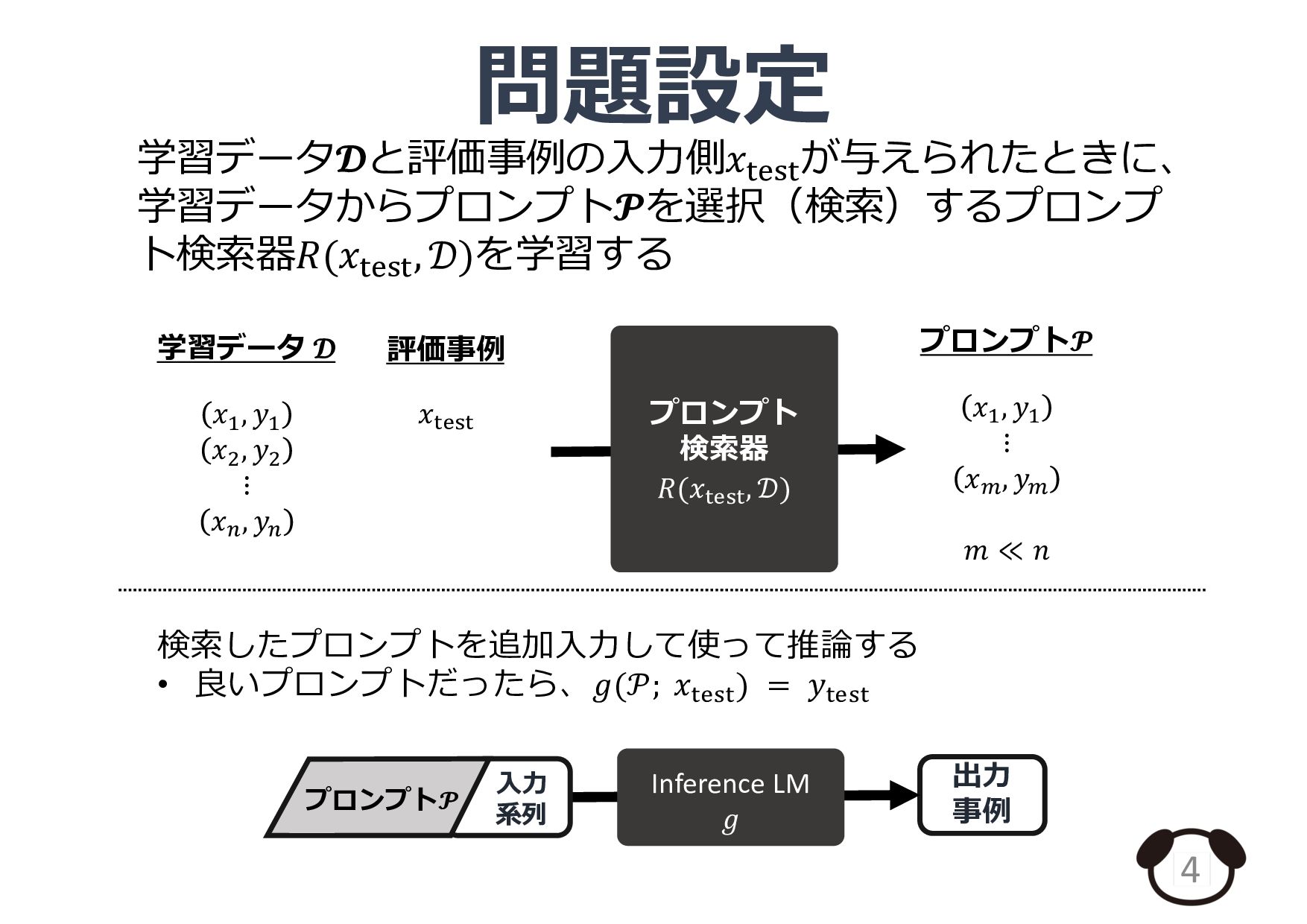
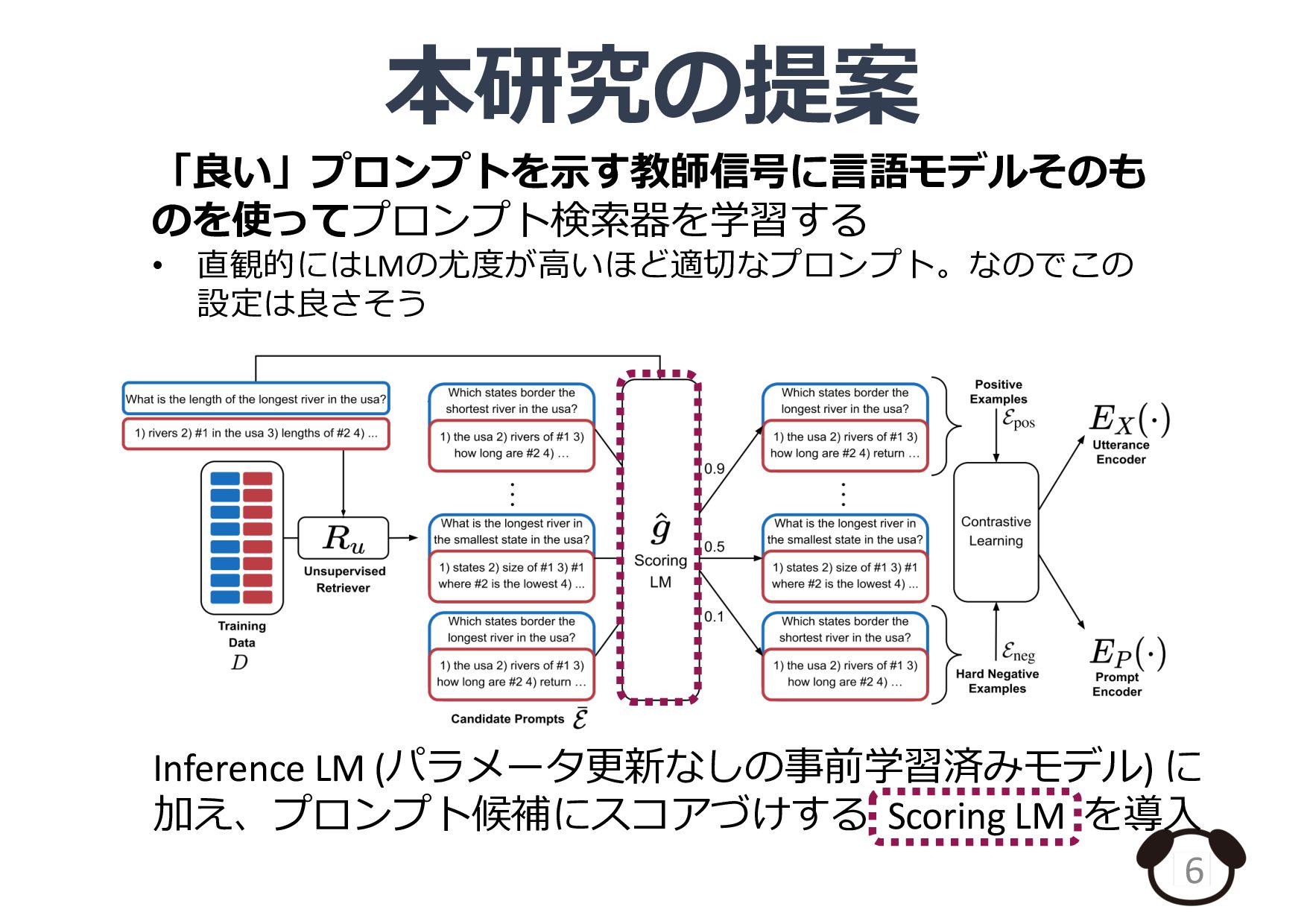
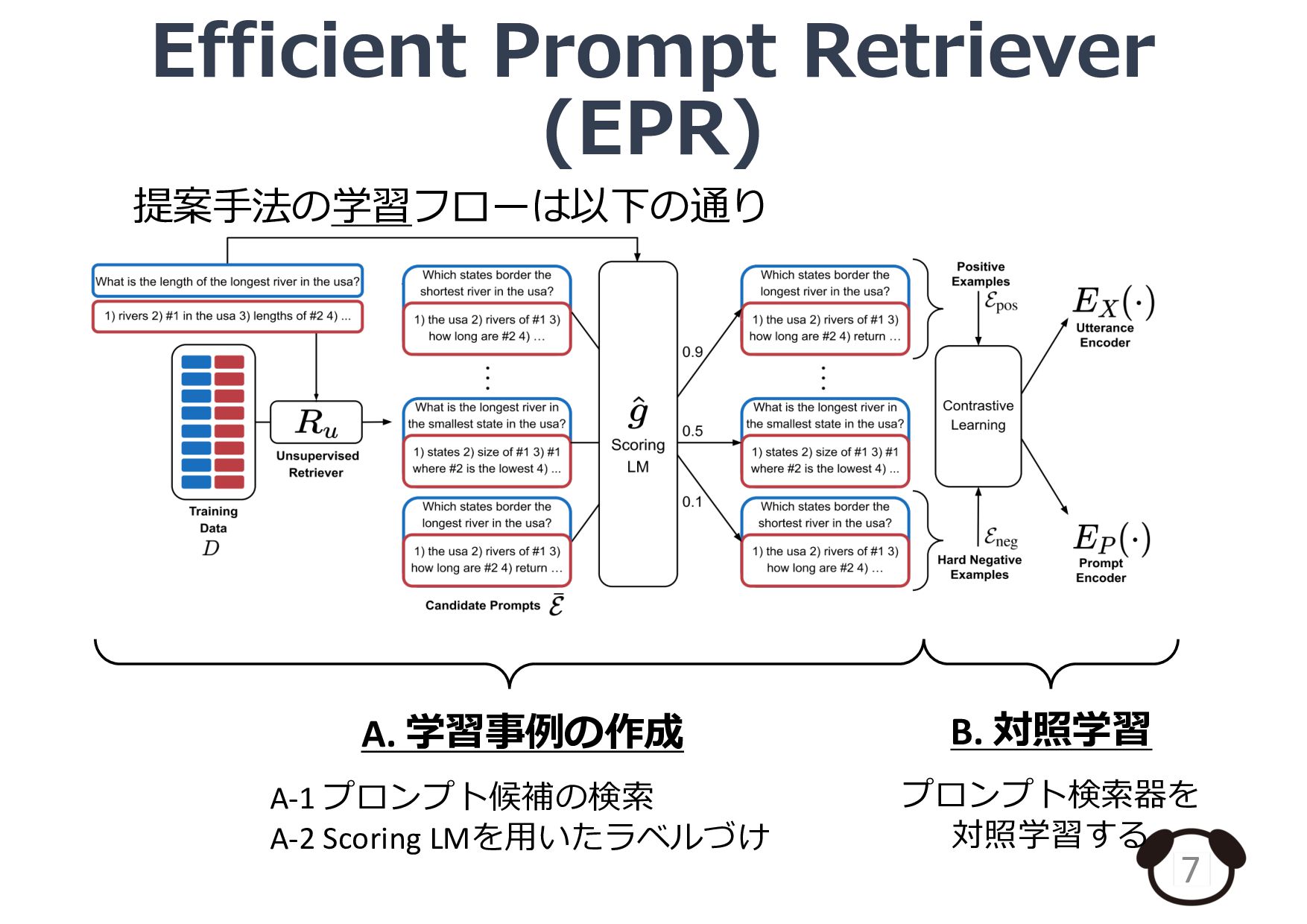
紹介論文: Rubin et al., Learning To Retrieve Prompts for In-Context Learning., NAACL 2022 (https://aclanthology.org/2022.naacl-main.191)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
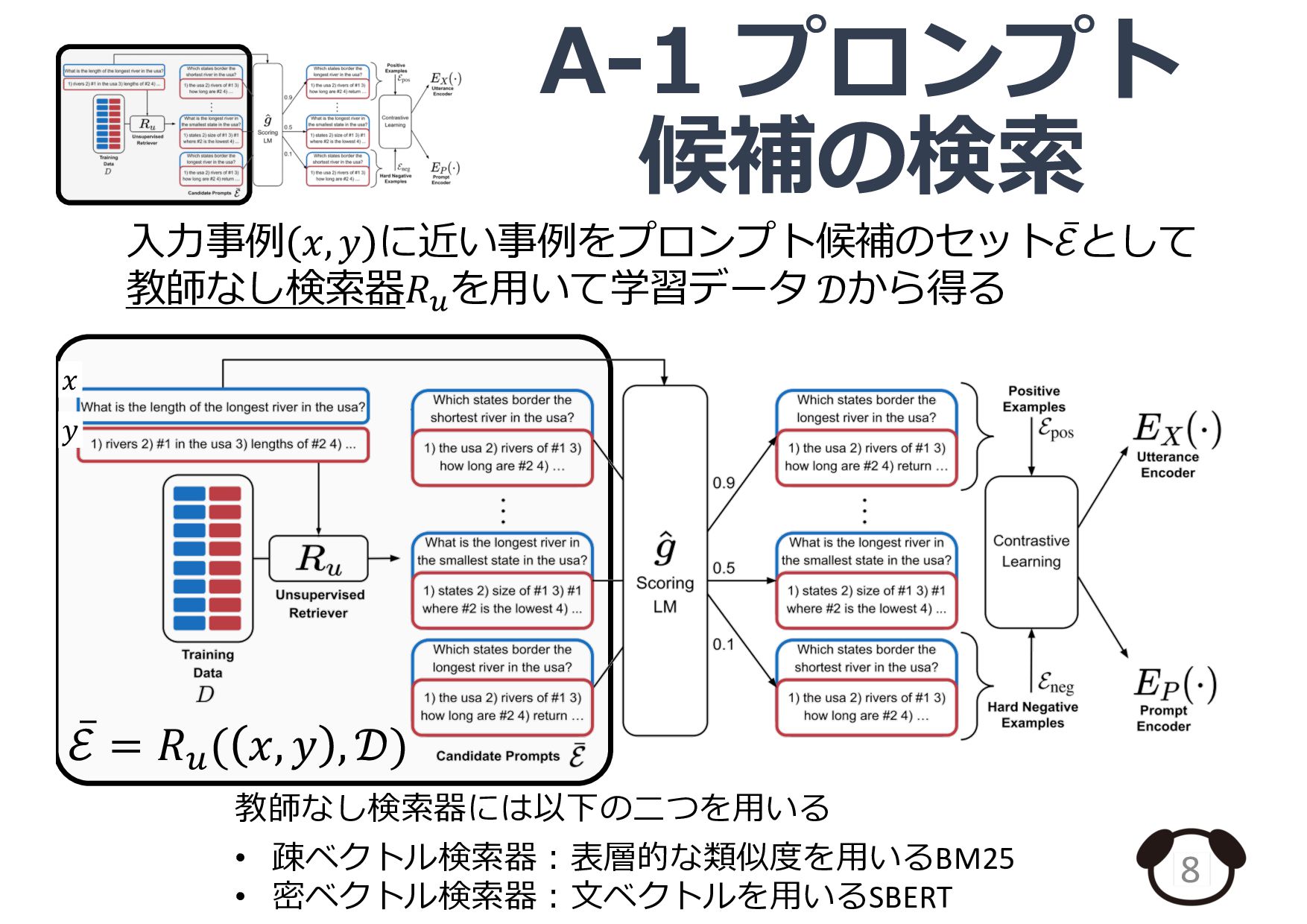
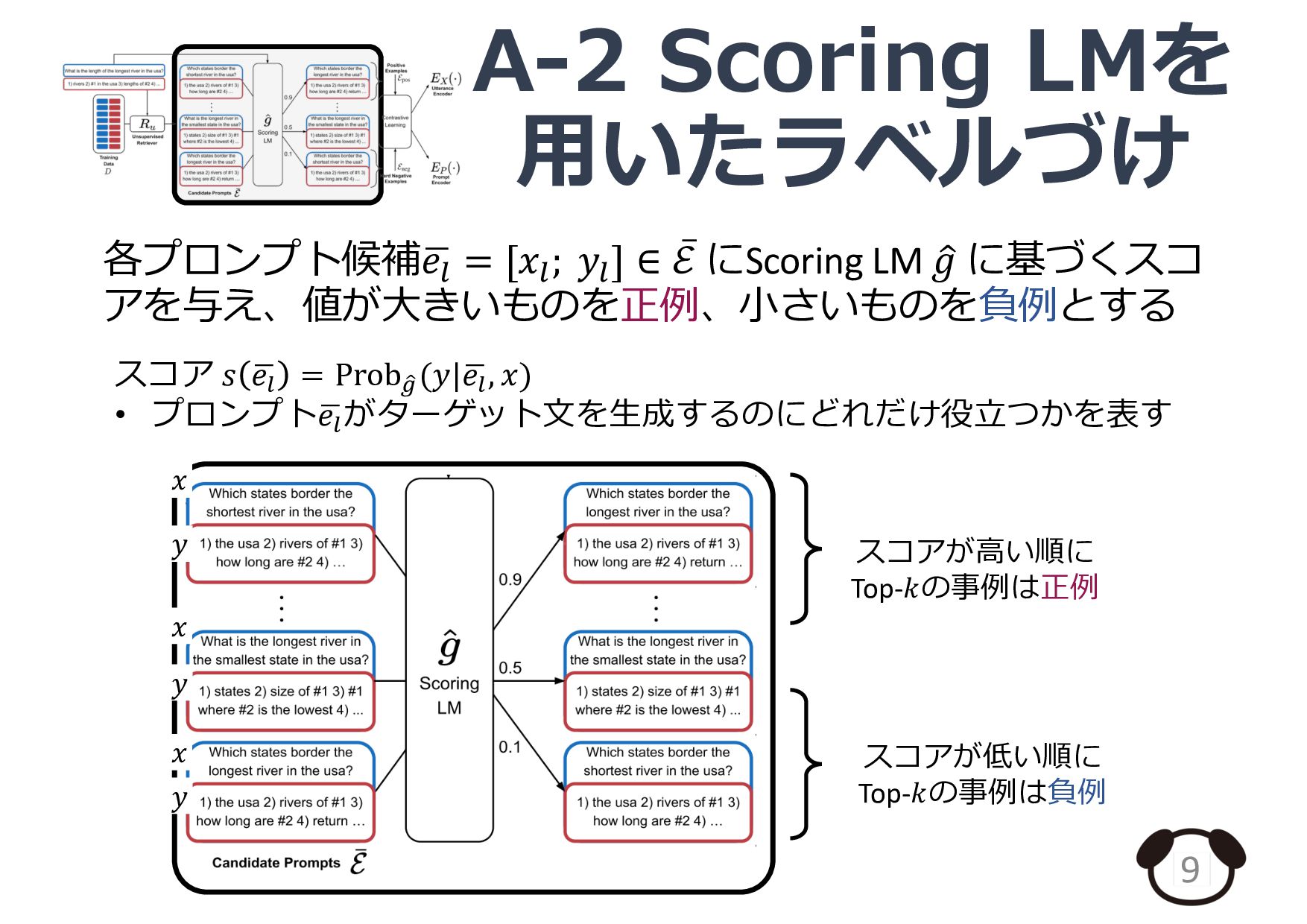
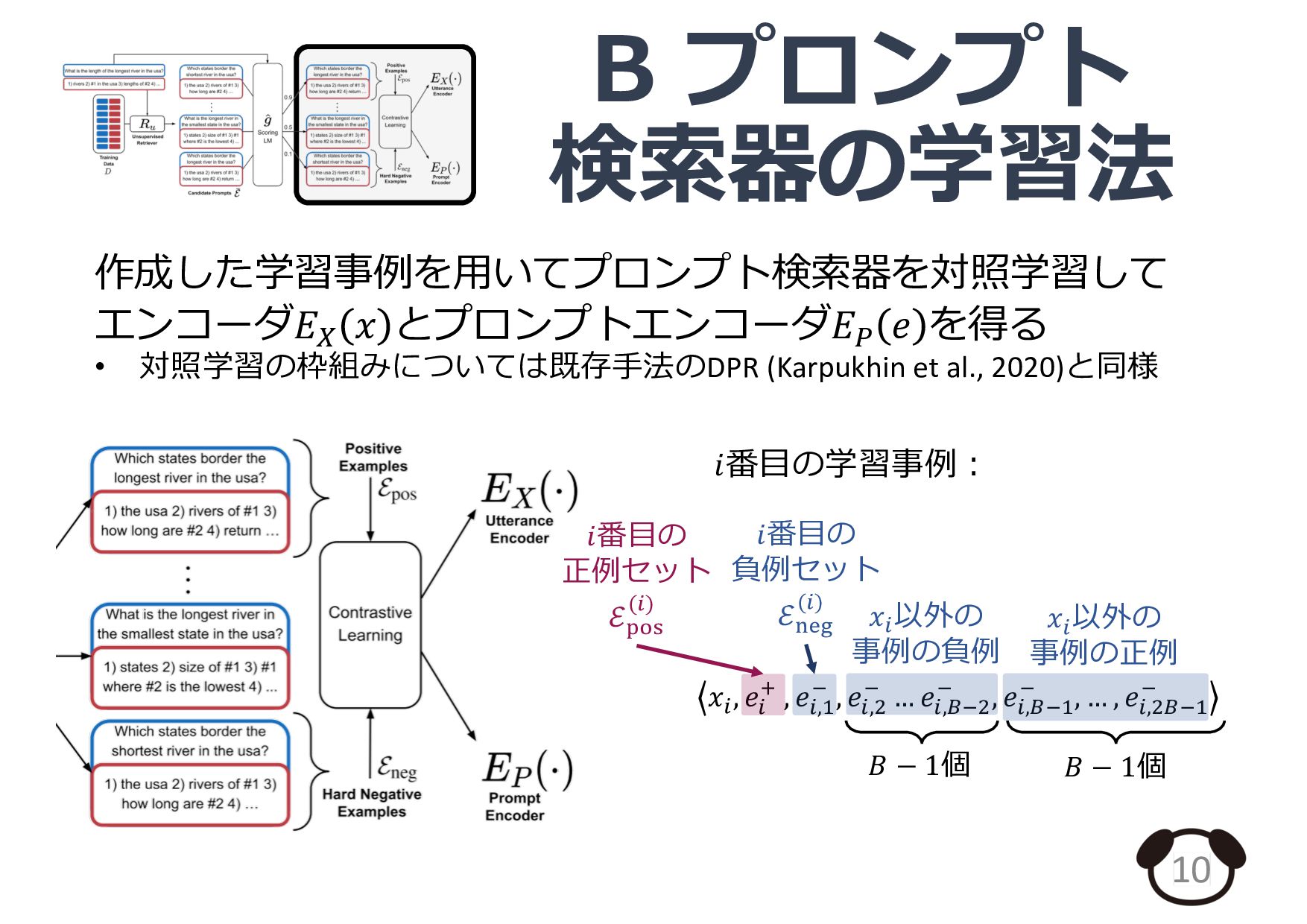
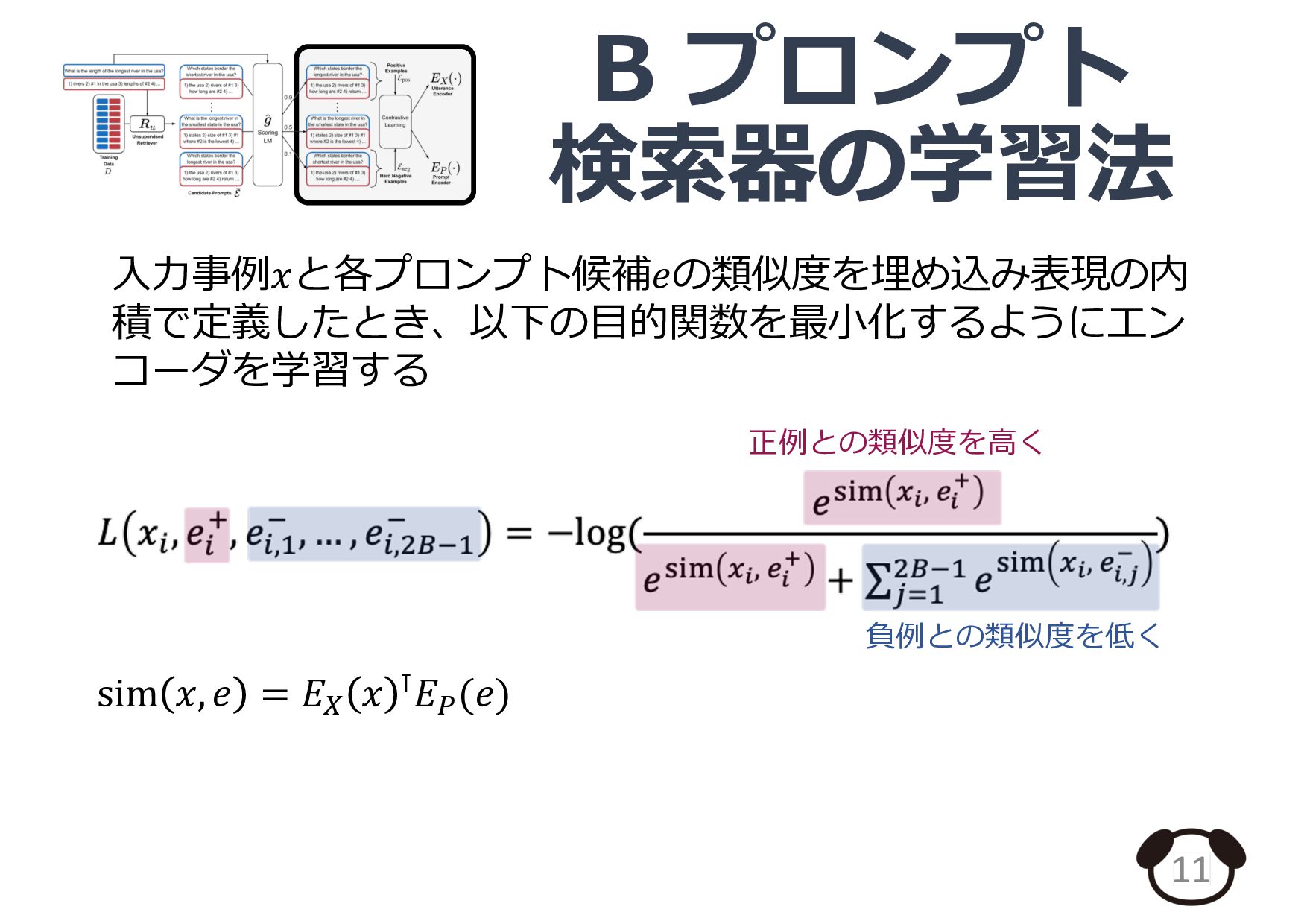
![プロンプト検索器の概要 5 ⼊⼒事例 𝒙 プロンプト候補 [𝒙𝟏 ; 𝒚𝟏 ] [𝒙𝟐](https://files.speakerdeck.com/presentations/0539e39dffd545379202b300d6ae43ab/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![𝑥!"#! 推論フロー 12 [前処理] 全ての学習事例をプロンプトエンコーダ𝐸!(#)でエンコード 埋め込み表現 𝐸3 (𝑥$%&$ ) エンコーダ](https://files.speakerdeck.com/presentations/0539e39dffd545379202b300d6ae43ab/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
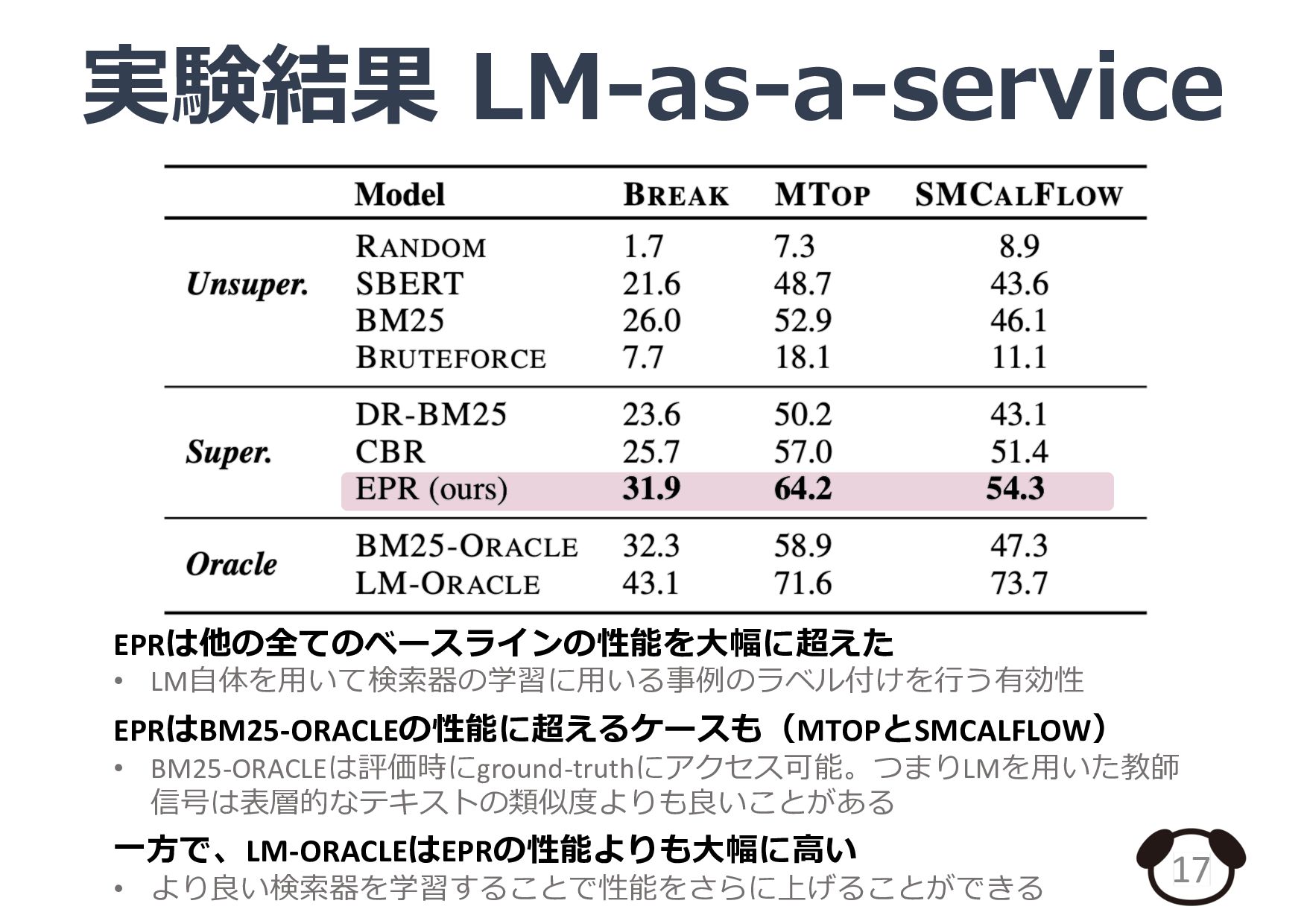{kind=link}
{kind=link}
{kind=link}