8 years of working experience as a research engineer in machine learning startup companies based in Myanmar and Thailand Conducting research in in Natural Language Processing, Sentiment Analysis, Structure from Motion, and Visual Localization Published 4 international conference papers and one manuscript is accepted for publication in Scopus Q2 journal • Thailand Education Hub for ASEAN Countries Scholarship, 2018 • Google Women Techmakers Scholarship APAC, 2018 • Kaggle BIPOC Grantee, 2021 A little bit about me
through interaction - not only with their parents and other adults, but also with other children. • All normal children who grow up in normal households, surrounded by conversation, will acquire the language that is being used around them. (Linguistic Society of America) Knowledge Transfer
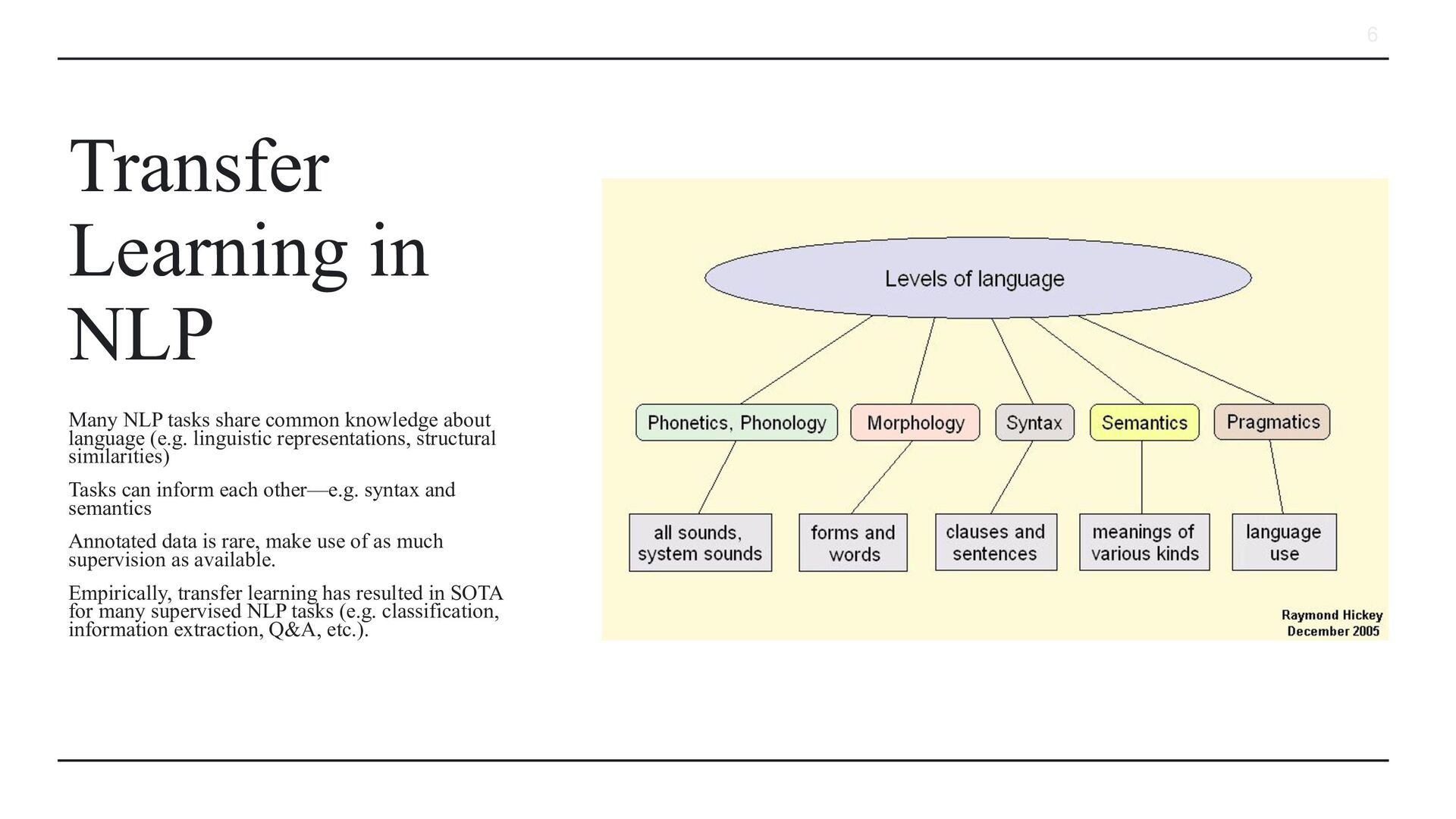
knowledge about language (e.g. linguistic representations, structural similarities) Tasks can inform each other—e.g. syntax and semantics Annotated data is rare, make use of as much supervision as available. Empirically, transfer learning has resulted in SOTA for many supervised NLP tasks (e.g. classification, information extraction, Q&A, etc.).
based on patterns found in massive amounts of training data. They are used in applications such as language translation, chatbots, and content creation. ❏ a LM learns P ϴ (text) or P ϴ (text | some other text) Mathematically, a language model is a very simple and beautiful object. Ability to assign (meaningful) probabilities to all sequences requires extraordinary (but implicit) linguistic abilities and world knowledge. What is LLM? Machine Learning The probability intuitively tells us how “good” a sequence of tokens is. For example, if the vocabulary is ={𝖺𝗍𝖾,𝖻𝖺𝗅𝗅,𝖼𝗁𝖾𝖾𝗌𝖾, 𝗆𝗈𝗎𝗌𝖾,𝗍𝗁𝖾} • p(the,mouse,ate,the,cheese)=0.02, • p(𝗍𝗁𝖾,𝖼𝗁𝖾𝖾𝗌𝖾,𝖺𝗍𝖾,𝗍𝗁𝖾,𝗆𝗈𝗎𝗌𝖾)=0.01, • p(𝗆𝗈𝗎𝗌𝖾,𝗍𝗁𝖾,𝗍𝗁𝖾,𝖼𝗁𝖾𝖾𝗌𝖾,𝖺𝗍𝖾)=0.0001 https://stanford-cs324.github.io/winter2022
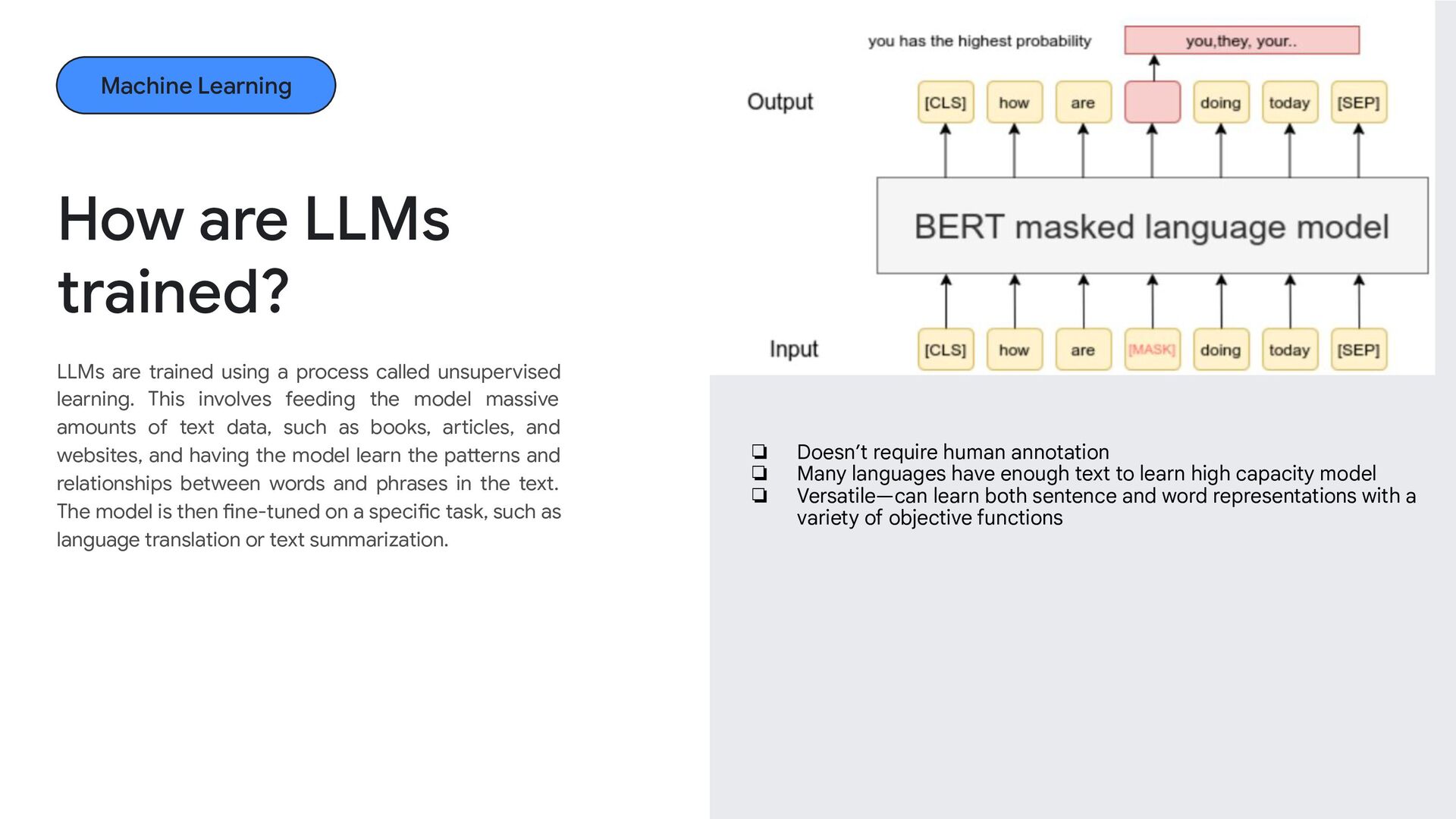
involves feeding the model massive amounts of text data, such as books, articles, and websites, and having the model learn the patterns and relationships between words and phrases in the text. The model is then fine-tuned on a specific task, such as language translation or text summarization. How are LLMs trained? ❏ ❏ ❏ Doesn’t require human annotation ❏ Many languages have enough text to learn high capacity model ❏ Versatile—can learn both sentence and word representations with a variety of objective functions Machine Learning
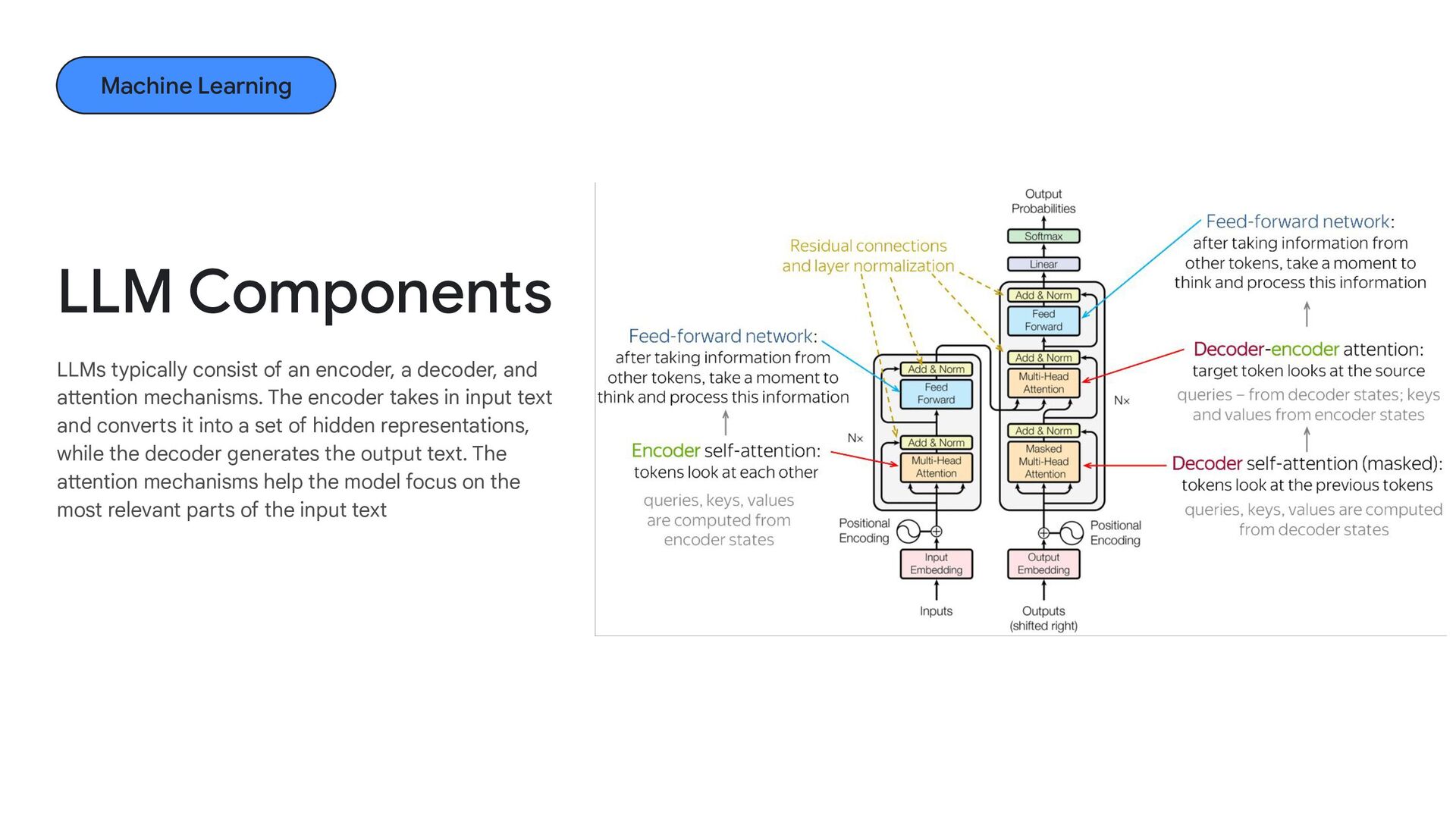
mechanisms. The encoder takes in input text and converts it into a set of hidden representations, while the decoder generates the output text. The attention mechanisms help the model focus on the most relevant parts of the input text LLM Components Machine Learning
meaning in a continuous vector space. Common methods for word embeddings include Word2Vec, GloVe, and fastText. Each token is broken down into smaller subword units (e.g., characters or character n-grams), and each subword is replaced by a vector that represents its meaning. This approach can handle out-of-vocabulary (OOV) words and can improve the model's ability to capture morphological and semantic similarities. Common methods for subword embeddings include Byte Pair Encoding (BPE), Unigram Language Model (ULM), and SentencePiece. Word Embedding Subword Embedding Since LLMs operate on sequences of tokens, they need a way to encode the position of each token in the sequence. Positional encodings are vectors that are added to the word or subword embeddings to provide information about the position of each token. Positional Encoding Machine Learning
language translation, chatbots, content creation, and text summarization. •They can also be used to improve search engines, voice assistants, and virtual assistants. Applications of LLMs Machine Learning
text, spanning more than 100 languages. This has significantly improved its ability to understand, generate and translate nuanced text — including idioms, poems and riddles — across a wide variety of languages, a hard problem to solve. PaLM 2 also passes advanced language proficiency exams at the “mastery” level. • Reasoning: PaLM 2’s wide-ranging dataset includes scientific papers and web pages that contain mathematical expressions. As a result, it demonstrates improved capabilities in logic, common sense reasoning, and mathematics. • Coding: PaLM 2 was pre-trained on a large quantity of publicly available source code datasets. This means that it excels at popular programming languages like Python and JavaScript, but can also generate specialized code in languages like Prolog, Fortran and Verilog. PaLM 2 (Pathway Language Model) - Google Machine Learning
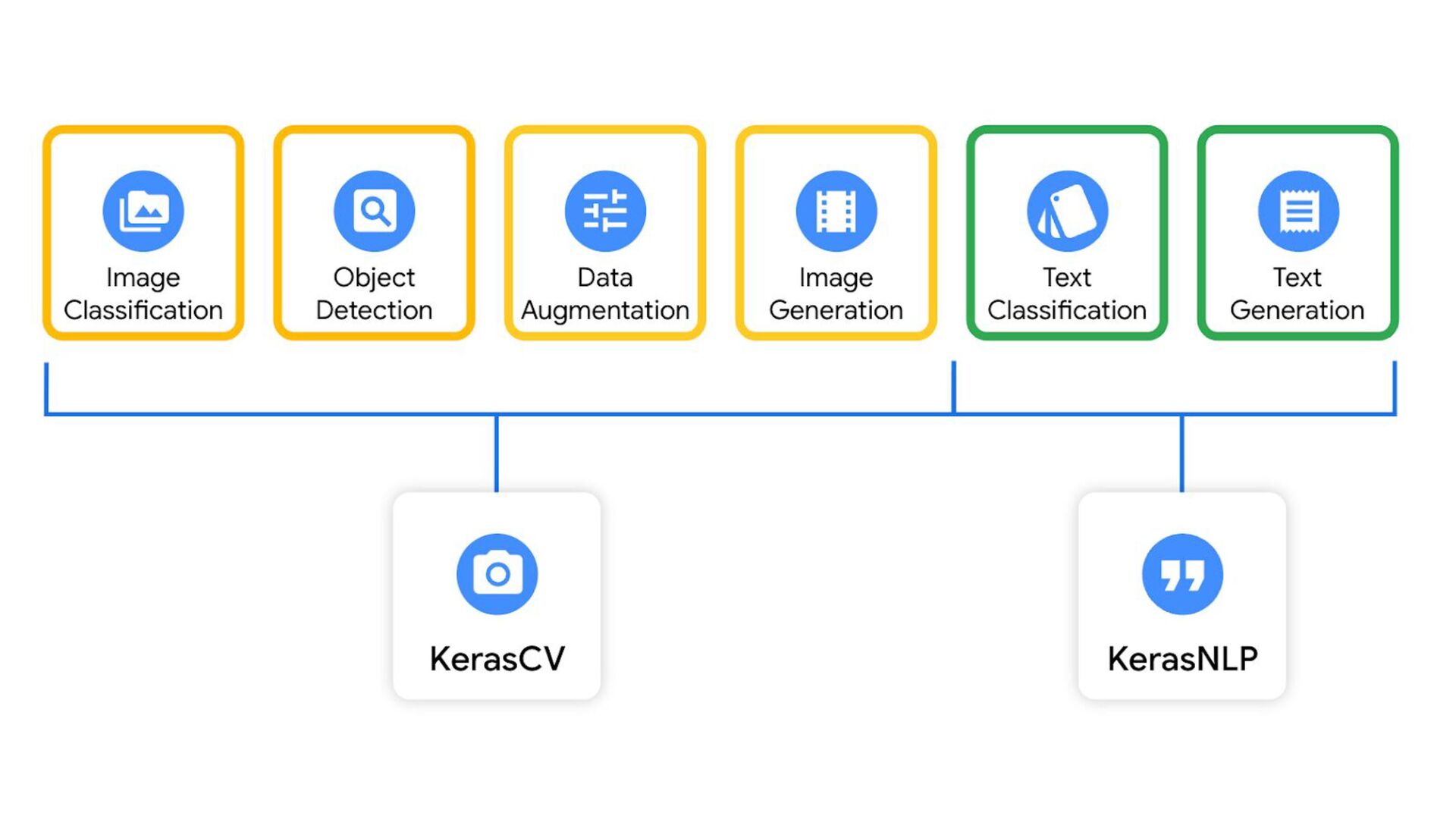
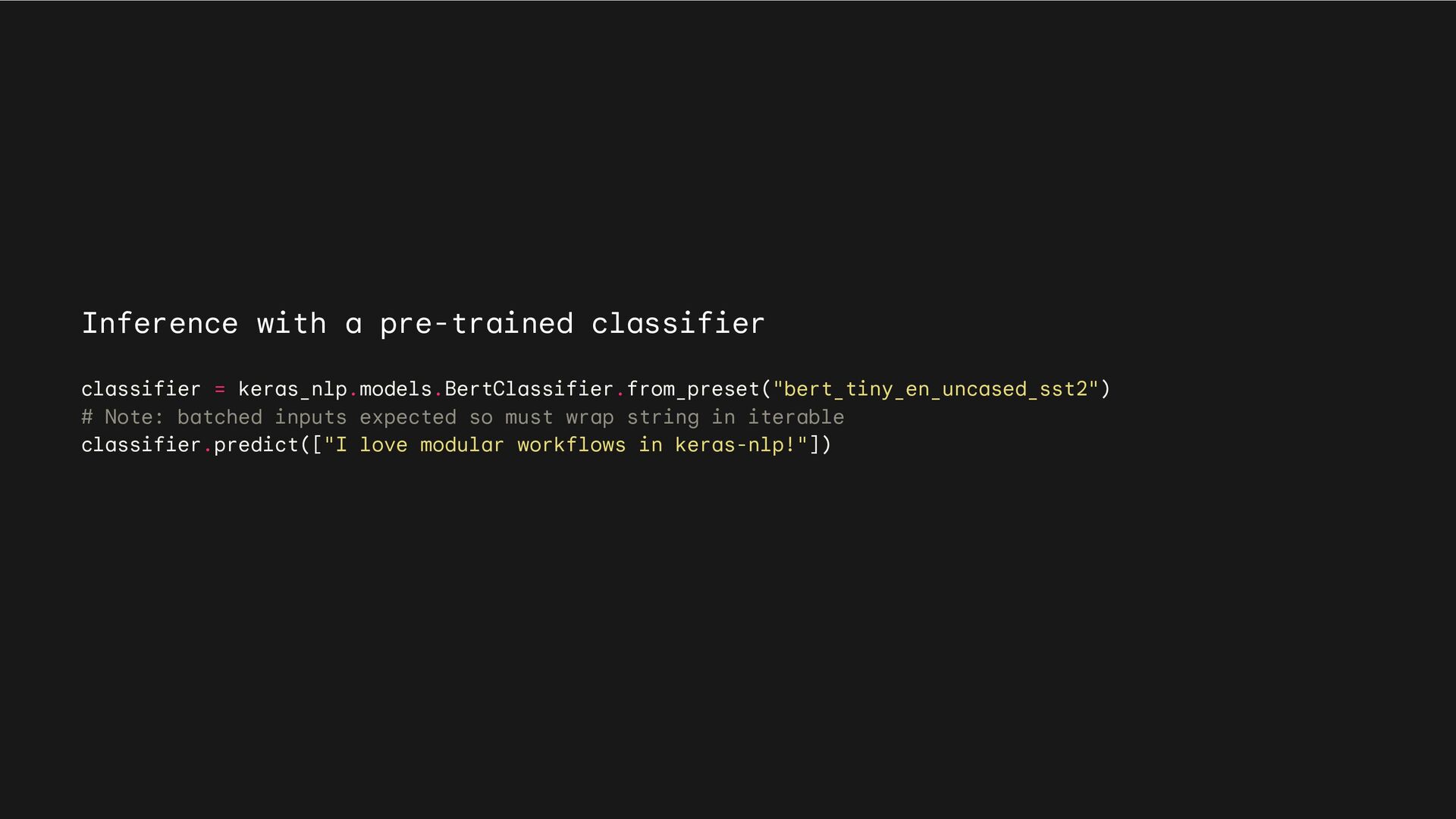
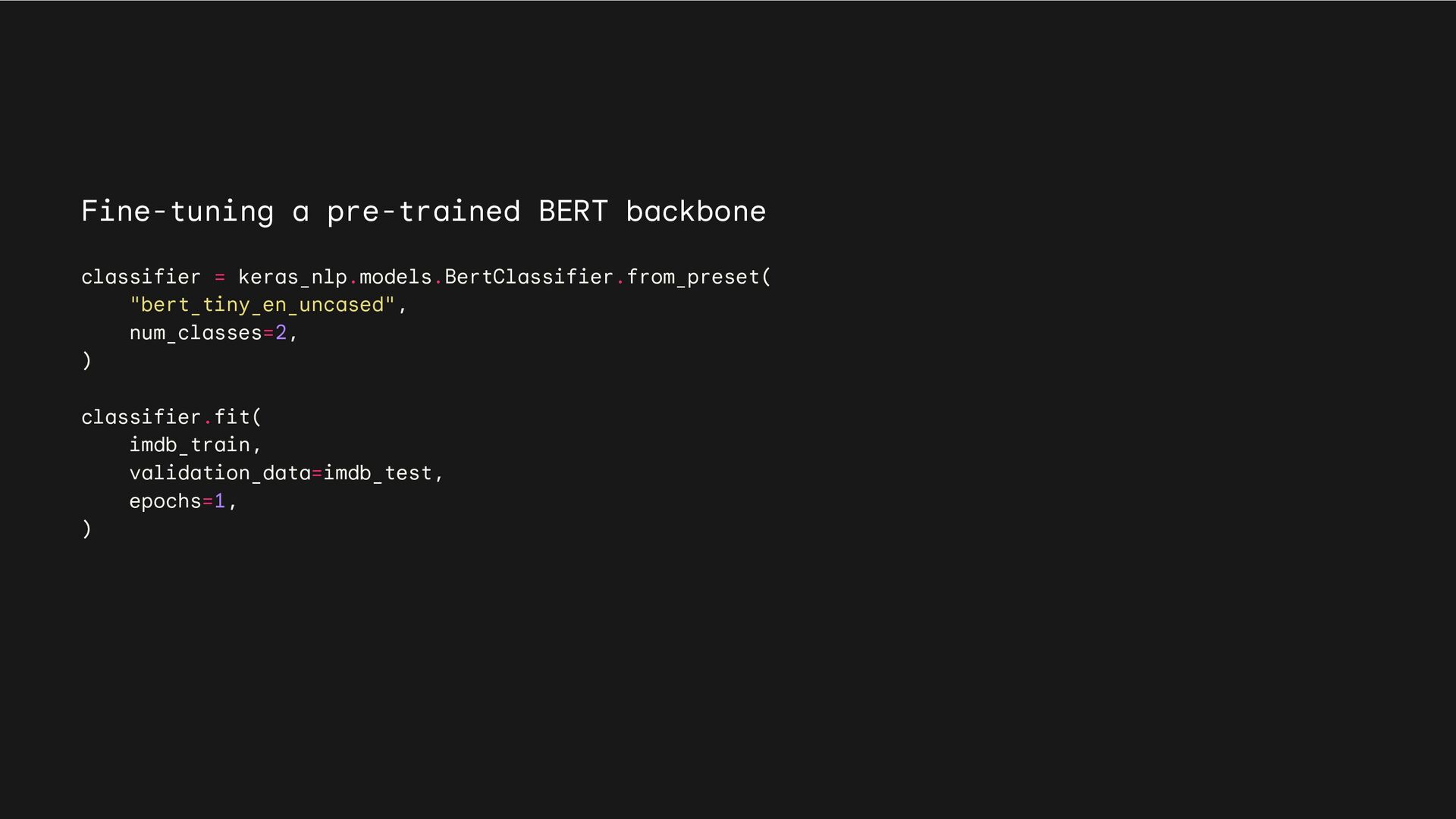
ids. • What it does: Converts strings to a dictionary of preprocessed tensors consumed by the backbone, starting with tokenization. Tokenizer Preprocessor • What it does: Converts preprocessed tensors to dense features. Does not handle strings; call the preprocessor first. Backbone KerasNLP API Task • What it does: Converts strings to task-specific output (e.g., classification probabilities).
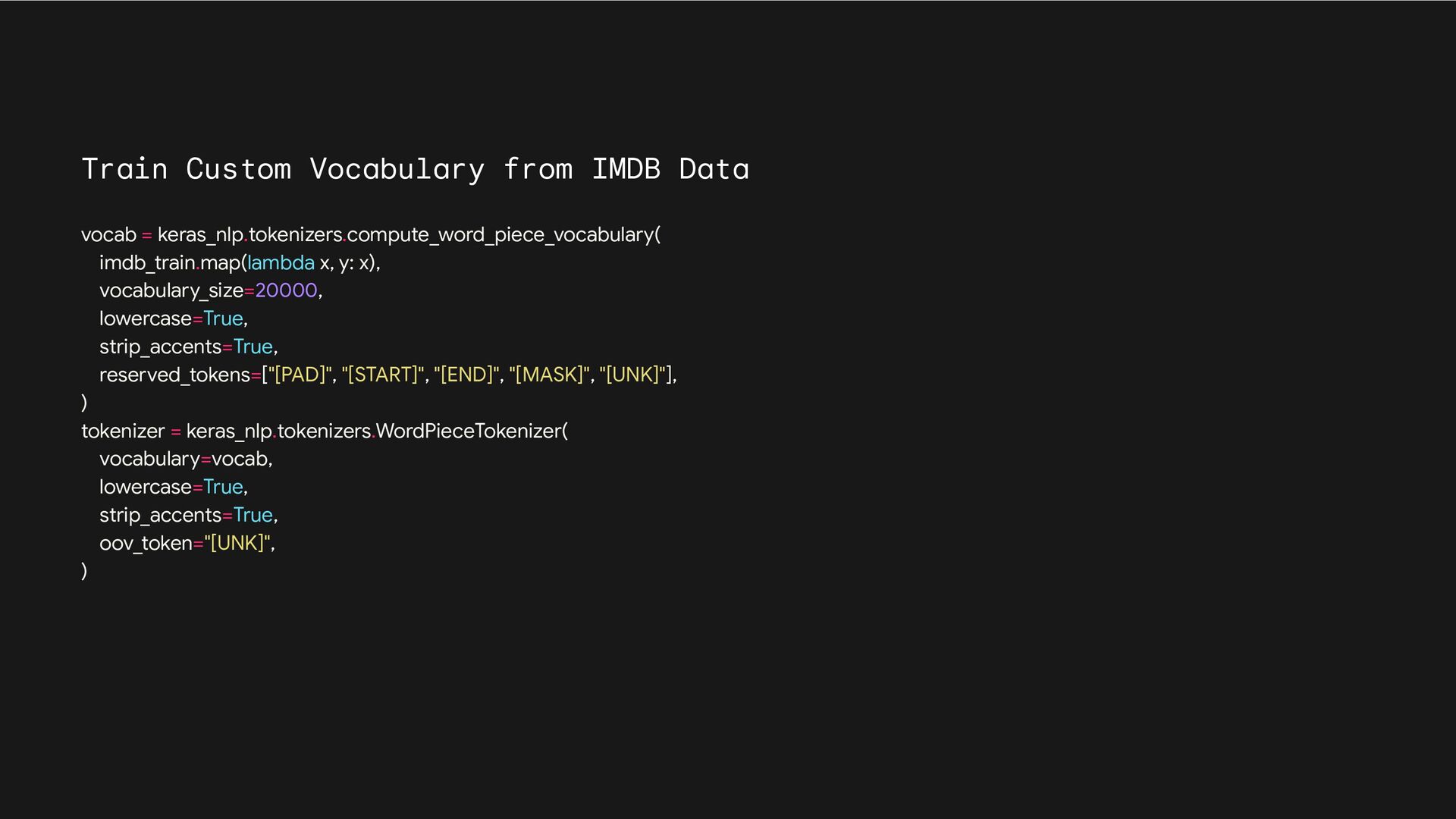
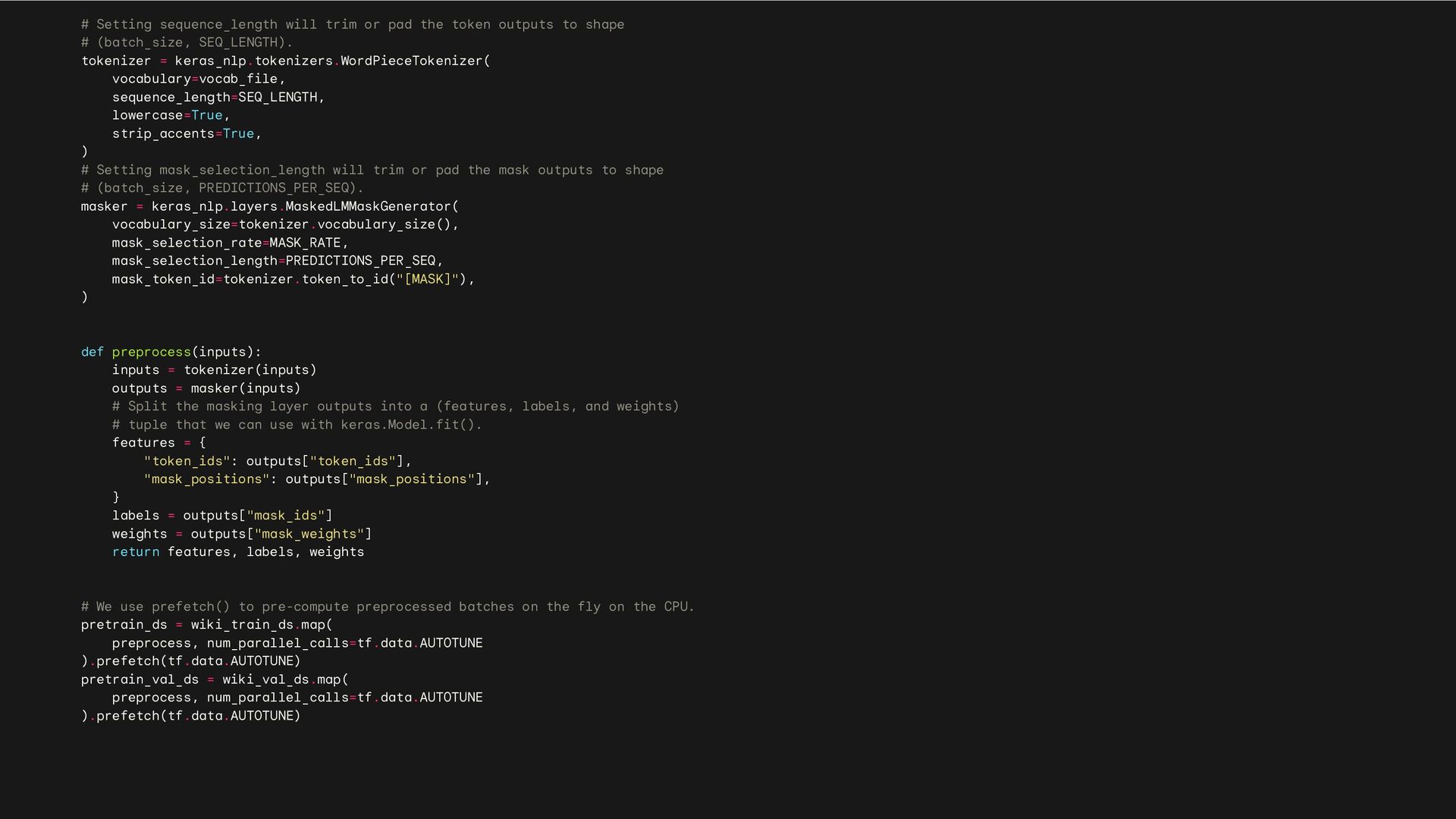
to shape # (batch_size, SEQ_LENGTH). tokenizer = keras_nlp.tokenizers.WordPieceTokenizer( vocabulary=vocab_file, sequence_length=SEQ_LENGTH, lowercase=True, strip_accents=True, ) # Setting mask_selection_length will trim or pad the mask outputs to shape # (batch_size, PREDICTIONS_PER_SEQ). masker = keras_nlp.layers.MaskedLMMaskGenerator( vocabulary_size=tokenizer.vocabulary_size(), mask_selection_rate=MASK_RATE, mask_selection_length=PREDICTIONS_PER_SEQ, mask_token_id=tokenizer.token_to_id("[MASK]"), ) def preprocess(inputs): inputs = tokenizer(inputs) outputs = masker(inputs) # Split the masking layer outputs into a (features, labels, and weights) # tuple that we can use with keras.Model.fit(). features = { "token_ids": outputs["token_ids"], "mask_positions": outputs["mask_positions"], } labels = outputs["mask_ids"] weights = outputs["mask_weights"] return features, labels, weights # We use prefetch() to pre-compute preprocessed batches on the fly on the CPU. pretrain_ds = wiki_train_ds.map( preprocess, num_parallel_calls=tf.data.AUTOTUNE ).prefetch(tf.data.AUTOTUNE) pretrain_val_ds = wiki_val_ds.map( preprocess, num_parallel_calls=tf.data.AUTOTUNE ).prefetch(tf.data.AUTOTUNE)
http://ruder.io/transfer-learning/, 2017. Abonia S., Ashish P., "Large Languge model(LLM) CheatSheet", Medium-Github, 2023. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics. Yoshua Bengio, Réjean Ducharme, Pascal Vincent, and Christian Janvin. 2003. A neural probabilistic language model. J. Mach. Learn. Res. 3, (3/1/2003), 1137–1155. Stanford Large Language Model Course (https://stanford-cs324.github.io/winter2022/lectures/introduction/) Watson, , Qian, Jonathan, Bischof, François, Chollet, and others. "KerasNLP." . (2022). (https://keras.io/keras_nlp/)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Proprocess data with a custom tokenizer packer = keras_nlp.layers.StartEndPacker( start_value=tokenizer.token_to_id("[START]"),](https://files.speakerdeck.com/presentations/2d078f727cb94533ab85ce6eb627a5c7/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}