- You can use Waterdrop directly, but it’s better to use Responders as they provide some extras and are more convenient to use - There is already version 2.0, although current Karafka version (1.4) uses 1.4 version of Waterdrop, so keep that in mind when reading docs
to Kafka can get some extra performance gain - Somewhat protective against Kafka being unavailable - Could lead to loss of messages (some of them might no be published at all)
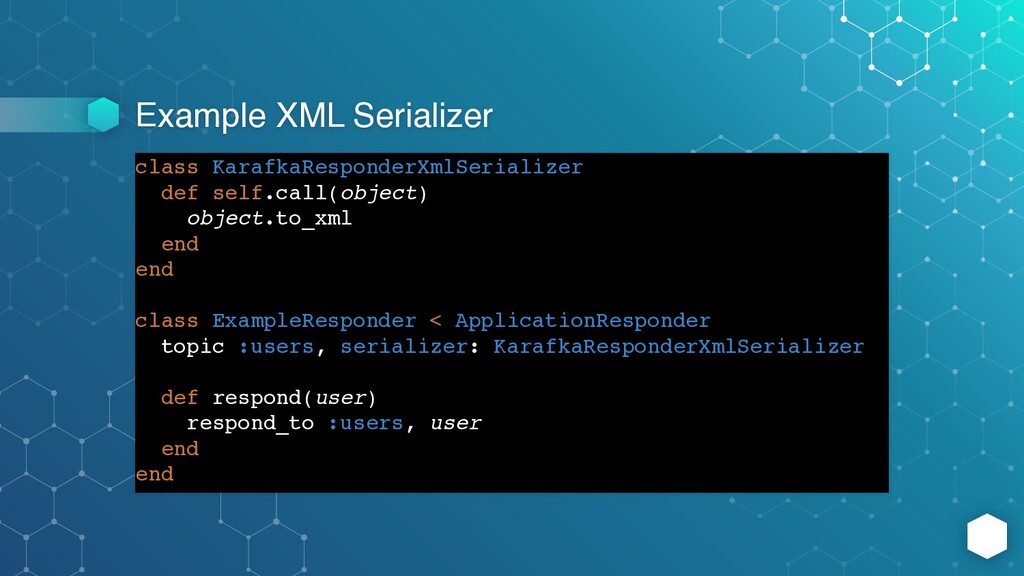
class ExampleResponder < ApplicationResponder topic :users, serializer: KarafkaResponderXmlSerializer def respond(user) respond_to :users, user end end
page_id: 1 end end class PagesResponder < ApplicationResponder topic :pages_from_consumer def respond(payload_with_page_id) respond_to :pages_from_consumer, payload_with_page_id end end
RSpec.describe UsersConsumer do subject(:consumer) { karafka_consumer_for(:users) } before do publish_for_karafka({ "user_id" => 1 }.to_json) end it "does some stuff" do # some potential mock consumer.consume # do some assertion here end end
end RSpec.describe UsersResponder do subject(:responder) { described_class.new } describe "#call" do let(:payload) { { "user_id" => 1 } } let(:data) do [[payload.to_json, { topic: "users" }]] end it "publishes stuff" do responder.call(payload) expect(responder.messages_buffer["users"]).to eq data end end end
= :sidekiq end end class ApplicationWorker < Karafka::BaseWorker end #2 KarafkaApp.routes.draw do consumer_group :example_consumer_group do topic :users do backend :sidekiq consumer UserConsumer worker KarafkaWorkers::UserWorker interchanger Interchangers:UserInterchanger # optional end end end
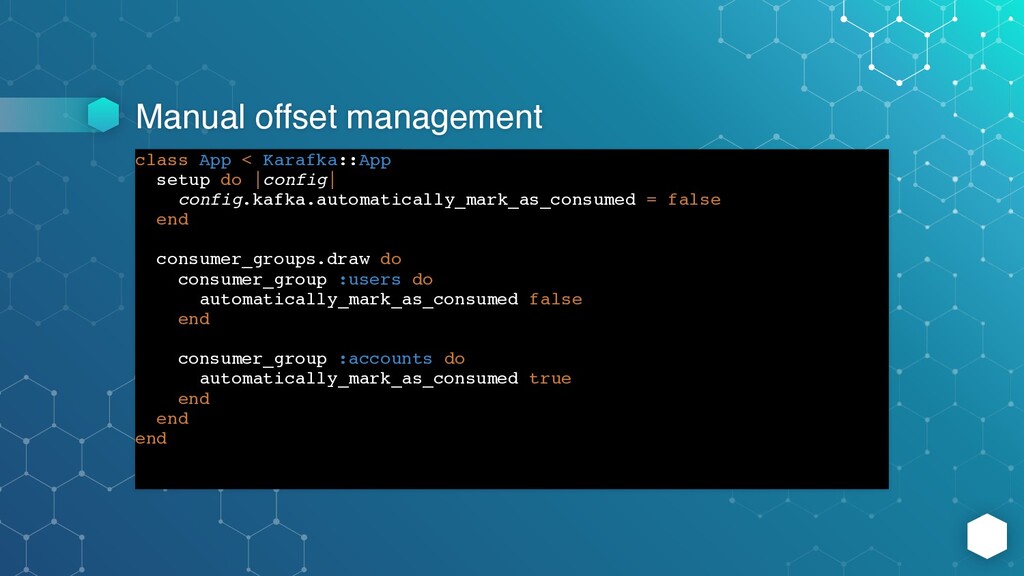
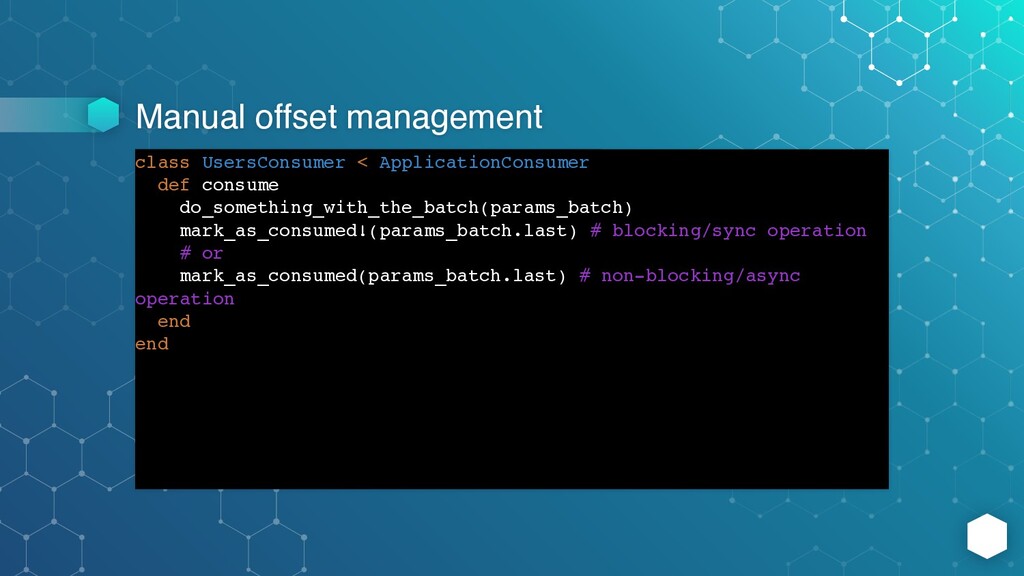
you are doing and why, in most cases you don’t need that feature - Karafka handles offset management out-of- box - it commits offsets after processing individual message or a batch (depending on “batch_fetching” setting) -
config.kafka.automatically_mark_as_consumed = false end consumer_groups.draw do consumer_group :users do automatically_mark_as_consumed false end consumer_group :accounts do automatically_mark_as_consumed true end end end
- If the consumer blows up with an error, it will stop for a while (configurable) and retry later - The messages will never be skipped - That means that the consumer will get stuck and not process any other messages until the issue is addressed
- By default, the worker will retry consuming every 10 seconds (configurable via ” pause_timeout” config param) - You can also enable exponential backoff (”pause_exponential_backoff” - disabled by default). Might be a good idea also to set ”pause_max_timeout” to not let the retry delay go out of control
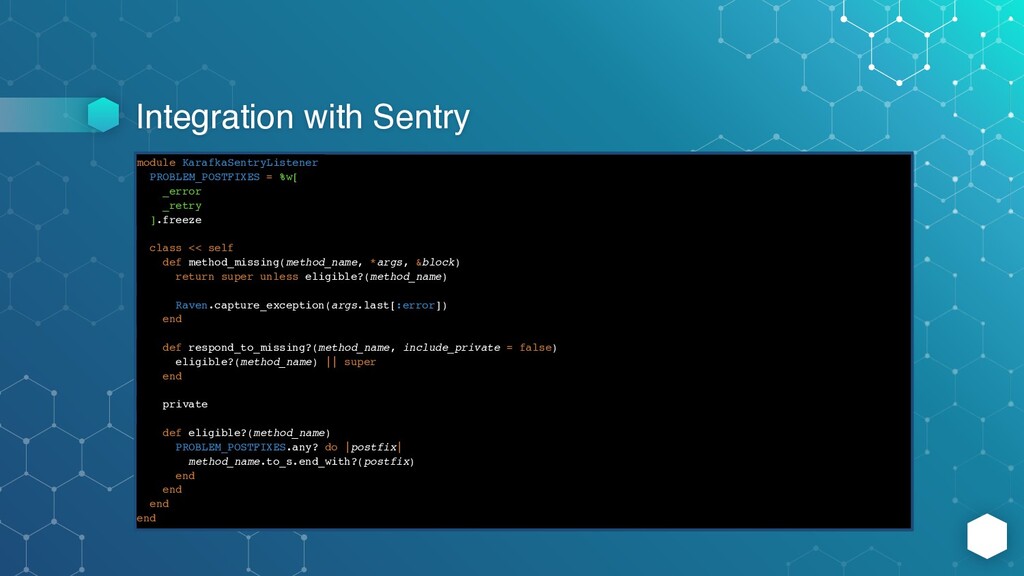
].freeze class << self def method_missing(method_name, *args, &block) return super unless eligible?(method_name) Raven.capture_exception(args.last[:error]) end def respond_to_missing?(method_name, include_private = false) eligible?(method_name) || super end private def eligible?(method_name) PROBLEM_POSTFIXES.any? do |postfix| method_name.to_s.end_with?(postfix) end end end end
*args, &block) return super unless method_name.to_s.end_with?("_error") NewRelic::Agent.notice_error(args.last[:error]) end def respond_to_missing?(method_name, include_private = false) method_name.to_s.end_with?("_error") || super end end end
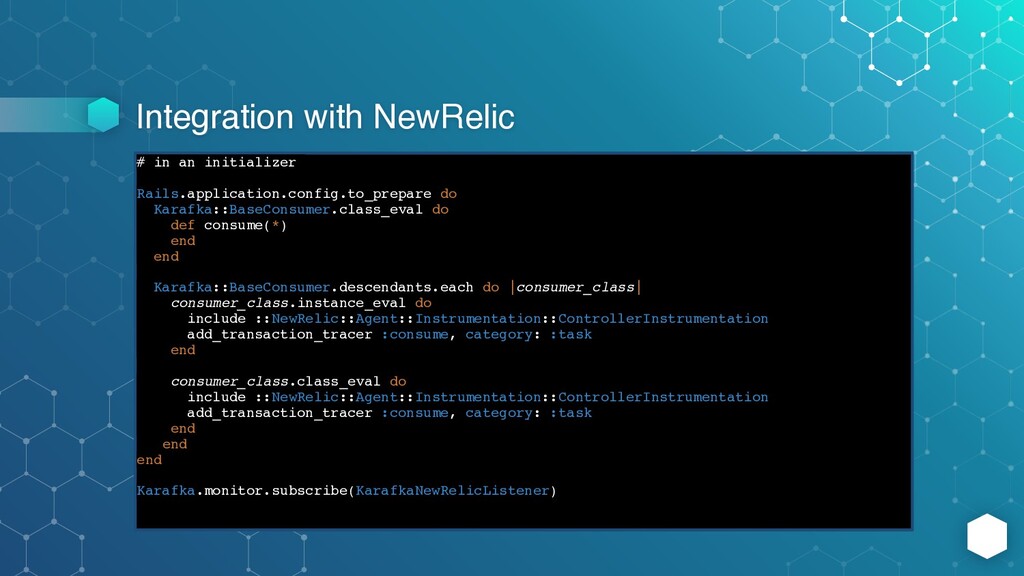
do def consume(*) end end Karafka::BaseConsumer.descendants.each do |consumer_class| consumer_class.instance_eval do include ::NewRelic::Agent::Instrumentation::ControllerInstrumentation add_transaction_tracer :consume, category: :task end consumer_class.class_eval do include ::NewRelic::Agent::Instrumentation::ControllerInstrumentation add_transaction_tracer :consume, category: :task end end end Karafka.monitor.subscribe(KarafkaNewRelicListener)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}