Continuous delivery and devops have gone mainstream, at least in terms of mindshare. As a result, a lot of vendors have jumped onto the bandwagon. Most products that have anything to do with deployment now try to associate themselves with devops and continuous delivery. In this webinar sponsored by ThoughtWorks Studios, I try to clear the air in a product independent manner. I also cover common devops anti-patterns and explain the idea of infrastructure as code.
As it turns out, this is as much a talk on the design of an effective Agile IT Organization design as it is a talk on the stated topic. Things are inter-related.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
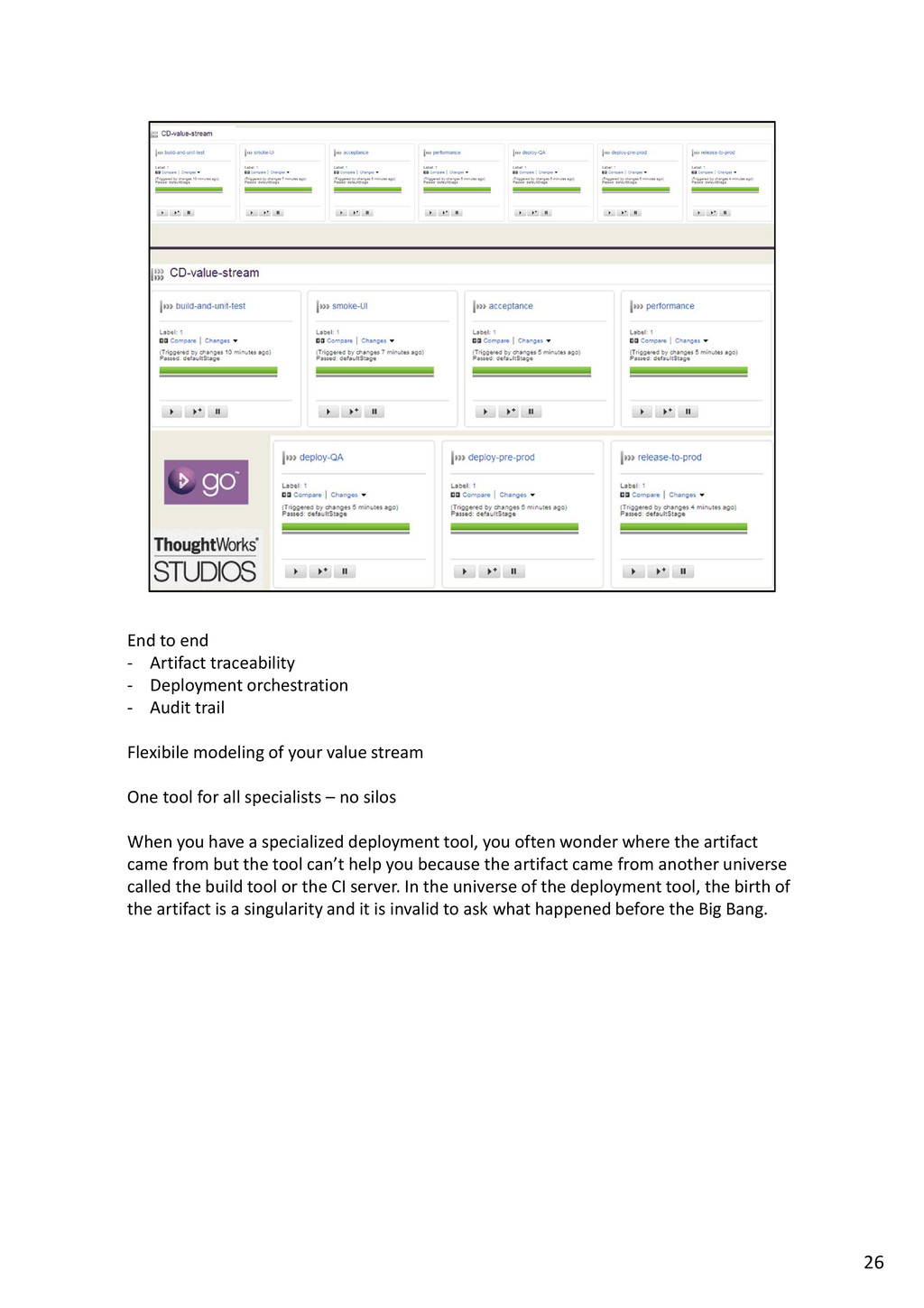
{kind=link}
{kind=link}
{kind=link}
{kind=link}
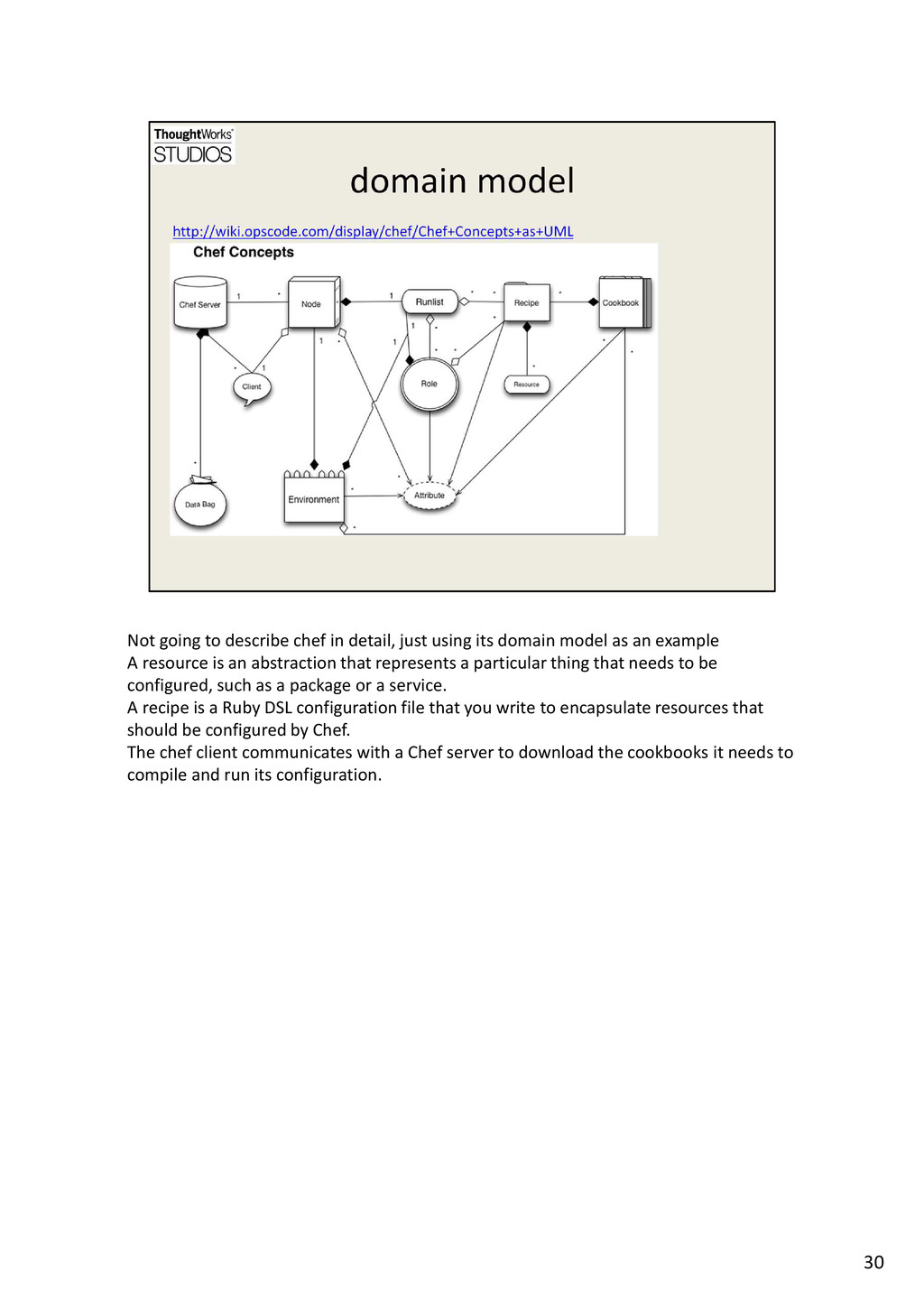
{kind=link}
{kind=link}
{kind=link}
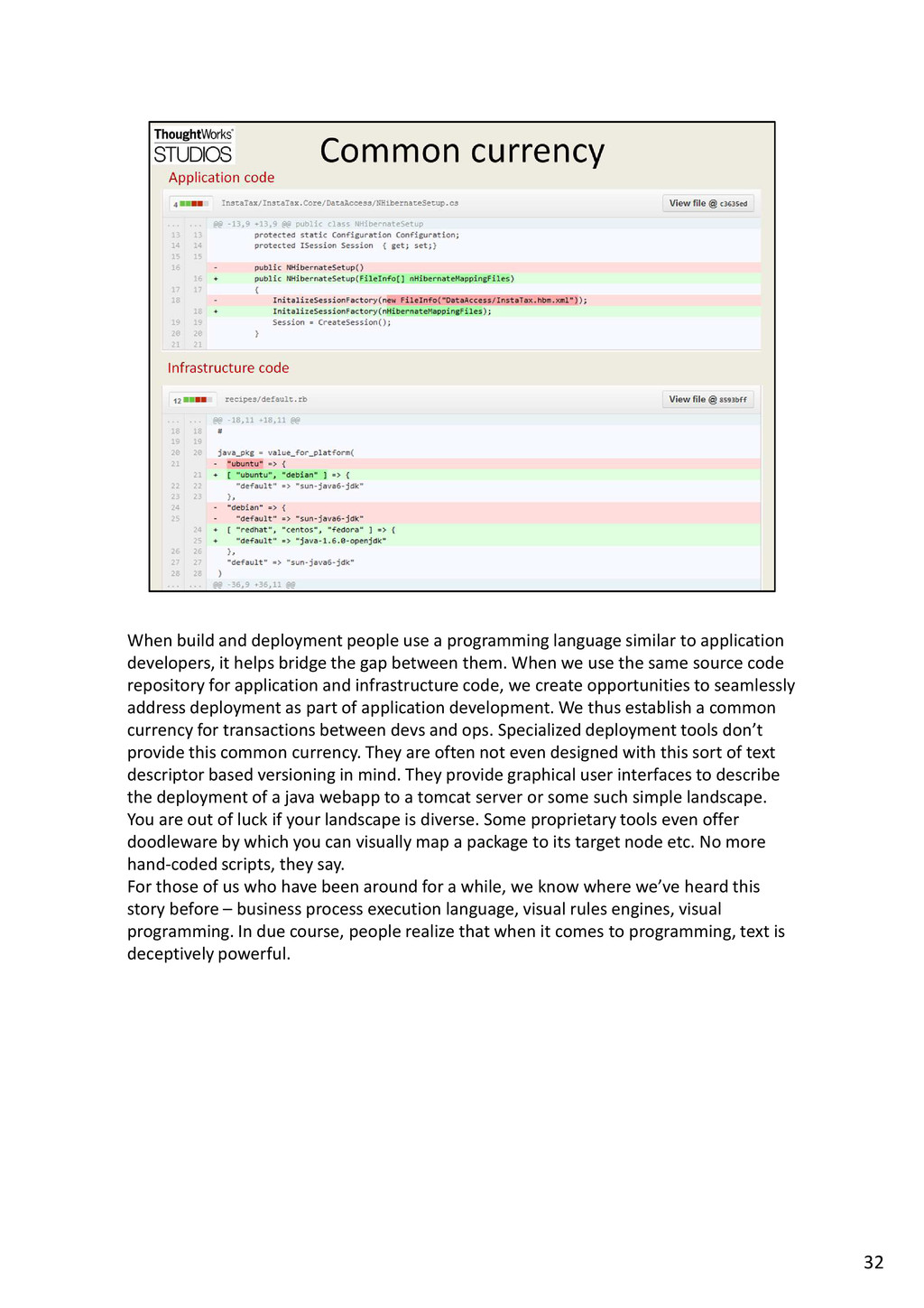
{kind=link}
{kind=link}
{kind=link}
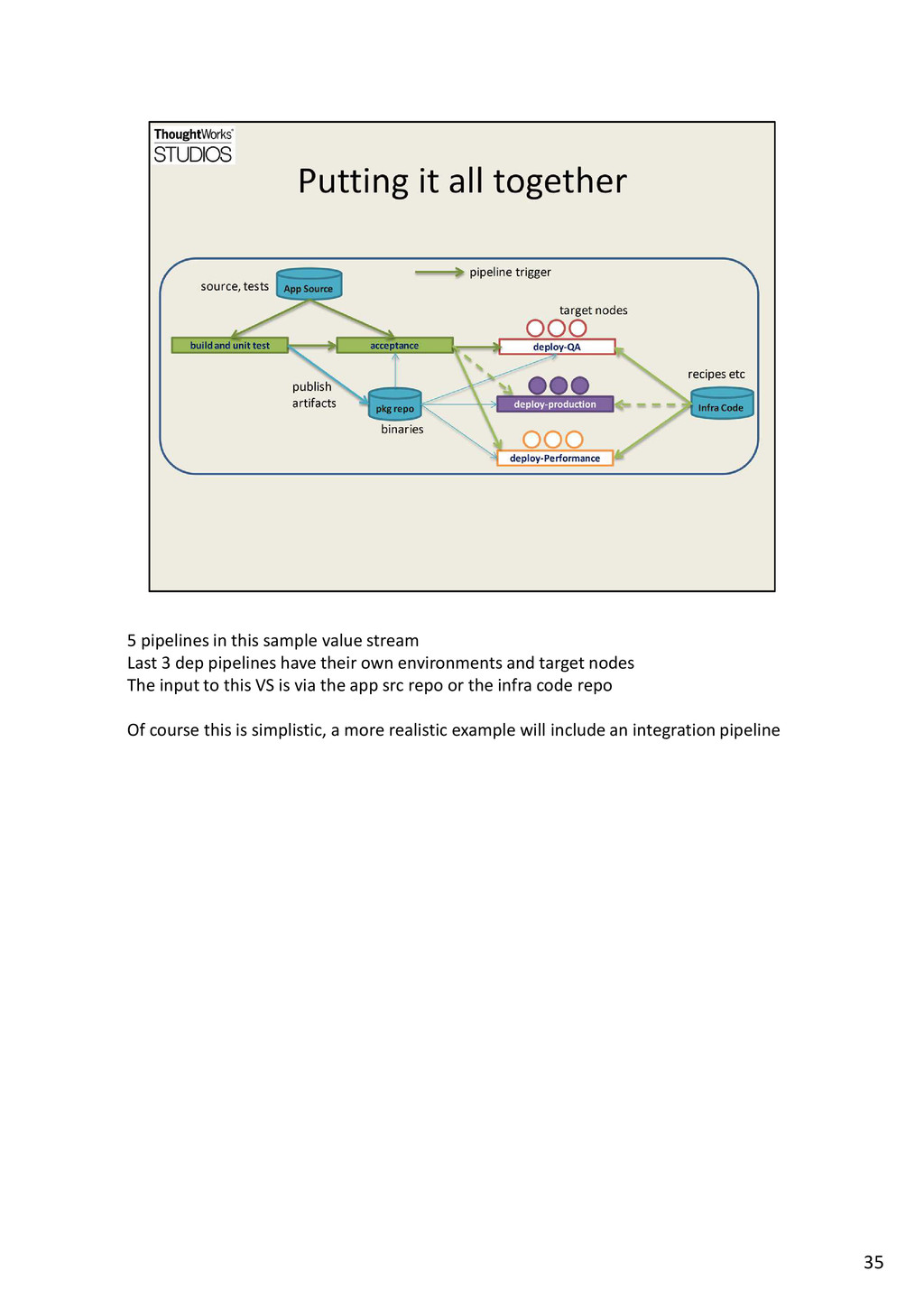
{kind=link}
{kind=link}