To make communication more natural – To make interaction more expressive – Better support in mental health • Imagine when you are angry and your AI assistant make you more angry – Many potential applications • AI assistant • Call service
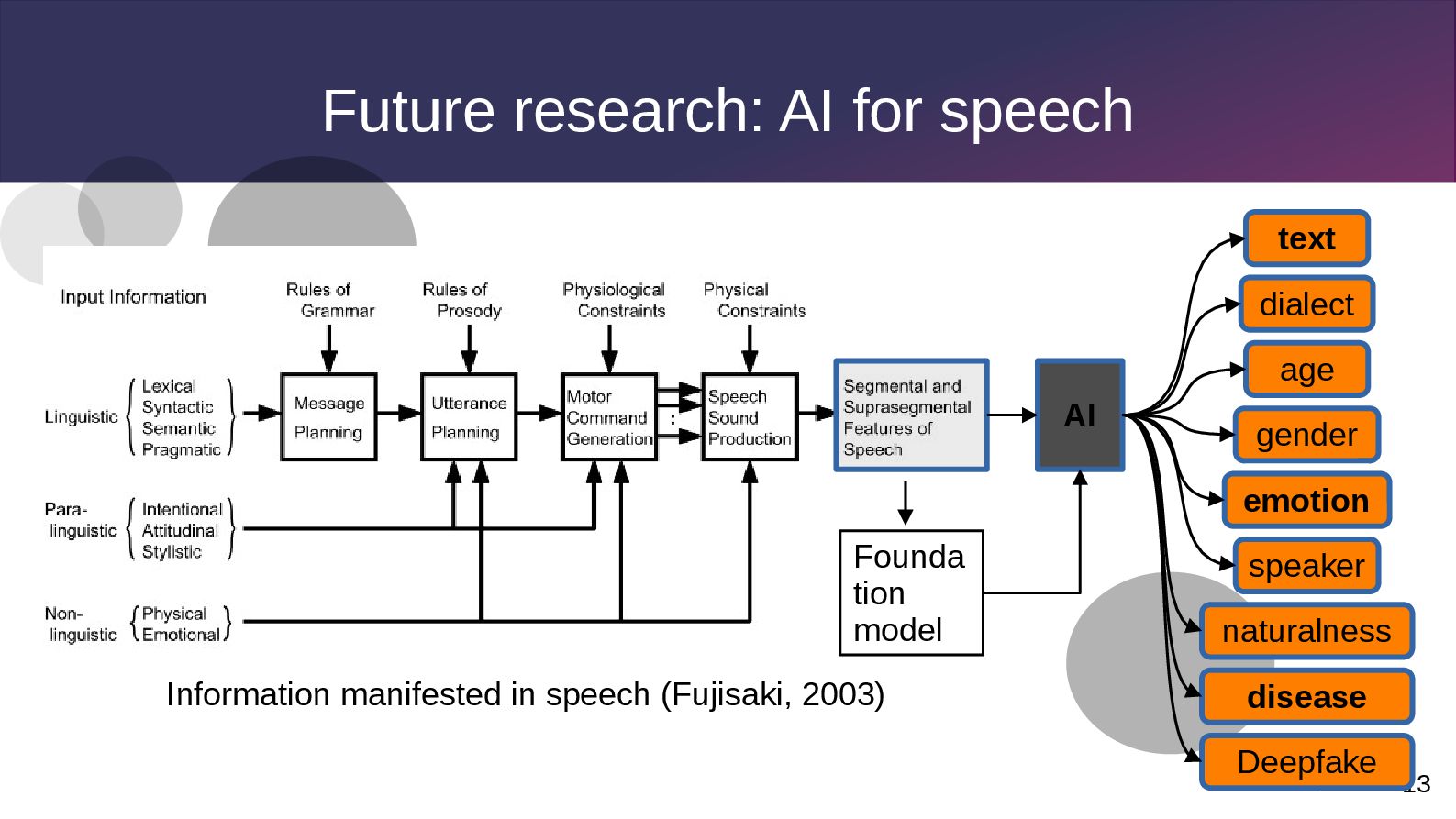
can understand, recognize and respond to human emotions. • In speech – Recognize: speech → text (ASR), speech → emotion – Understand: elicit appropriate response – Respond: text → speech (TTS), emotional speech • This presentation will explore mainly on speech emotion recognition (SER) from basic, multimodal, multitask, and multilingual setting.
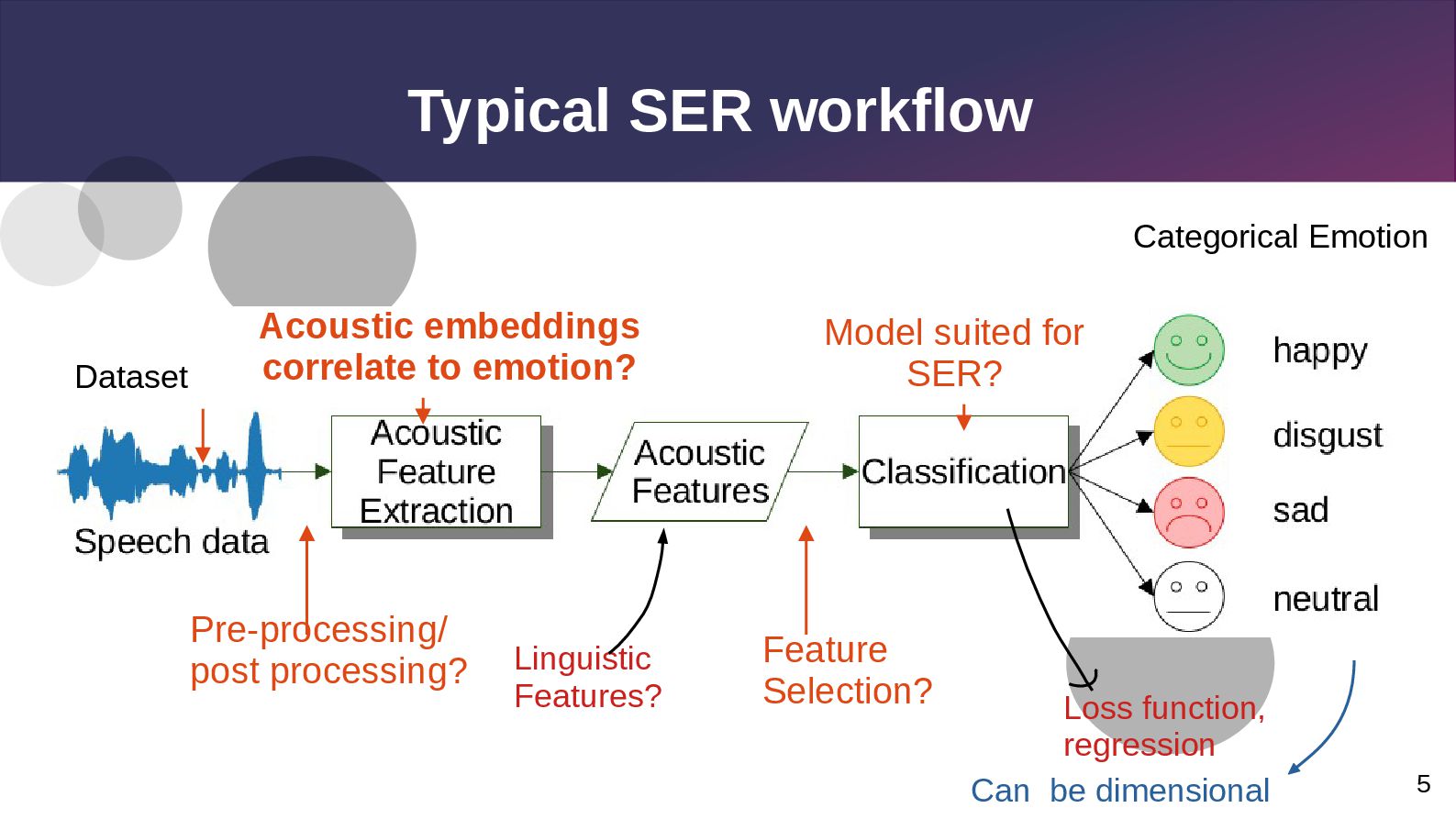
Model suited for SER? Pre-processing/ post processing? Feature Selection? Categorical Emotion Loss function, regression Linguistic Features? Can be dimensional
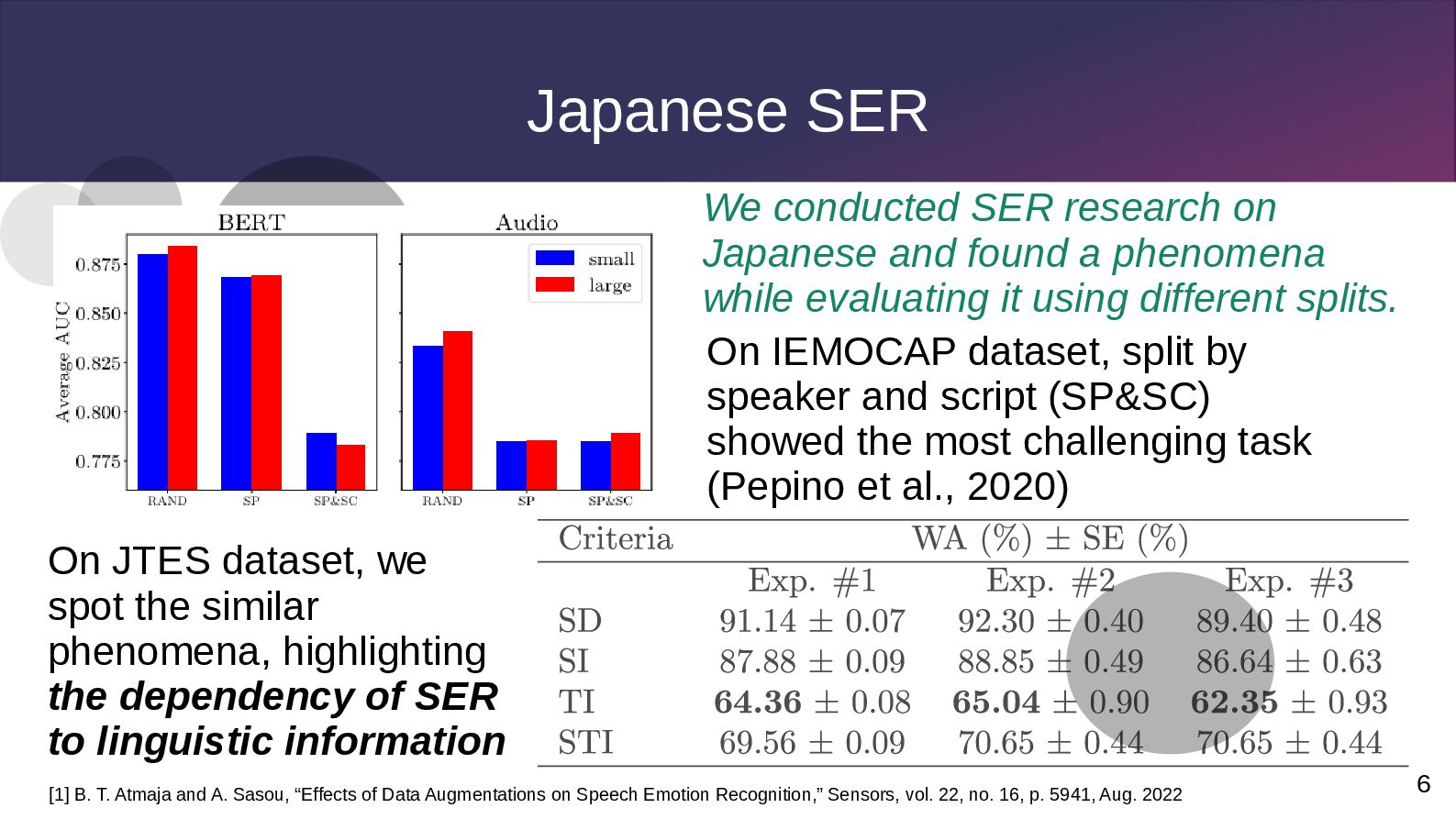
script (SP&SC) showed the most challenging task (Pepino et al., 2020) On JTES dataset, we spot the similar phenomena, highlighting the dependency of SER to linguistic information We conducted SER research on Japanese and found a phenomena while evaluating it using different splits. [1] B. T. Atmaja and A. Sasou, “Effects of Data Augmentations on Speech Emotion Recognition,” Sensors, vol. 22, no. 16, p. 5941, Aug. 2022
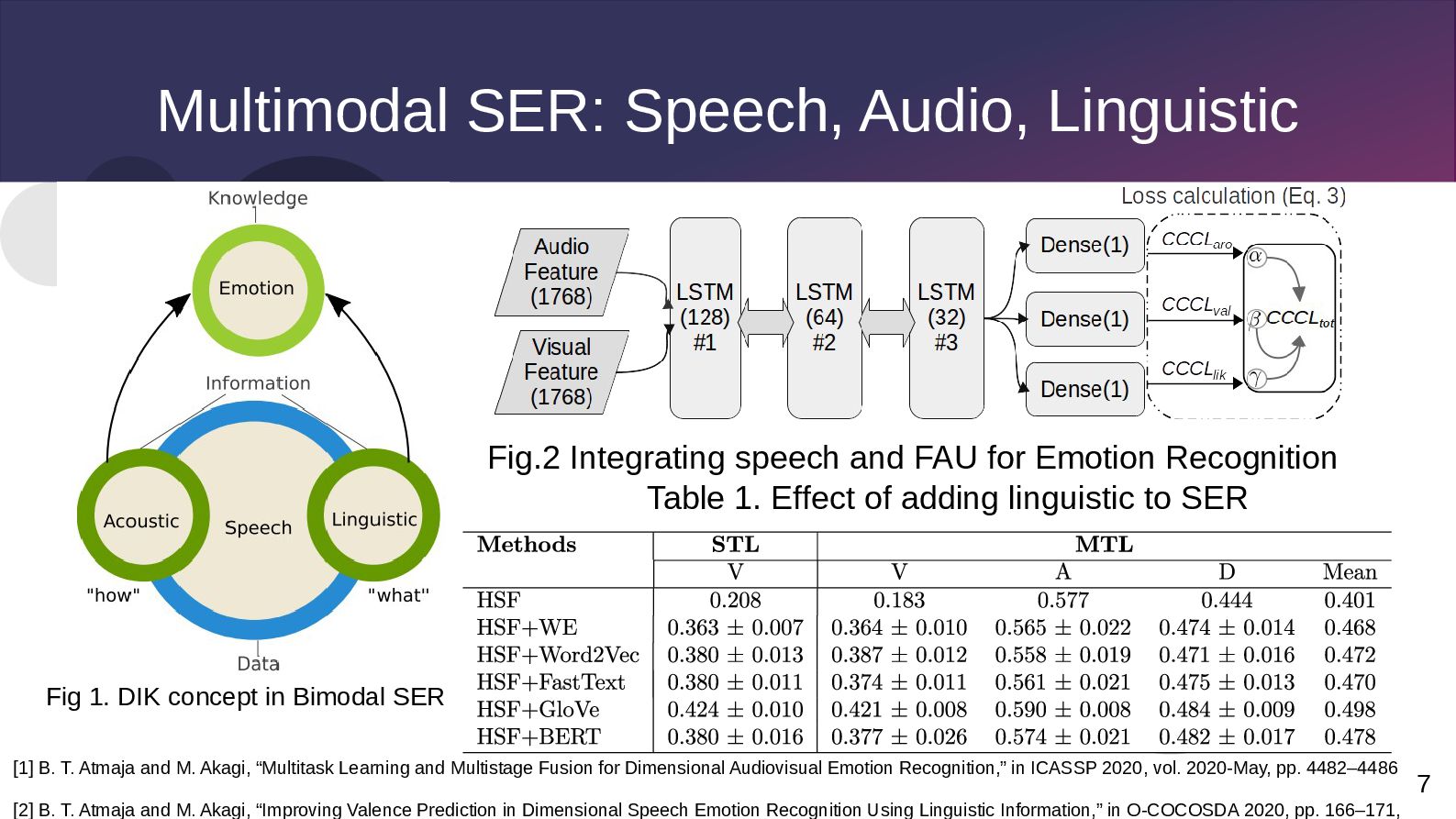
FAU for Emotion Recognition Fig 1. DIK concept in Bimodal SER Table 1. Effect of adding linguistic to SER [1] B. T. Atmaja and M. Akagi, “Multitask Learning and Multistage Fusion for Dimensional Audiovisual Emotion Recognition,” in ICASSP 2020, vol. 2020-May, pp. 4482–4486 [2] B. T. Atmaja and M. Akagi, “Improving Valence Prediction in Dimensional Speech Emotion Recognition Using Linguistic Information,” in O-COCOSDA 2020, pp. 166–171,
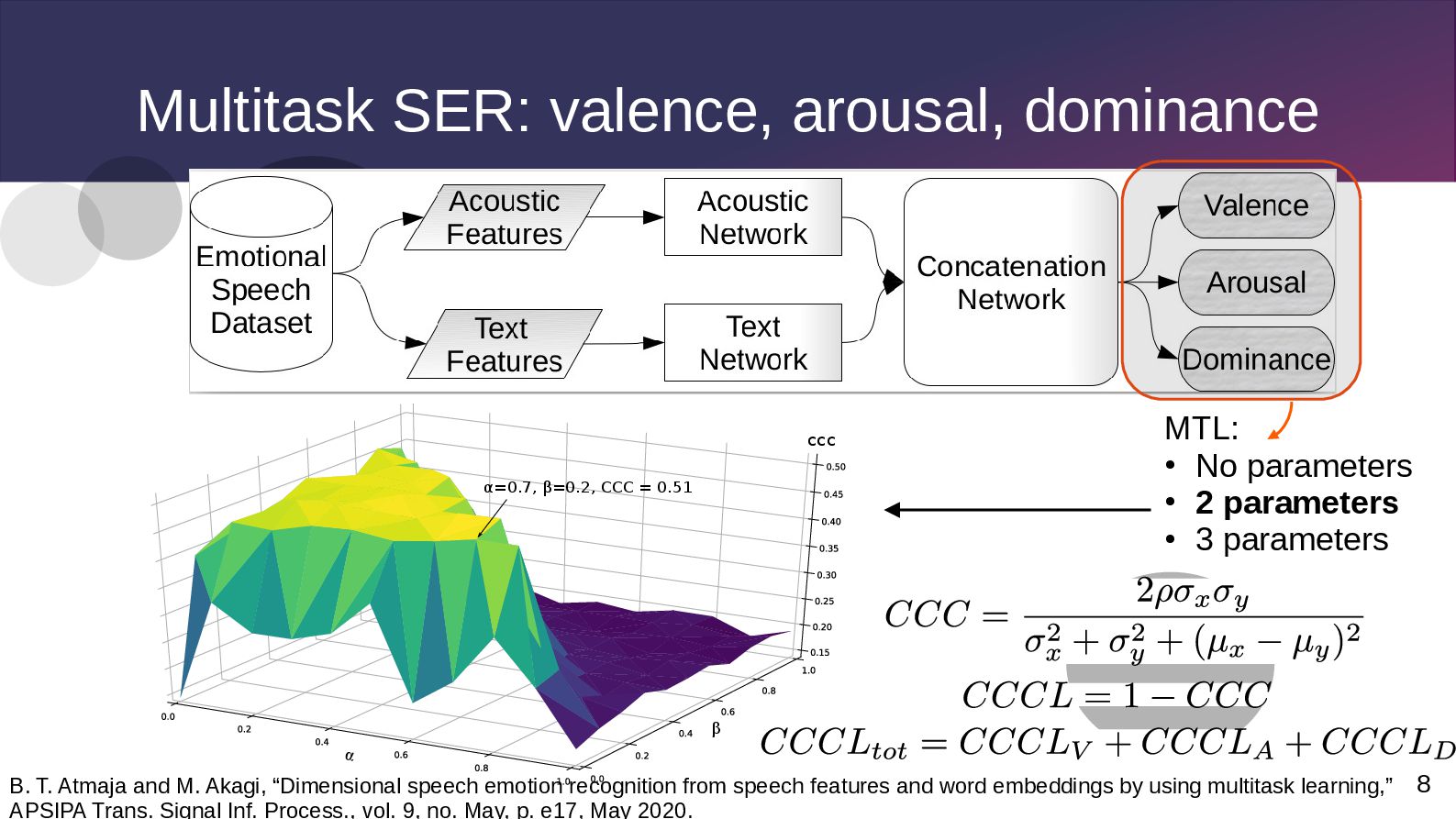
CCC = 0.51 ccc MTL: • No parameters • 2 parameters • 3 parameters B. T. Atmaja and M. Akagi, “Dimensional speech emotion recognition from speech features and word embeddings by using multitask learning,” APSIPA Trans. Signal Inf. Process., vol. 9, no. May, p. e17, May 2020.
A. Sasou, and M. Akagi, “Automatic Naturalness Recognition from Acted Speech Using Neural Networks,” in APSIPA Annual Summit and Conference, 2021, pp. 731–736. [2] B. T. Atmaja, A. Sasou, and M. Akagi, “Speech Emotion and Naturalness Recognitions with Multitask and Single- task Learnings,” IEEE Access, pp. 1–1, 2022, doi: 10.1109/ACCESS.2022. 3189481.
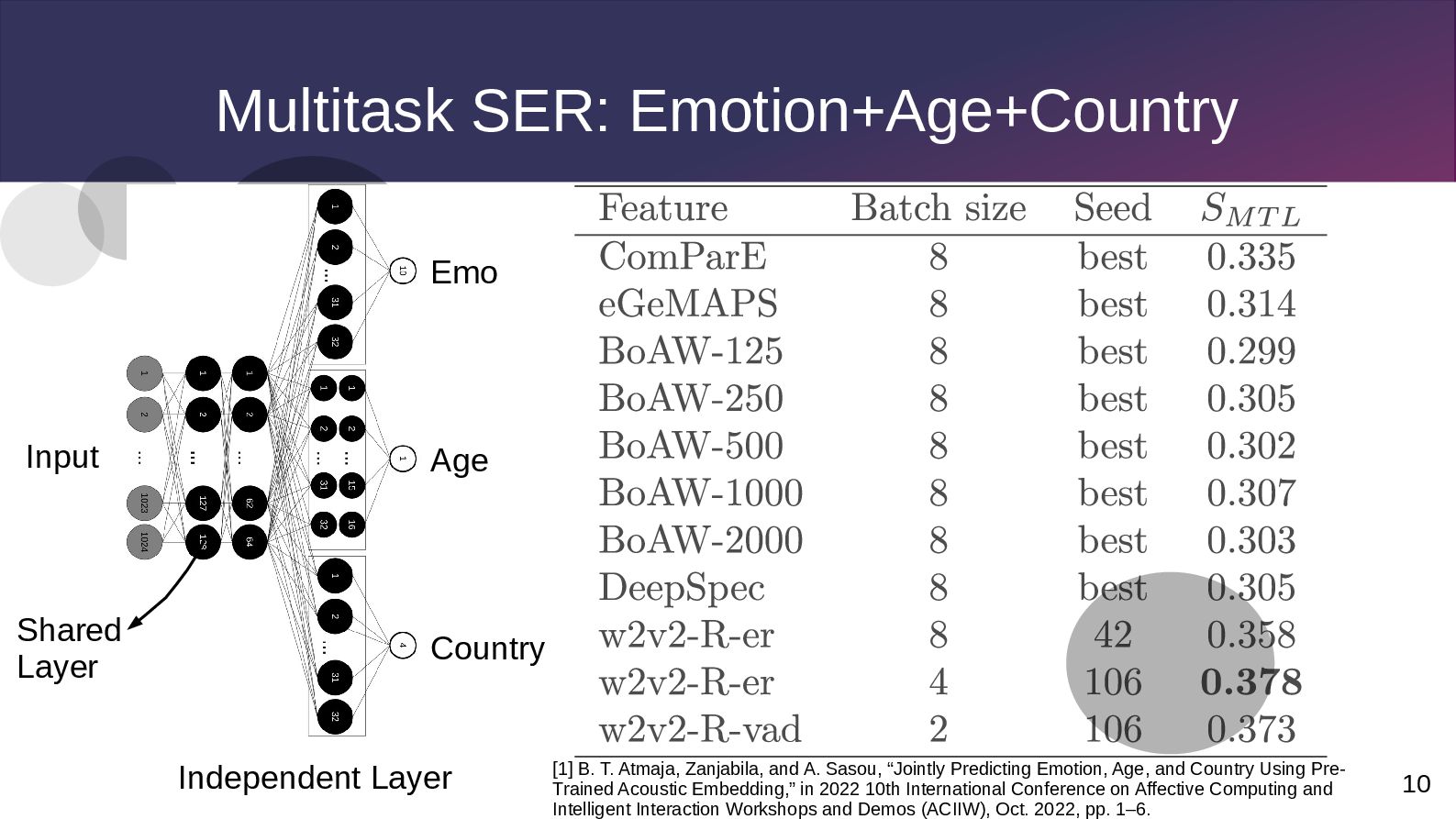
Independent Layer [1] B. T. Atmaja, Zanjabila, and A. Sasou, “Jointly Predicting Emotion, Age, and Country Using Pre- Trained Acoustic Embedding,” in 2022 10th International Conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW), Oct. 2022, pp. 1–6.
“Multilingual, Cross-lingual, and Monolingual Speech Emotion Recognition on EmoFilm Dataset,” in 2023 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Oct. 2023, pp. 1019–1025. Multilingual Evaluation
T. Atmaja and A. Sasou, “Ensembling Multilingual Pre-Trained Models for Predicting Multi-Label Regression Emotion Share from Speech,” in 2023 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Oct. 2023, pp. 1026–1029, . What is Ensemble learning? →
recognizing cat or dog which is clearly separable, we can only estimate to get as high as possible but impossible to get perfect score. • Data vs. model: data now is more important than model, data- driven research could provide better insights than direct modeling. • Although mimicking how human learn is useful, machine not necessary to follow strictly how human learns (e.g., multitask learning, multilingual). • Speech can be used to learn many tasks, it also can be combined with other modalities to enhance learning process.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![9 Multitask SER: Emotion + Naturalness [1] B. T. Atmaja,](https://files.speakerdeck.com/presentations/d35cfe2e59484ee39b02184b62a04d99/slide_8.jpg){kind=link}
{kind=link}
![11 Multilingual SER [1] B. T. Atmaja and A. Sasou,](https://files.speakerdeck.com/presentations/d35cfe2e59484ee39b02184b62a04d99/slide_10.jpg){kind=link}
![12 Multilingual SER: Ensemble Learning Spearmann Correlation Test [1] B.](https://files.speakerdeck.com/presentations/d35cfe2e59484ee39b02184b62a04d99/slide_11.jpg){kind=link}
{kind=link}
{kind=link}