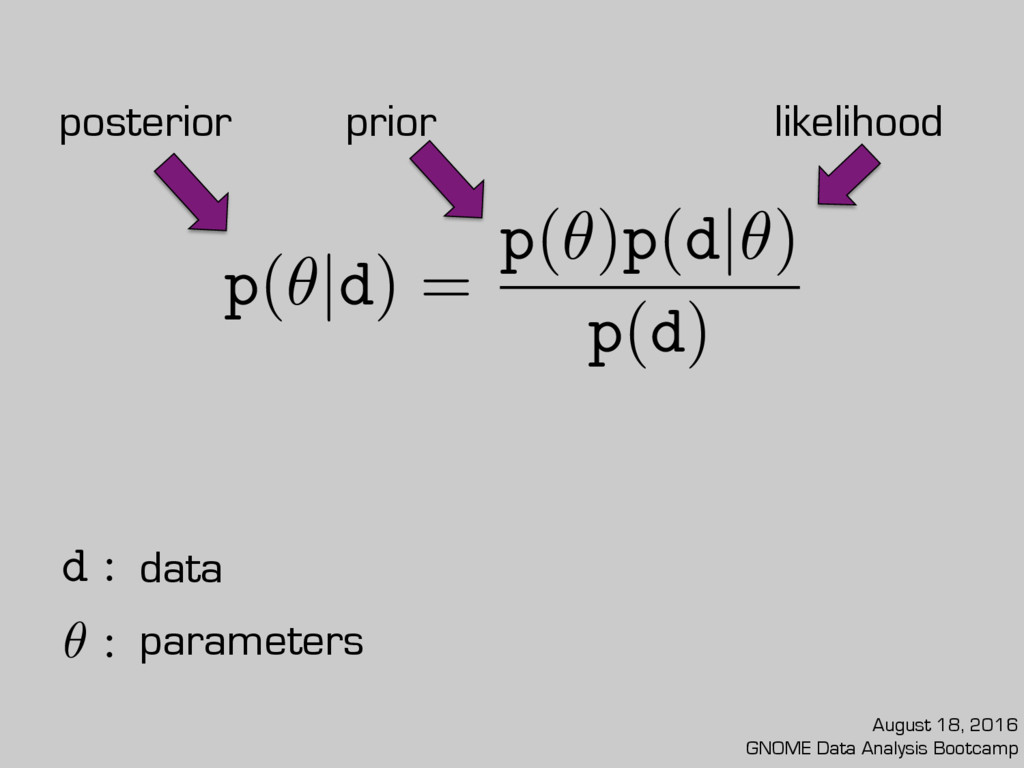
: ✓ : M : data parameters model = fully marginalized likelihood or “evidence” Without something to compare to, FML is not very useful... August 18, 2016 GNOME Data Analysis Bootcamp
p(MA |d) p(MB |d) Let’s have two models compete! Bayes Factor Prior on models Posterior Odds Ratio model A MA : MB : model B p(d|MA ) p(d|MB ) = R p(✓A |MA )p(d|✓A , MA )d✓A R p(✓B |MB )p(d|✓B , MB )d✓B August 18, 2016 GNOME Data Analysis Bootcamp
small, favor Otherwise, it’s not very decisive. p(d|MA ) p(d|MB ) ⇥ p(MA ) p(MB ) = p(MA |d) p(MB |d) MA MB “So, what do I do with this?” August 18, 2016 GNOME Data Analysis Bootcamp
small, favor Otherwise, it’s not very decisive. p(d|MA ) p(d|MB ) ⇥ p(MA ) p(MB ) = p(MA |d) p(MB |d) MA Takeaway #1: model comparison ≠ model selection “So, what do I do with this?” MB August 18, 2016 GNOME Data Analysis Bootcamp
probabilities. Model selection is a decision based on other (outside) factors, i.e. a cost function/utility. August 18, 2016 GNOME Data Analysis Bootcamp
based on other (outside) factors, i.e. a cost function/utility. Most rigorous thing to do is average all models, not select the most probable. Why model comparison ≠ model selection p(✓|d) = K X k=1 p(✓|d, Mk )p(Mk |d) August 18, 2016 GNOME Data Analysis Bootcamp
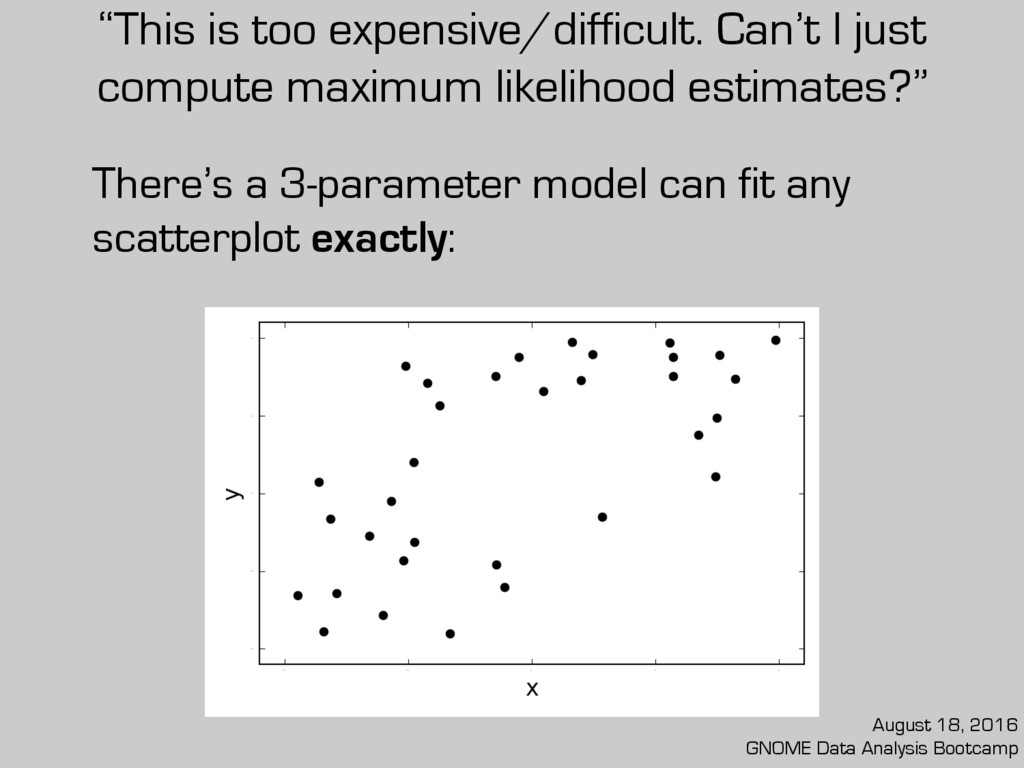
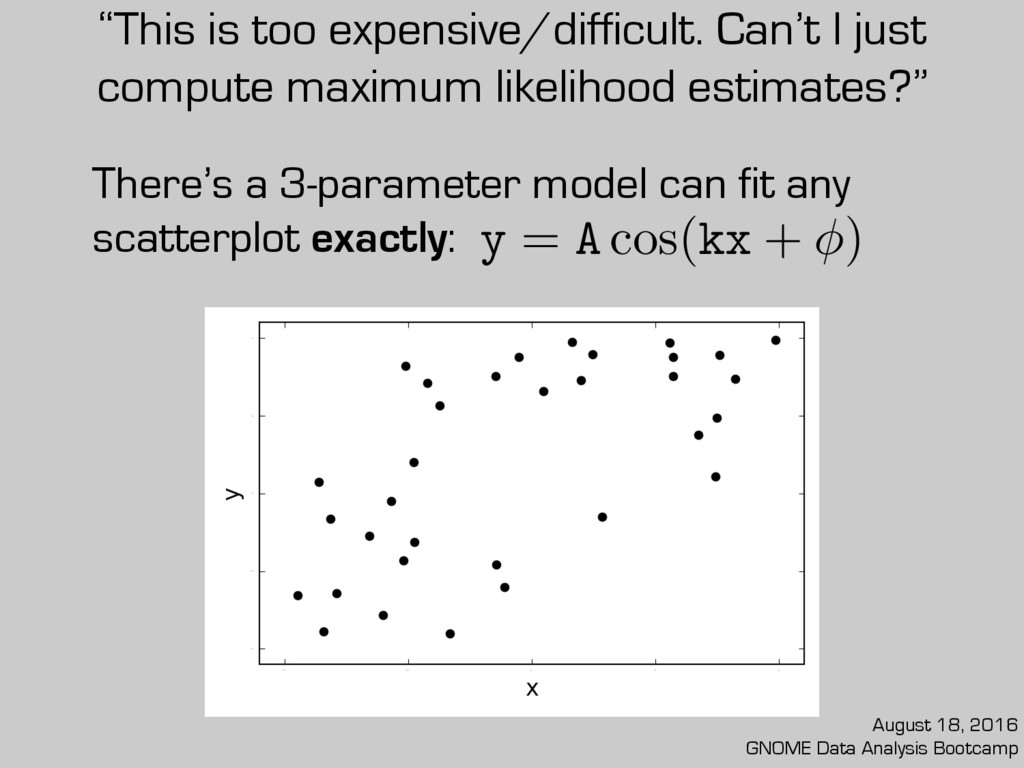
Can’t I just compute maximum likelihood estimates?” There’s a 3-parameter model can fit any scatterplot exactly: August 18, 2016 GNOME Data Analysis Bootcamp
MCMCs with likelihoods taken to different powers: p (✓|d) / p(✓)p (d|✓) Earl & Deem 2010, Phys Chem Chem Phys August 18, 2016 GNOME Data Analysis Bootcamp
taken to different powers: 2. FML at is p (✓|d) / p(✓)p (d|✓) p (d) = Z p(✓)p (d|✓)d✓ Thermodynamic Integration (Theory) Earl & Deem 2010, Phys Chem Chem Phys August 18, 2016 GNOME Data Analysis Bootcamp
taken to different powers: 2. FML at is 3. Ultimately, derive... p (d) = Z p(✓)p (d|✓)d✓ p (✓|d) / p(✓)p (d|✓) p ( d ) ⇡ exp Z 1 0 d h log p ( d|✓ ) i “average” log-likelihood at Thermodynamic Integration (Theory) Earl & Deem 2010, Phys Chem Chem Phys August 18, 2016 GNOME Data Analysis Bootcamp
h log p ( d|✓ ) i Thermodynamic Integration (Practice) Advantages: 1. A nice side effect of performing PTMCMC 2. Already implemented in emcee* Caveats: Need a robust estimate of at every h log p ( d|✓ ) i *dan.iel.fm/emcee/current/user/pt August 18, 2016 GNOME Data Analysis Bootcamp
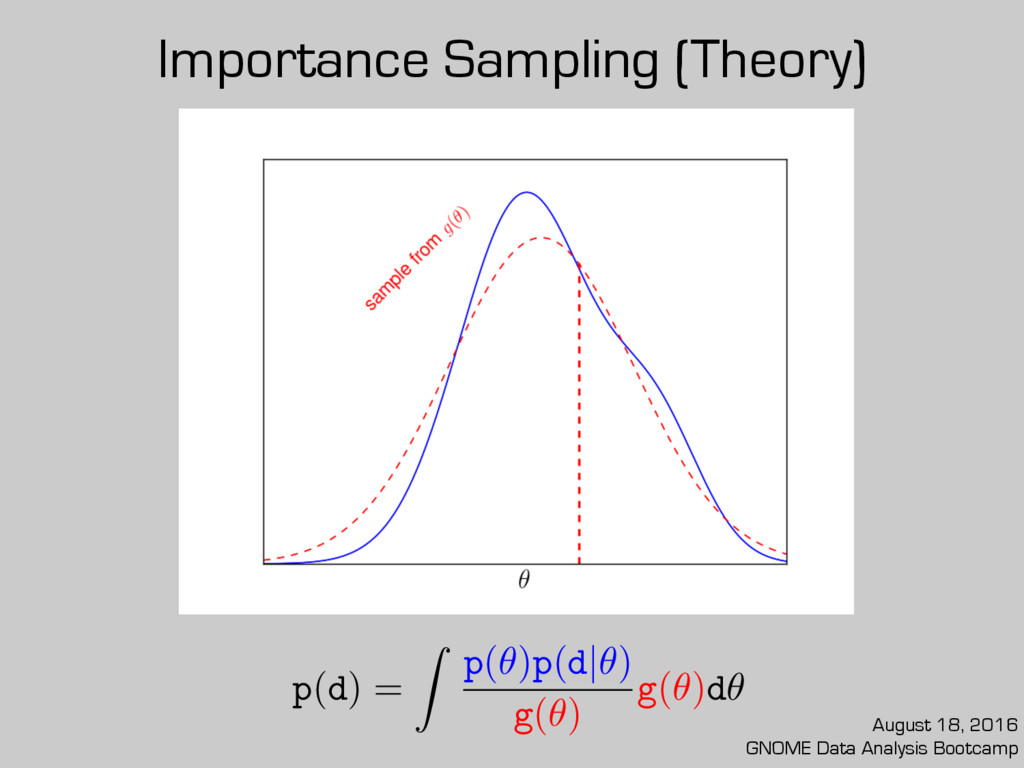
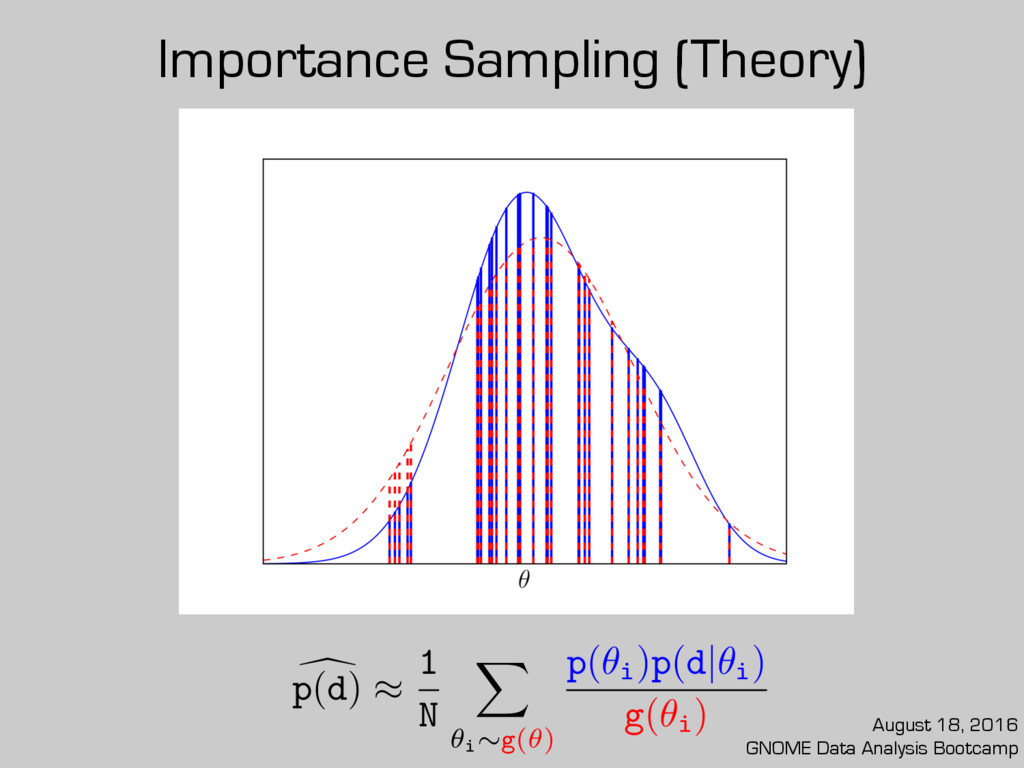
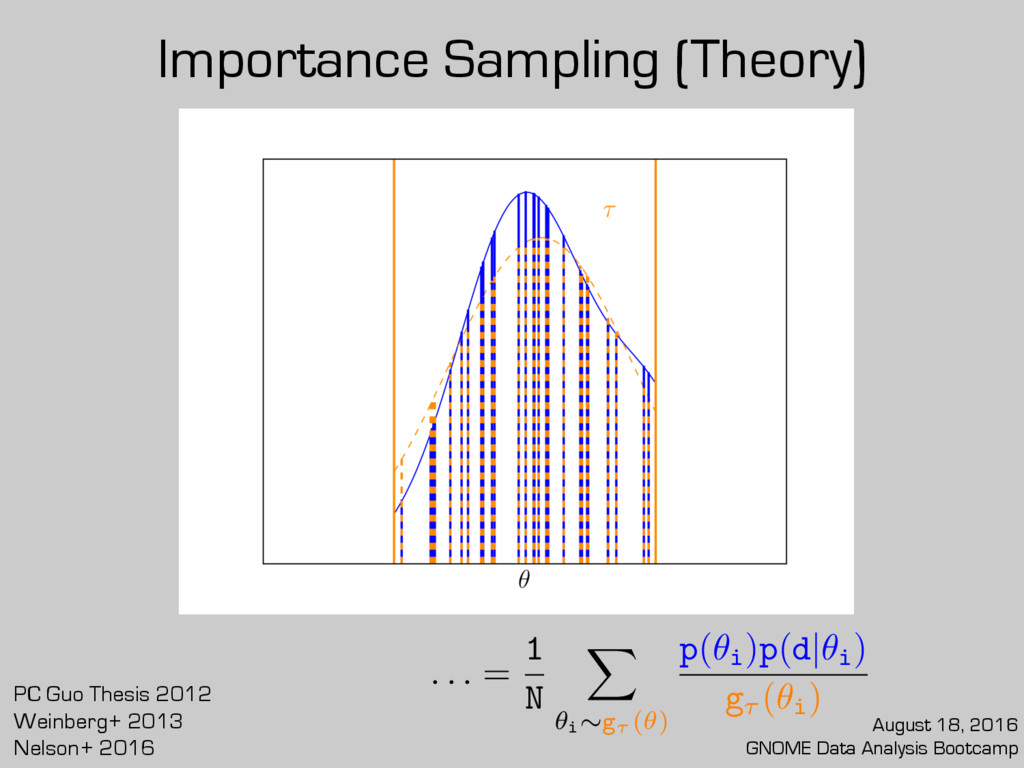
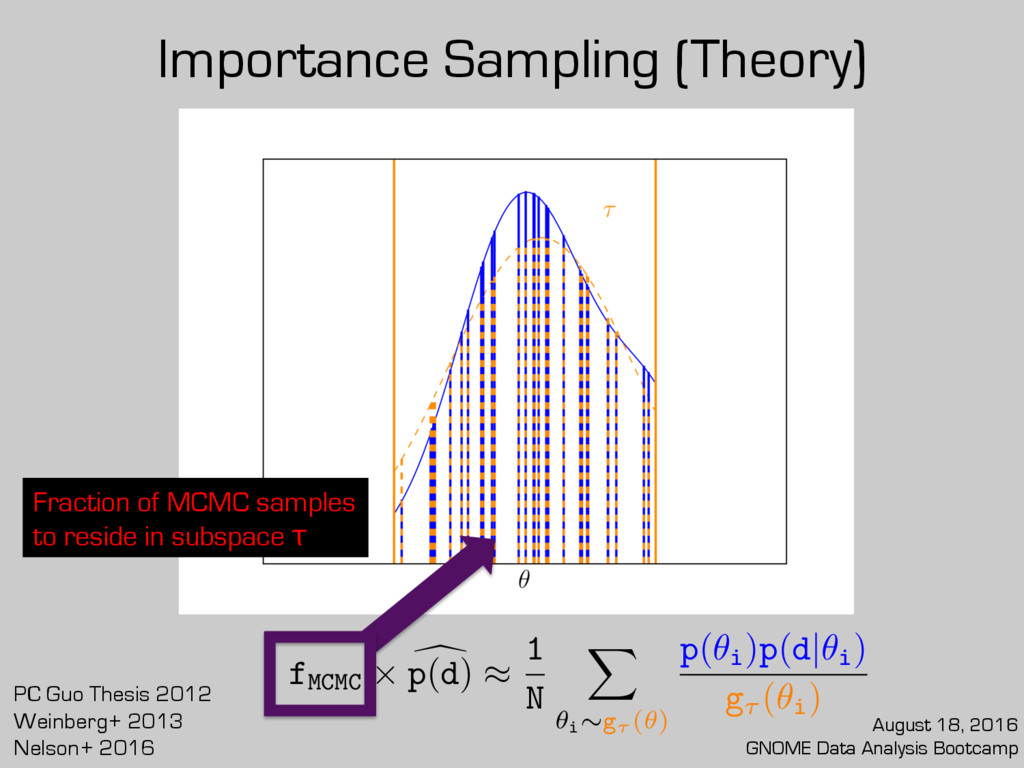
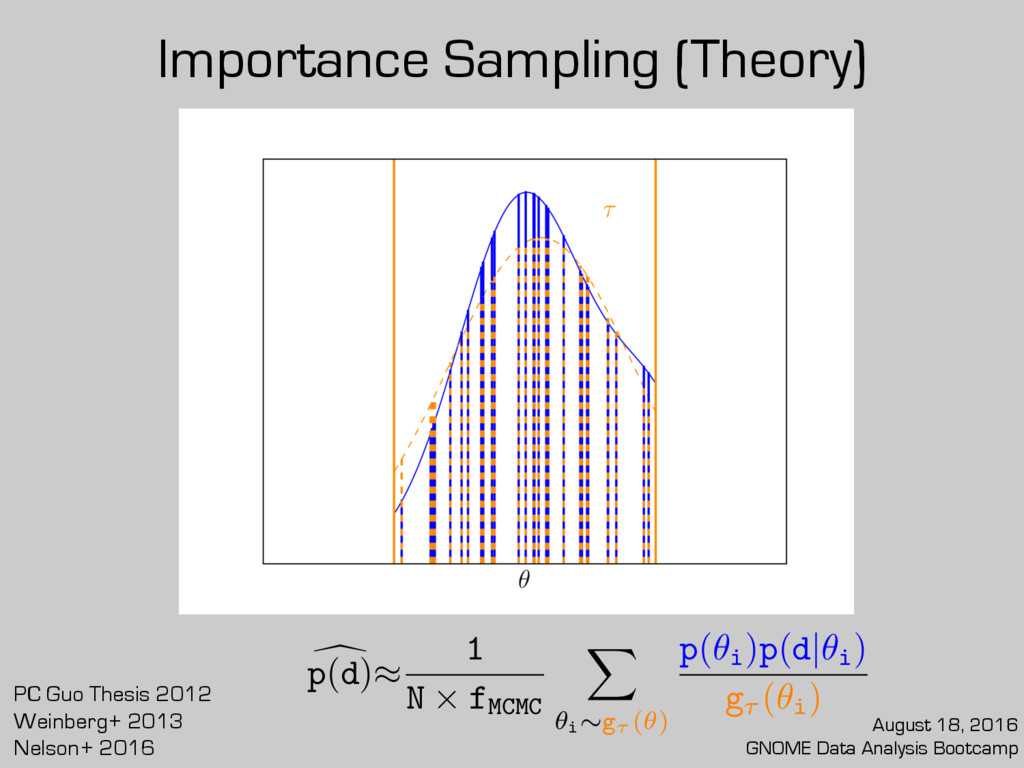
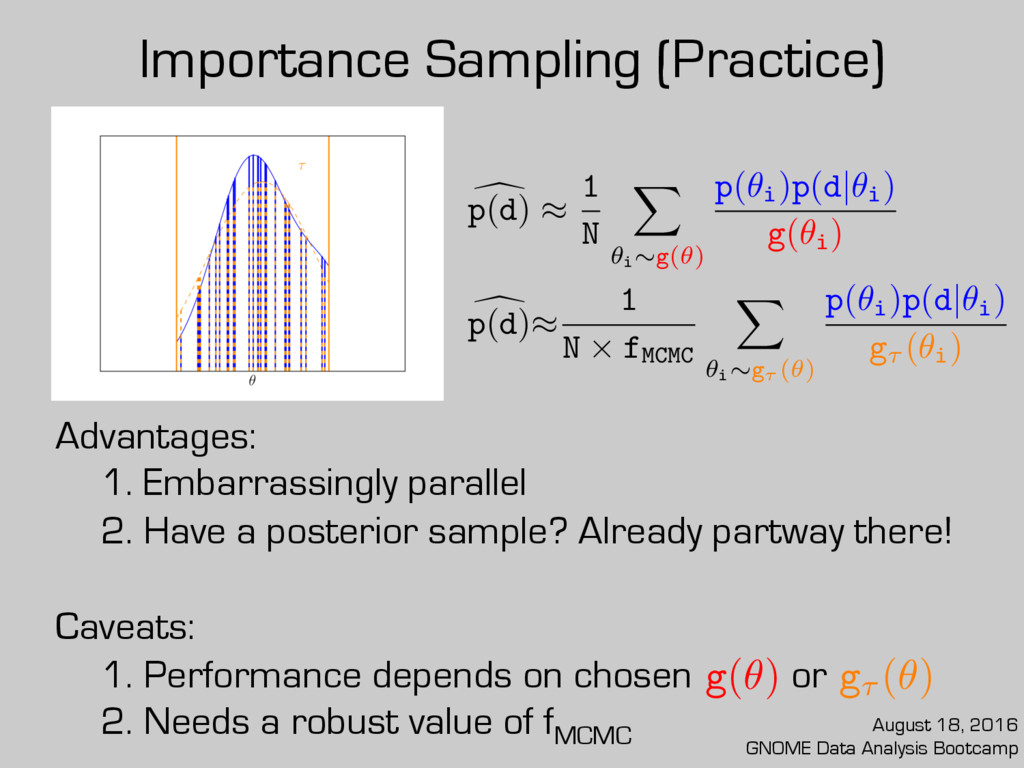
posterior sample? Already partway there! Caveats: 1. Performance depends on chosen or 2. Needs a robust value of fMCMC g(✓) d p(d) ⇡ 1 N X ✓i ⇠g(✓) p(✓i )p(d|✓i ) g(✓i ) d p(d)⇡ 1 N ⇥ fMCMC X ✓i ⇠g⌧ (✓) p(✓i )p(d|✓i ) g⌧ (✓i ) g⌧ (✓) August 18, 2016 GNOME Data Analysis Bootcamp
form of eccentricity distribution (Kipping 2013), testing n-planets in RV observations (Brewer & Donovan 2015) Publicly available code: Multinest (Feroz & Hobson 2008, Feroz 2009), DNest3/4 (Brewer+ 2010), Transdimensional MCMC (Brewer & Donovan 2015) Geometric Path Monte Carlo Science: testing n-planets in RV observations (Hou, Goodman, Hogg 2014) Savage-Dickey Density Ratio Specializes in comparing nested models with 1-2 parameter difference Science: Mass of Mars-sized Kepler-138b (Jontof-Hutter+ 2016) More methods August 18, 2016 GNOME Data Analysis Bootcamp
form of eccentricity distribution (Kipping 2013), testing n-planets in RV observations (Brewer & Donovan 2015) Publicly available code: Multinest (Feroz & Hobson 2008, Feroz 2009), DNest3/4 (Brewer+ 2010), Transdimensional MCMC (Brewer & Donovan 2015) Geometric Path Monte Carlo Science: testing n-planets in RV observations (Hou, Goodman, Hogg 2014) Savage-Dickey Density Ratio Specializes in comparing nested models with 1-2 parameter difference Science: Mass of Mars-sized Kepler-138b (Jontof-Hutter+ 2016) More methods Takeaway #3: Computing FML is an active field in itself August 18, 2016 GNOME Data Analysis Bootcamp
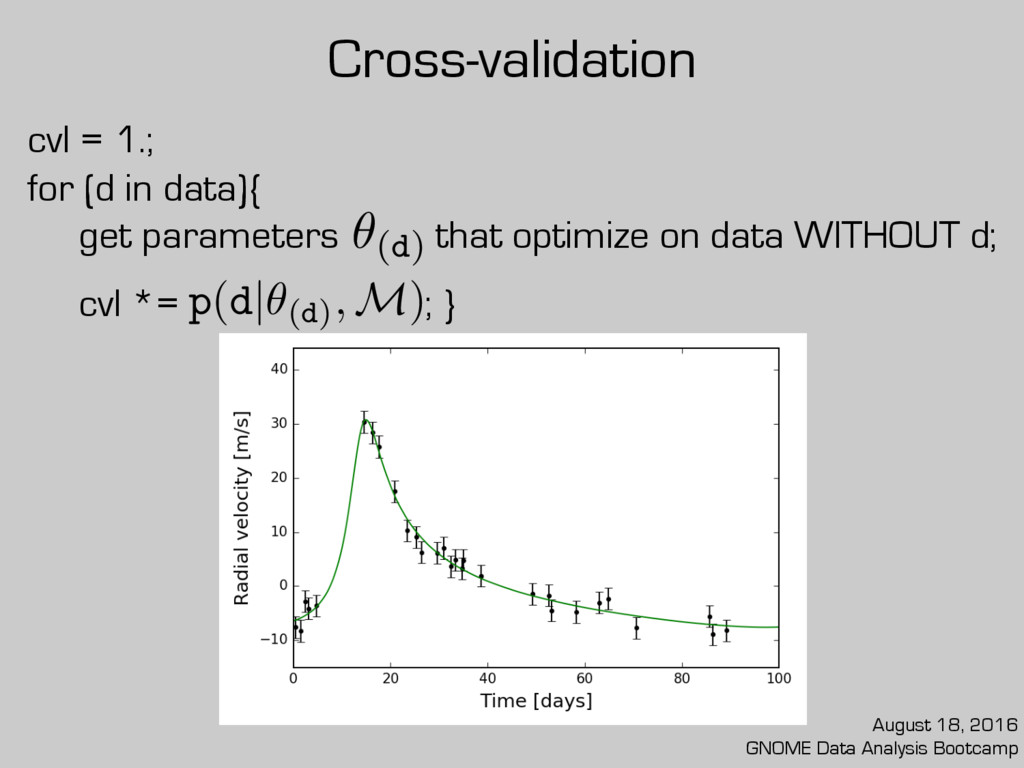
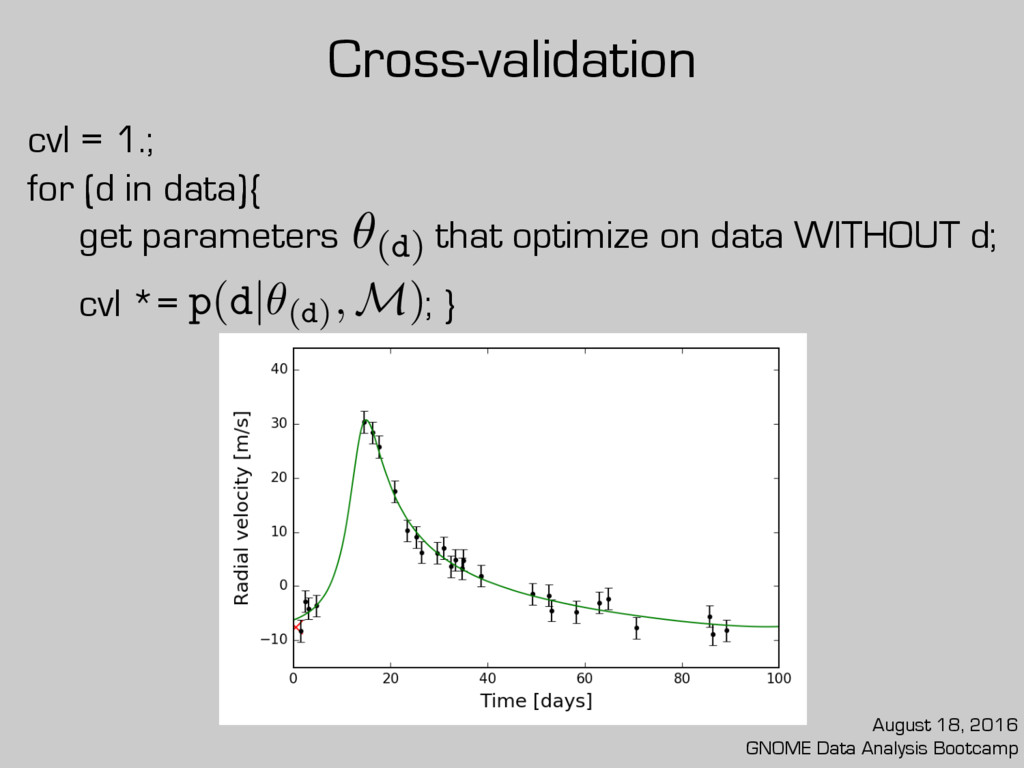
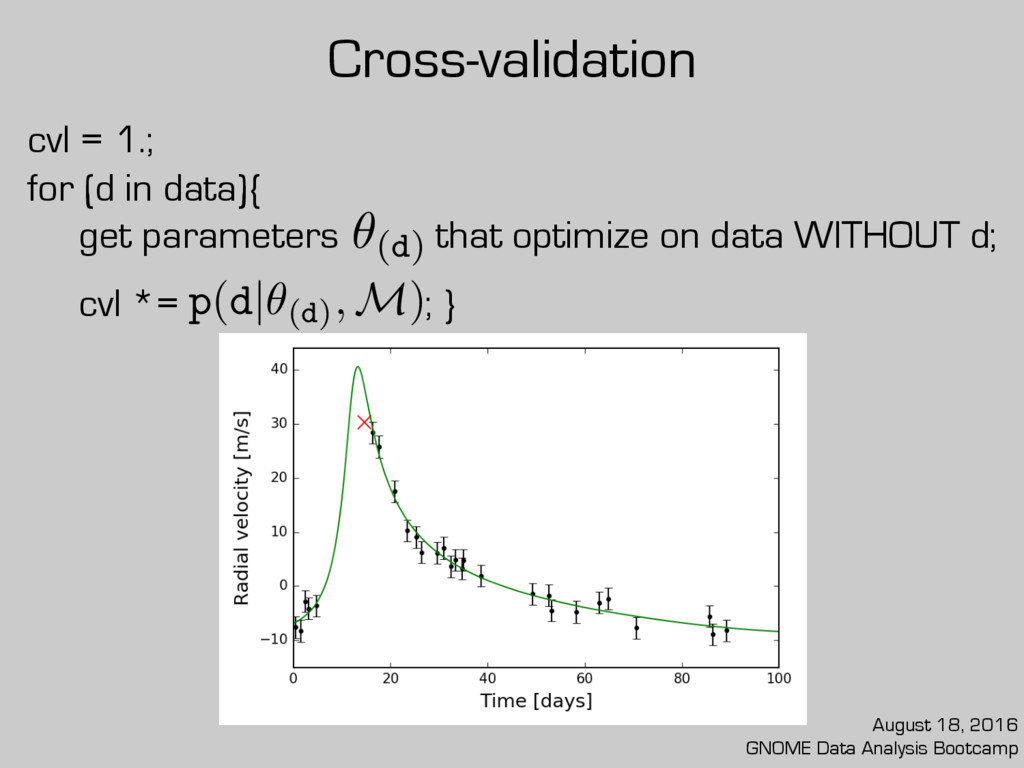
cross-validation likelihood (cvl) is preferred. cvl = 1.; for (d in data){ get parameters that optimize on data WITHOUT d; cvl *= ; } August 18, 2016 GNOME Data Analysis Bootcamp
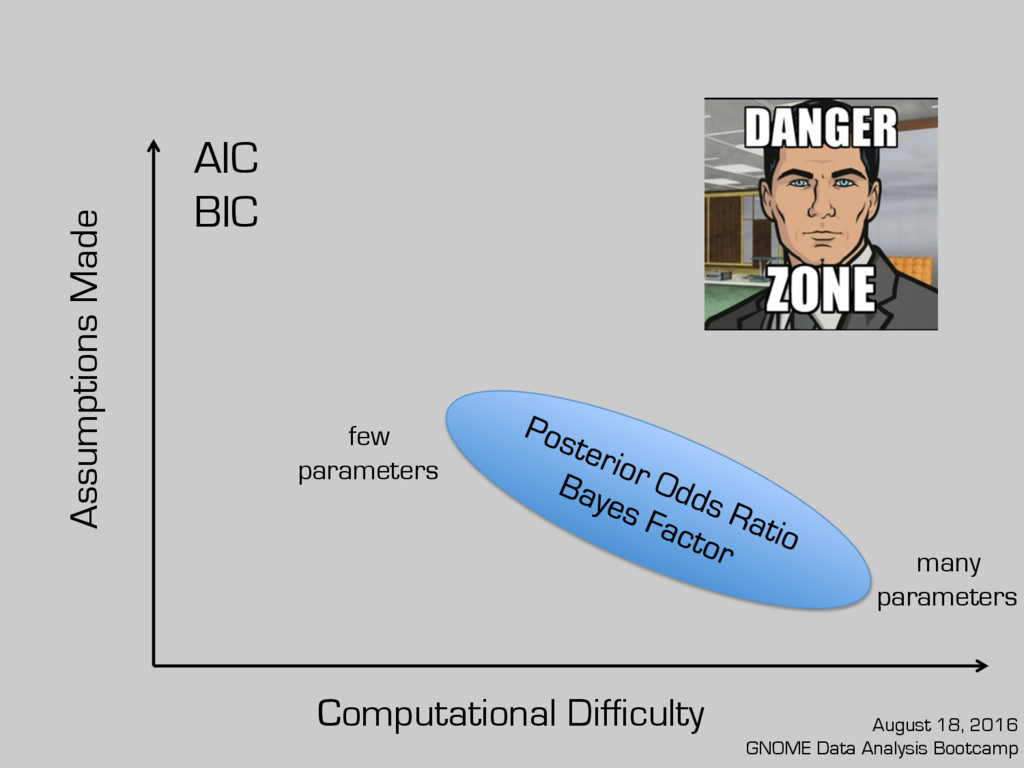
many rough decisions quickly (i.e. milliseconds)? AIC/BIC 2. Do you have decent computational resources and really understand your priors/utility? Bayes factor/posterior odds ratio 3. Is your problem somewhat in between? Cross-validation August 18, 2016 GNOME Data Analysis Bootcamp
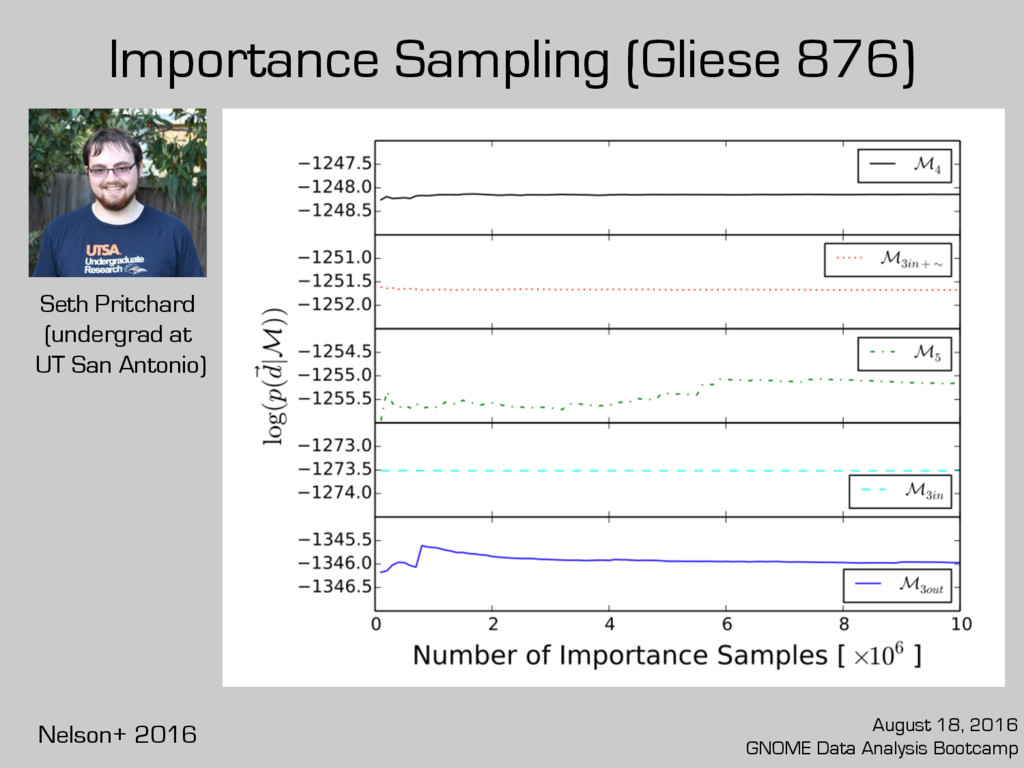
on your utility For 3+ parameter models, computing FML is hard. But it’s an active problem in exoplanet research. For tutorial on using importance sampling to compute FMLs: github.com/benelson/FML August 18, 2016 GNOME Data Analysis Bootcamp
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
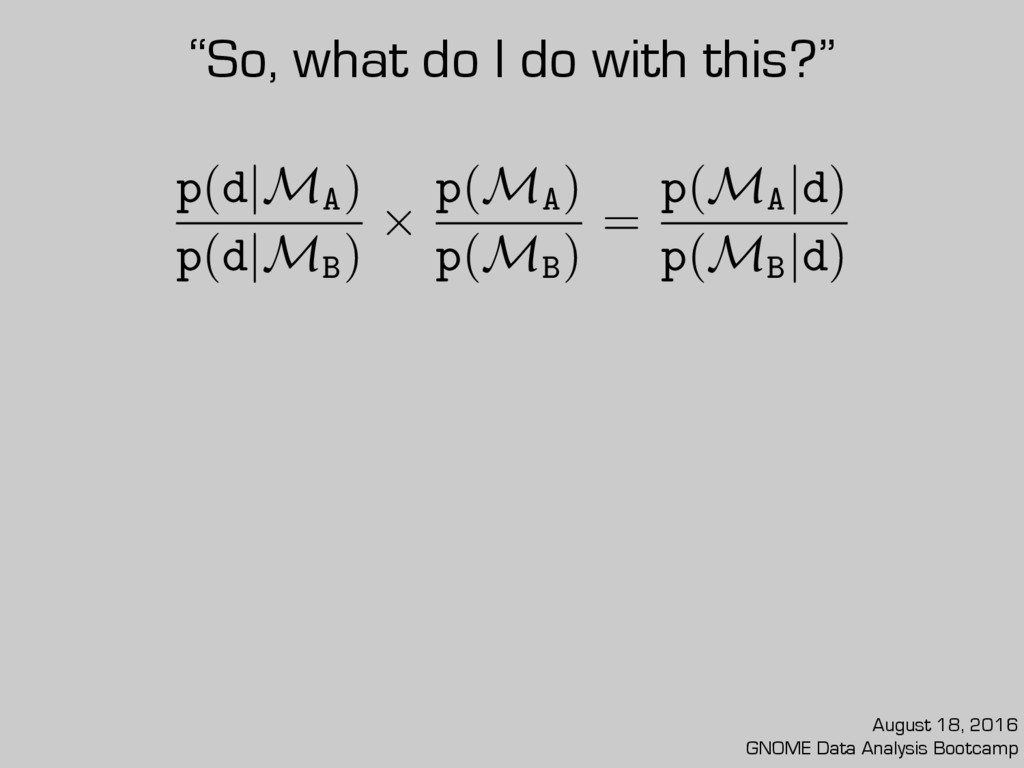{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Nested Sampling Science: determining evidence for exomoons (Kipping+ 2013], functional](https://files.speakerdeck.com/presentations/14ecde923a2248b2a700035c1800a962/slide_35.jpg){kind=link}
![Nested Sampling Science: determining evidence for exomoons (Kipping+ 2013], functional](https://files.speakerdeck.com/presentations/14ecde923a2248b2a700035c1800a962/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}