et al.のリース回帰と一致. • 双対問題は安定共変量バランシングの最適化問題と一致. • 密度比推定におけるLSIFに対応. • 未正規化KL(Unnormalized KL; UKL)距離の場合:Zhao et al.のテイラー損失最小化などと一致. • 双対問題はエントロピー共変量バランシングの最適化問題と一致. • 密度比推定におけるKLIEPに対応. • 二値KL(Binary KL; BKL)距離の場合:傾向スコアの最尤推定と一致. 関連研究: ブレグマン距離最小化に基づく密度比推定(Sugiyama et al., Ann Inst Stat Math 2012) Copyright (c) Mizuho–DL Financial Technology Co., Ltd. All Rights Reserved.
Bruns-Smith et al. (JRSSB 2025)・Singh (arXiv 2024)・Mou et al. (Mathematics of OR 2025?). ◼正則化を加えることによりリース表現量や回帰関数の推定精度を向上. Copyright (c) Mizuho–DL Financial Technology Co., Ltd. All Rights Reserved.
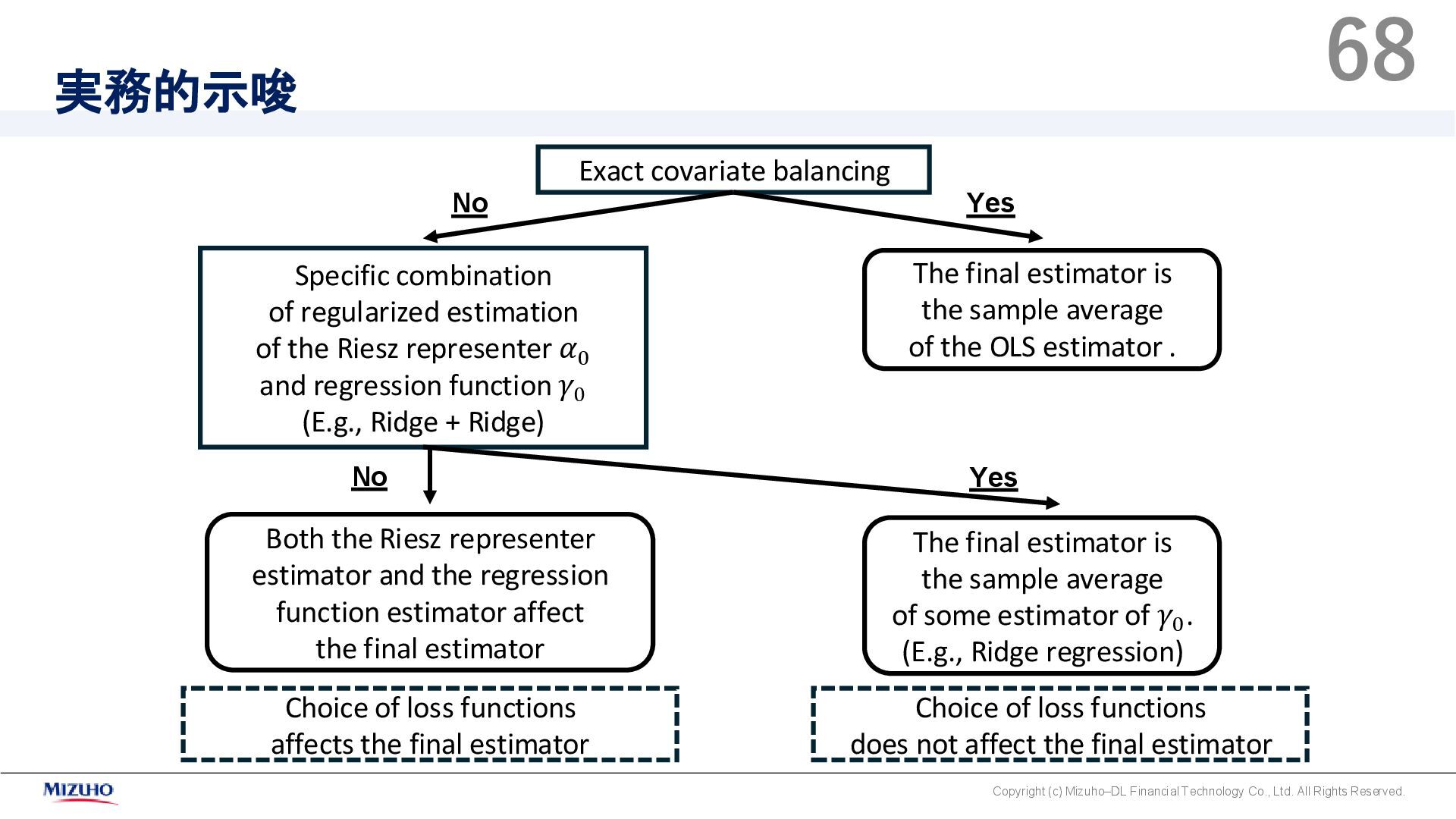
Rights Reserved. Exact covariate balancing Specific combination of regularized estimation of the Riesz representer 𝛼0 and regression function 𝛾0 (E.g., Ridge + Ridge) The final estimator is the sample average of the OLS estimator . The final estimator is the sample average of some estimator of 𝛾0 . (E.g., Ridge regression) Both the Riesz representer estimator and the regression function estimator affect the final estimator Choice of loss functions affects the final estimator Choice of loss functions does not affect the final estimator Yes Yes No No
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}