Description
Presented at East Bay Java User Group on August 22nd 2012 (http://www.meetup.com/eastbayjug/events/74544872/)
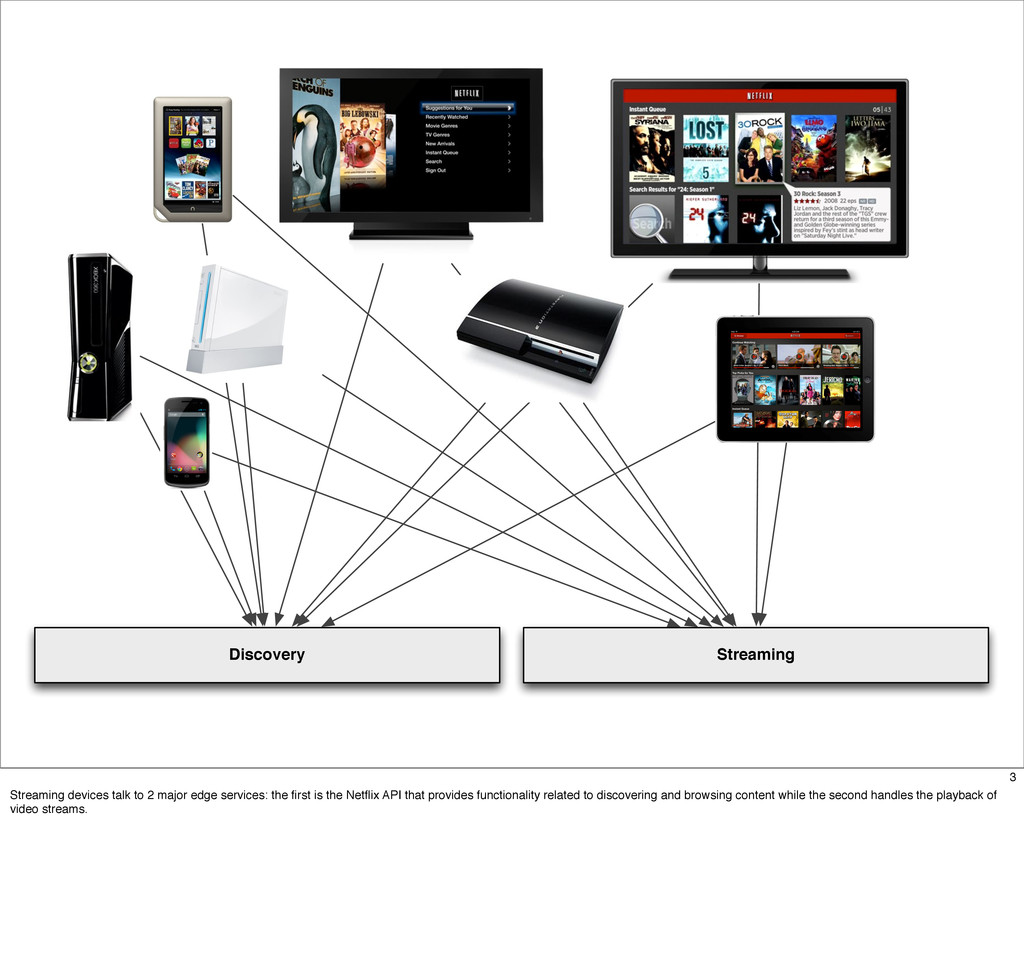
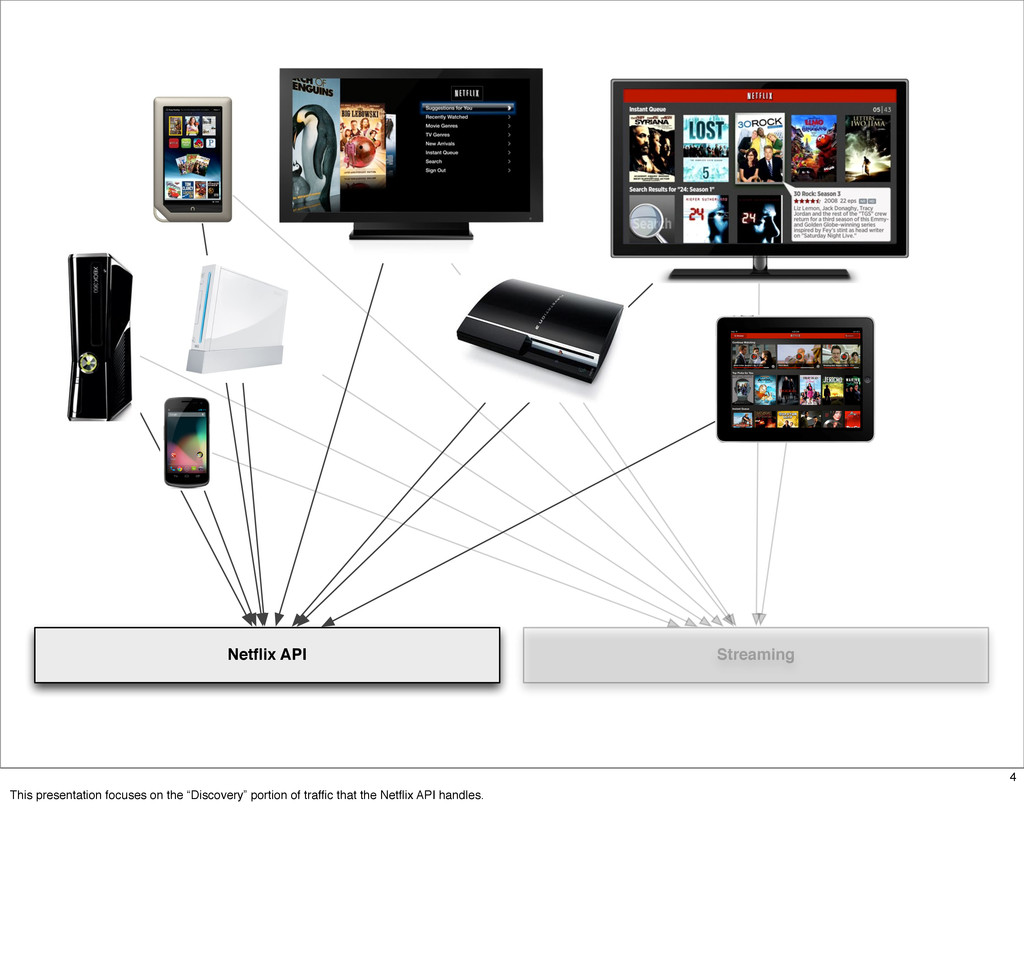
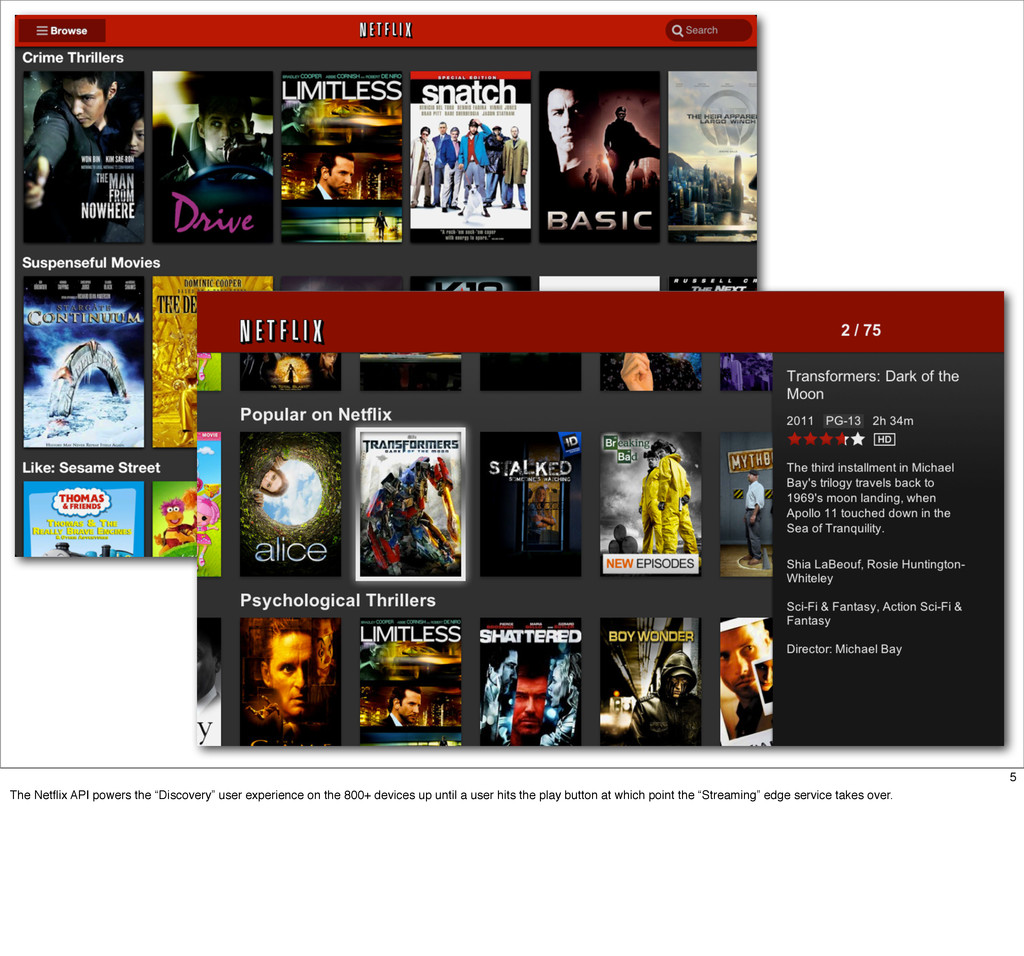
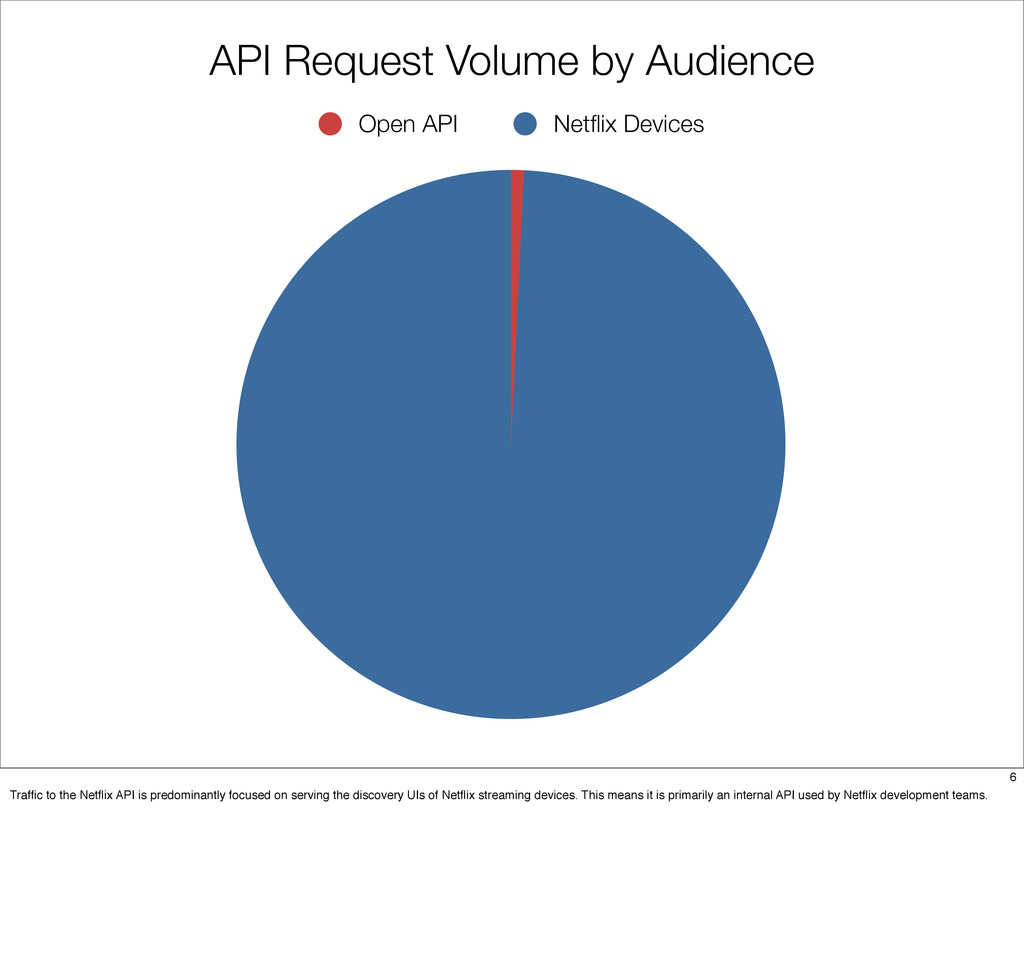
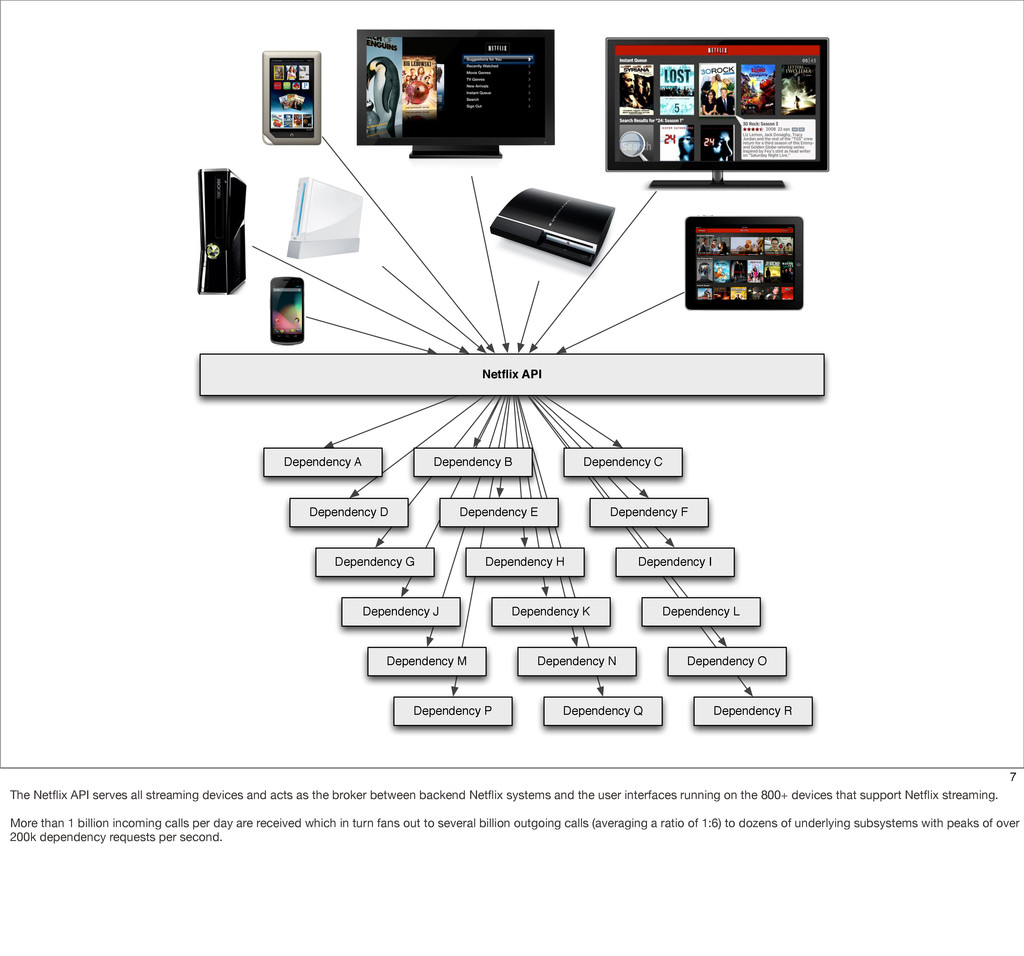
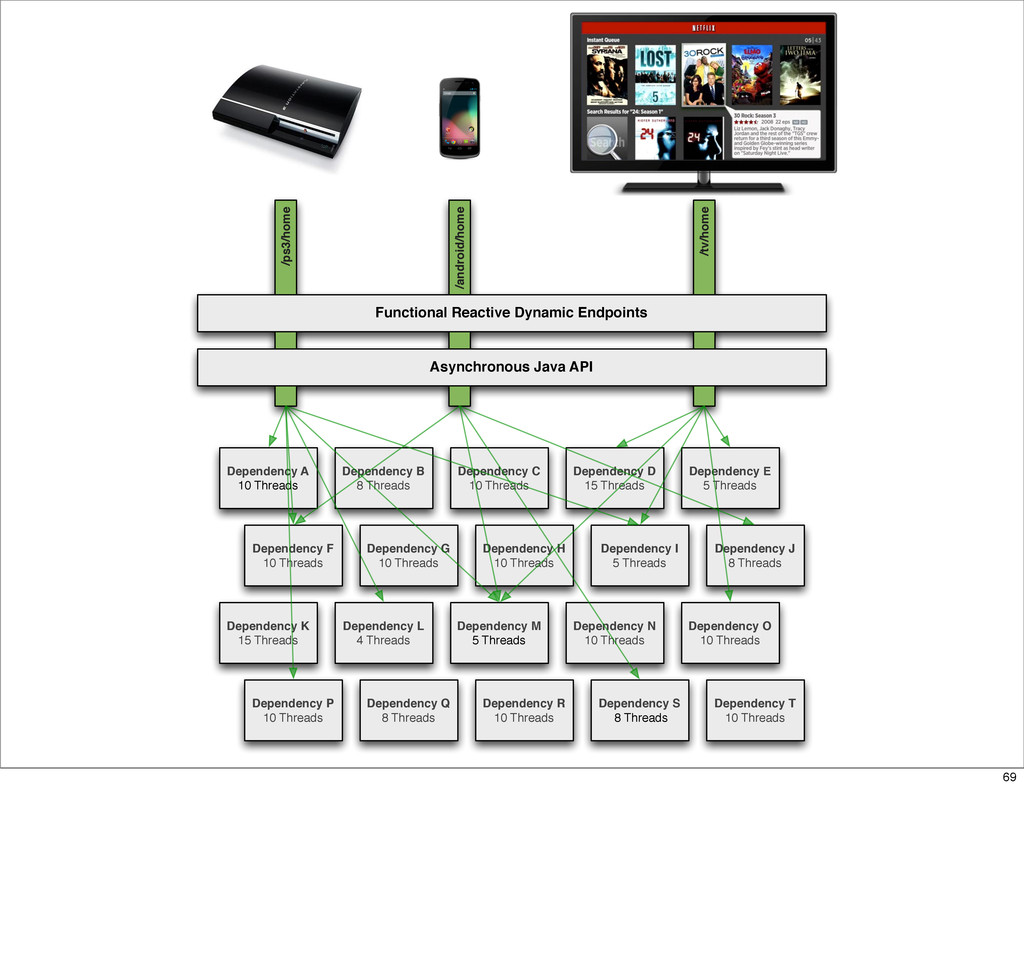
The Netflix API receives over a billion requests a day which translates into multiple billions of calls to underlying systems in the Netflix service-oriented architecture. These requests come from more than 800 different devices ranging from gaming consoles like the PS3, XBox and Wii to set-top boxes, TVs and mobile devices such as Android and iOS.
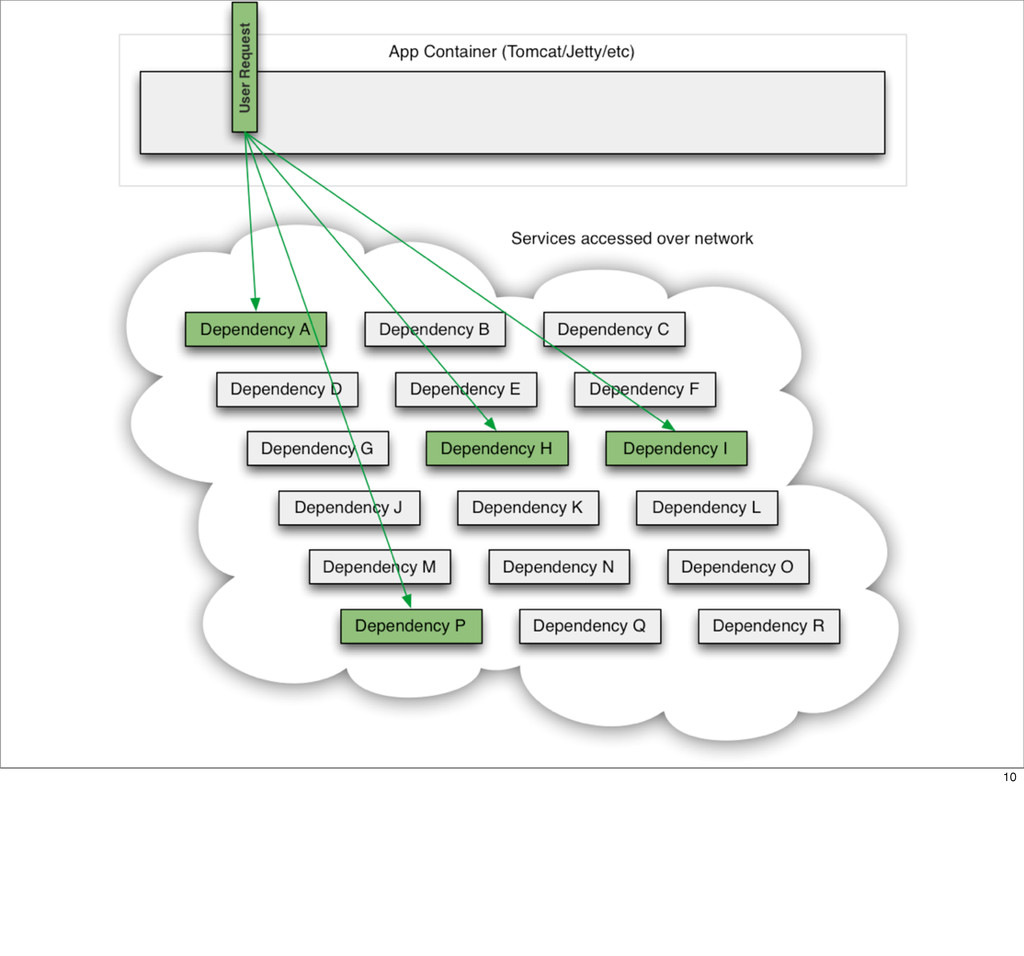
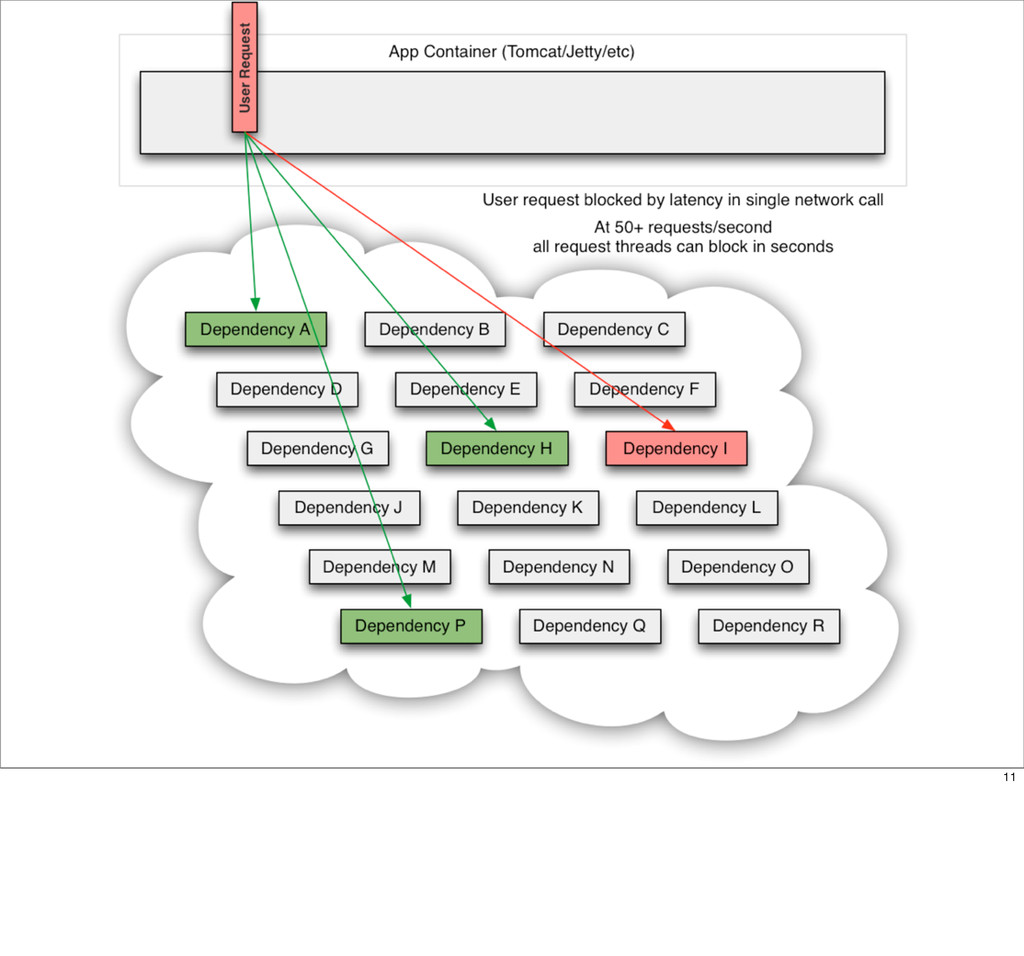
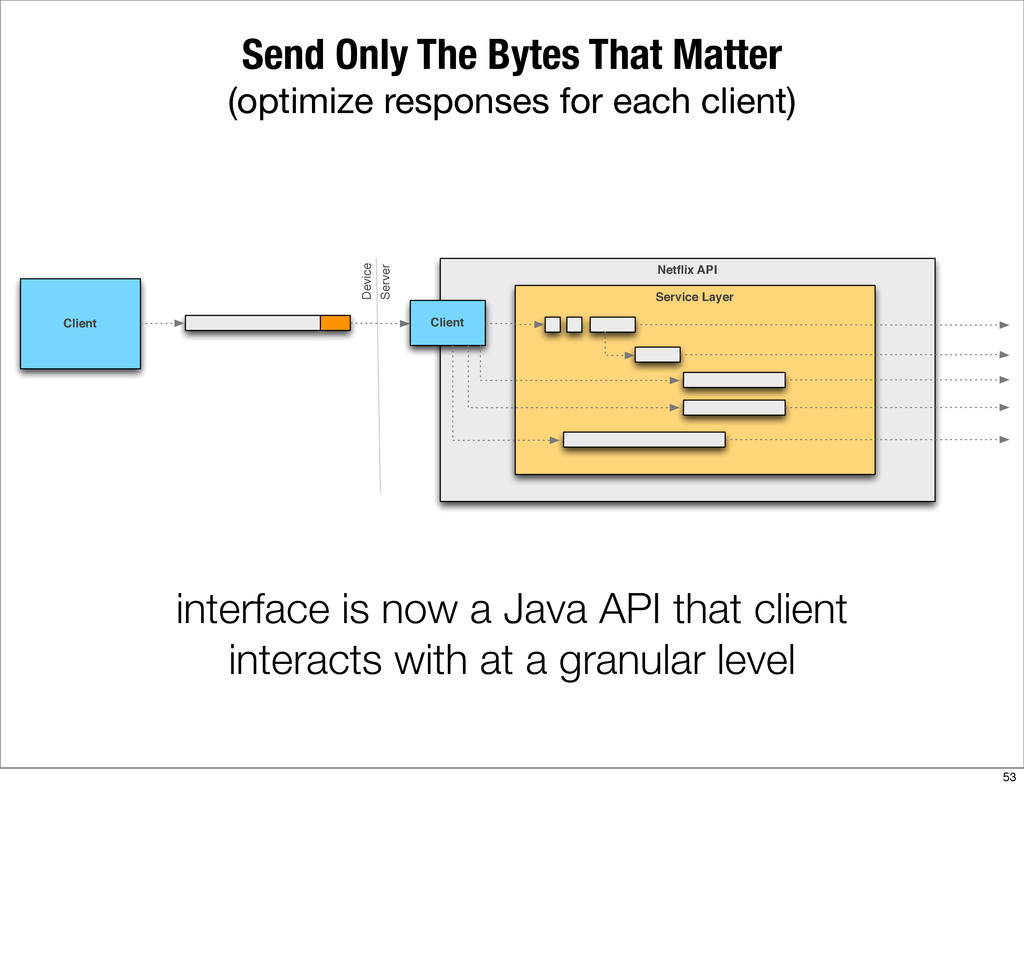
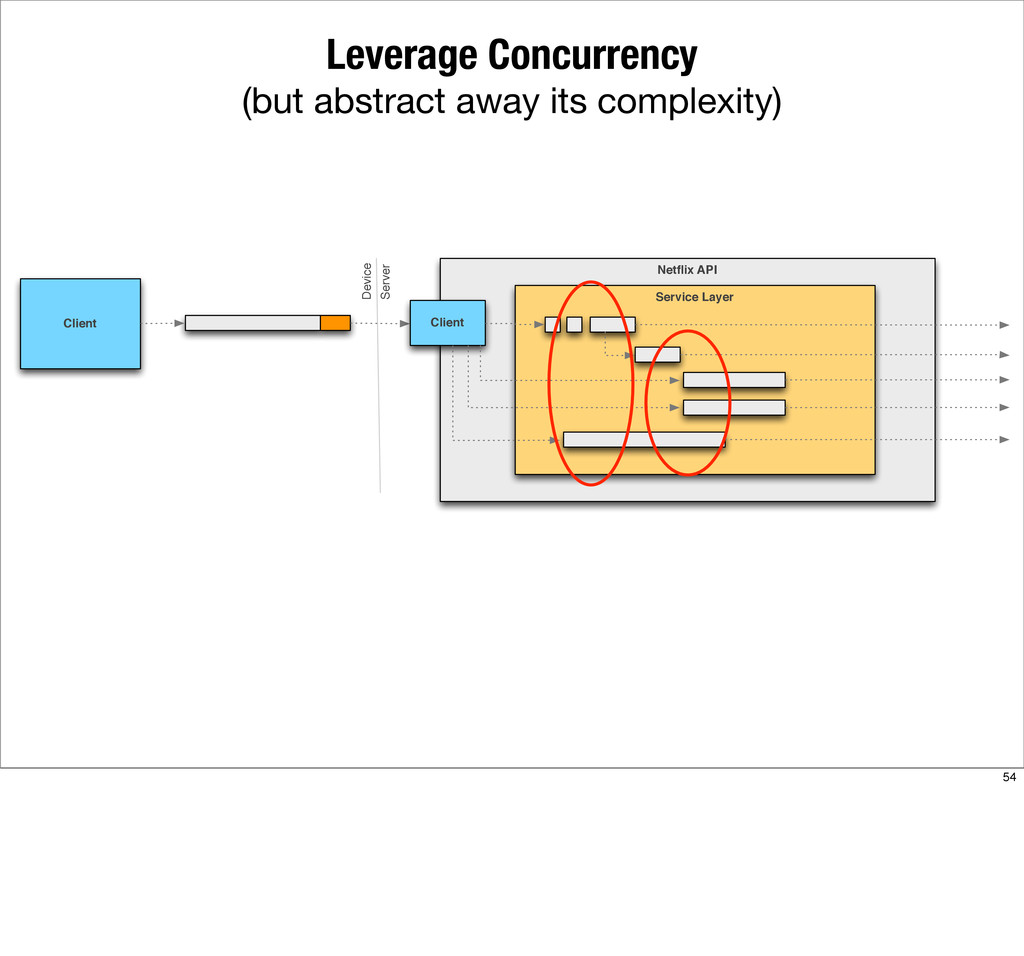
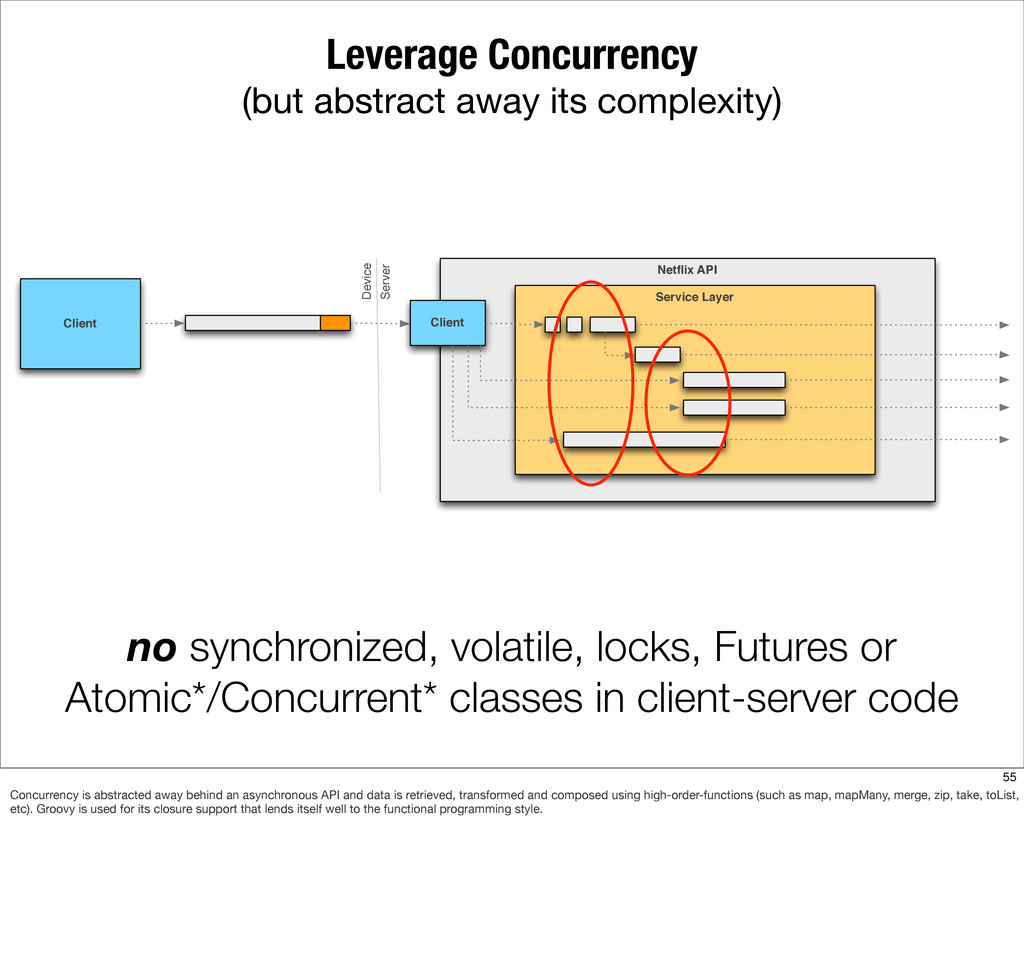
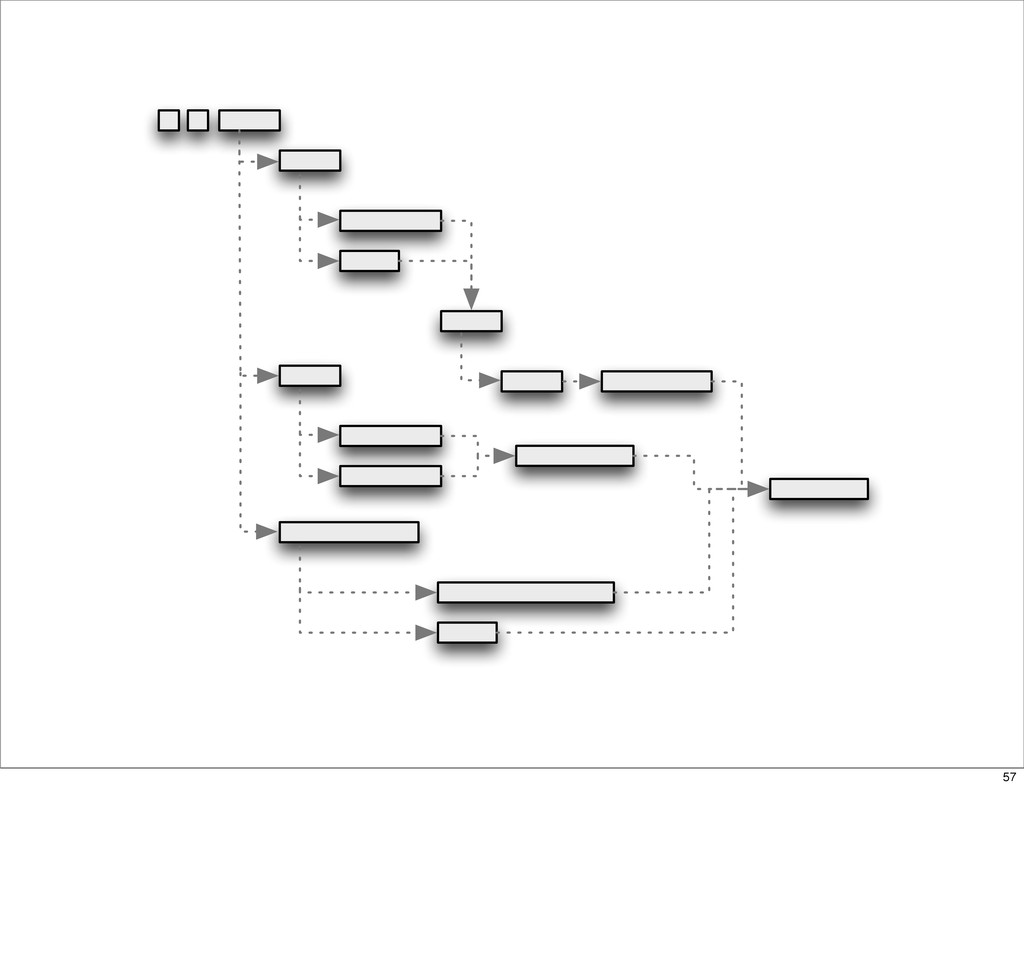
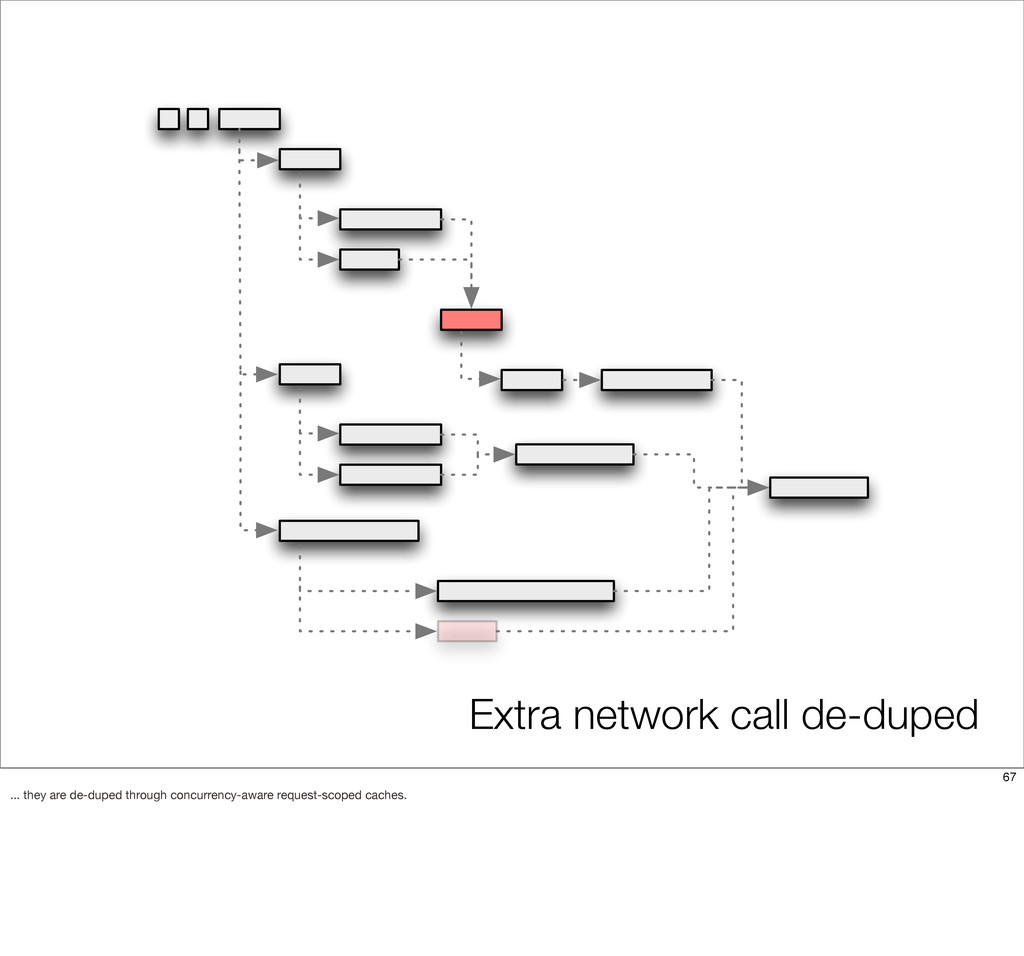
This presentation describes how the Netflix API supports those devices and achieves fault tolerance in a distributed architecture while depending on dozens of systems which can fail at any time. It also explains how a new system design allows each device to optimize API calls to their unique needs and leverage concurrency on the server-side to improve their performance.
(Some slides have been modified and notes included for readability and understanding of content without accompanying speech.)
Only difference from QCon Sao Paulo slides (https://speakerdeck.com/u/benjchristensen/p/performance-and-fault-tolerance-for-the-netflix-api-qcon-sao-paulo) is the US instead of Brazilian screenshot.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
!["Timeout guard" daemon prio=10 tid=0x00002aaacd5e5000 nid=0x3aac runnable [0x00002aaac388f000] java.lang.Thread.State: RUNNABLE](https://files.speakerdeck.com/presentations/50356a43d135ef0002003bdc/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
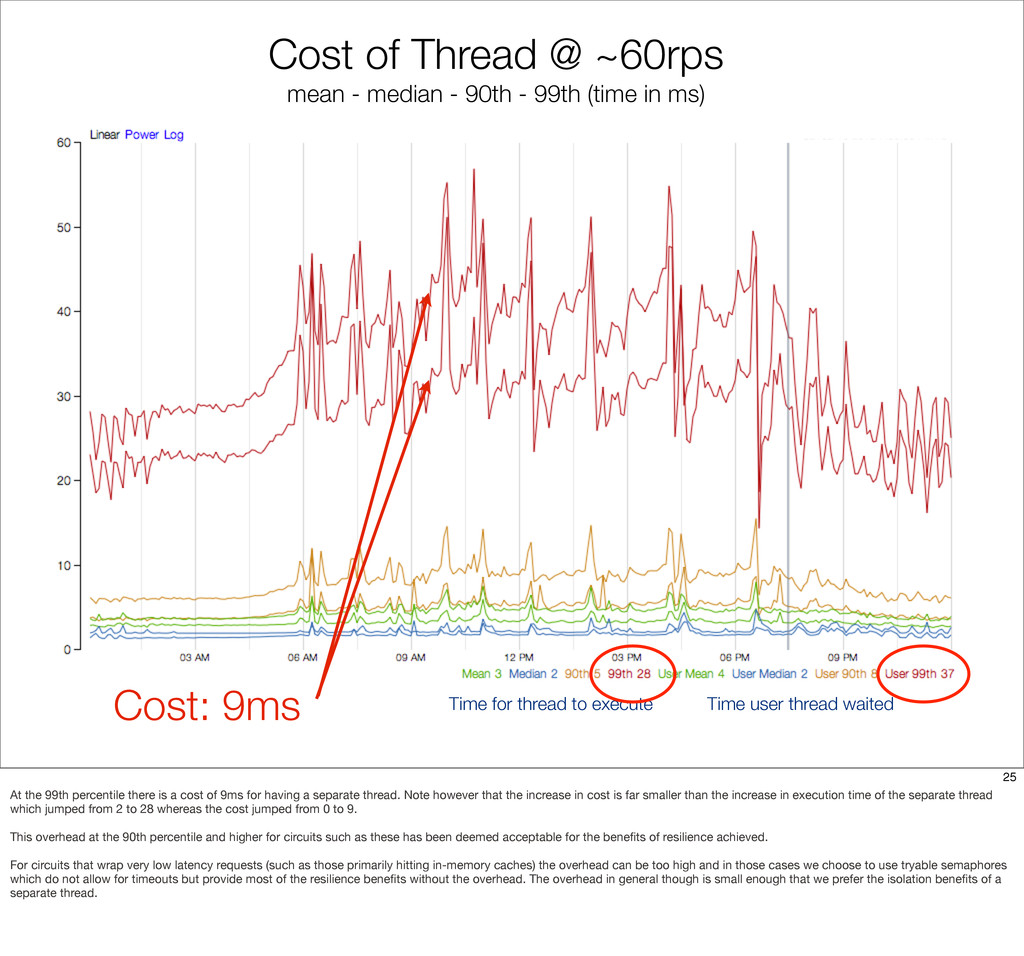{kind=link}
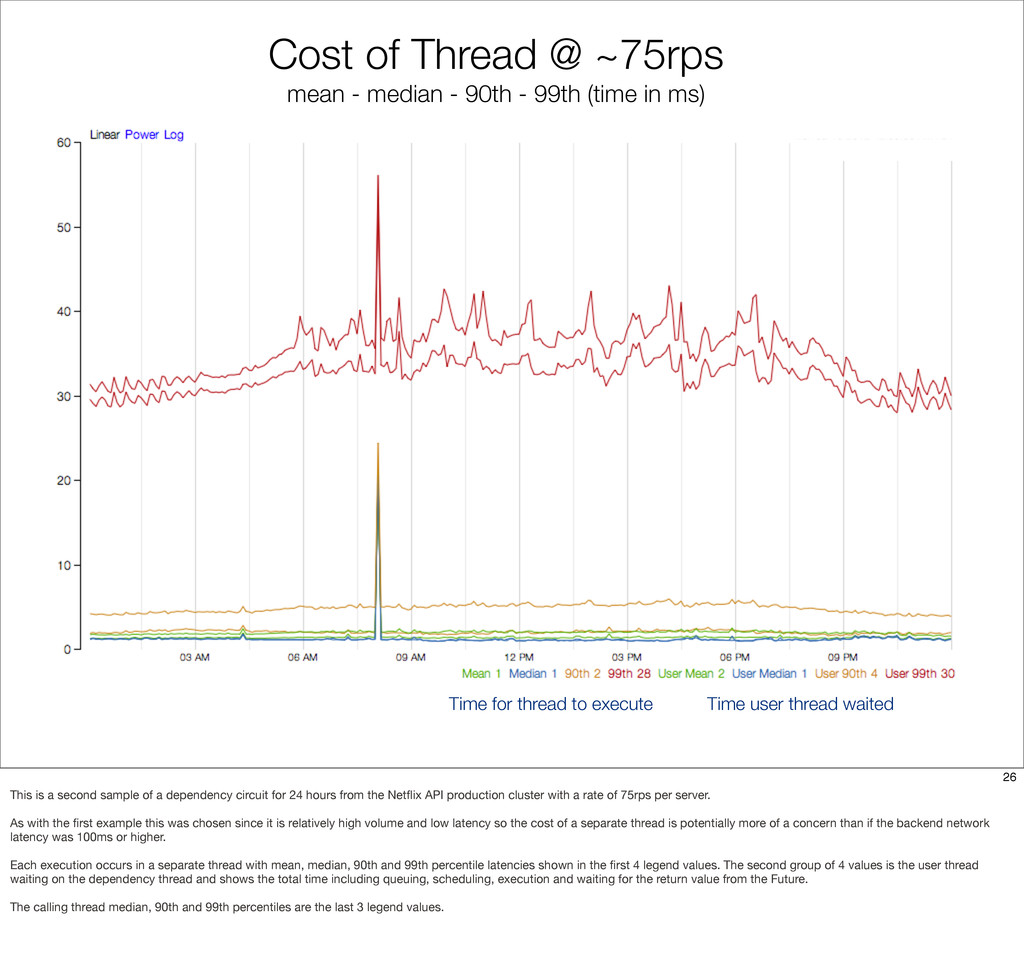{kind=link}
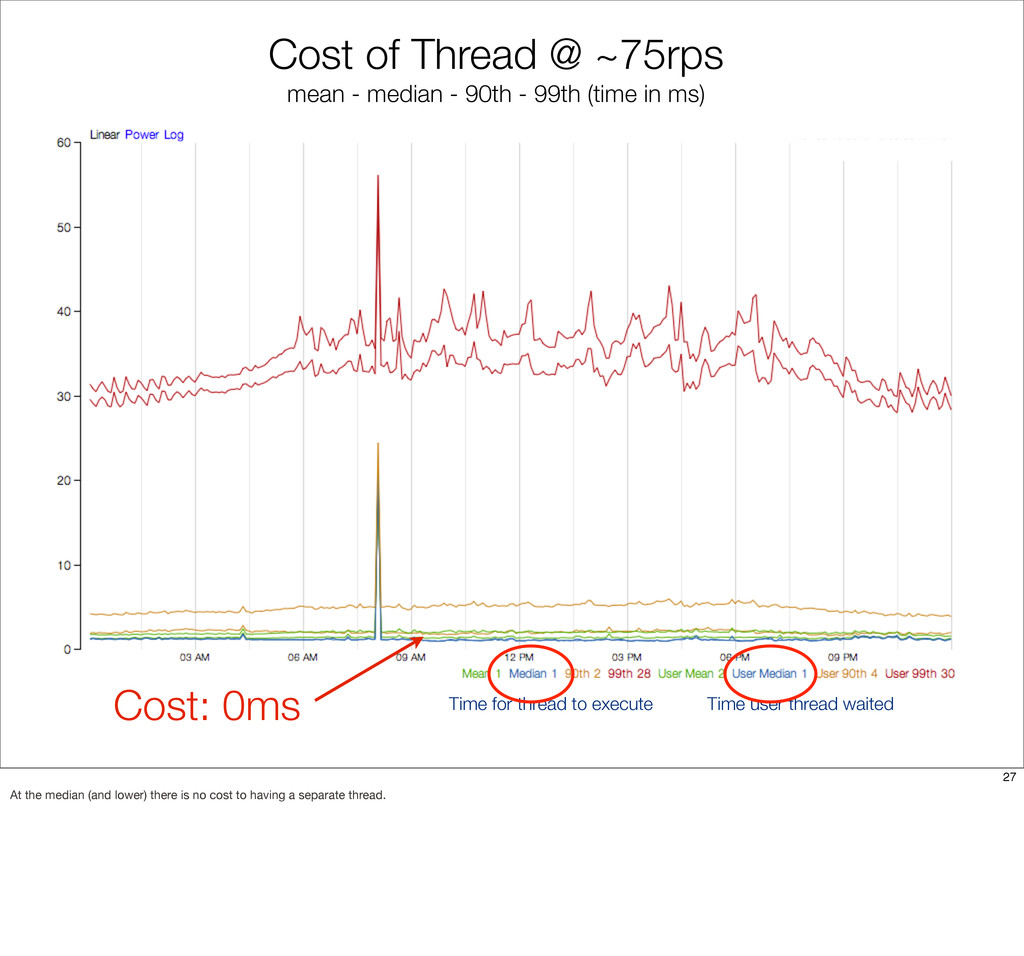{kind=link}
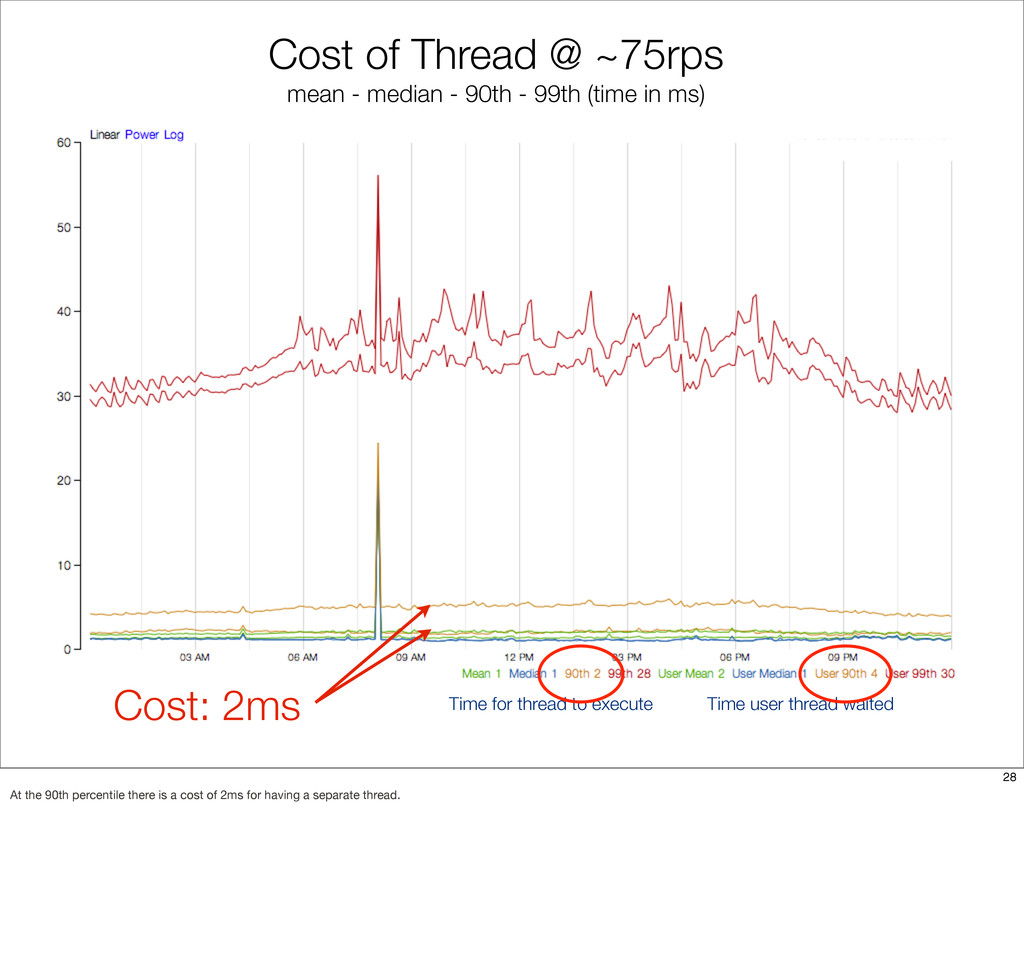{kind=link}
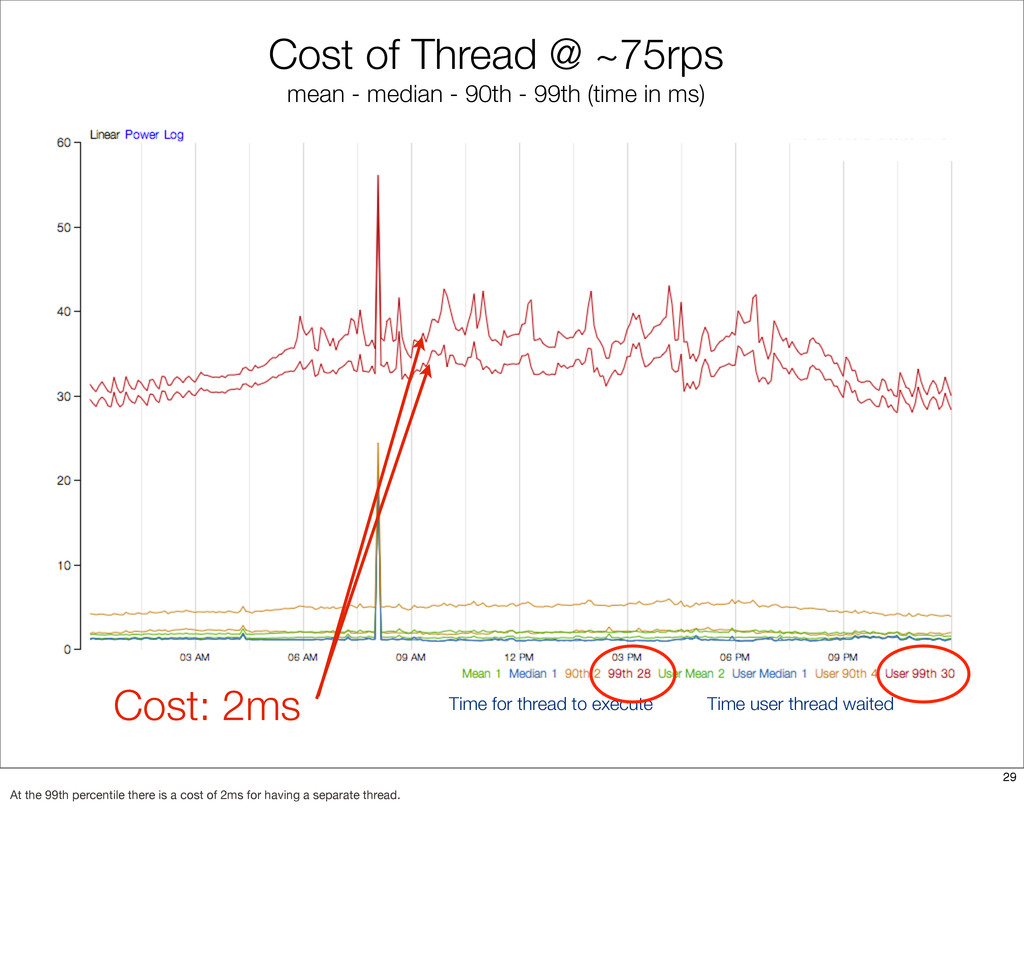{kind=link}
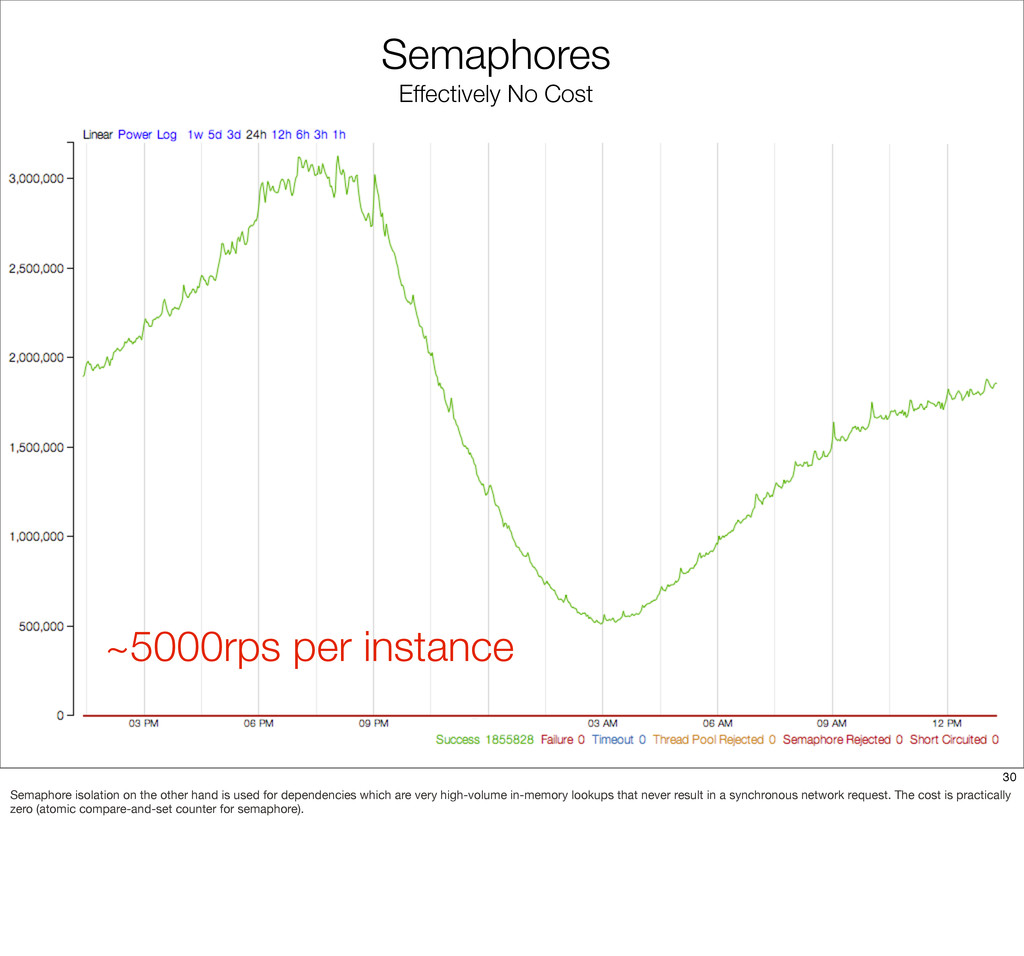{kind=link}
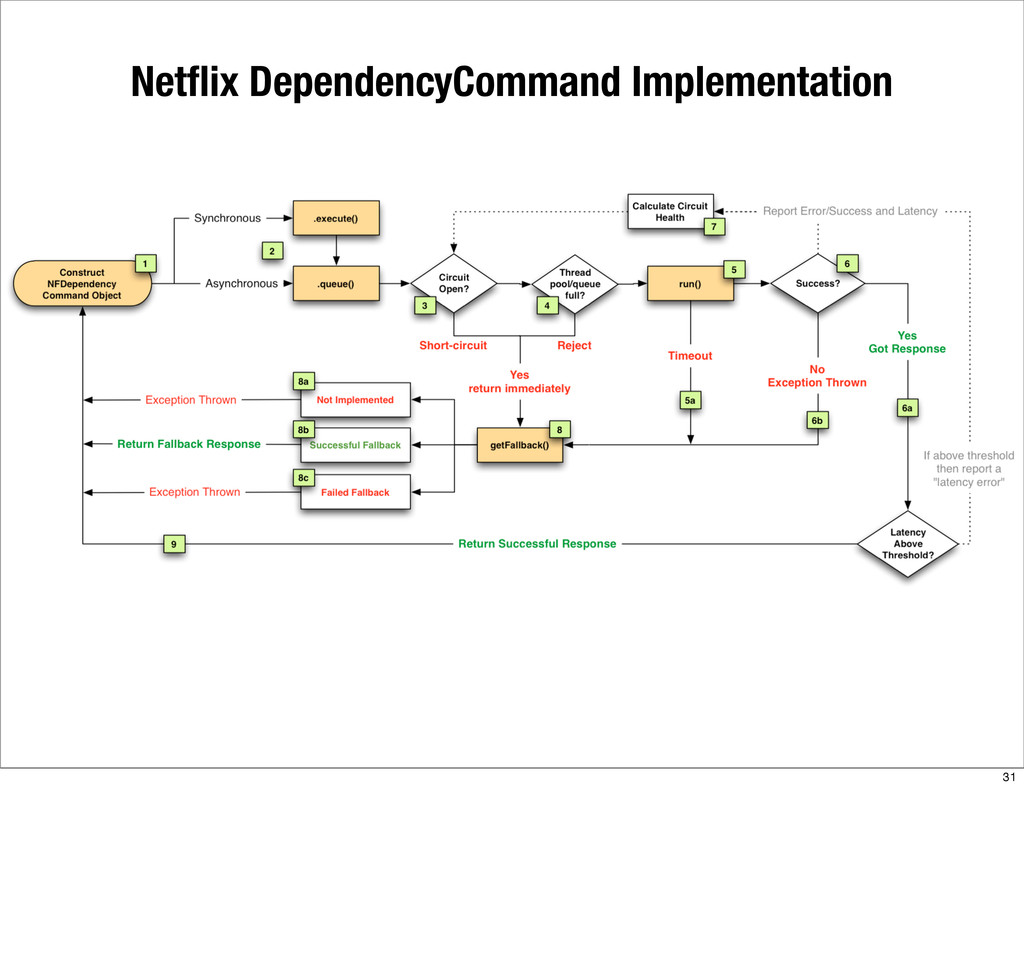{kind=link}
{kind=link}
{kind=link}
{kind=link}
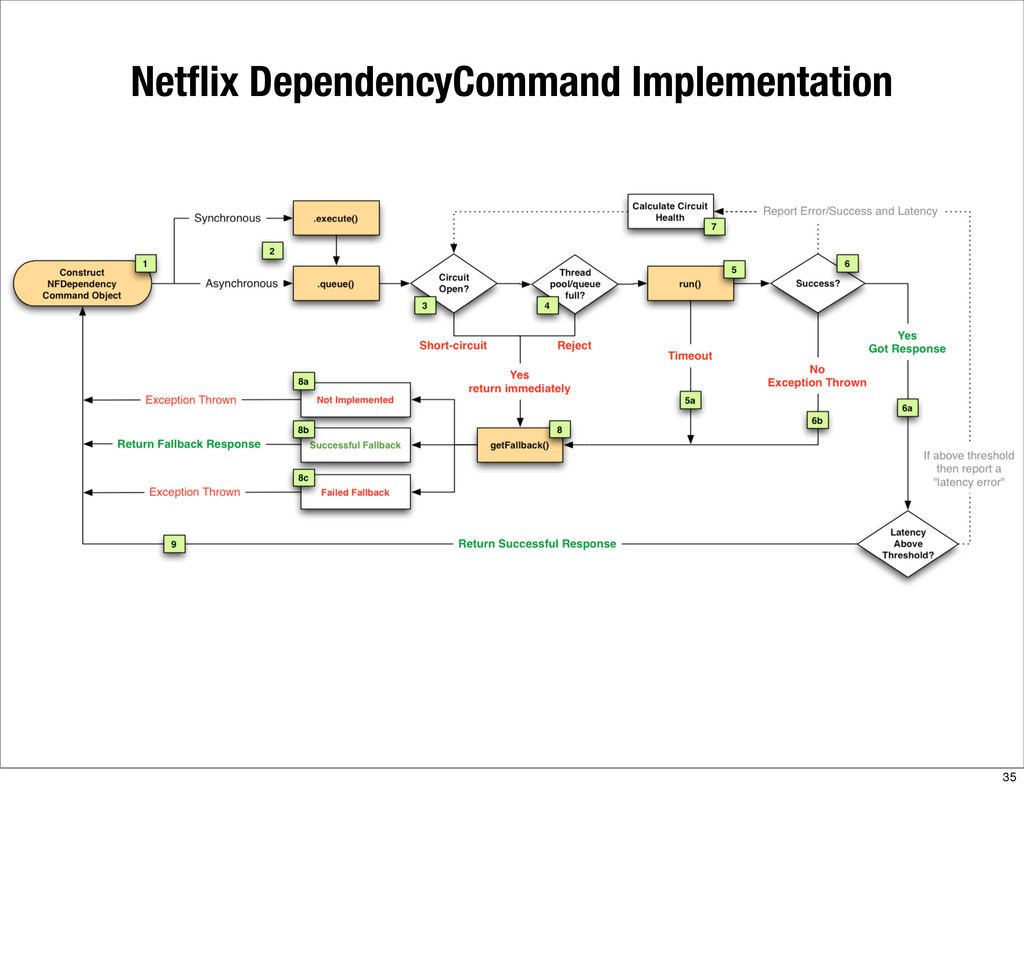{kind=link}
{kind=link}
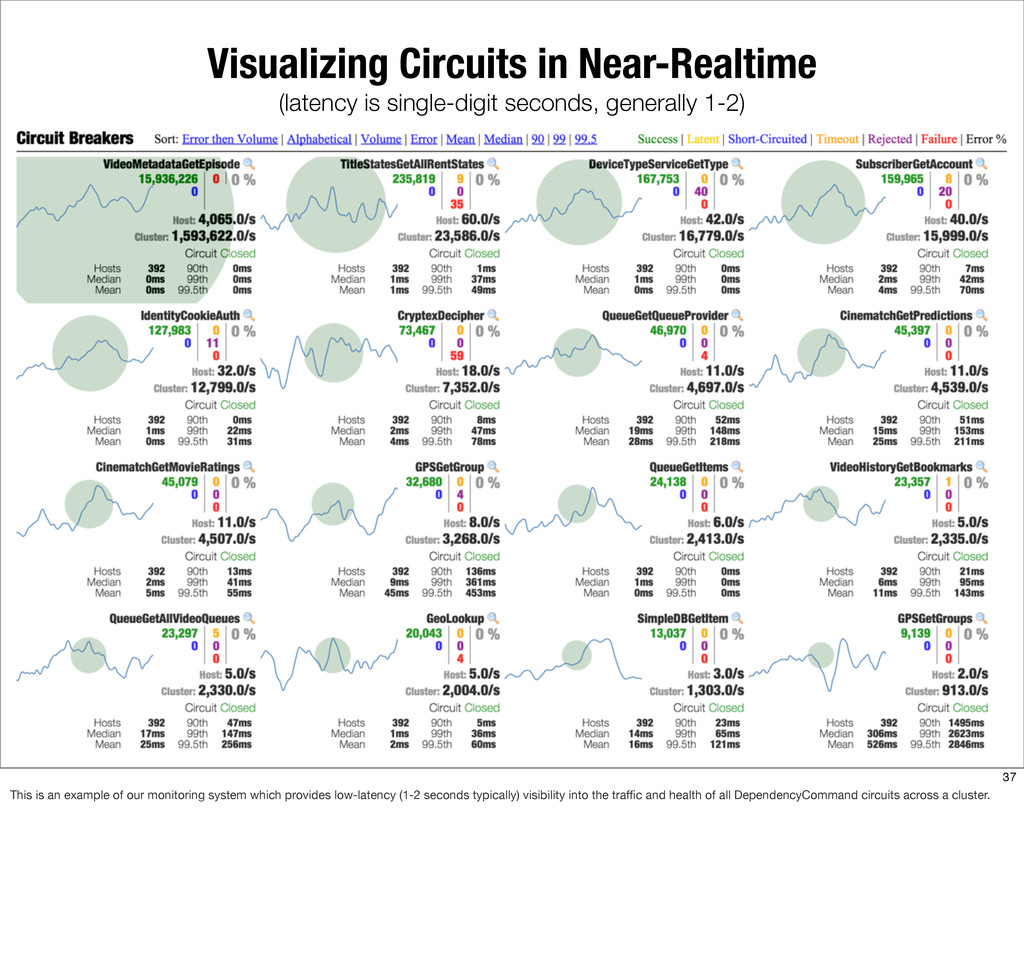{kind=link}
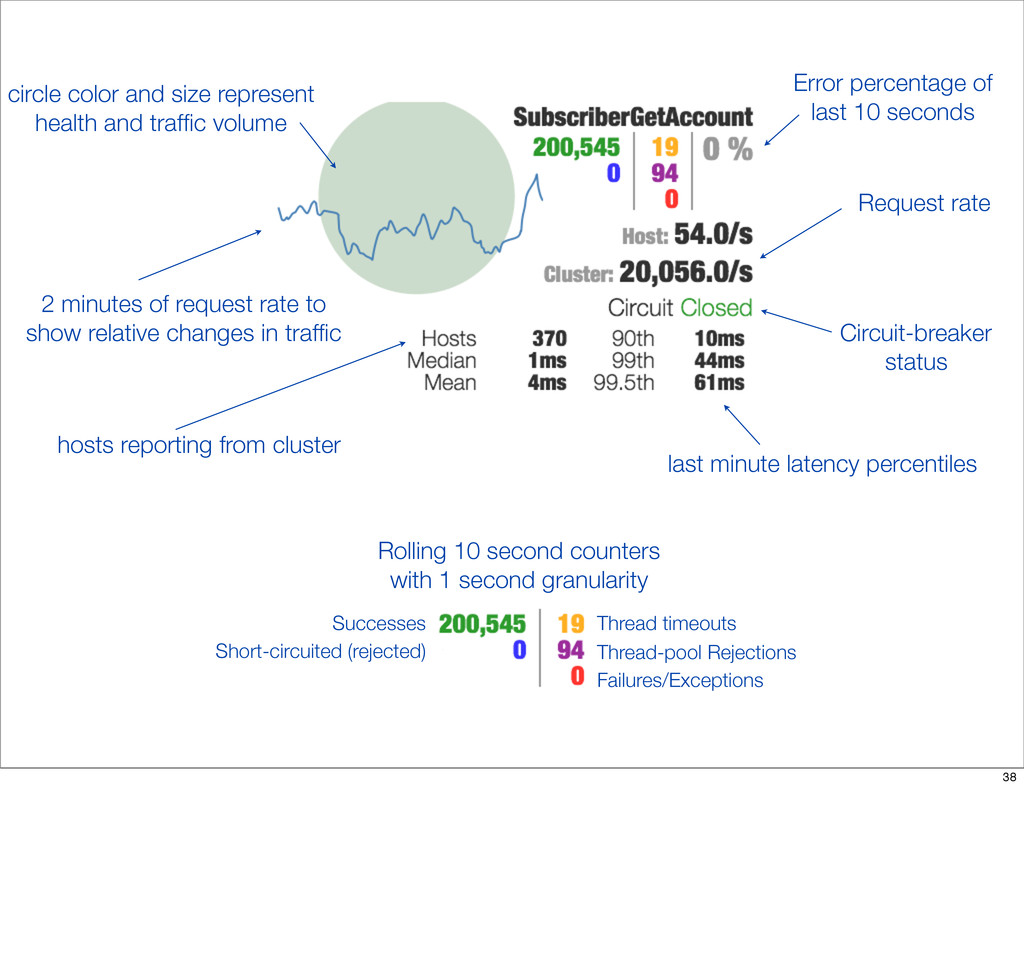{kind=link}
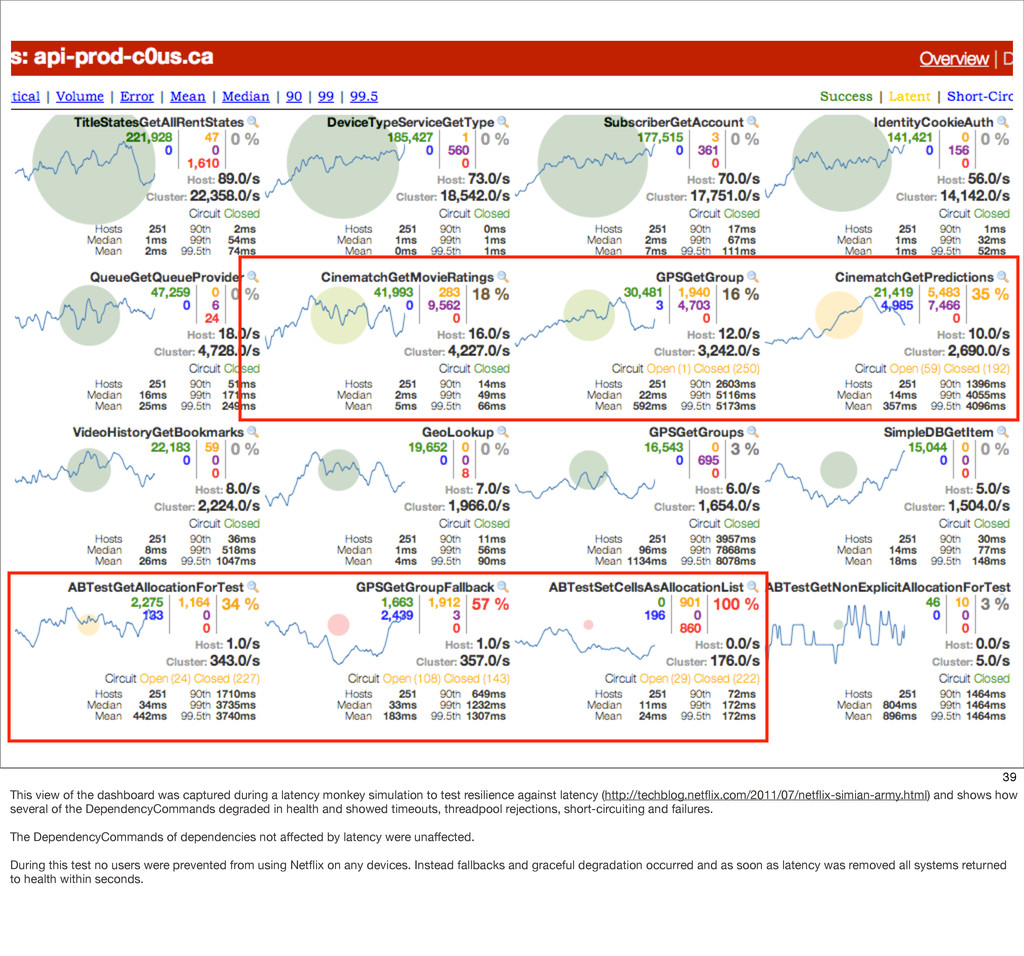{kind=link}
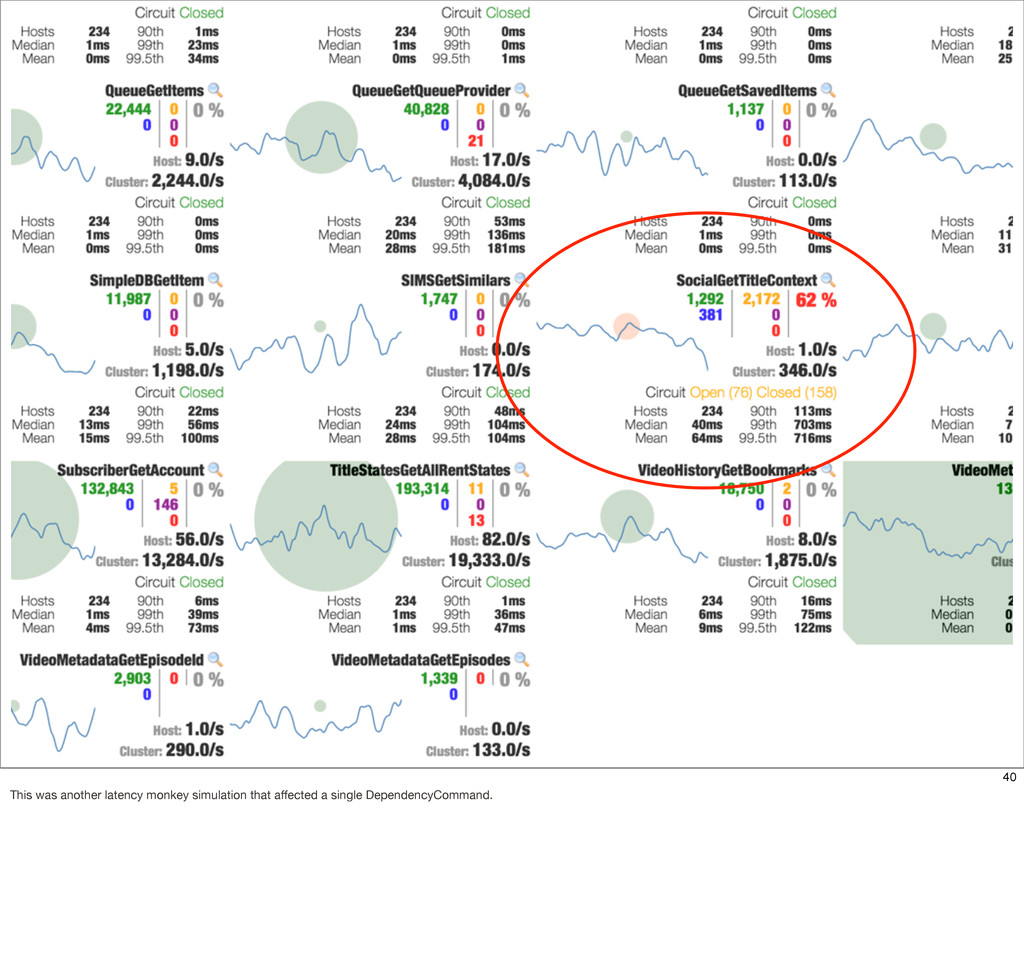{kind=link}
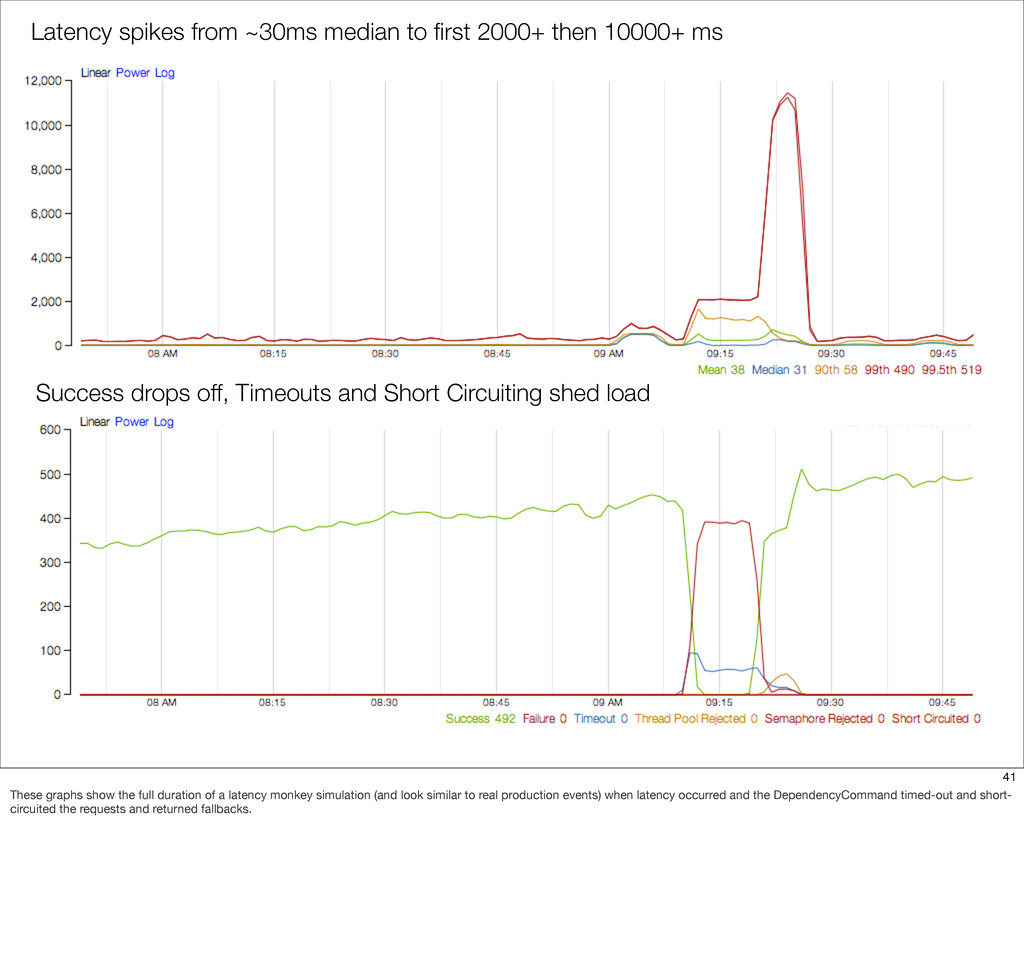{kind=link}
{kind=link}
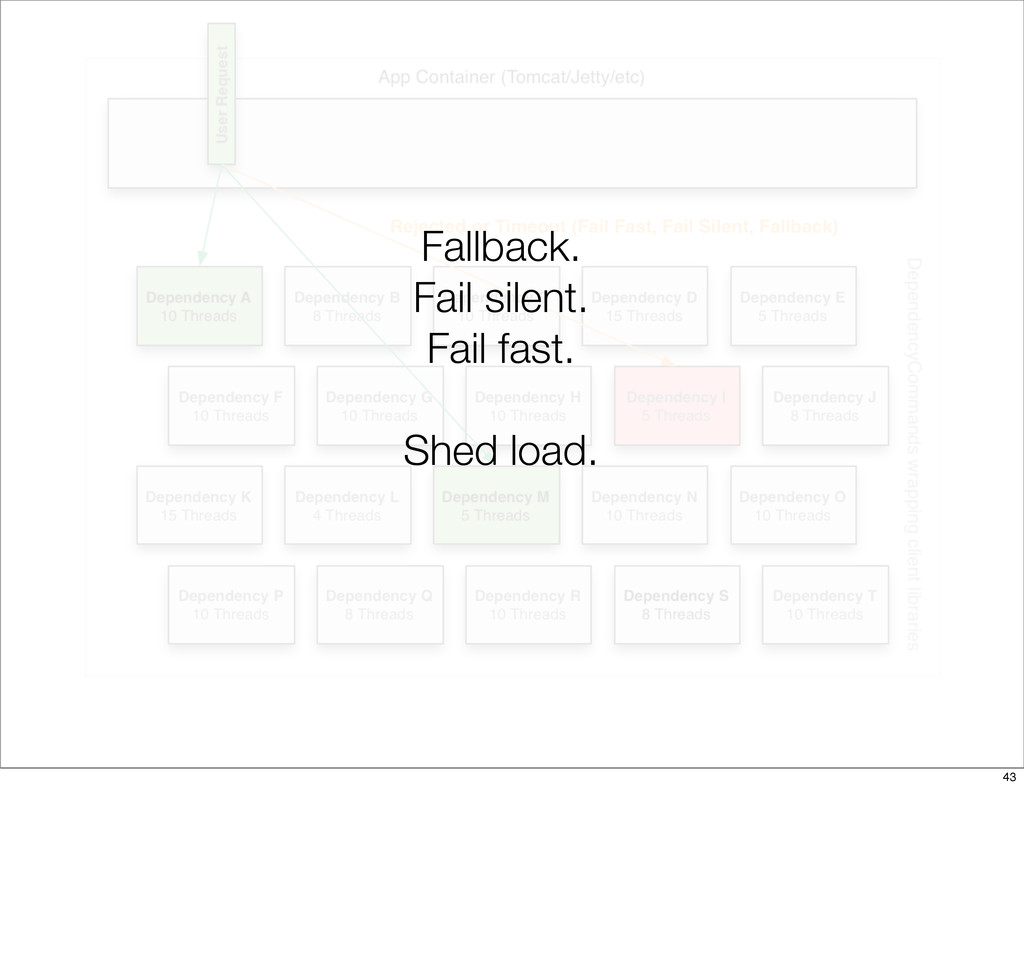{kind=link}
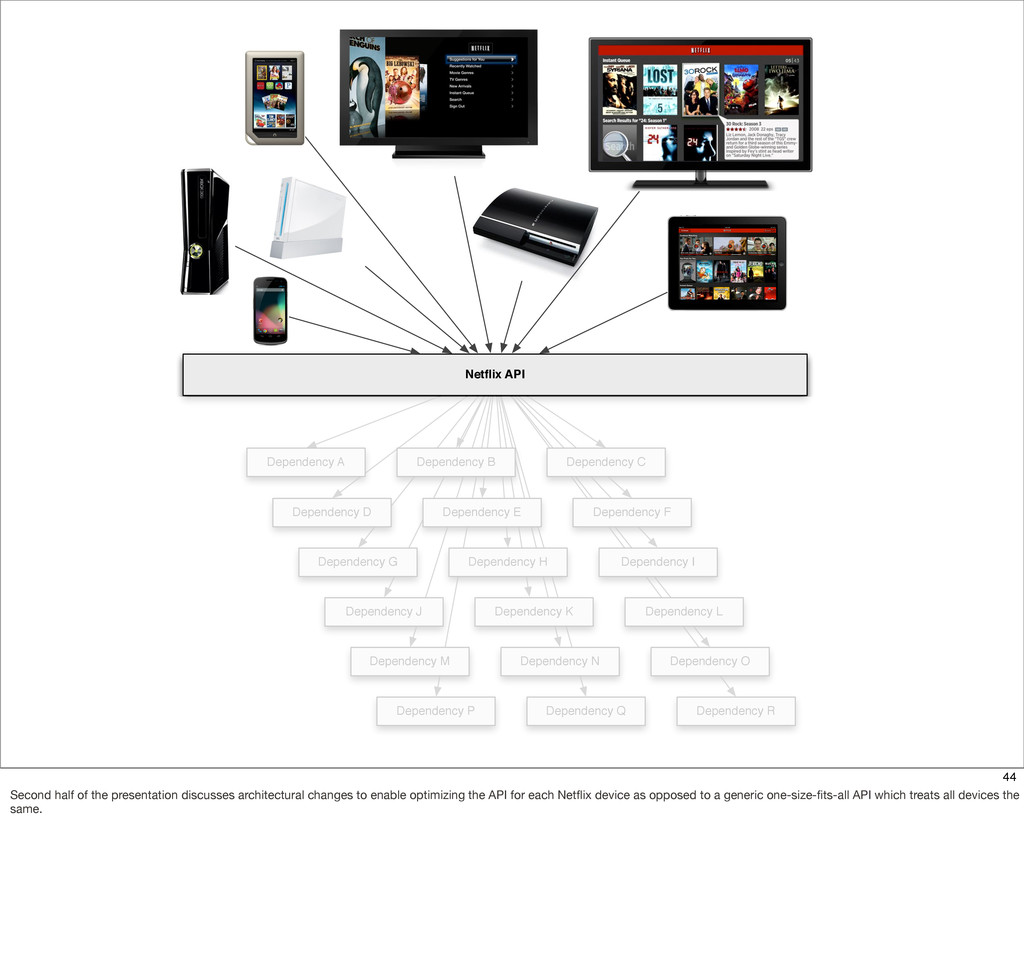{kind=link}
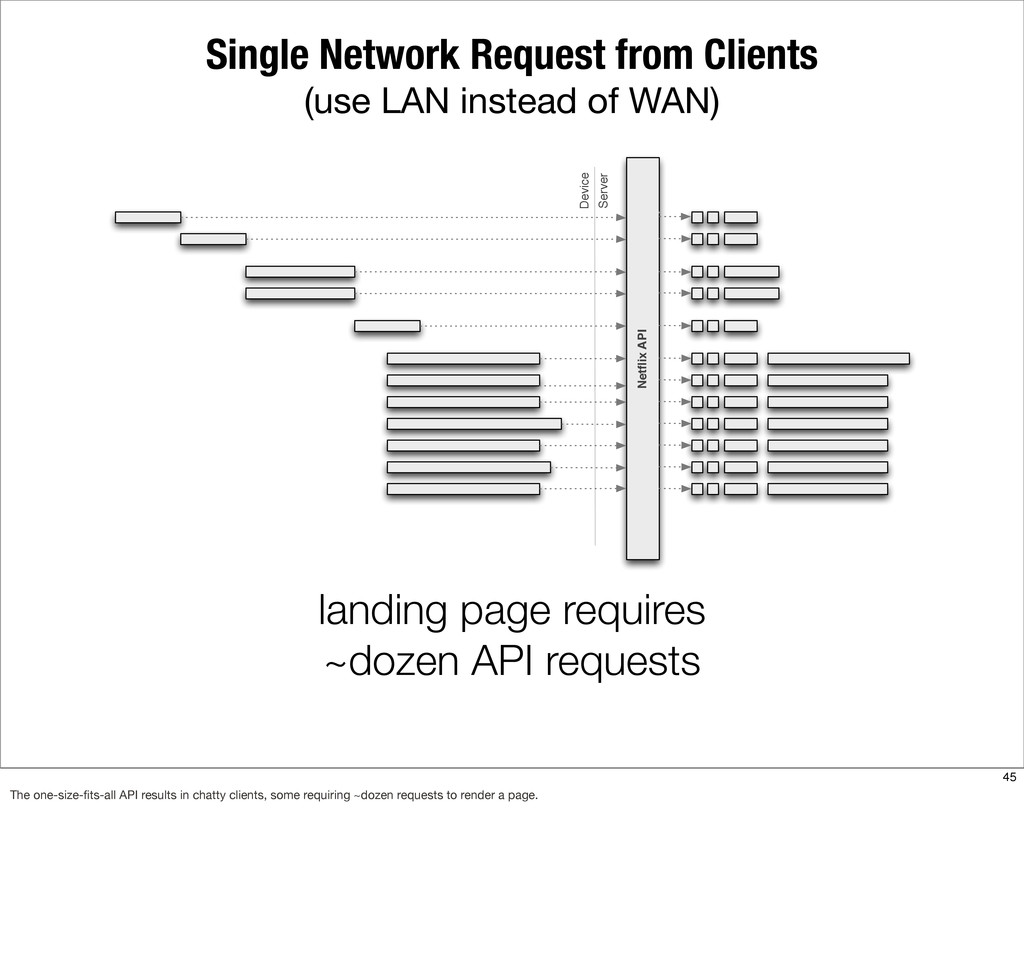{kind=link}
{kind=link}
{kind=link}
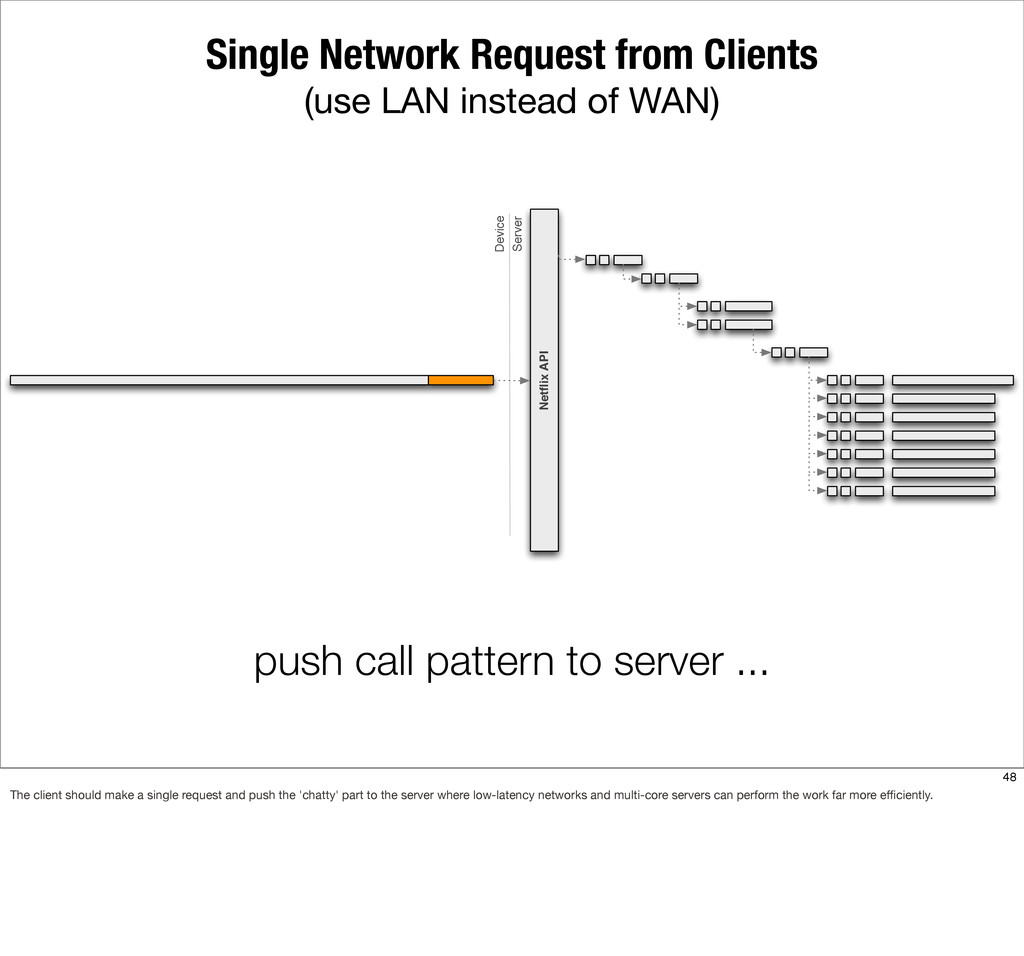{kind=link}
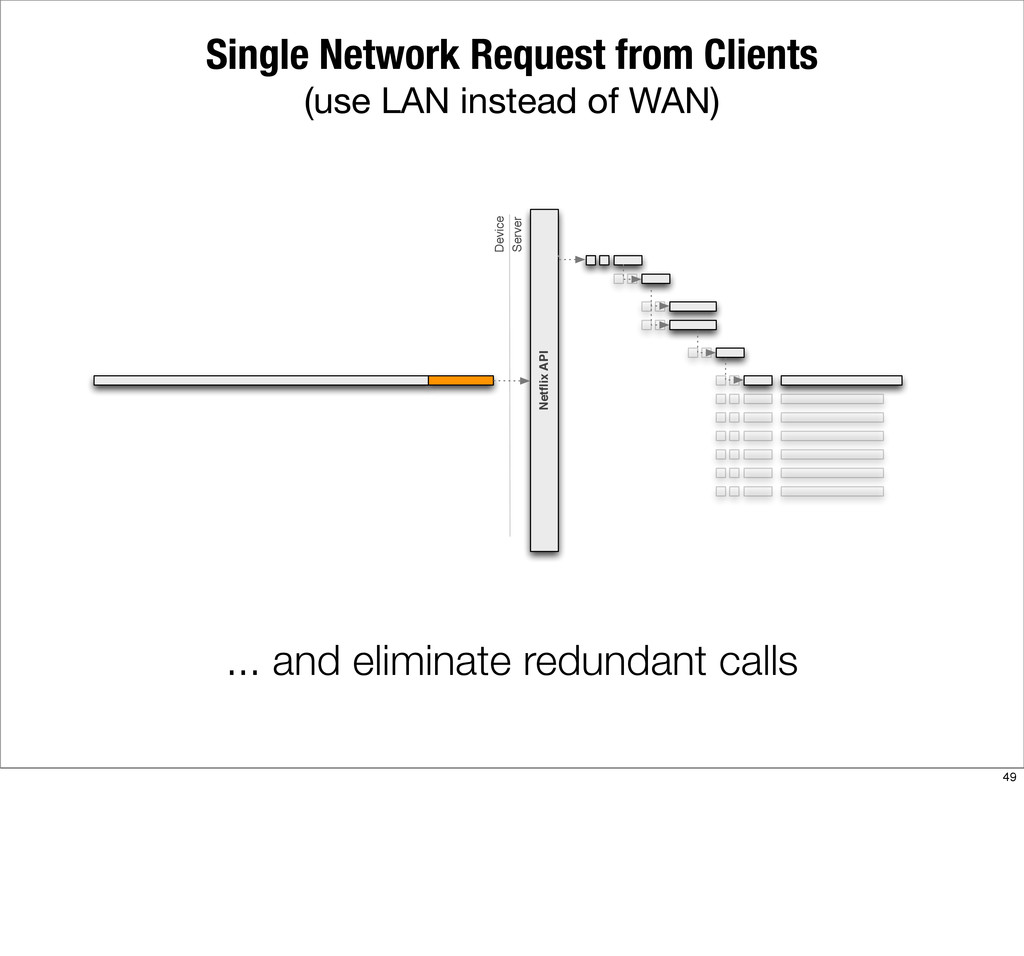{kind=link}
{kind=link}
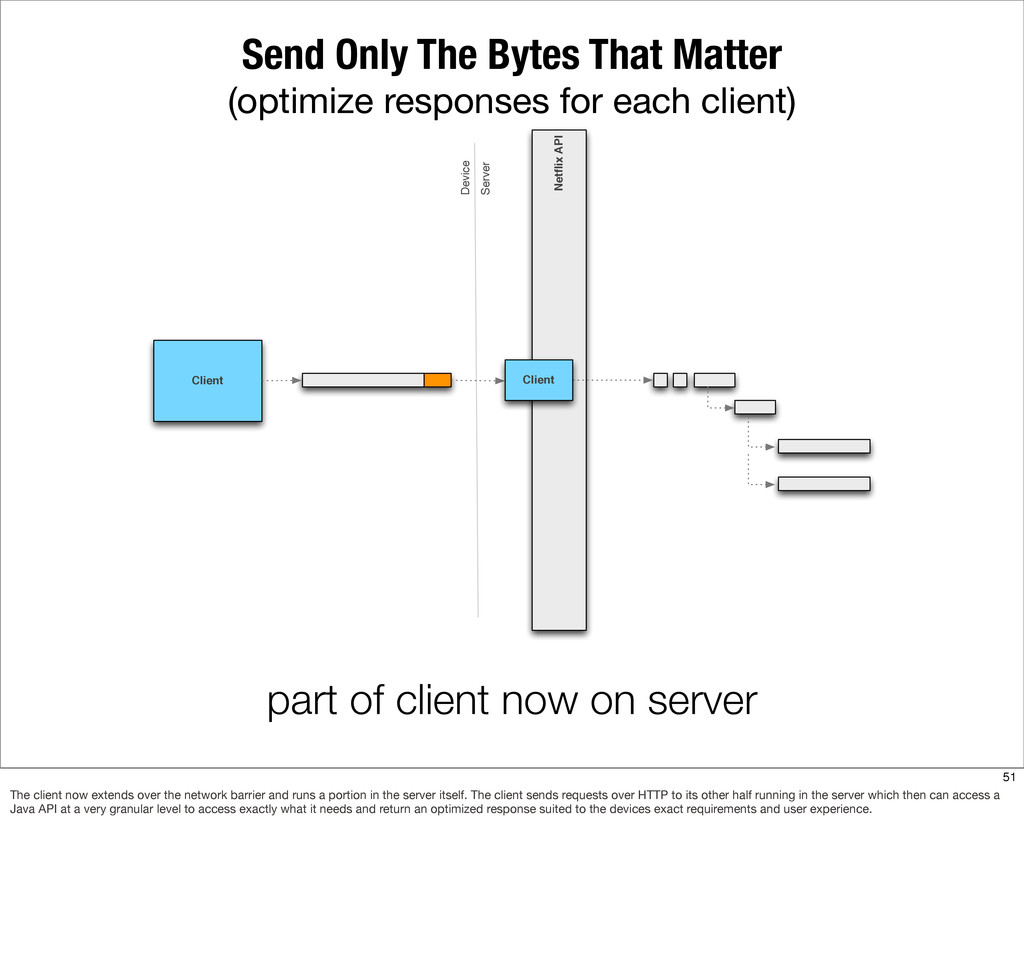{kind=link}
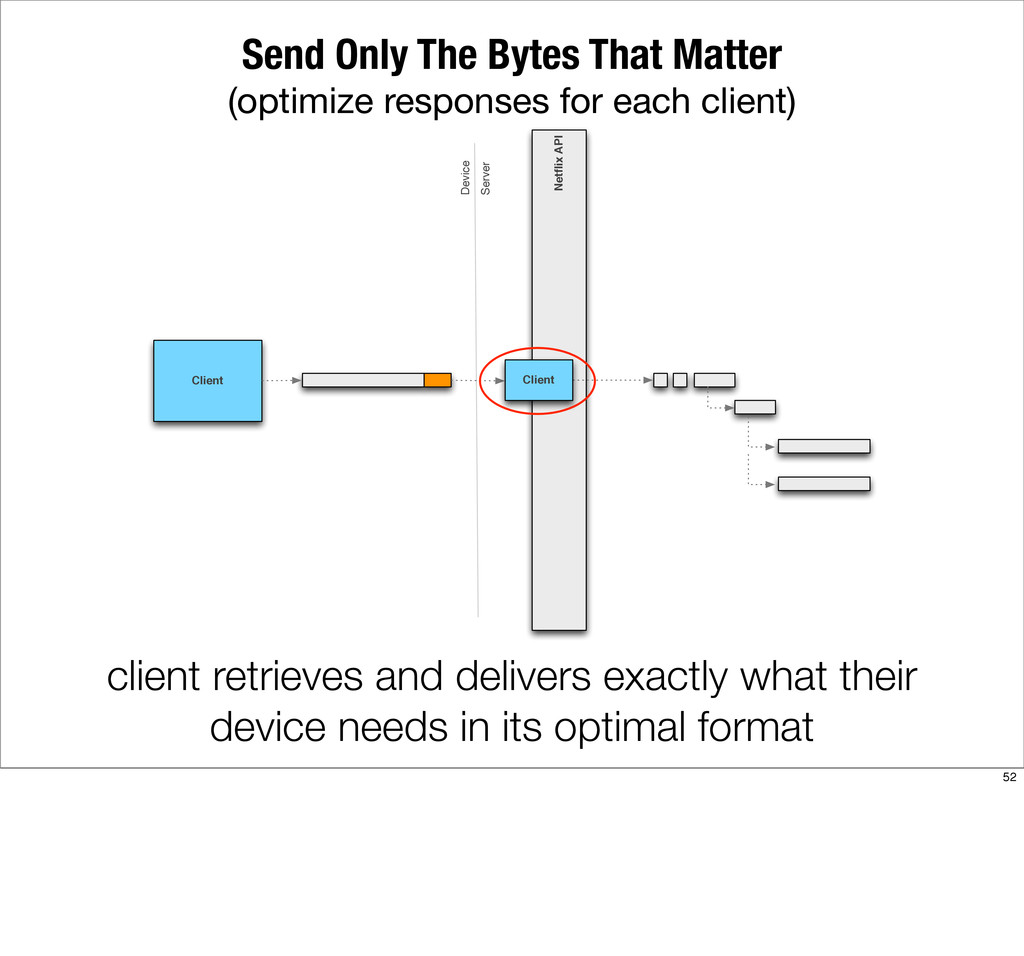{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
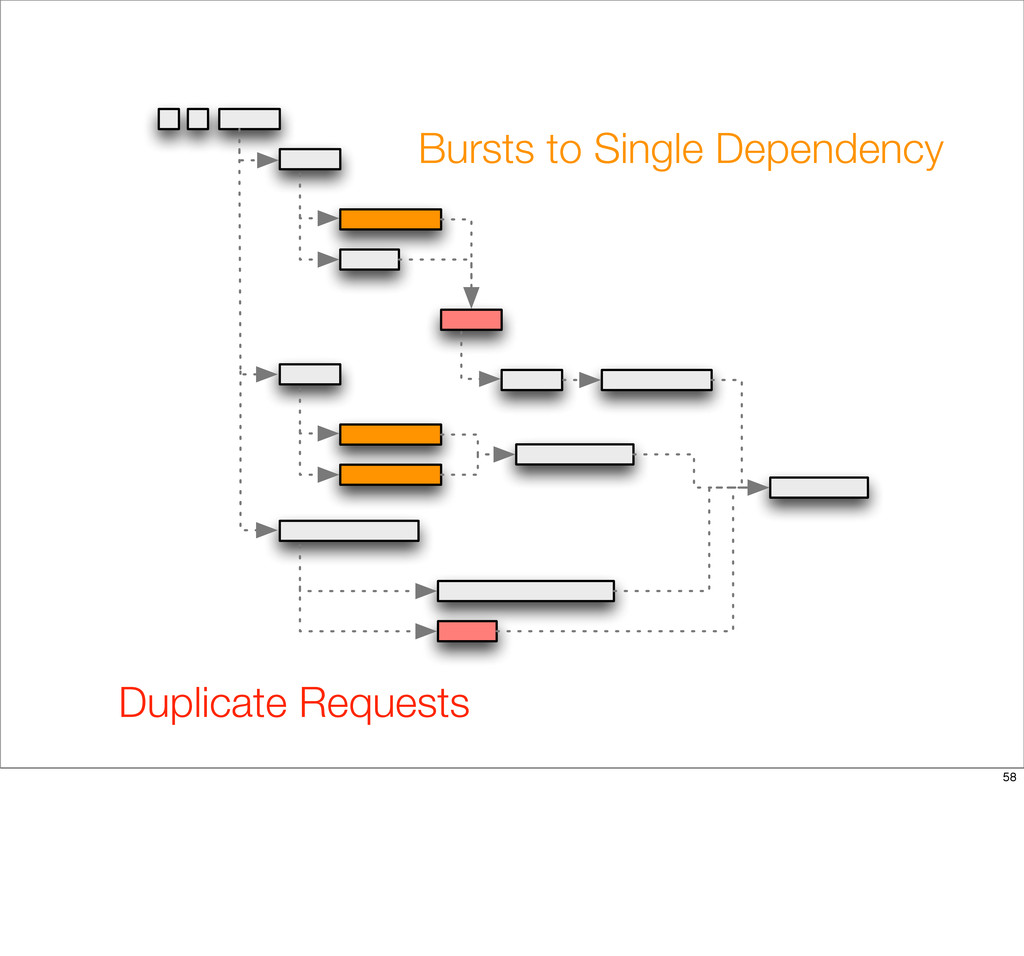{kind=link}
{kind=link}
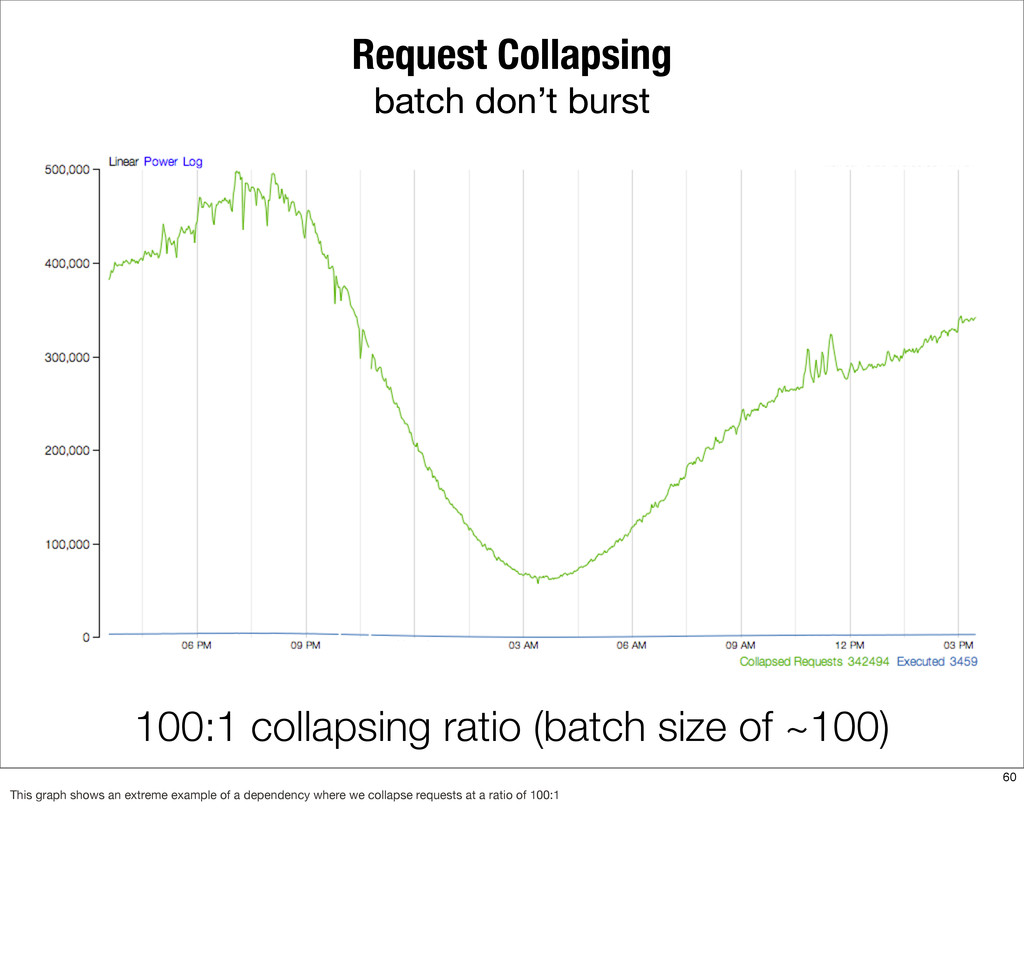{kind=link}
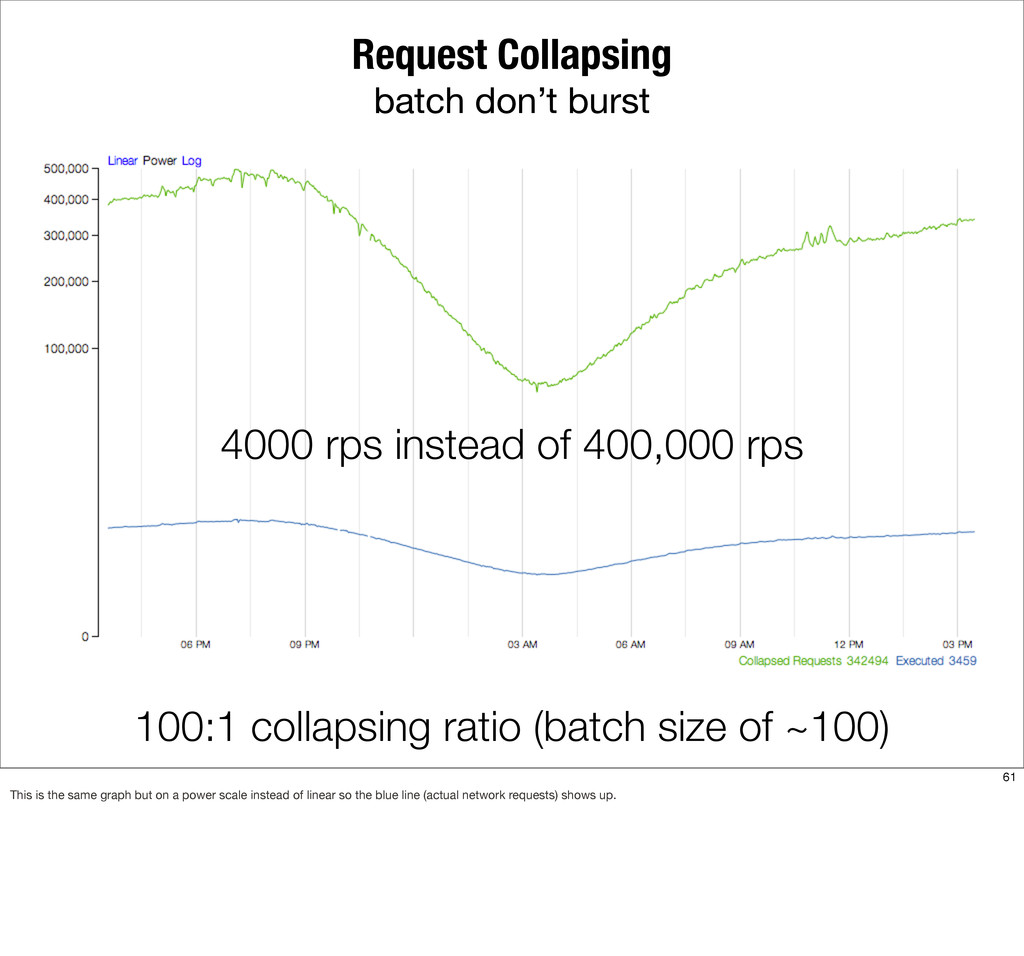{kind=link}
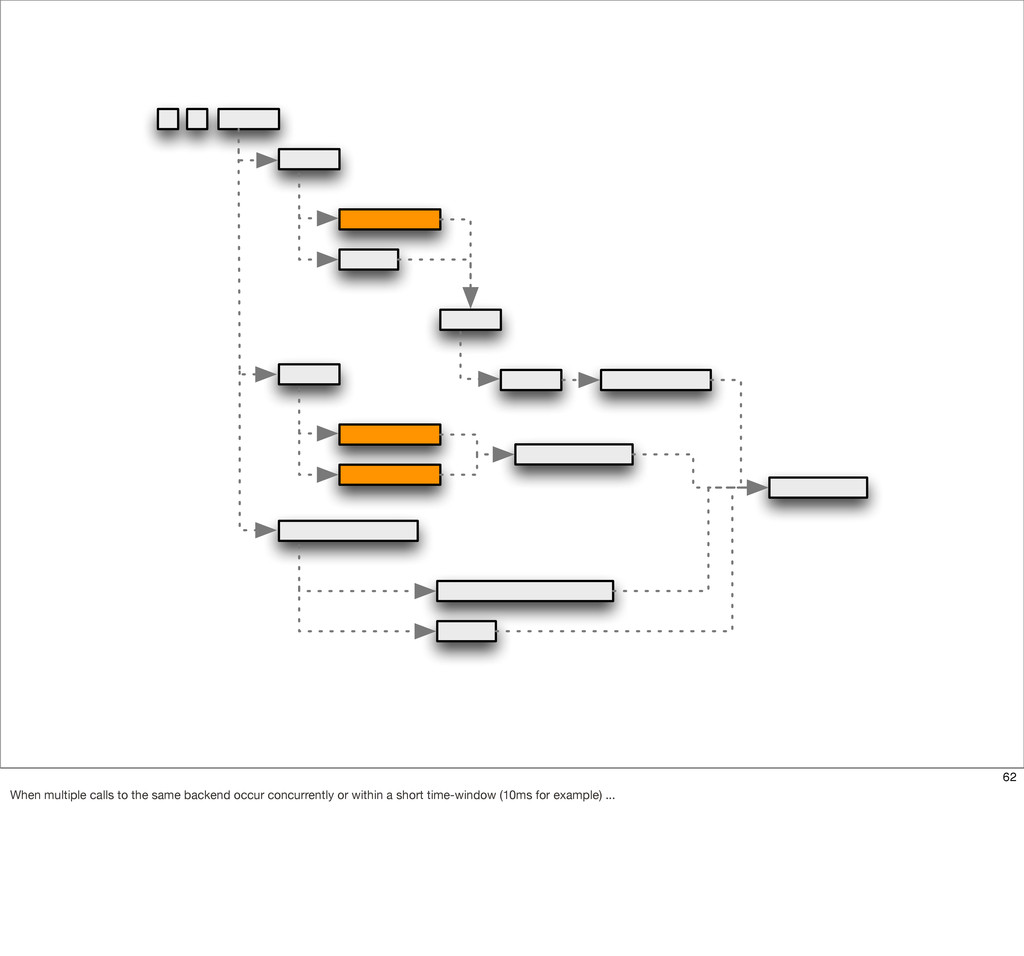{kind=link}
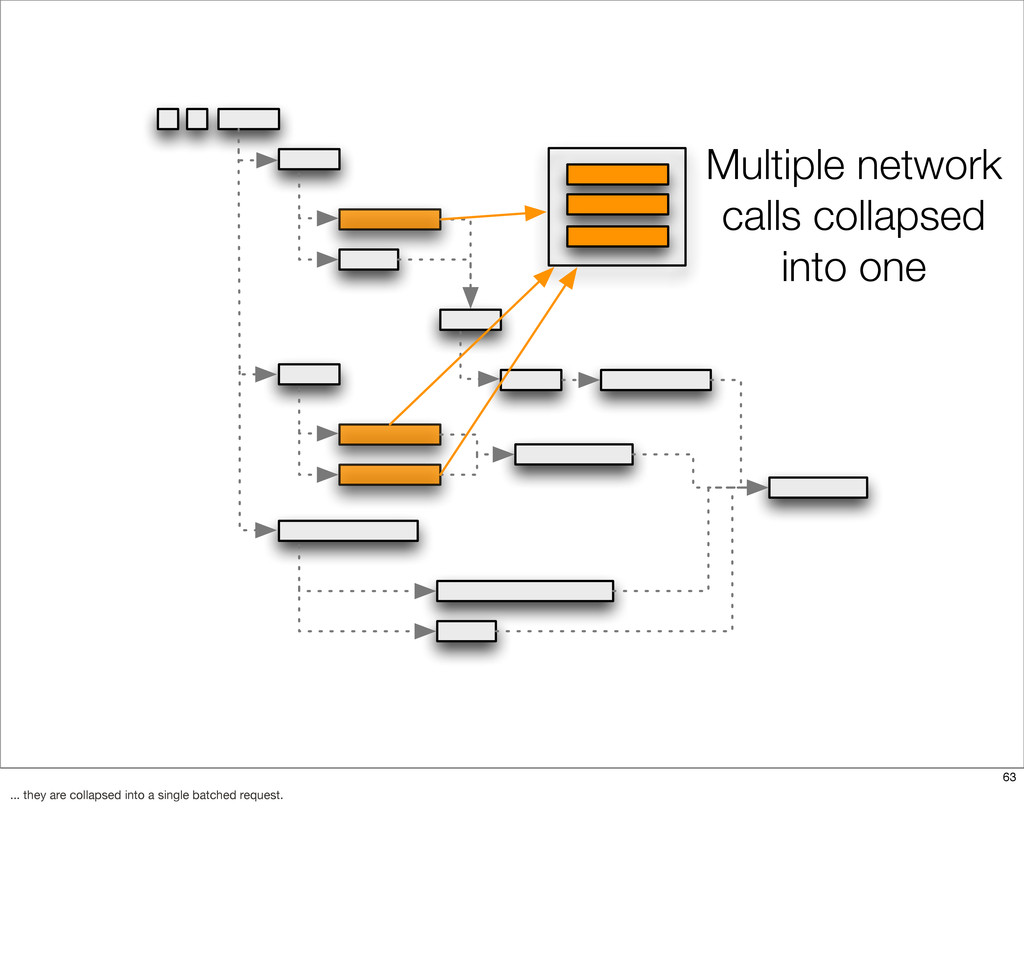{kind=link}
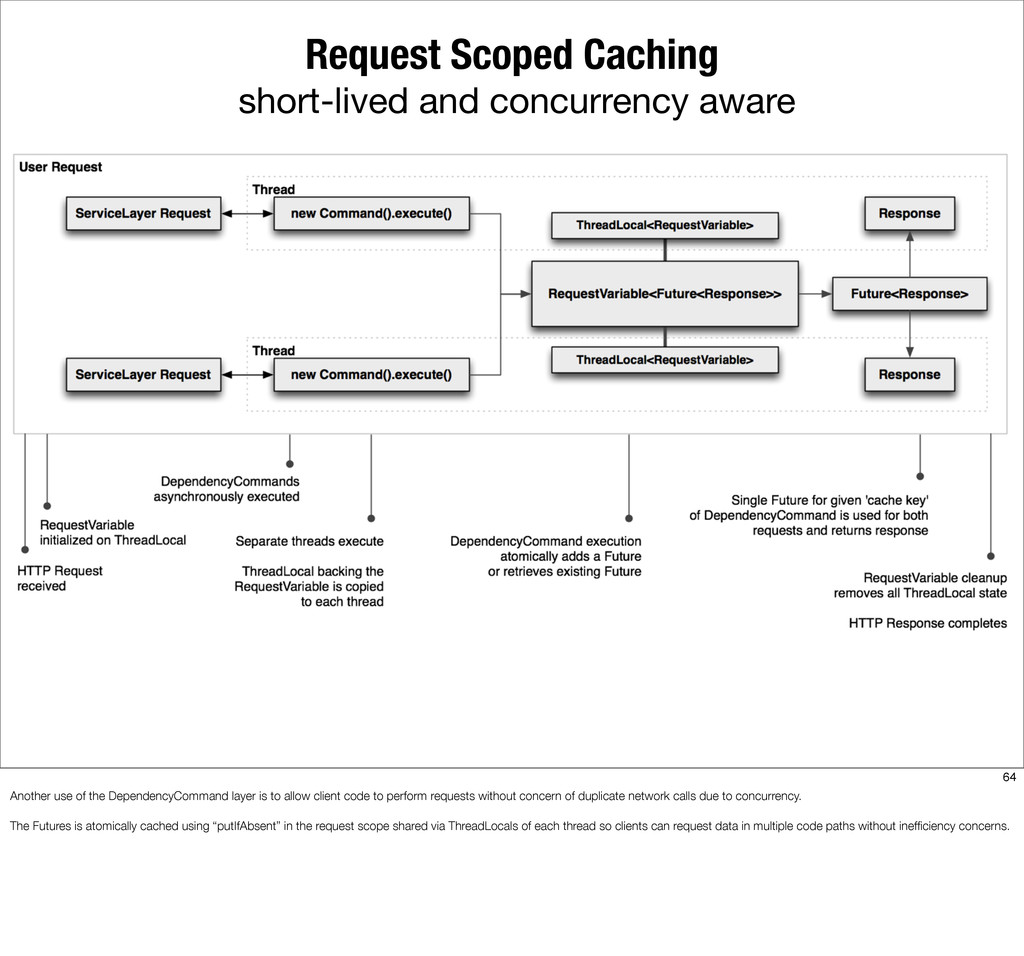{kind=link}
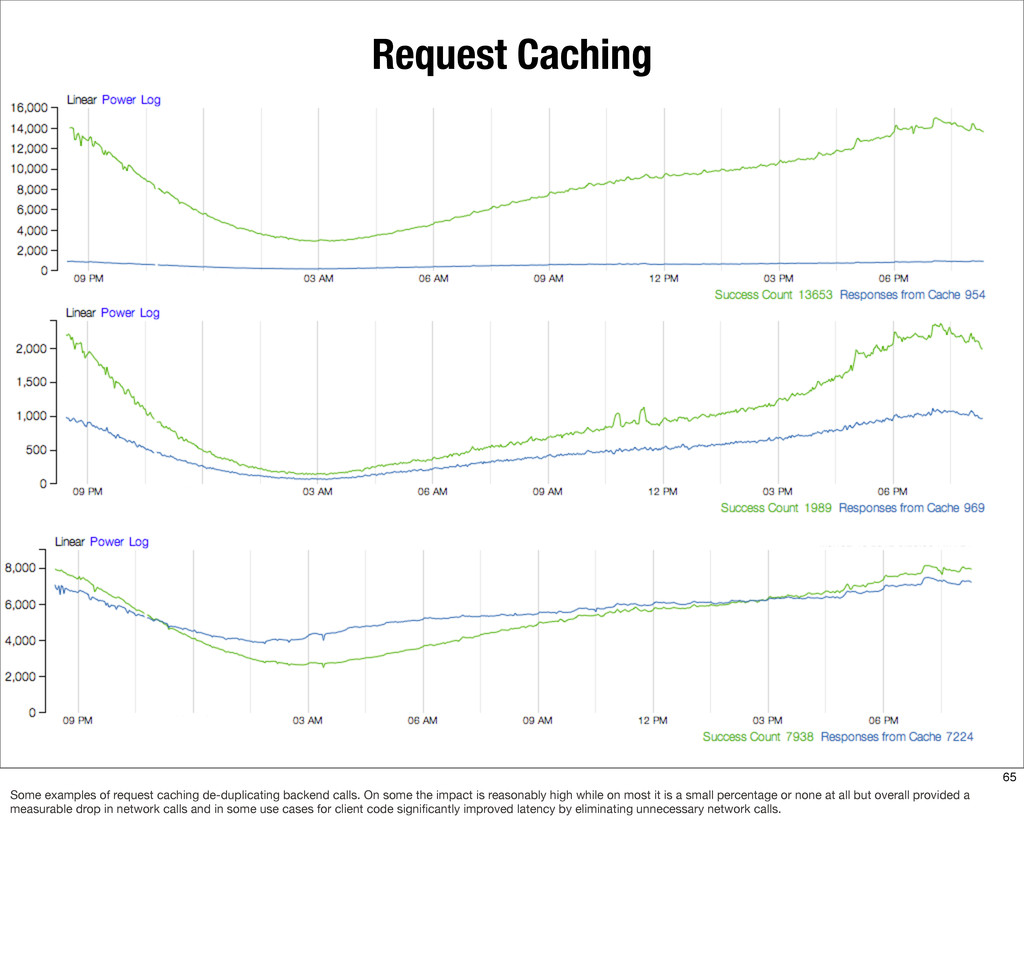{kind=link}
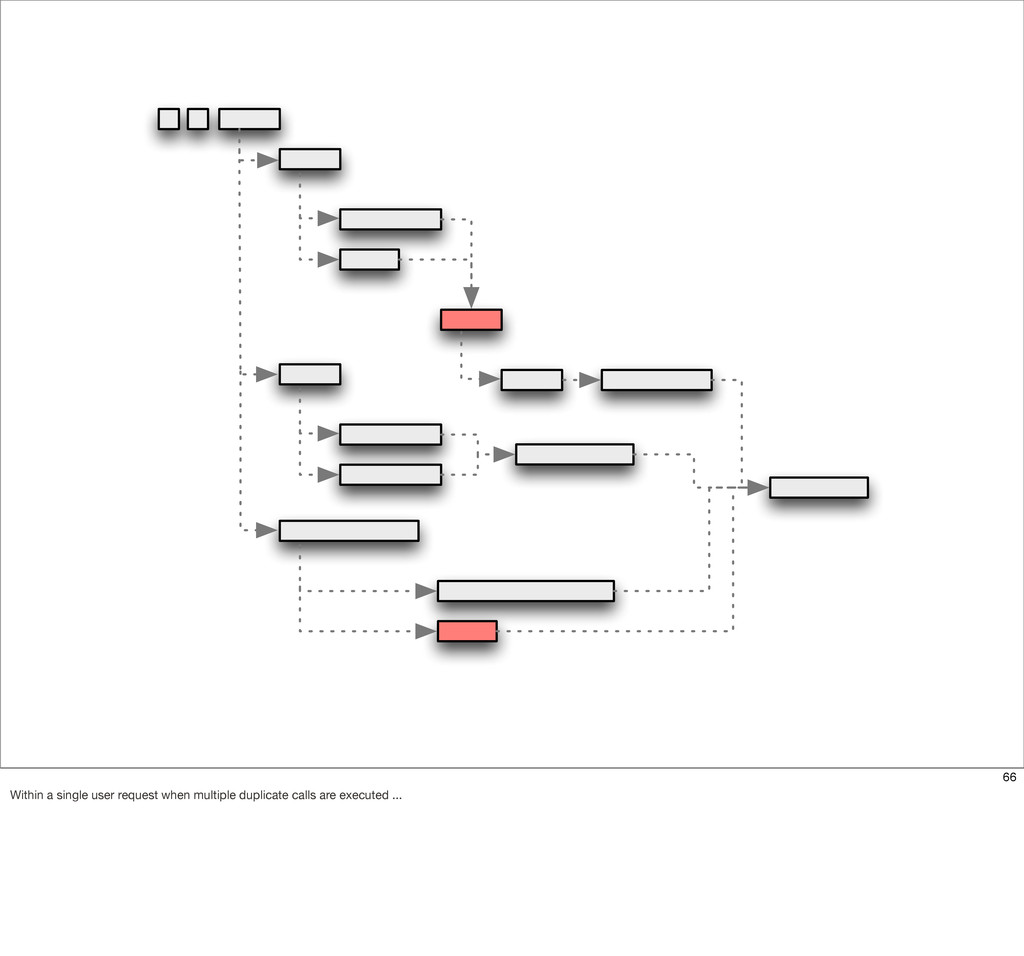{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}