Last year, during BDS14, two Allegro engineers shared their experience by presenting pitfalls and mistakes that were made when implementing data ingestion pipelines in our company. This time, Maciej Arciuch presents a brand new design and shows how accepting good advices can result in a drastic design change and how making mistakes can teach us a lot.
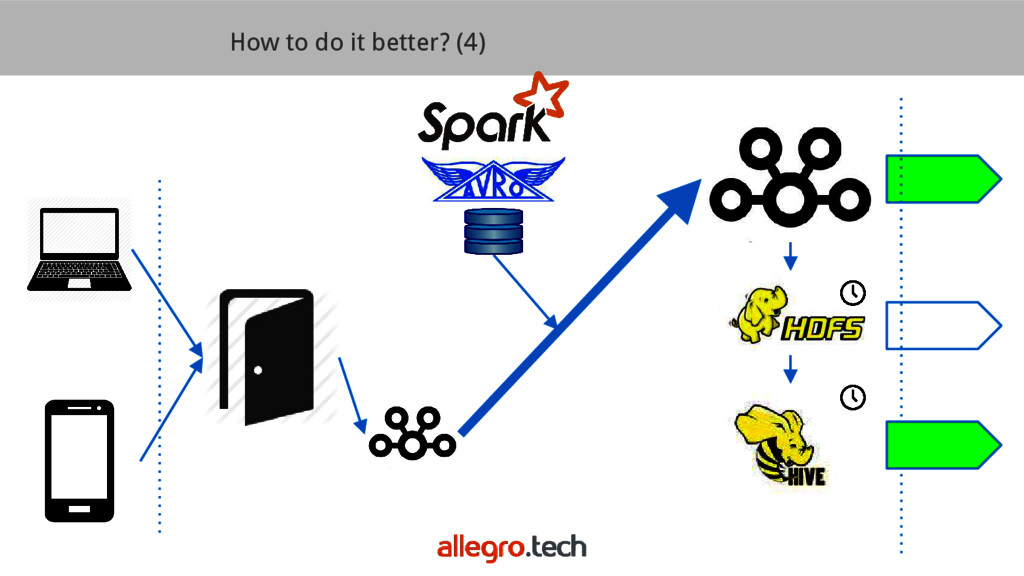
The design presented during BDS14 as an anti-pattern was an HDFS-centric system storing semi-structured, but hardly documented JSON documents. Moreover, there was no buffer between the traffic and HDFS. Data was not monitored well enough and low level, error-prone APIs like Hadoop MapReduce in Java were used to manipulate data. Data was available in hourly or daily batches. Large number of small files caused name nodes to choke.
Session presented at Big Data Spain 2015 Conference
16th Oct 2015
Kinépolis Madrid
http://www.bigdataspain.org
Event promoted by: http://www.paradigmatecnologico.com
Abstract: http://www.bigdataspain.org/program/fri/slot-29.html#spch29.1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}