Application Virtualization o UNIX server applications o Solaris 2.6 applications on Solaris 10 • Real-time Operating Systems o Hubble Space Telescope o Under Wing Armaments o Medical Instruments • Launch Processing System o NASA Kennedy Space Center o Hardware and Software Design of Ground-based Launch Control Systems
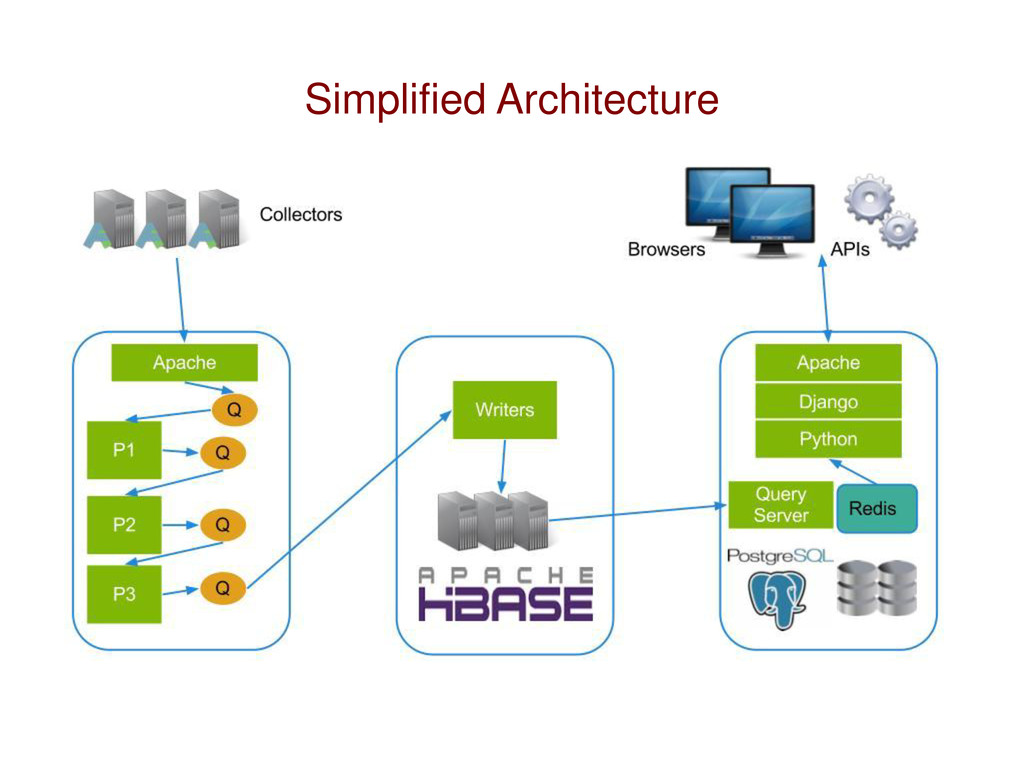
summarize data from 10ks of remote servers o Provide information for web apps and APIs • A Few Metrics o 45k to 50k summaries per minute o GBs per remote server per day o TBs of new data daily o Query & retrieve information in < 100 MS o Data store for up to 1 year AppFirst Collects, Aggregates and Correlates Information from Production Applications
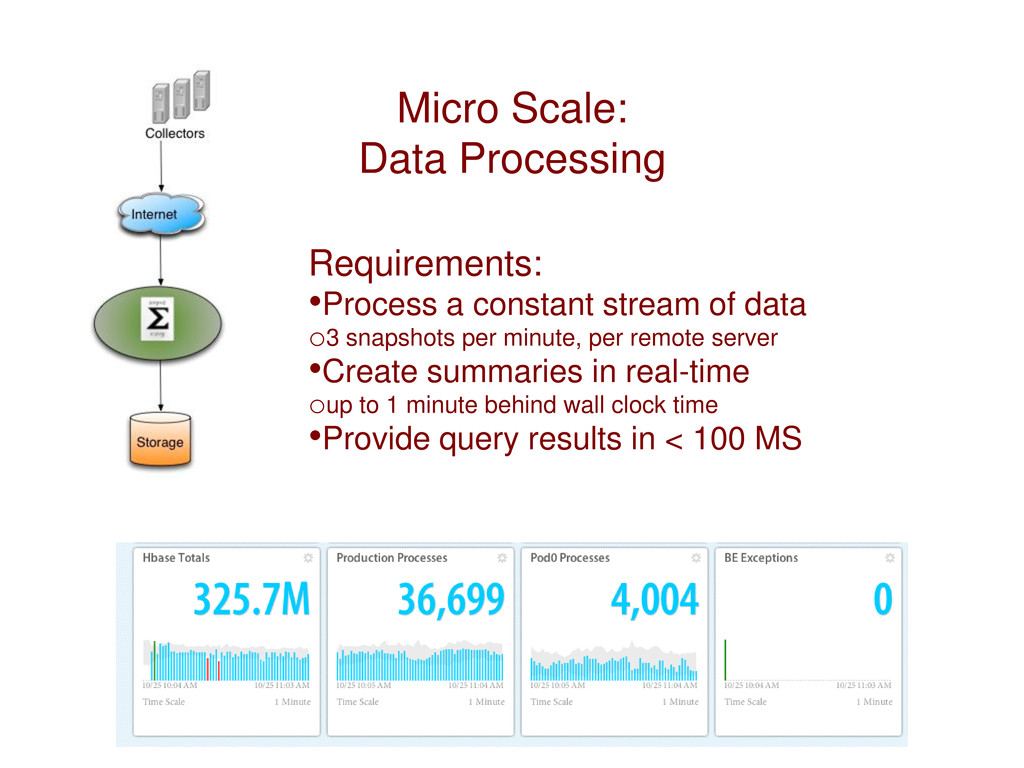
data o3 snapshots per minute, per remote server •Create summaries in real-time oup to 1 minute behind wall clock time •Provide query results in < 100 MS
were needed in order to keep queries < 100 MS oServer oProcess oProcess sets oTopology •Time series needed for each summary type oMinute oHour oDay We tried: •Flat files •Network file systems •Distributed file systems •Relational databases •NoSQL key-value store •Memory based SQL databases •Distributed shared memory
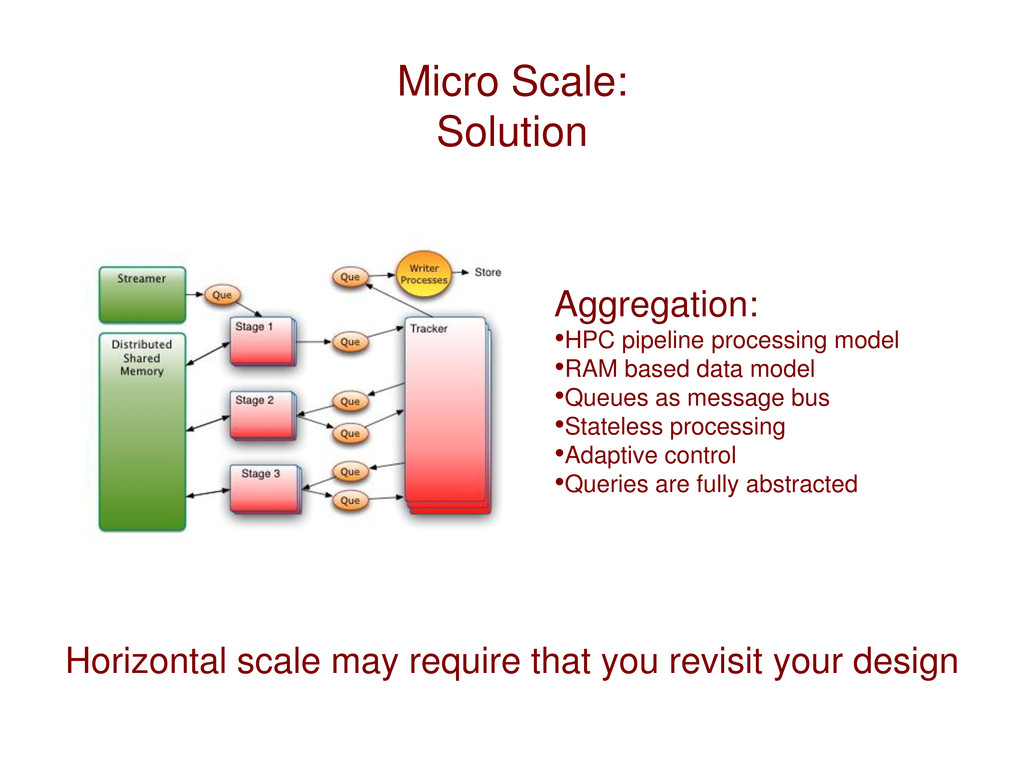
data model •Queues as message bus •Stateless processing •Adaptive control •Queries are fully abstracted Horizontal scale may require that you revisit your design
Stateless •Any data processing with any time constraint •Processes can be run on any server •Processes can be migrated •Multiple processes can be added as load varies •All data stored in distributed shared memory •Message passing between components •Send keys and not data Cluster •Use components that cluster •Don’t do backups, use replication •Redis, memcached, RabbitMQ, Hbase can be clustered •Postgresql & MySQl don’t really cluster
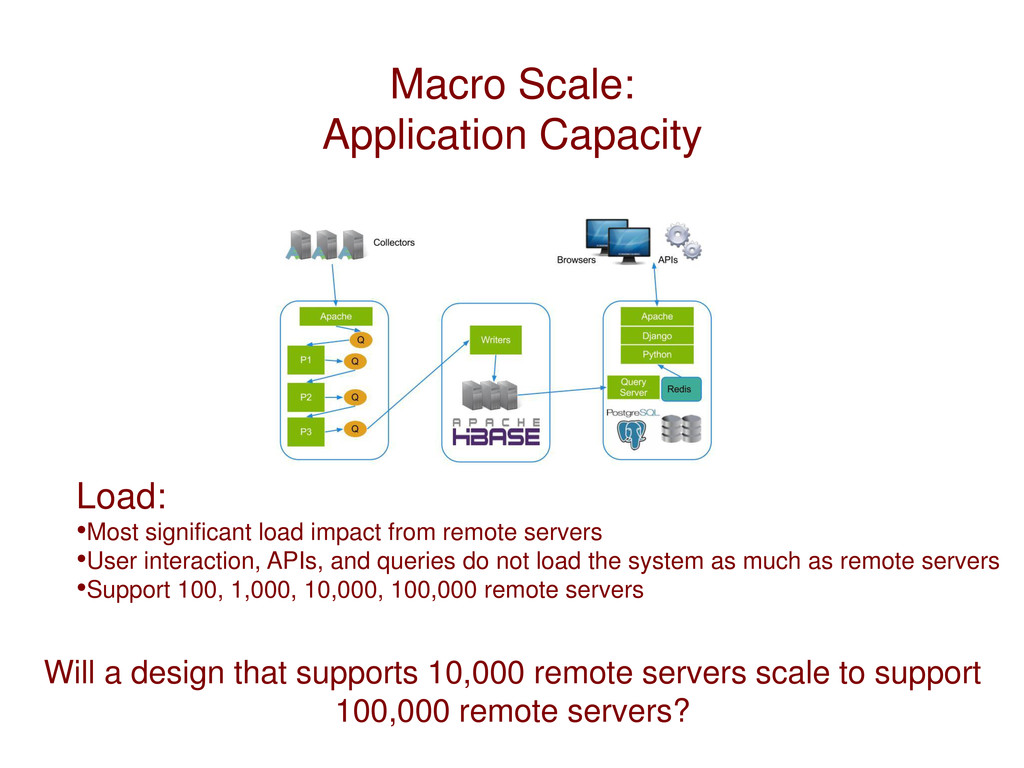
remote servers •User interaction, APIs, and queries do not load the system as much as remote servers •Support 100, 1,000, 10,000, 100,000 remote servers Will a design that supports 10,000 remote servers scale to support 100,000 remote servers?
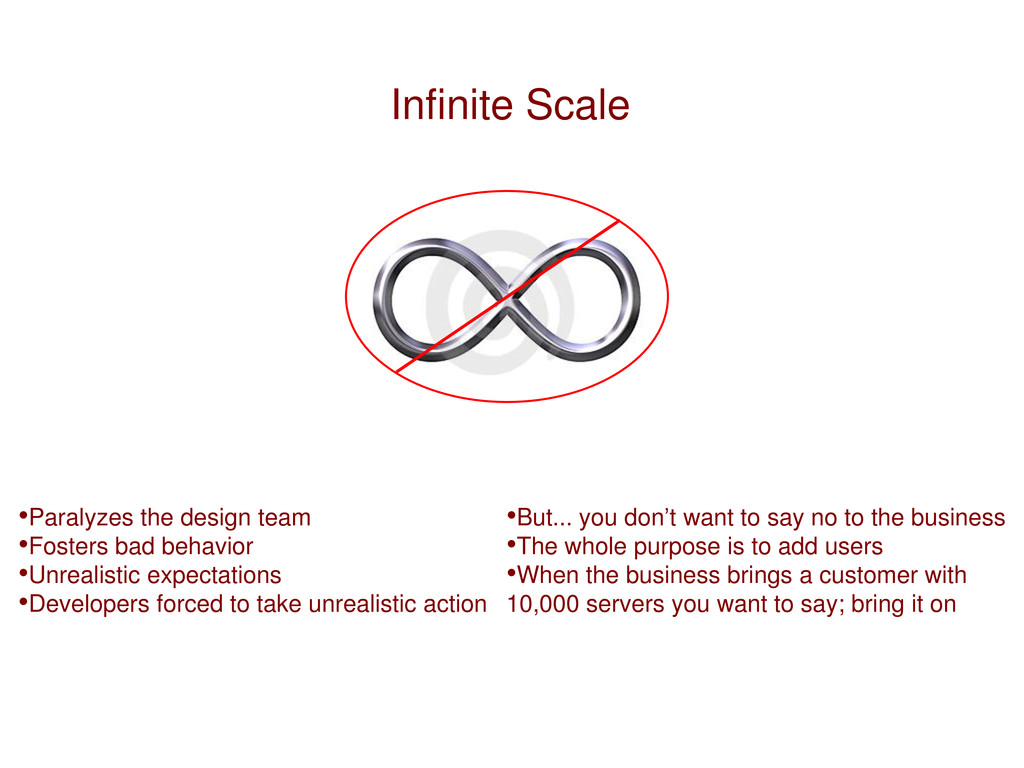
expectations •Developers forced to take unrealistic action •But... you don’t want to say no to the business •The whole purpose is to add users •When the business brings a customer with 10,000 servers you want to say; bring it on
remote servers •Micro scale results made it possible to scale out •fairly flexible application component design •Scale out to 10,000 remote servers •This is a financial calculation •Scaled out in linear fashion •Data processing •Storage •Started in linear fashion then determined actual requirements
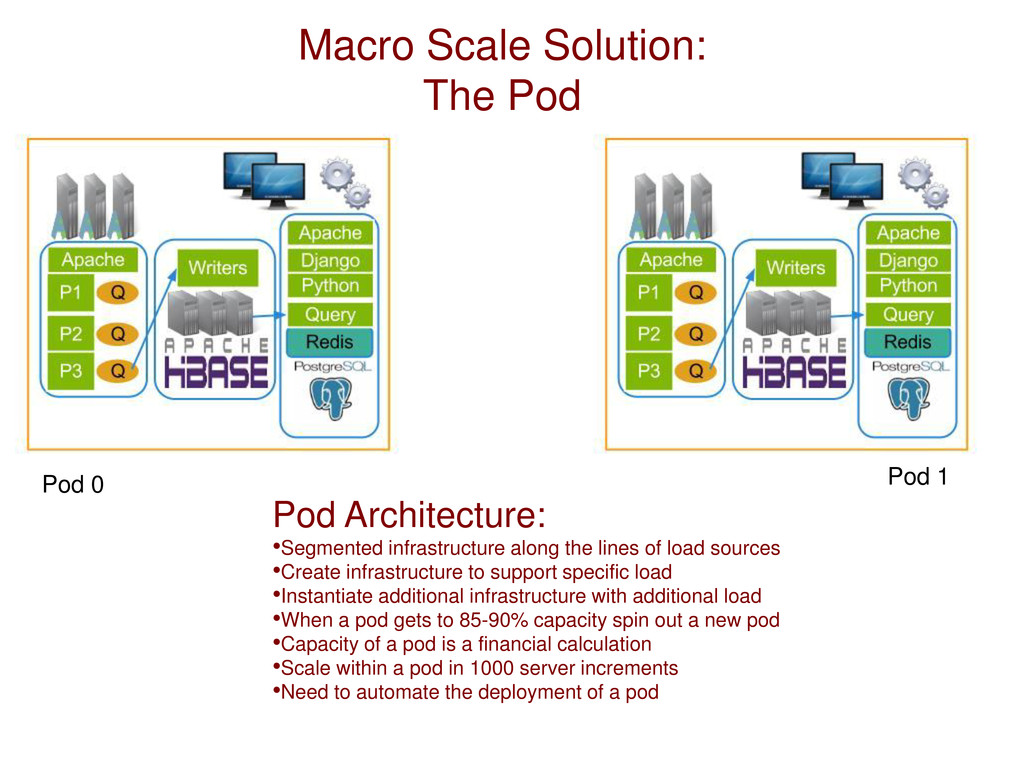
the lines of load sources •Create infrastructure to support specific load •Instantiate additional infrastructure with additional load •When a pod gets to 85-90% capacity spin out a new pod •Capacity of a pod is a financial calculation •Scale within a pod in 1000 server increments •Need to automate the deployment of a pod Pod 0 Pod 1
back •Migrate Metrics are king •Business metrics •Application metrics Time Series Data •Issues relate to a specific time •Complete state information for any given minute •Don’t know what info is needed before a problem occurs; all data every minute Don’t trust the data •Clocks are skewed •Encodings fail •Save all bad data & replay •Think defensive The Pod Rocks •Isolated •Distributed •Located where needed •Behind the firewall
oRAM based design is critical, not optional •Cluster oUse components that cluster, not just master/salve •Design for infinite scale does not work •Pod approach is an answer for infinite scale
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You! Donn Rochette [email protected] www.appfirst.com](https://files.speakerdeck.com/presentations/92dd84501b6e013014db1231380fad16/slide_17.jpg){kind=link}