BigDL is a deep learning framework modeled after Torch and open-sourced by Intel in 2016. BigDL runs on Apache Spark, a fast, general, distributed computing platform that is widely used for Big Data processing and machine learning tasks.
https://www.bigdataspain.org/2017/talk/deep-learning-in-spark-with-bigdl
Big Data Spain 2017
16th -17th November Kinépolis Madrid
{kind=link}
![Deep Learning in Spark with BigDL Petar Zečević [email protected] https://hr.linkedin.com/in/pzecevic](https://files.speakerdeck.com/presentations/efc2d353ffb44b87b5e0c8b08c453ce4/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
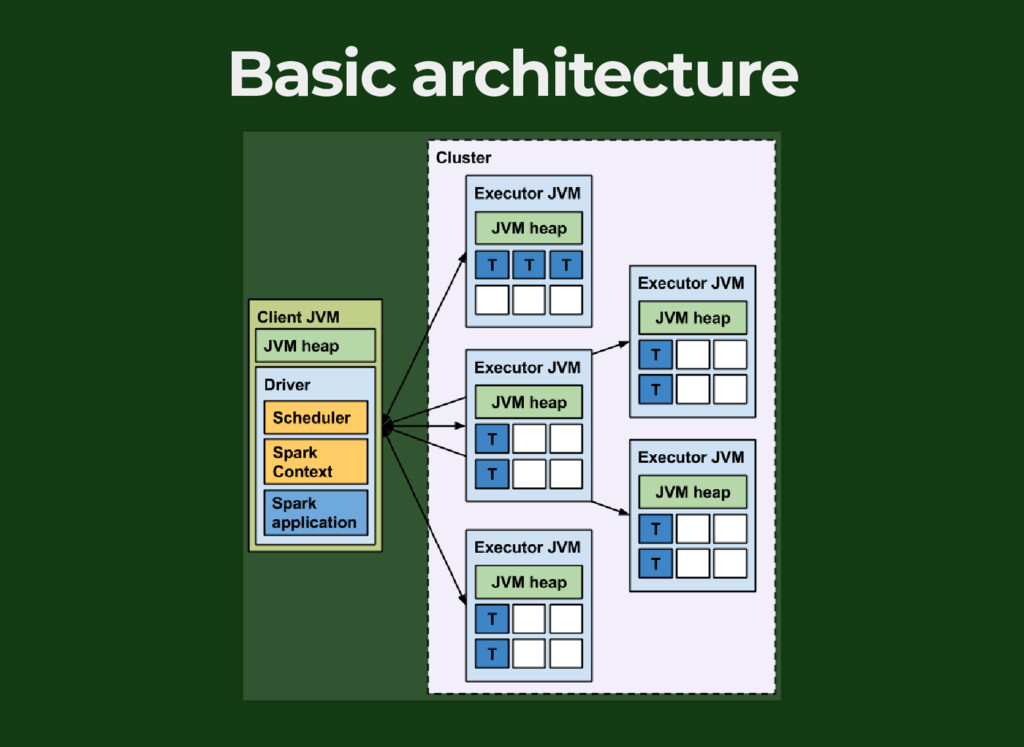{kind=link}
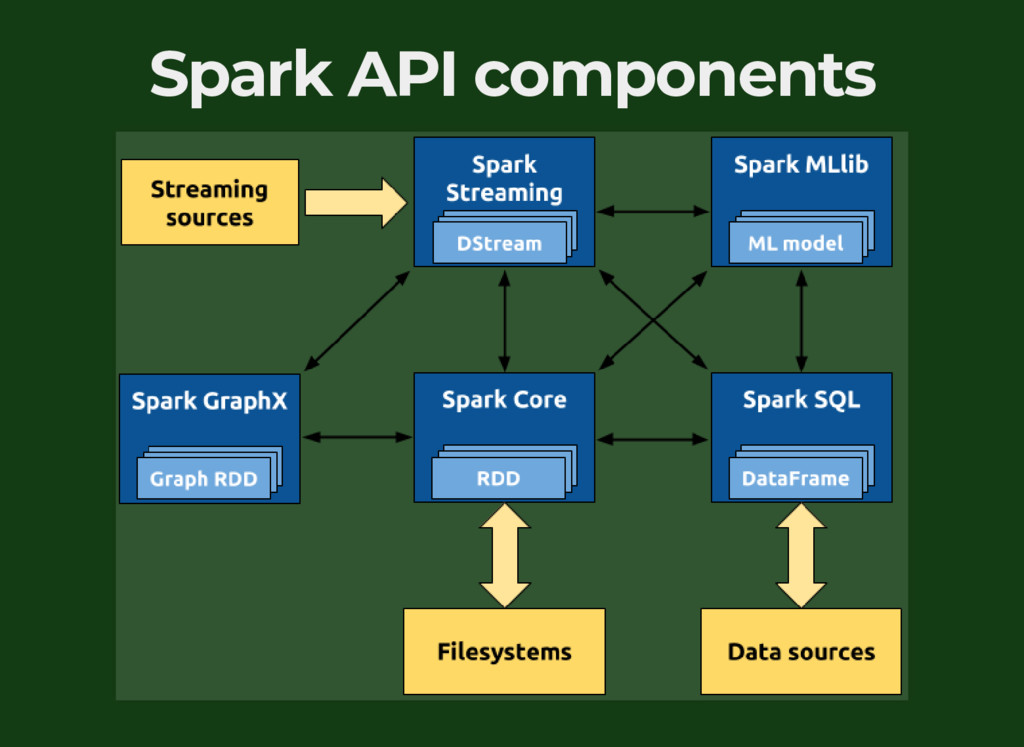{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
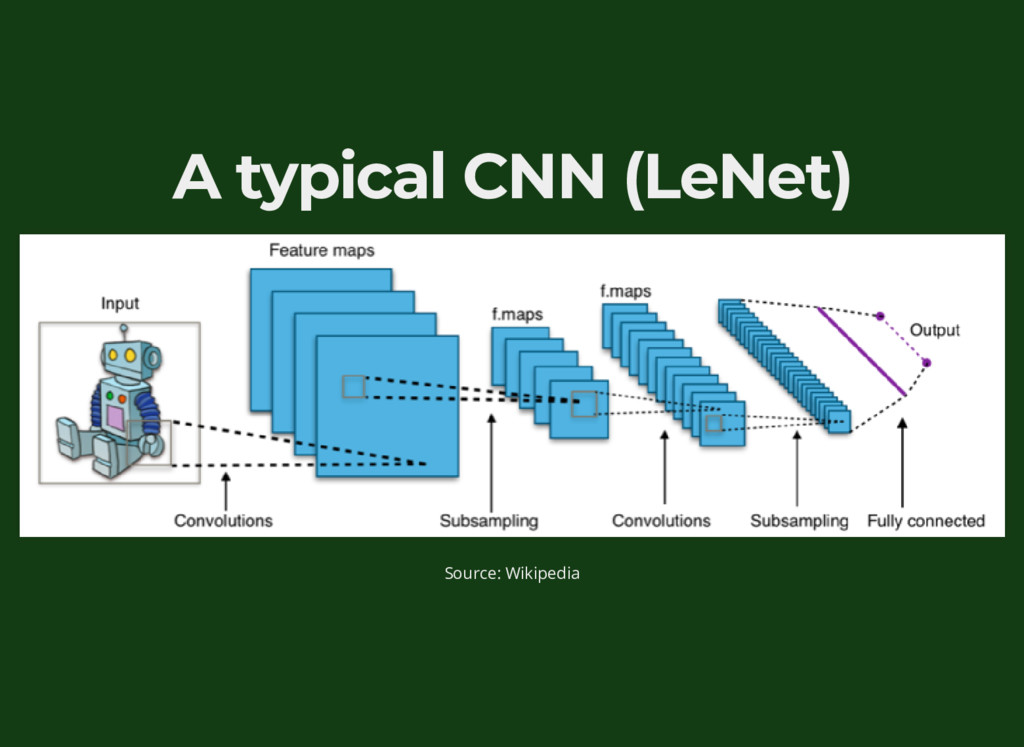{kind=link}
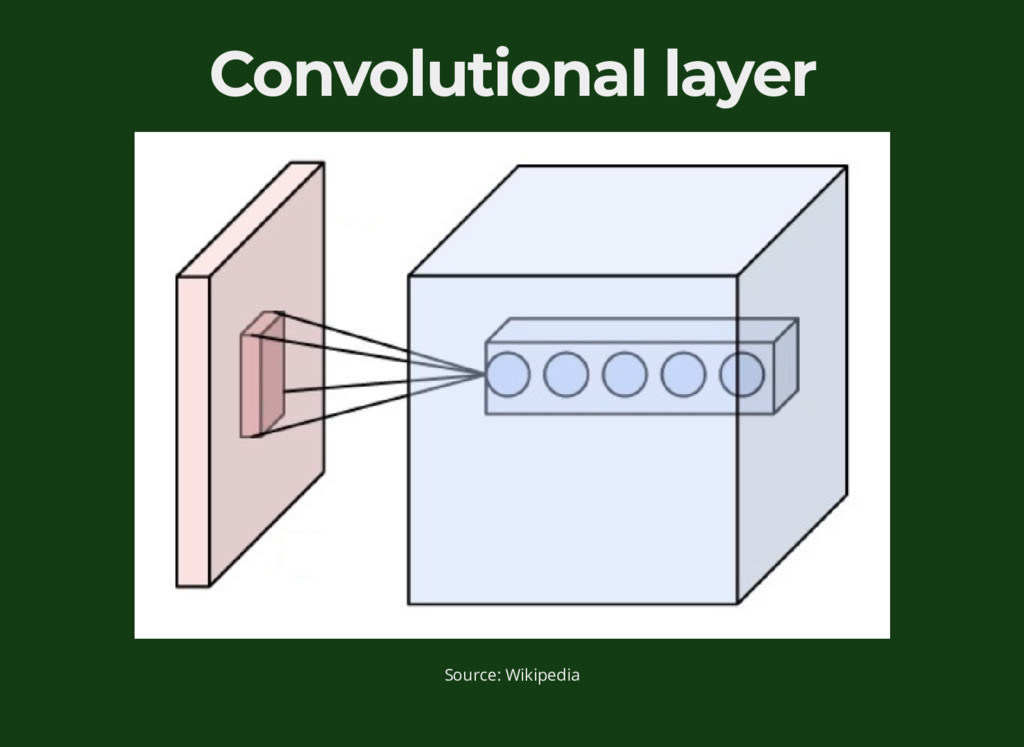{kind=link}
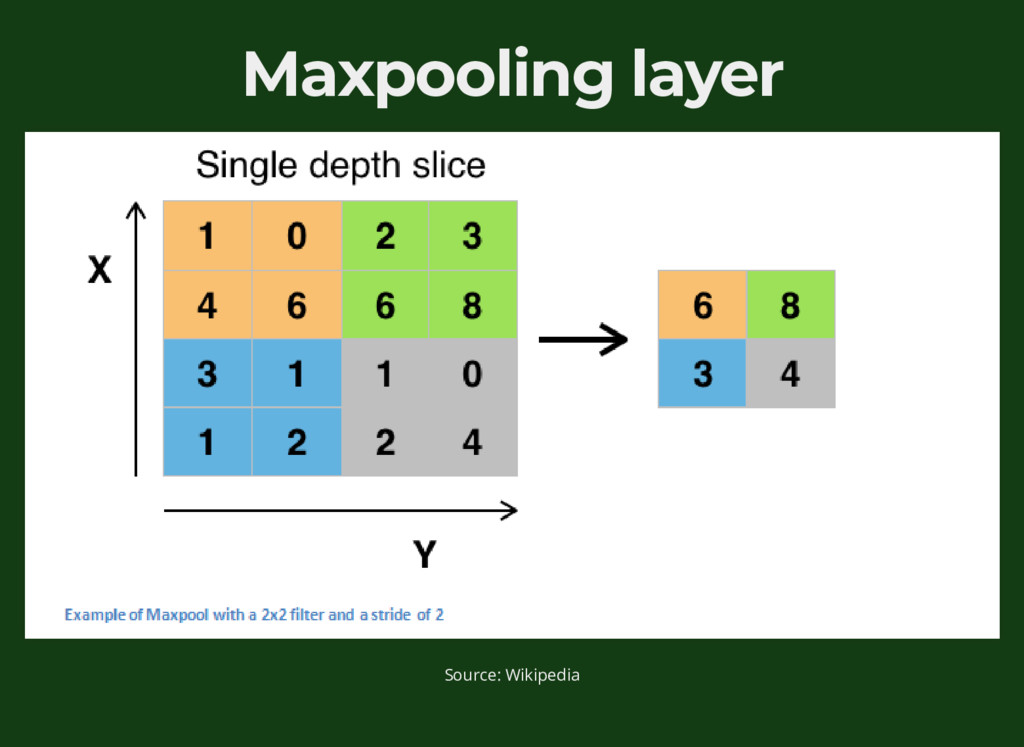{kind=link}
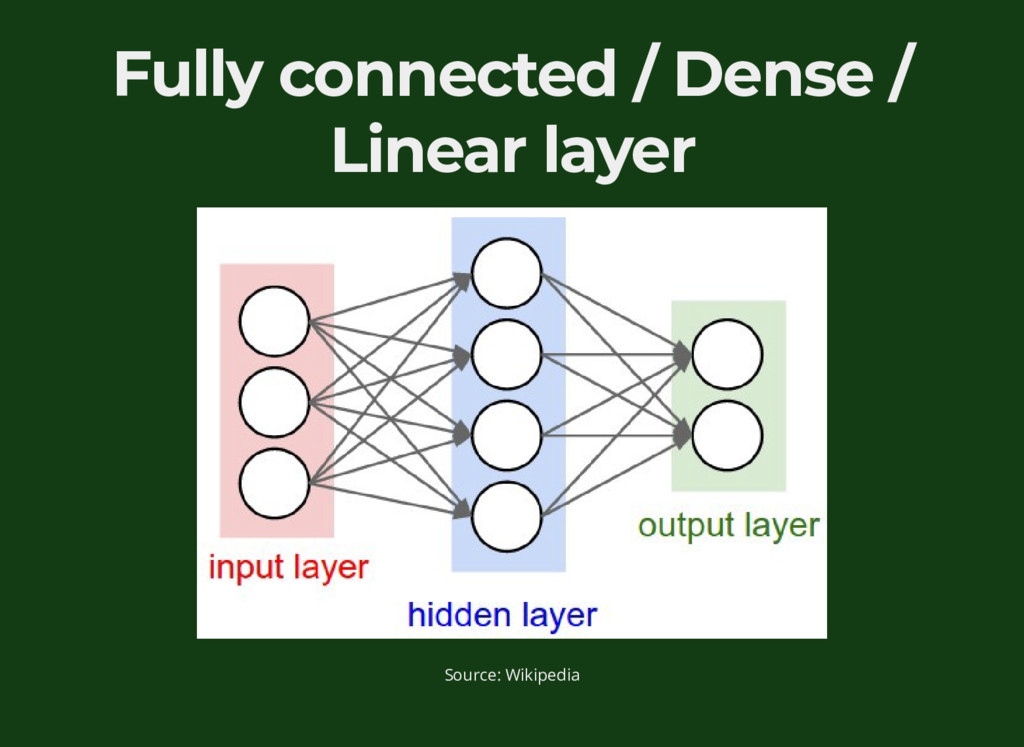{kind=link}
{kind=link}
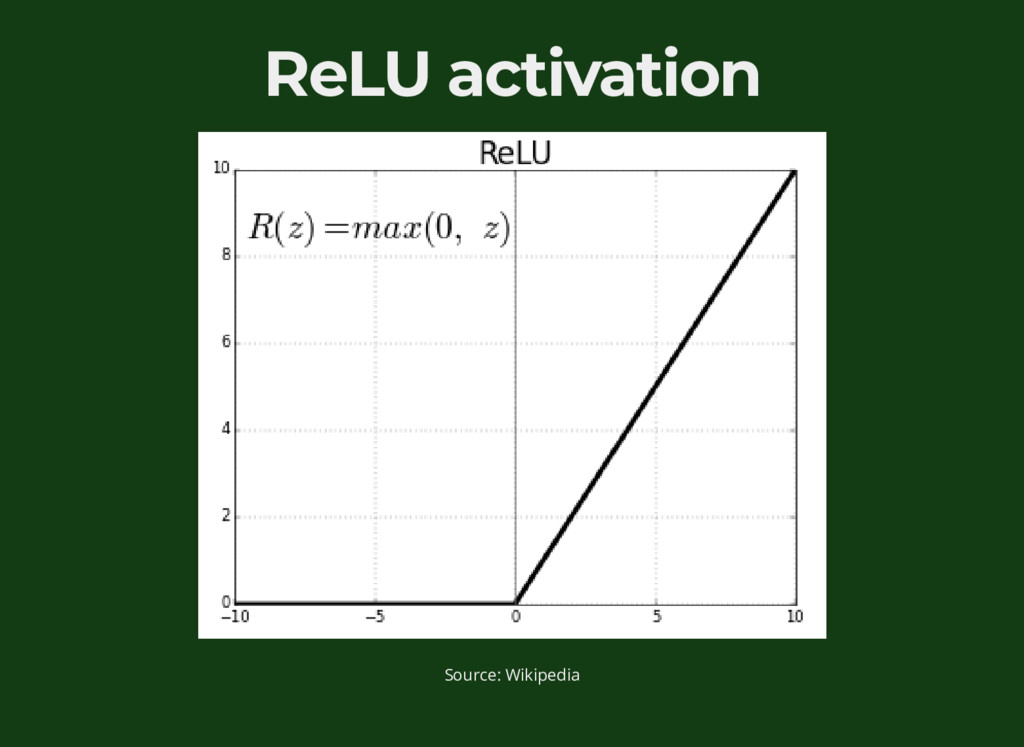{kind=link}
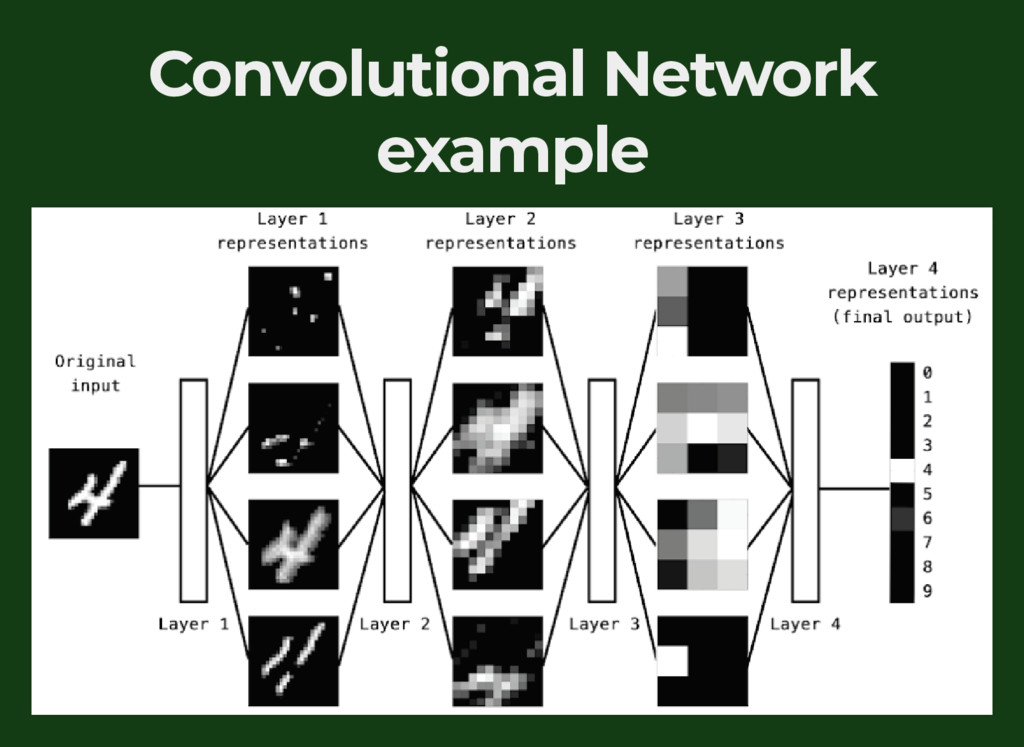{kind=link}
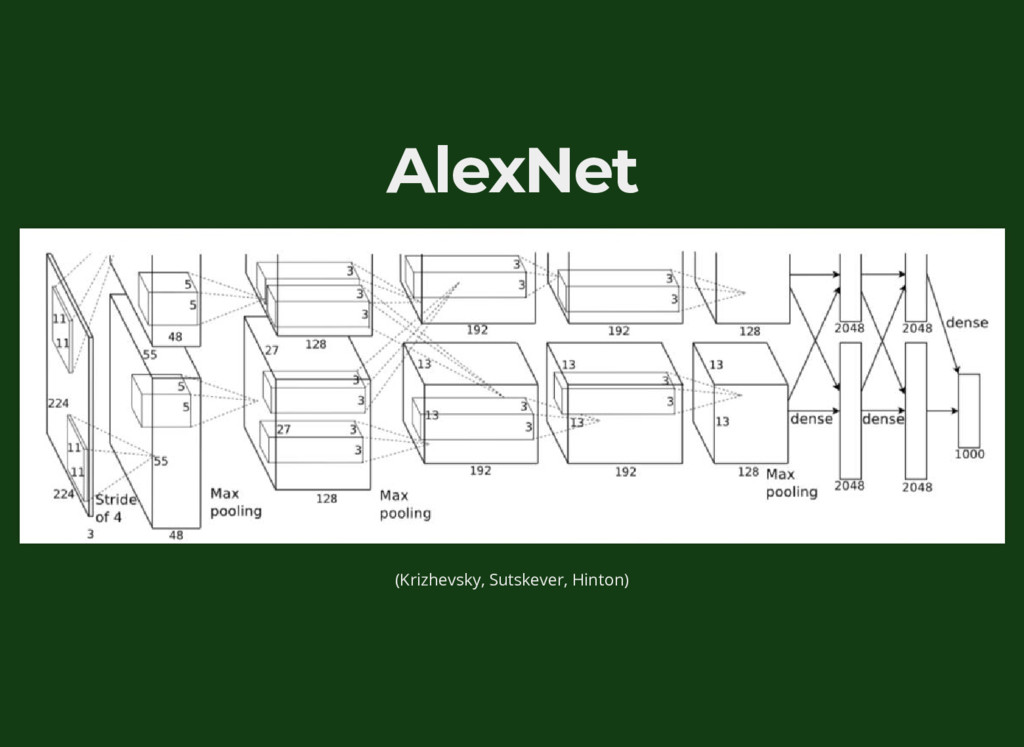{kind=link}
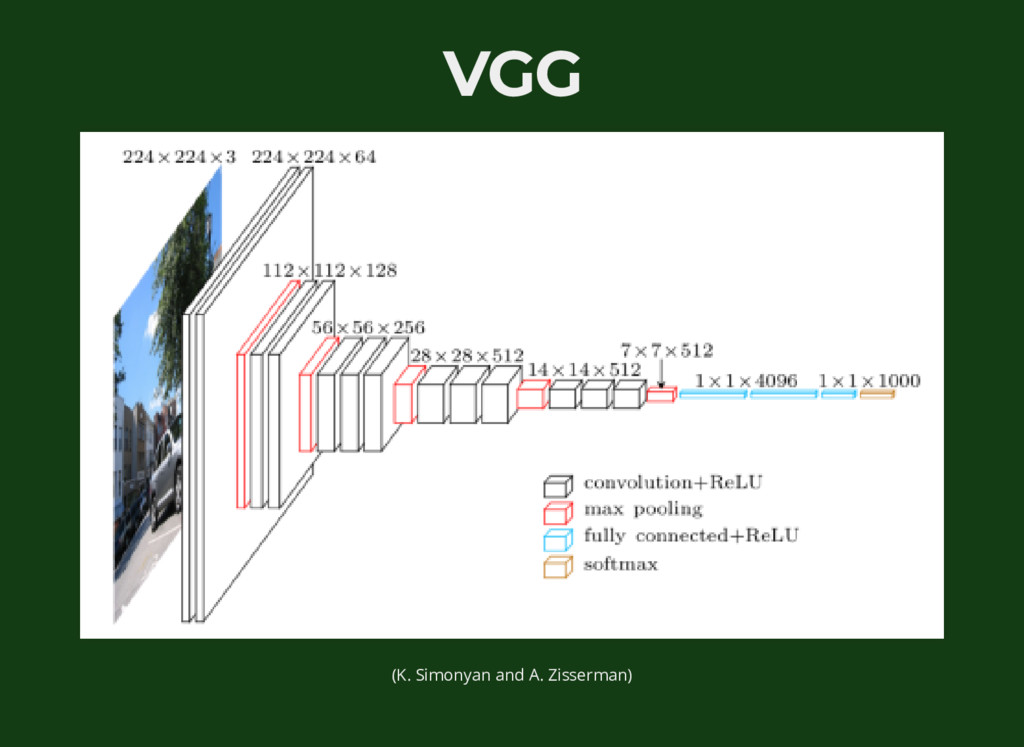{kind=link}
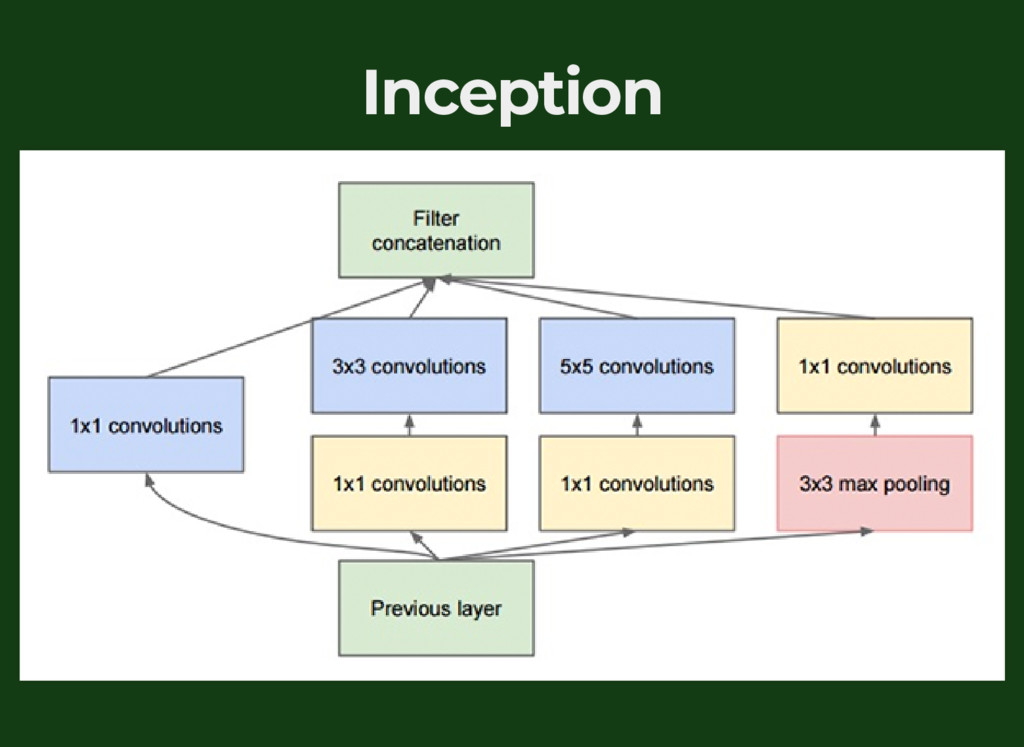{kind=link}
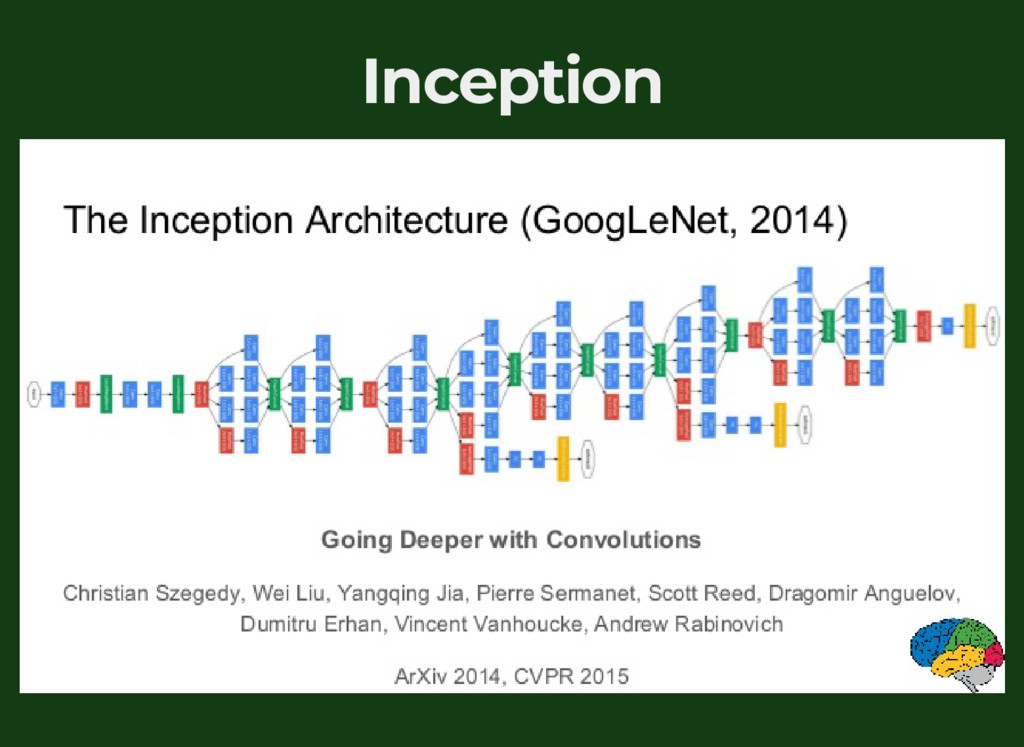{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
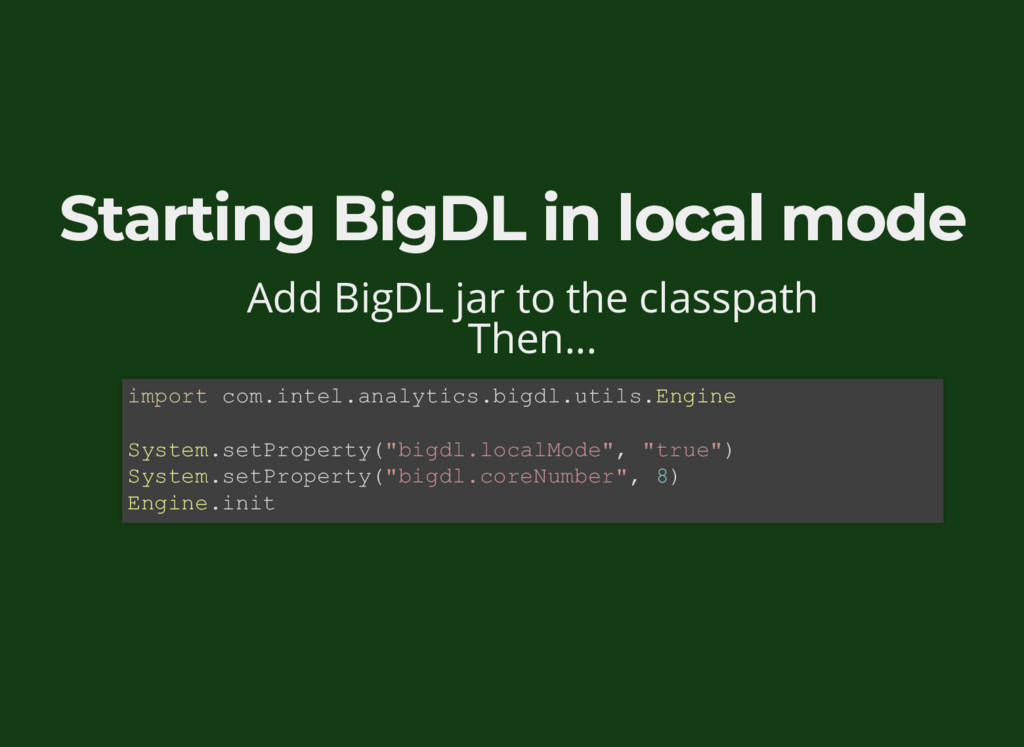{kind=link}
{kind=link}
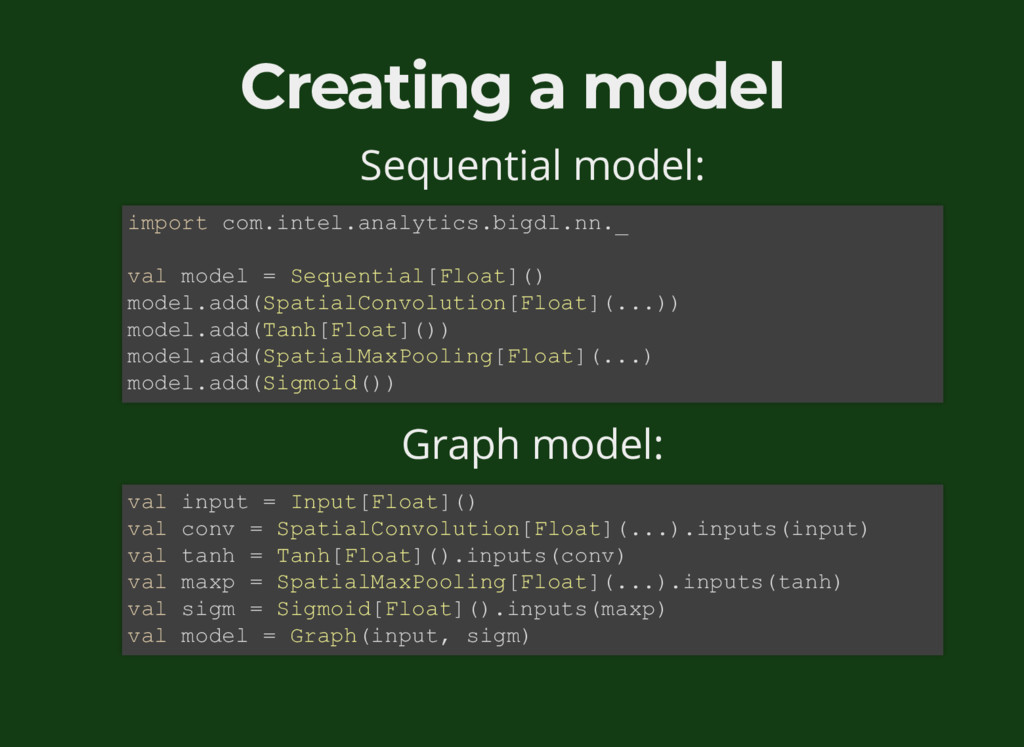{kind=link}
{kind=link}
![Example model val model = Sequential[Float]() model.add(SpatialConvolution[Float](3, 32, 3, 3,](https://files.speakerdeck.com/presentations/efc2d353ffb44b87b5e0c8b08c453ce4/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Preparing the data val bytes:RDD[Sample[Float]] = sc.binaryFiles(folder). map(pathbytes => {](https://files.speakerdeck.com/presentations/efc2d353ffb44b87b5e0c8b08c453ce4/slide_40.jpg){kind=link}
![Create an optimizer val optimizer = Optimizer(module, trainRdd, BCECriterion[Float](), batchSize)](https://files.speakerdeck.com/presentations/efc2d353ffb44b87b5e0c8b08c453ce4/slide_41.jpg){kind=link}
{kind=link}
![Optimization running [Epoch 2 18432/20000][Iteration 2 67][Wall Clock 888.091331139s] Trained](https://files.speakerdeck.com/presentations/efc2d353ffb44b87b5e0c8b08c453ce4/slide_43.jpg){kind=link}
![Optimization running [Wall Clock 857.896149222s] Validate model... Loss is (Loss:](https://files.speakerdeck.com/presentations/efc2d353ffb44b87b5e0c8b08c453ce4/slide_44.jpg){kind=link}
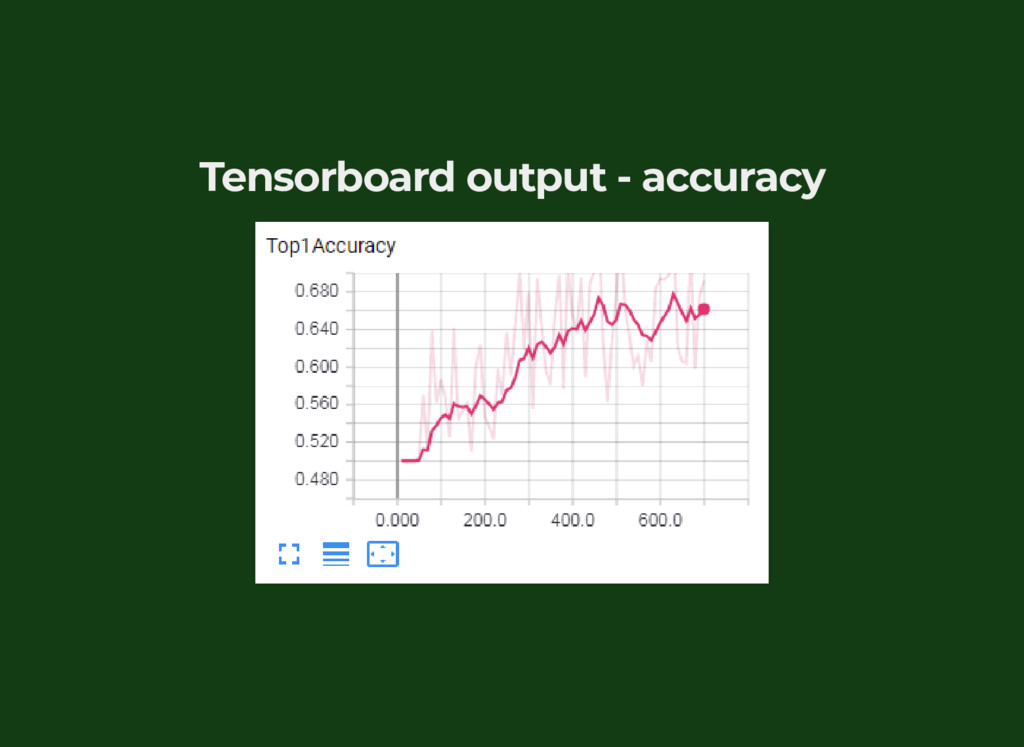{kind=link}
{kind=link}
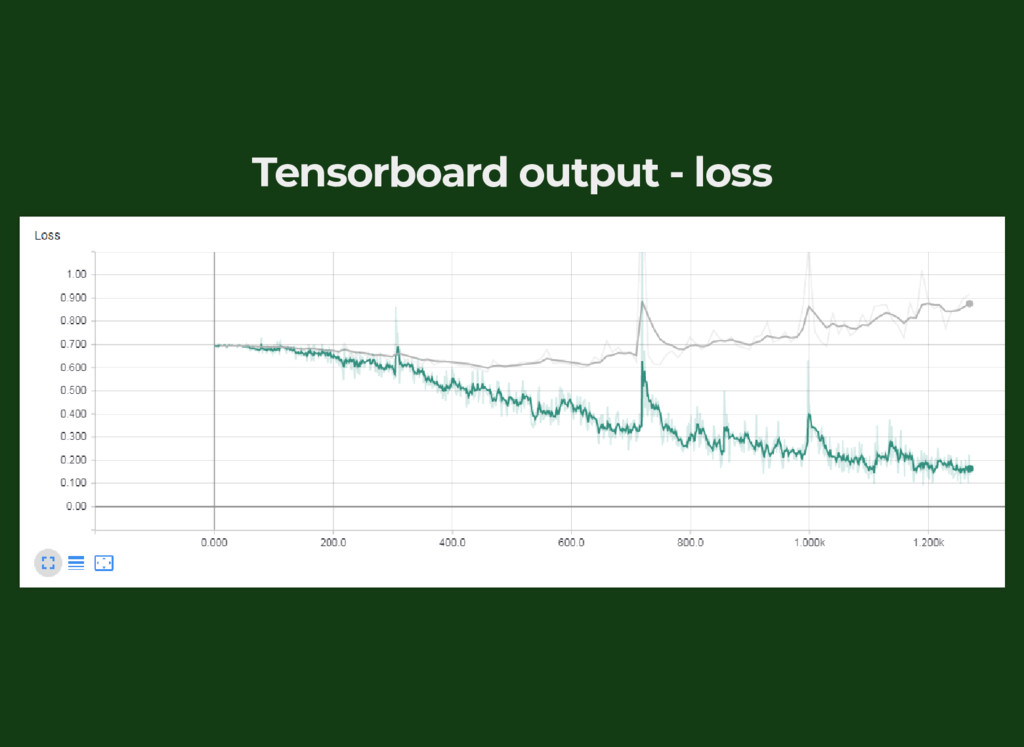{kind=link}
{kind=link}
{kind=link}
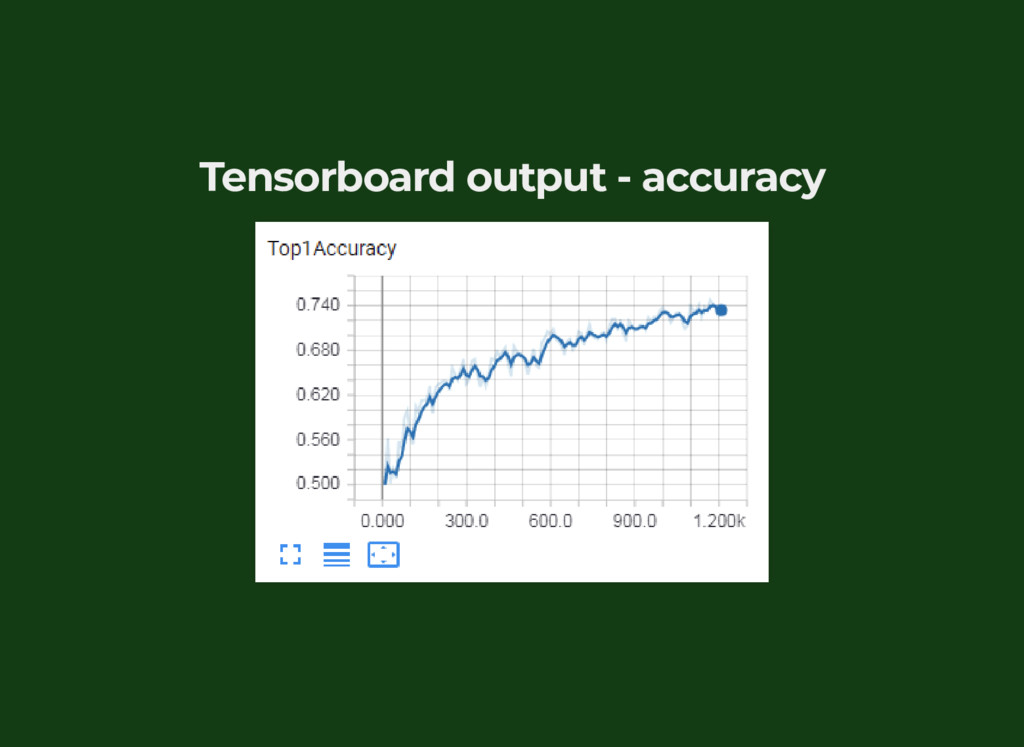{kind=link}
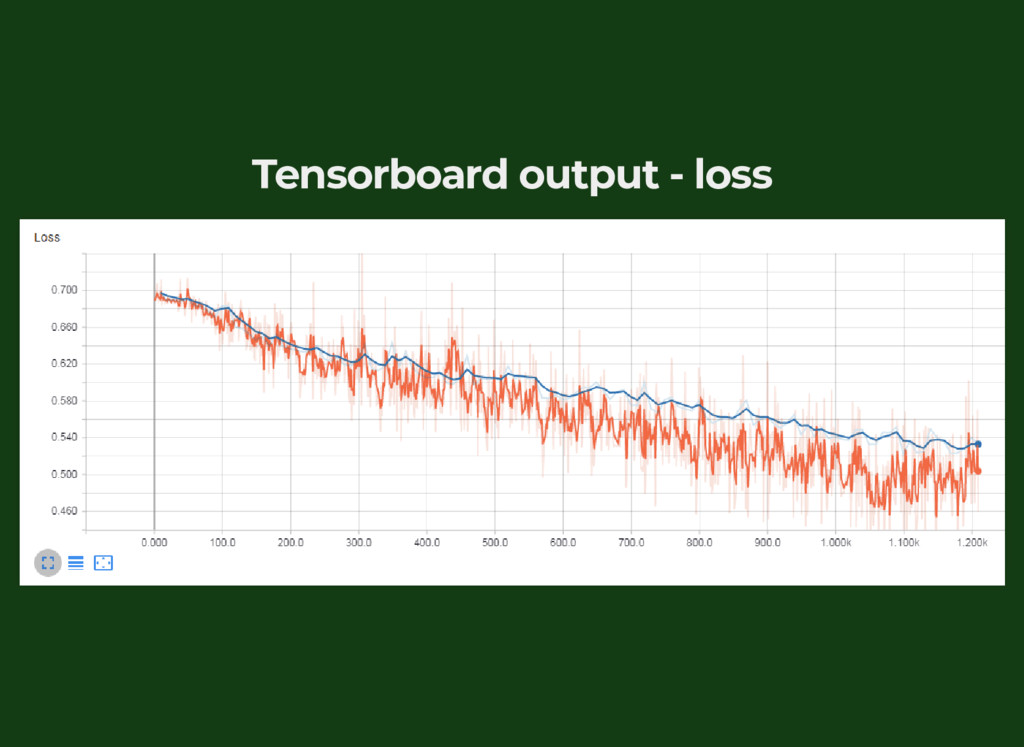{kind=link}
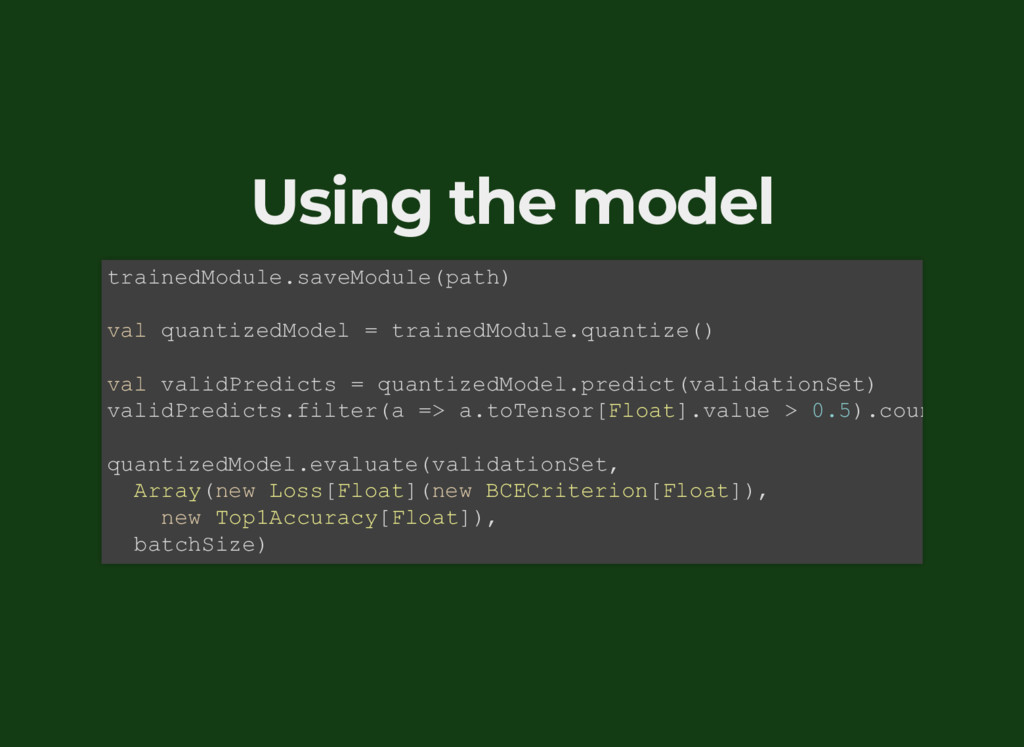{kind=link}
{kind=link}
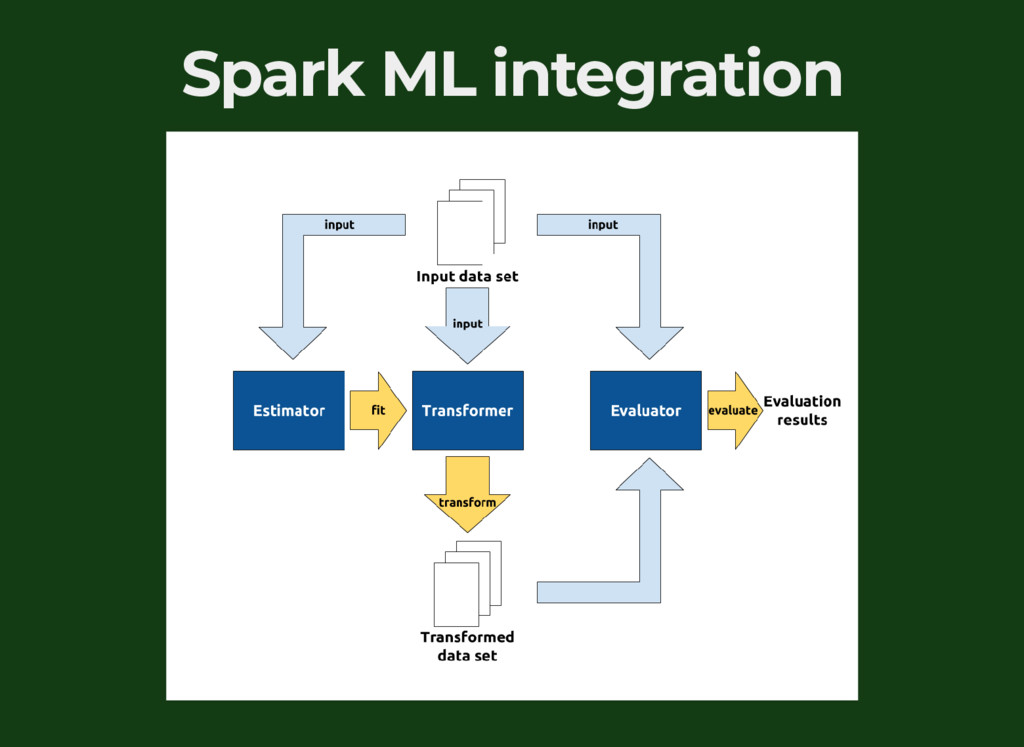{kind=link}
{kind=link}
![Spark ML integration val criterion = BCECriterion[Float]() val featureSize =](https://files.speakerdeck.com/presentations/efc2d353ffb44b87b5e0c8b08c453ce4/slide_56.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}