Agora owns dozens of themed, classified, entertainment and social services. There are news and sports portals, forums, advertising services, blogs and many other thematic websites. All sites generate over 400 page views per second (under normal conditions) and considerably more events (likes focus, clicks and scrolling events). It raises one question: how to build user profiles real-time in such a dynamic and changing environment?
Session presented at Big Data Spain 2015 Conference
15th Oct 2015
Kinépolis Madrid
http://www.bigdataspain.org
Event promoted by: http://www.paradigmatecnologico.com
Abstract: http://www.bigdataspain.org/program/thu/slot-16.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
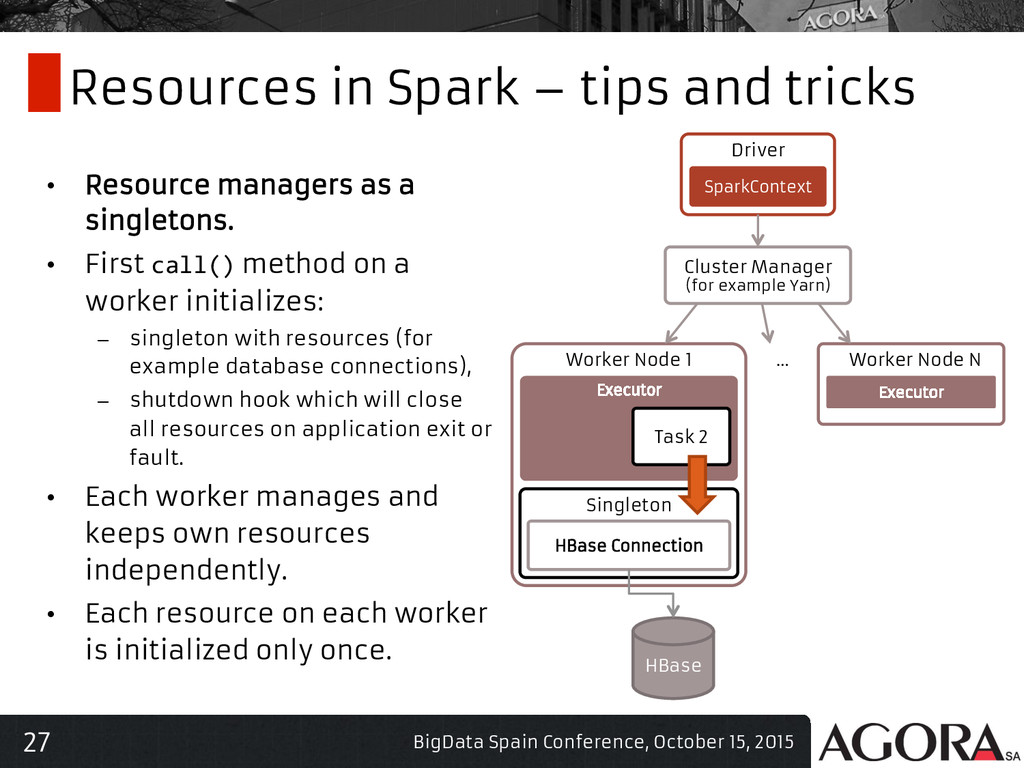{kind=link}
{kind=link}
{kind=link}
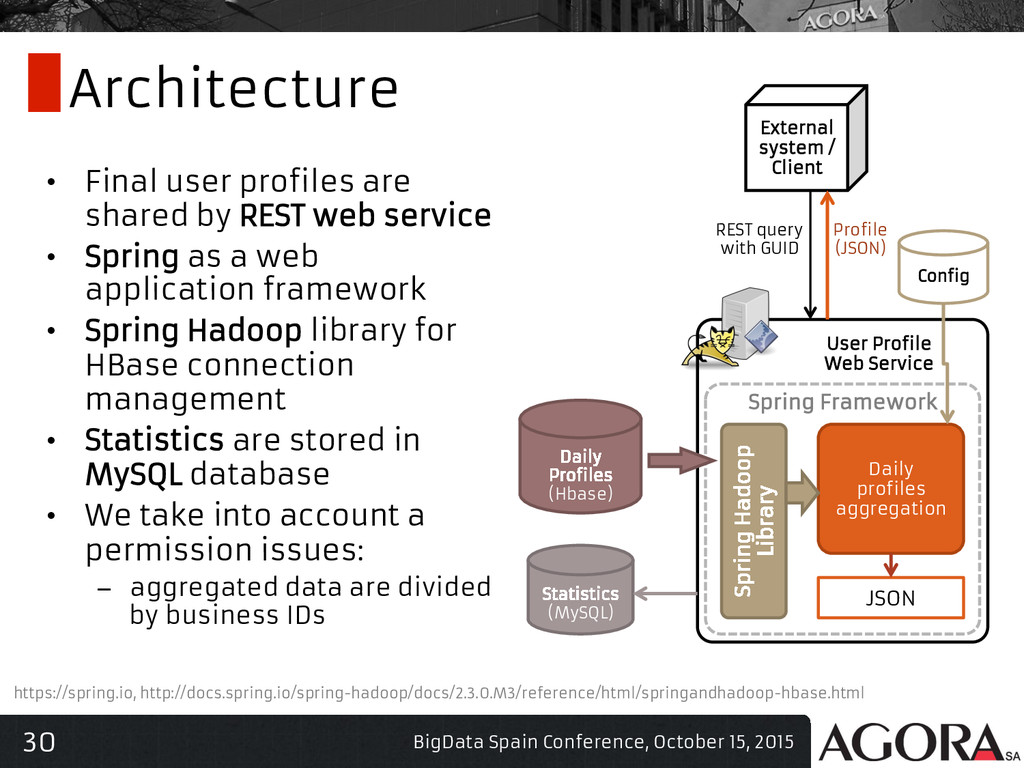{kind=link}
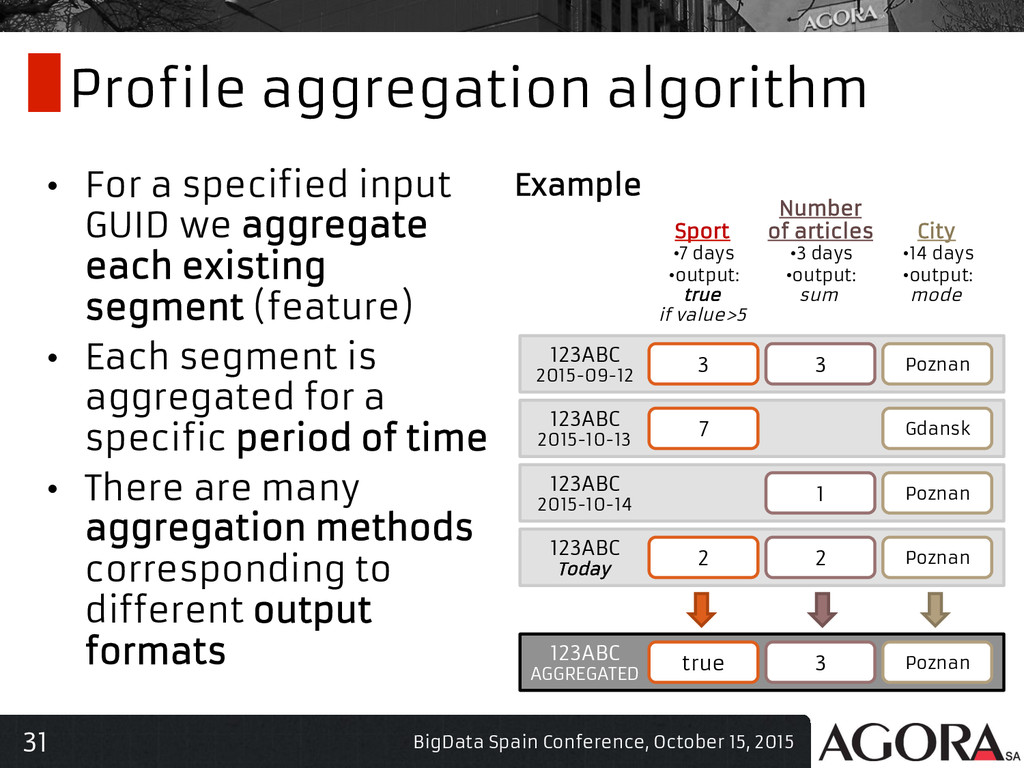{kind=link}
{kind=link}
{kind=link}
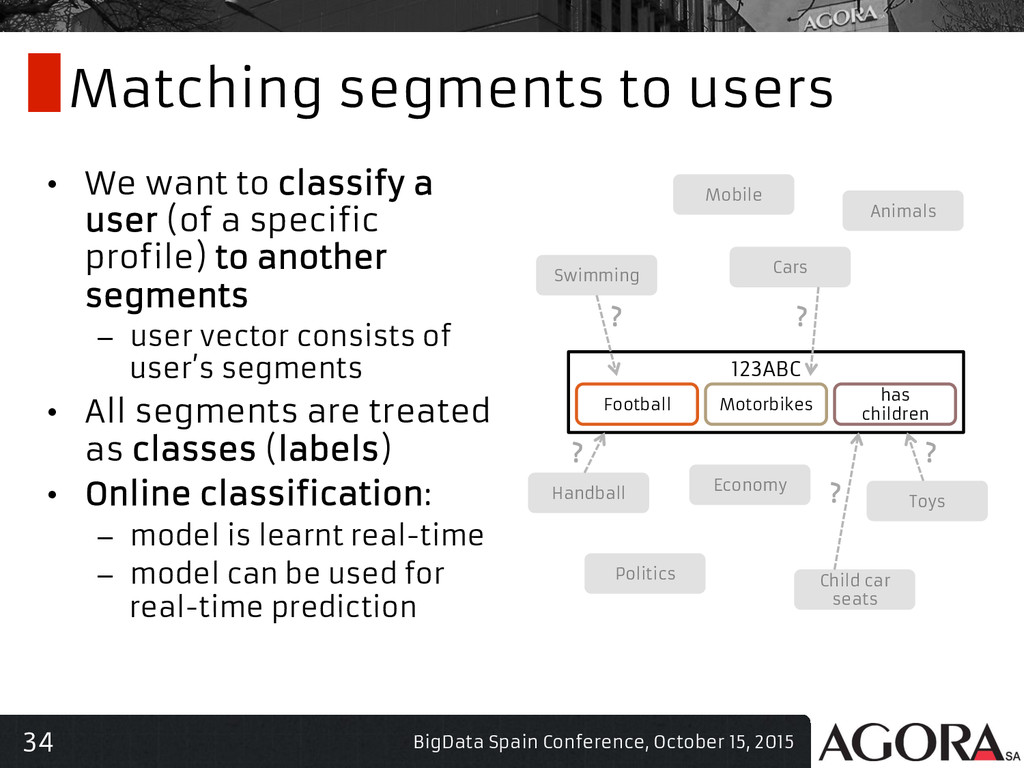{kind=link}
{kind=link}
{kind=link}
{kind=link}