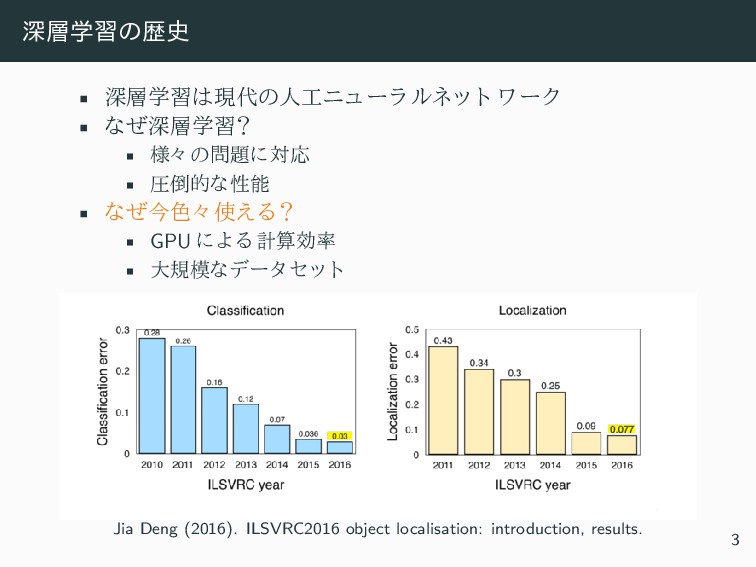
• 1998 LeNet • 2012 AlexNet • 2014 GoogleNet / VGG • 2016 AlphaGo • … Silver et al. “Mastering the game of Go with deep neural networks and tree search.” Nature, 2016. 3
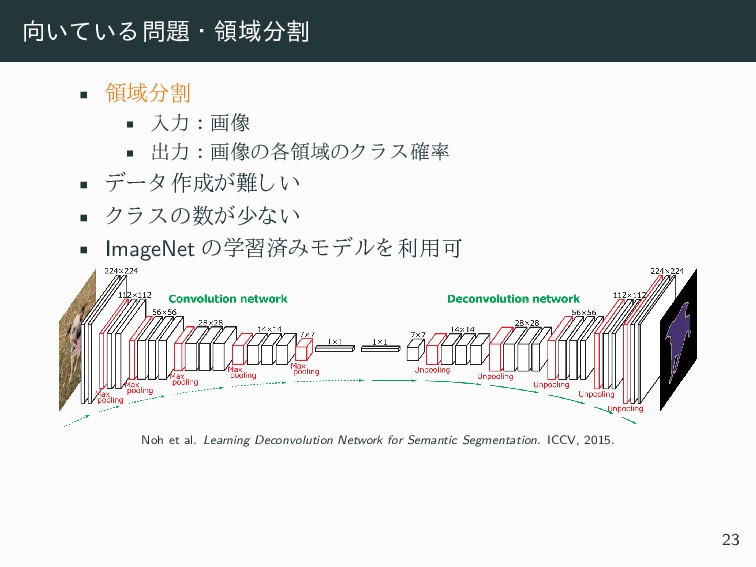
• 出力 : 画像の各領域のク ラ ス確率 • データ 作成が難し い • ク ラ スの数が少ない • ImageNet の学習済みモデルを 利用可 Chen et al. The Role of Context for Object Detection and Semantic Segmentation in the Wild. CVPR, 2014. 23
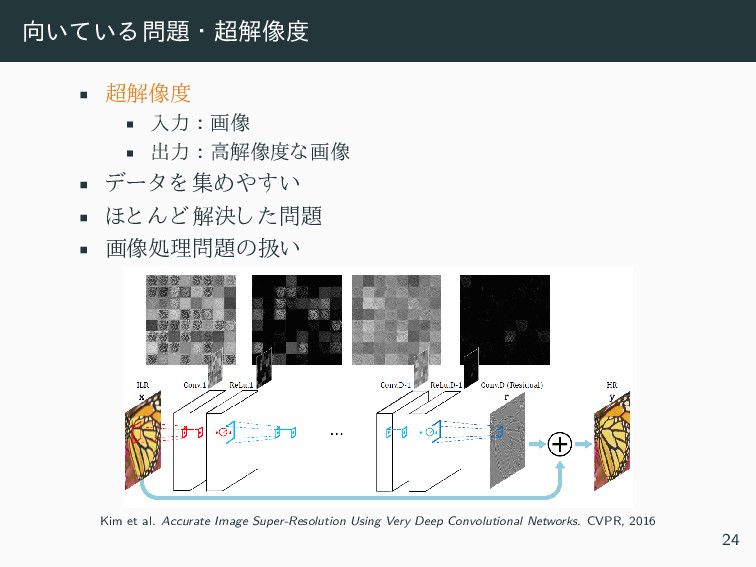
• 出力 : 高解像度な画像 • データ を 集めやすい • ほと んど解決し た問題 • 画像処理問題の扱い Kim et al. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. CVPR, 2016 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![汎化能力 Generalizing Training • Dropout [Srivastava et al. 2014] •](https://files.speakerdeck.com/presentations/238198b2e5e444b6902abd3362cdcafd/slide_72.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
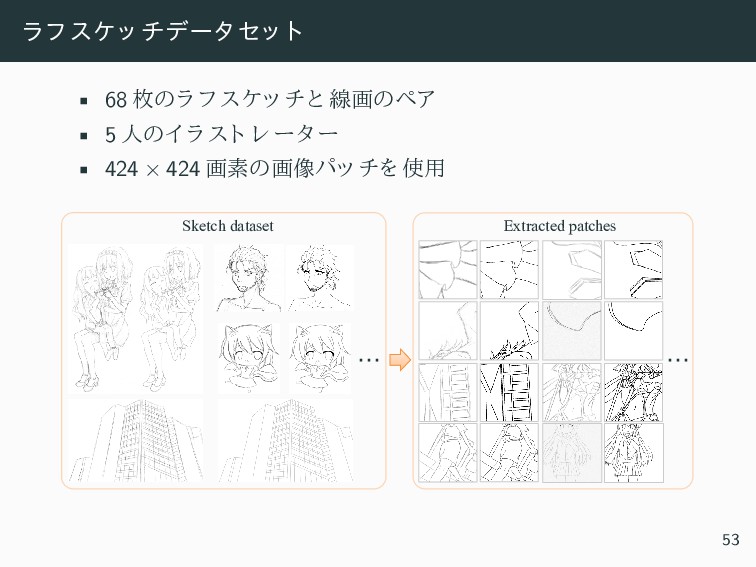{kind=link}
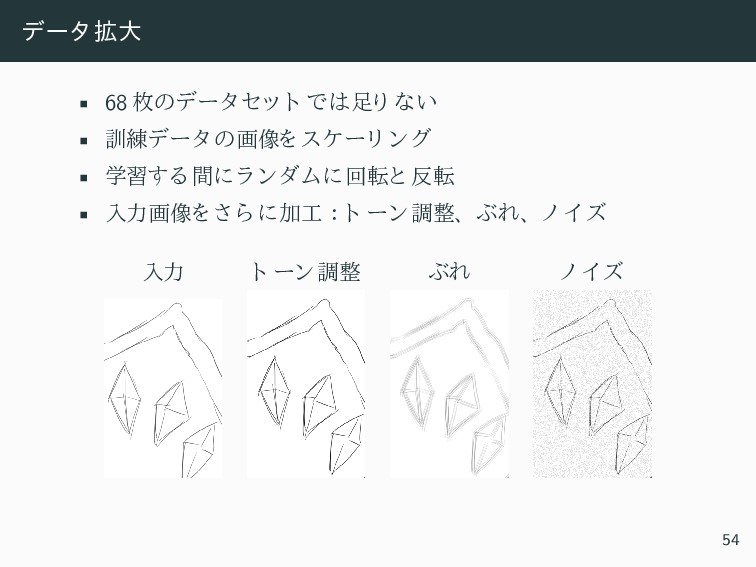{kind=link}
{kind=link}
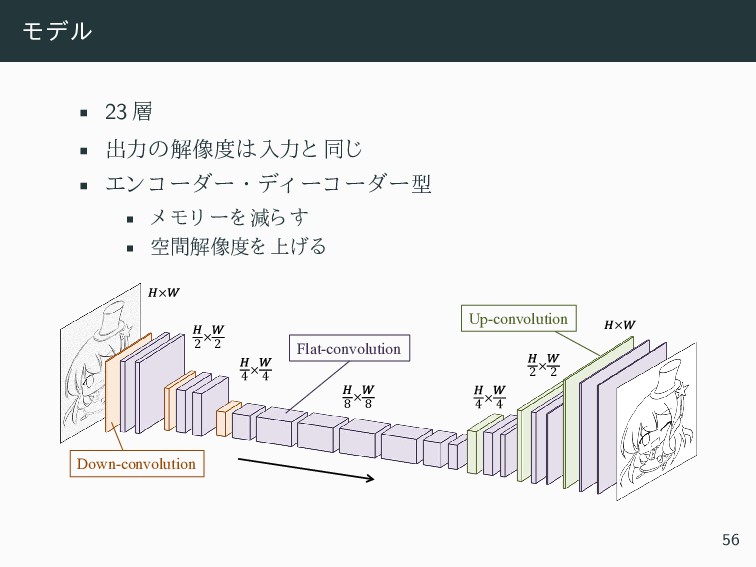{kind=link}
{kind=link}
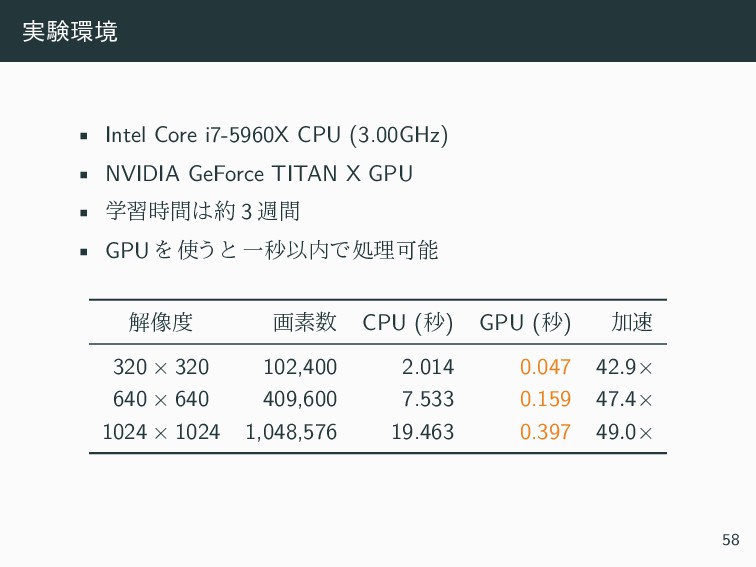{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![比較 入力画像 [Larsson+ ’16] [Zhang+ ’16] [Iizuka+ ’16] 68](https://files.speakerdeck.com/presentations/238198b2e5e444b6902abd3362cdcafd/slide_129.jpg){kind=link}
![比較 入力画像 [Larsson+ ’16] [Zhang+ ’16] [Iizuka+ ’16] 68](https://files.speakerdeck.com/presentations/238198b2e5e444b6902abd3362cdcafd/slide_130.jpg){kind=link}
![比較 入力画像 [Larsson+ ’16] [Zhang+ ’16] [Iizuka+ ’16] 68](https://files.speakerdeck.com/presentations/238198b2e5e444b6902abd3362cdcafd/slide_131.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}