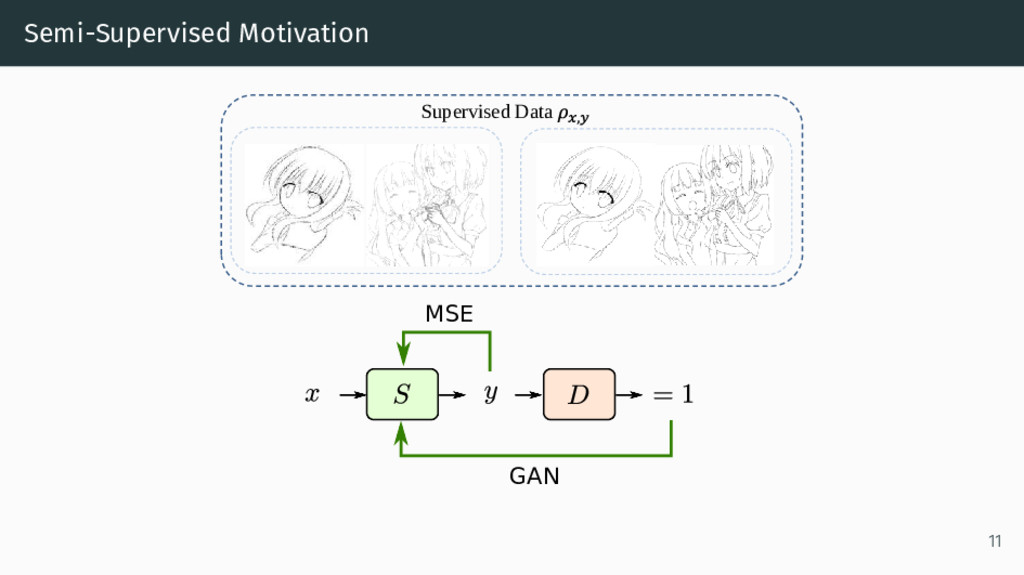
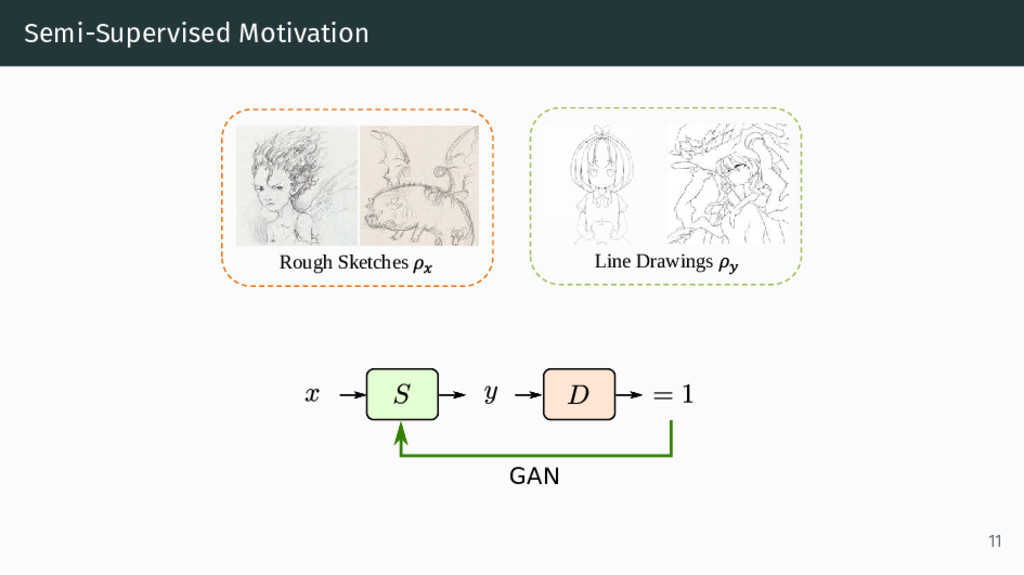
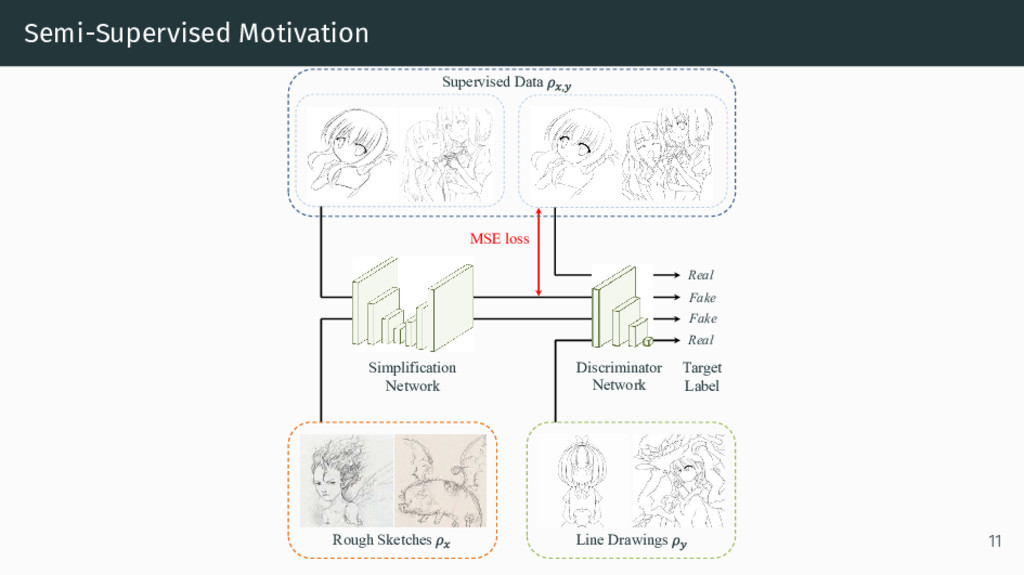
Model: D(·) • Supervised Training Data: ρx,y (rough sketch x, line drawing y∗) • Unsupervised data: ρy, ρx • Adversarial weighting hyperparameter: α • Unsupervised weighting hyperparameter: β min S max D E(x,y∗)∼ρx , y [ S(x) − y∗ 2 + α log D(y∗) + α log(1 − D(S(x))) ] + β Ey∼ρy [ log D(y) ] + β Ex∼ρx [ log(1 − D(S(x))) ] 9
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
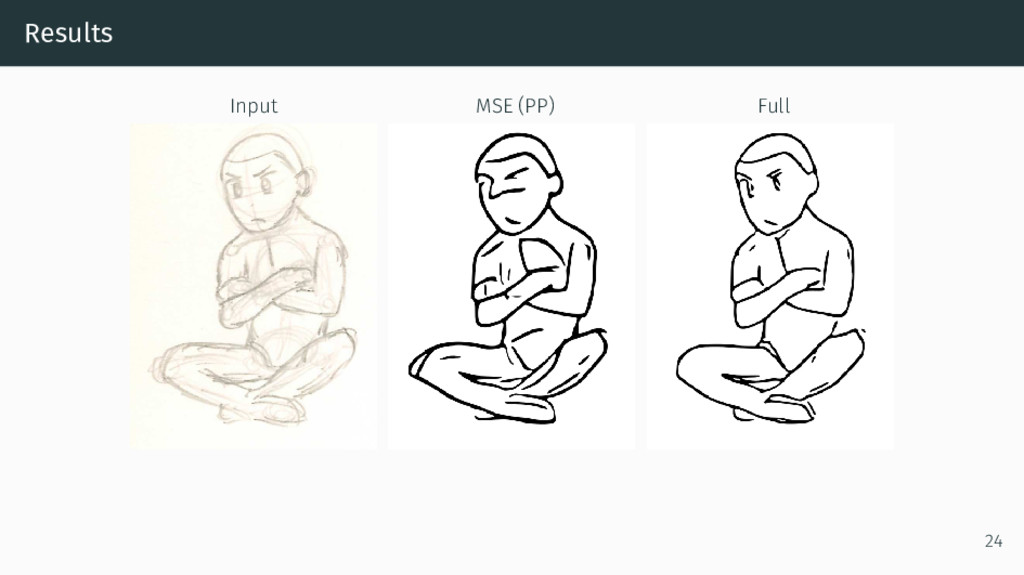{kind=link}
{kind=link}
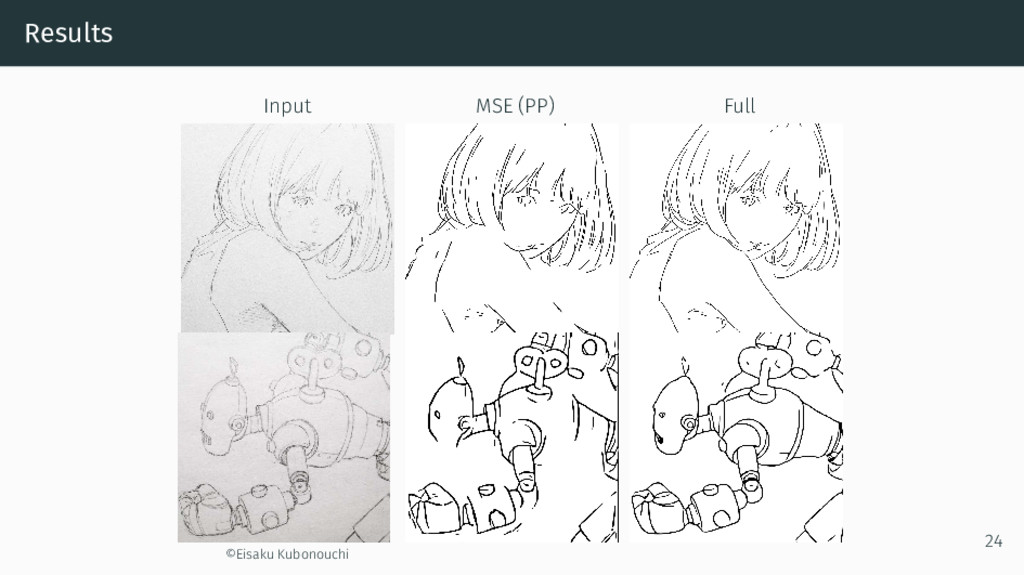{kind=link}
{kind=link}
{kind=link}
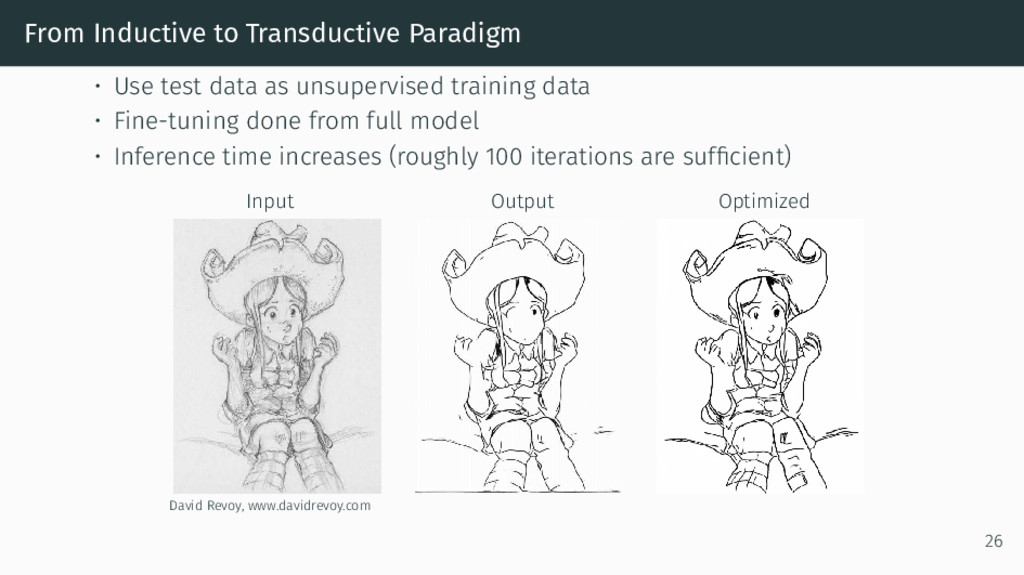{kind=link}
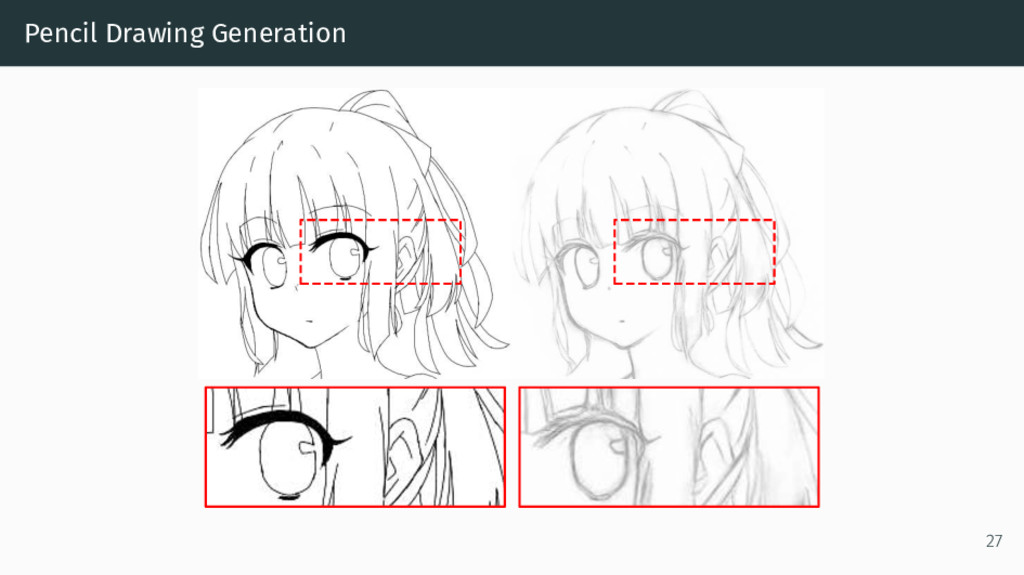{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}