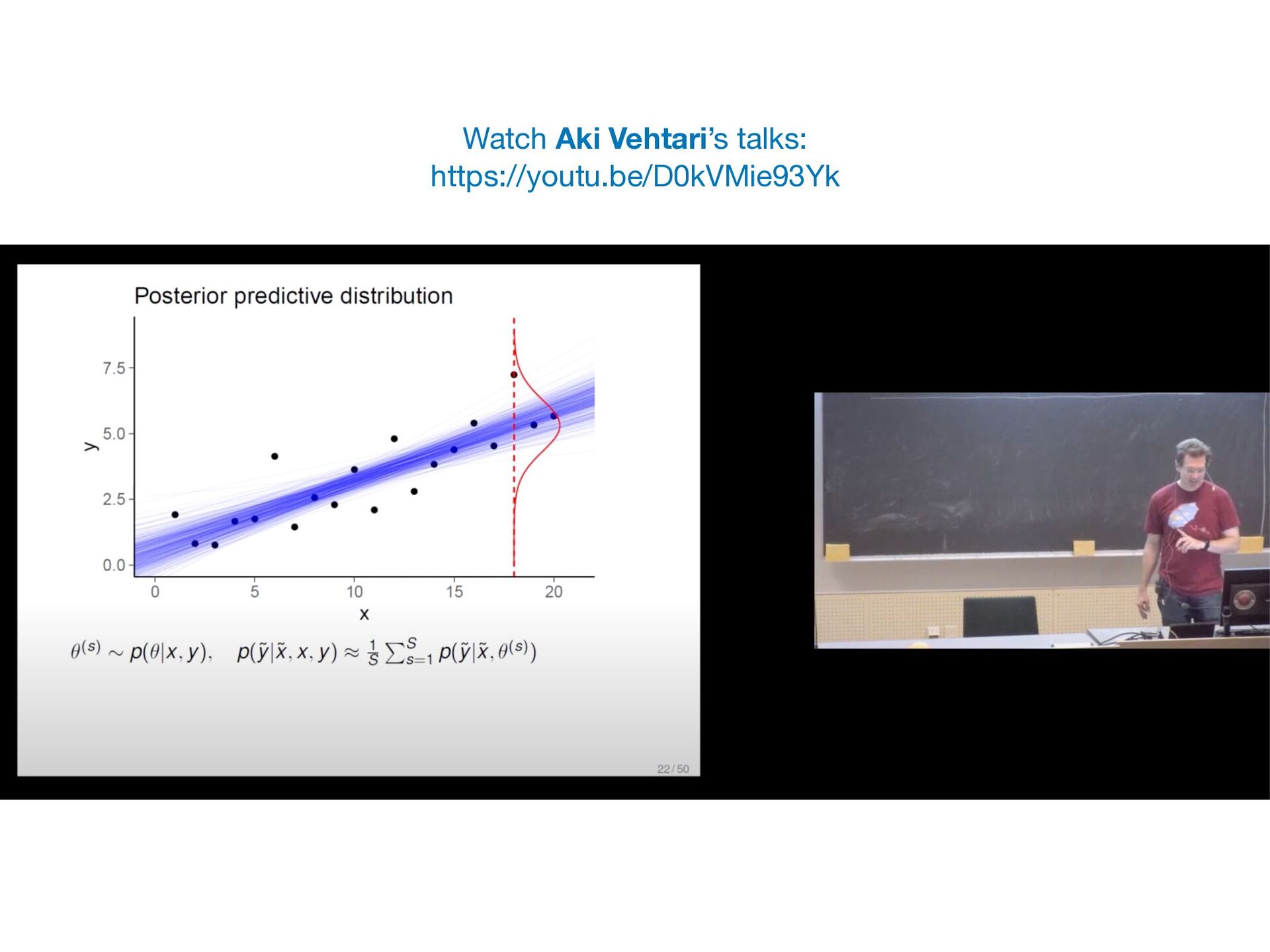
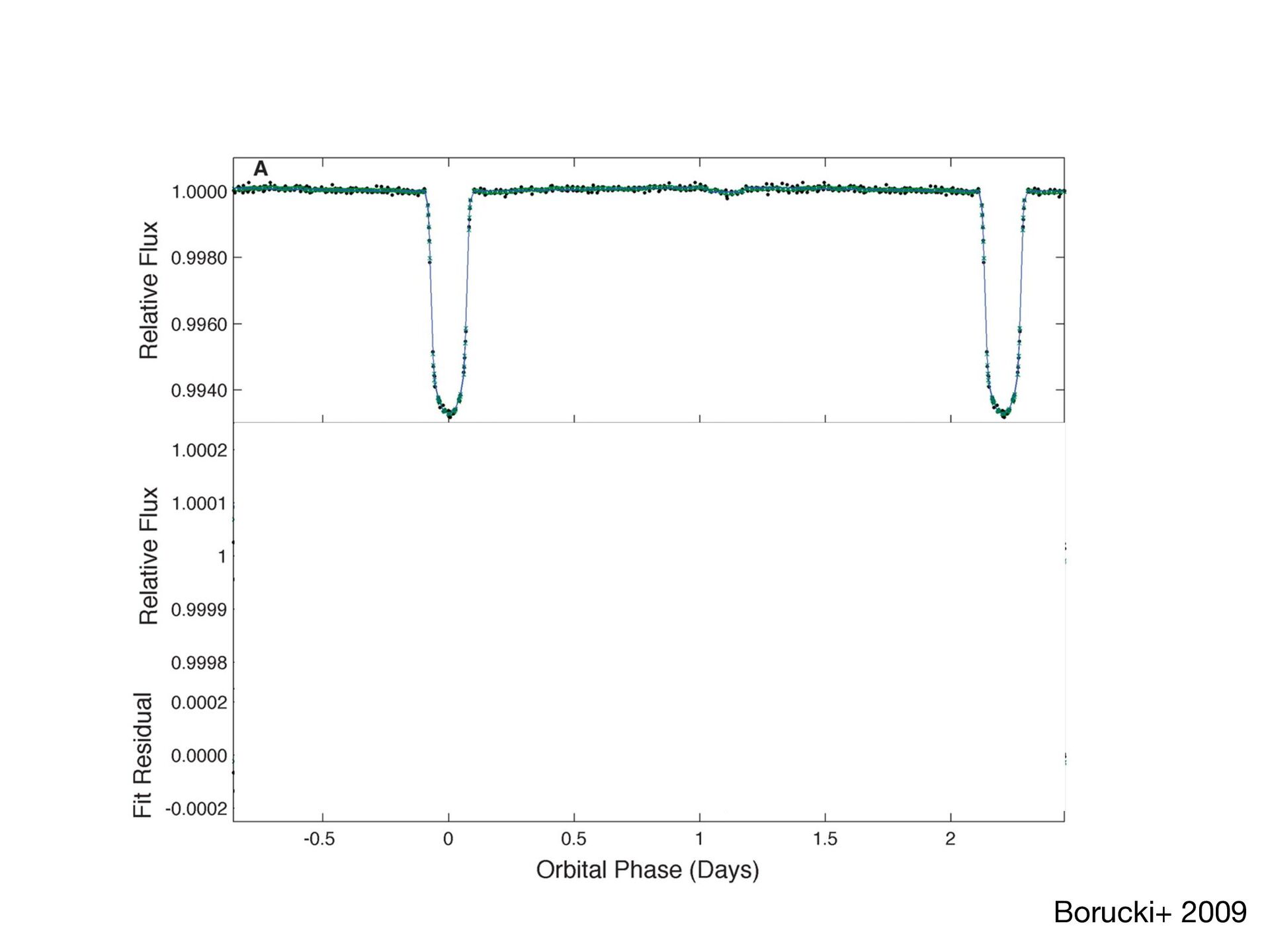
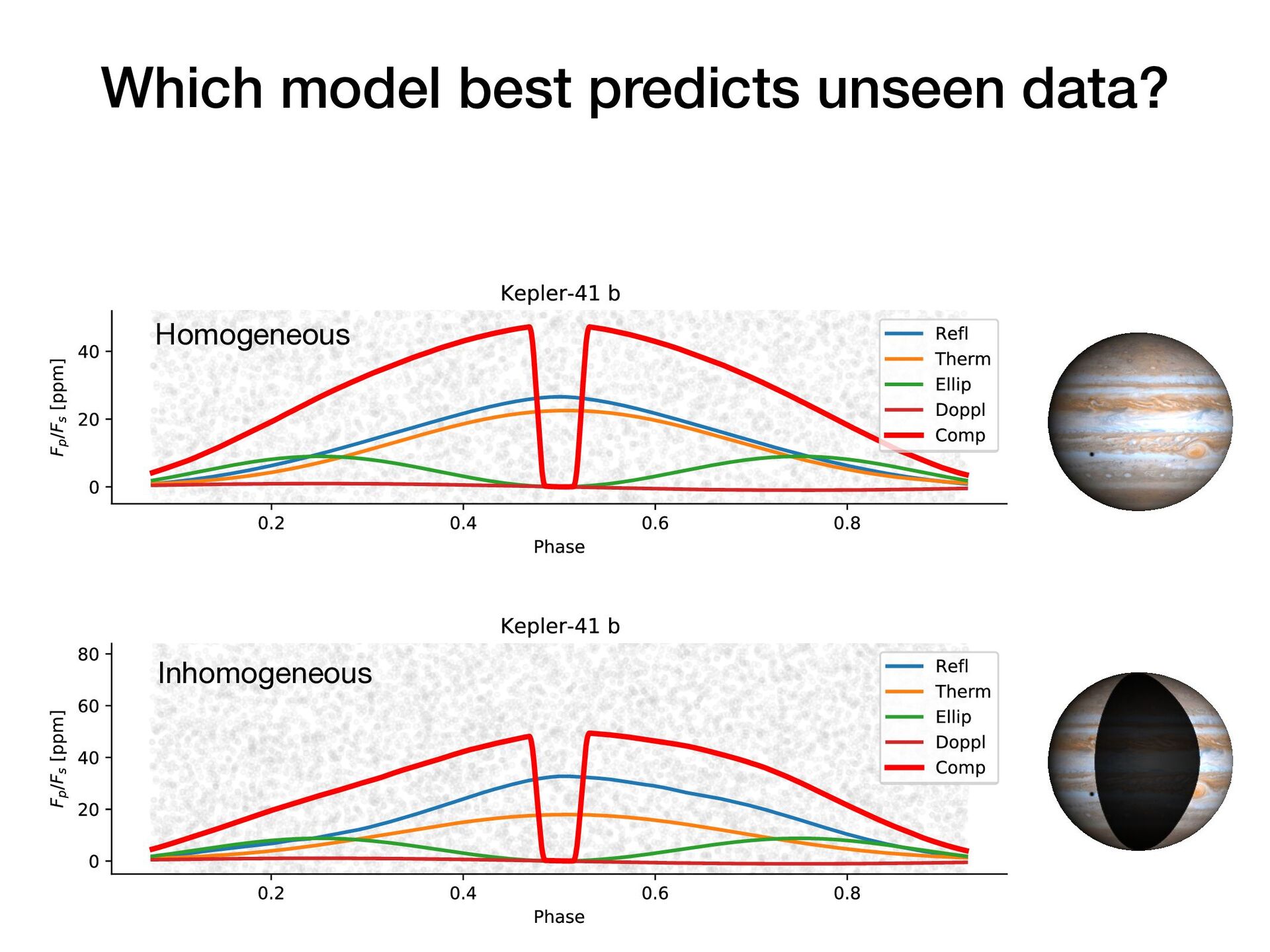
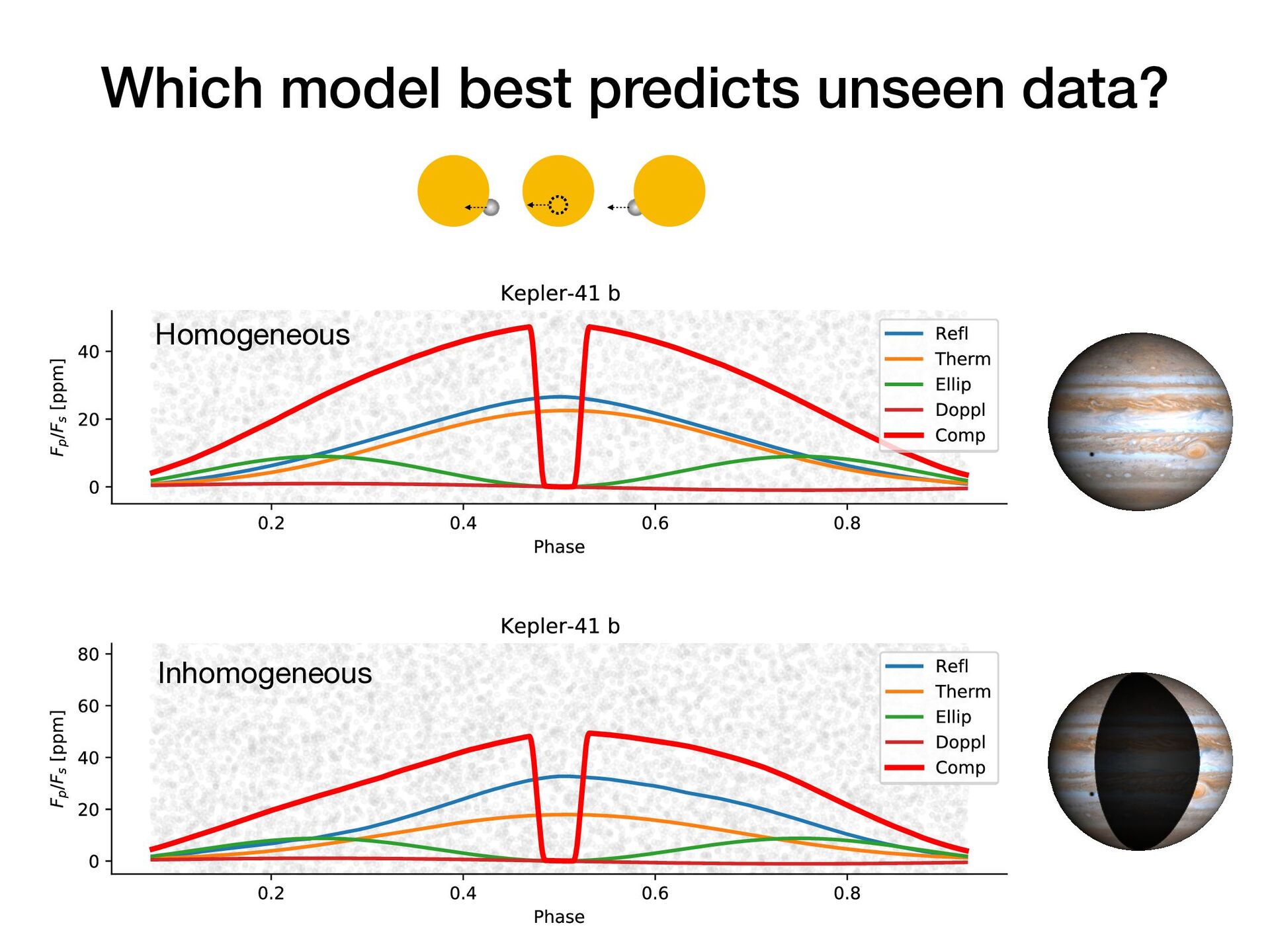
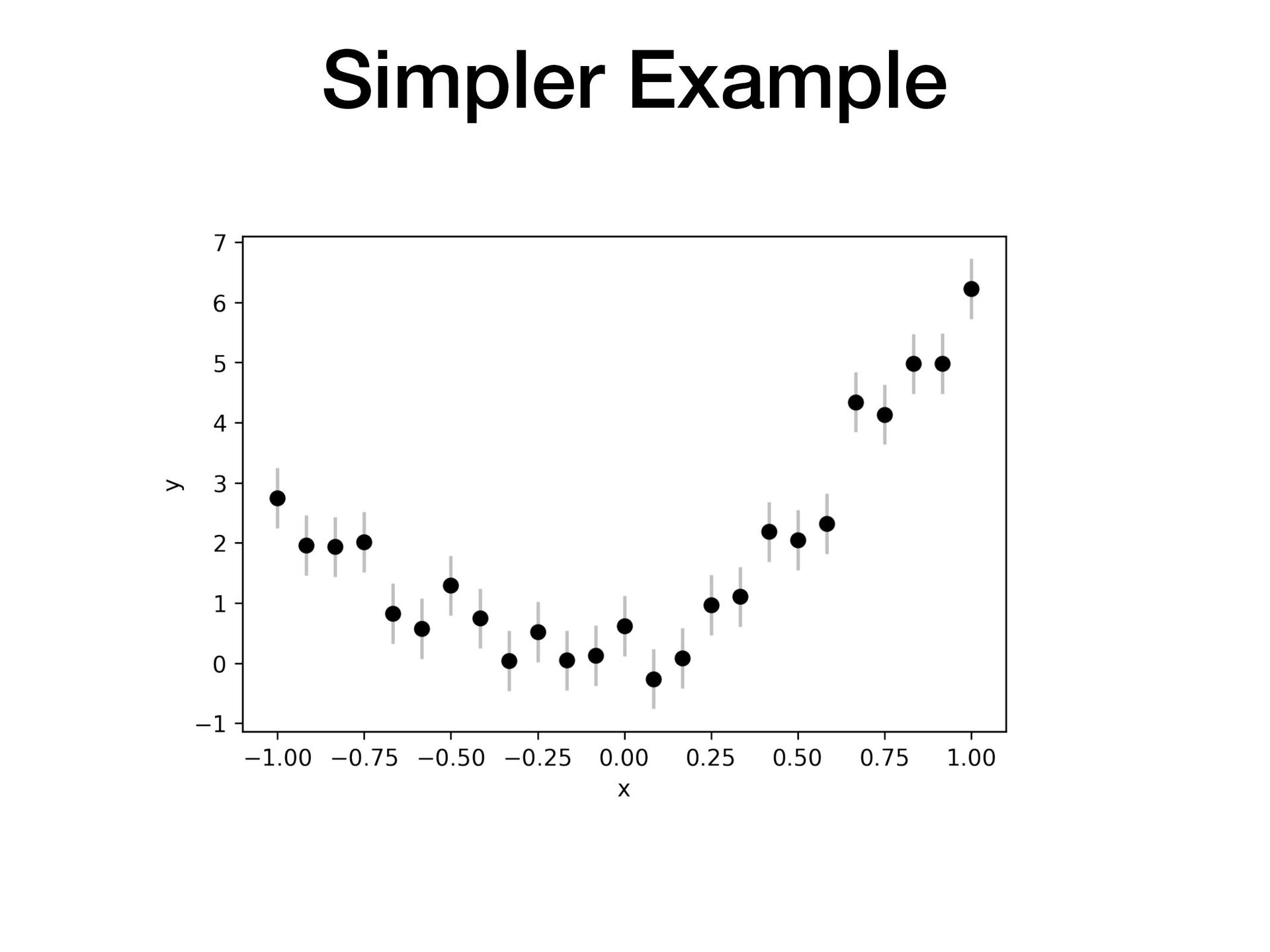
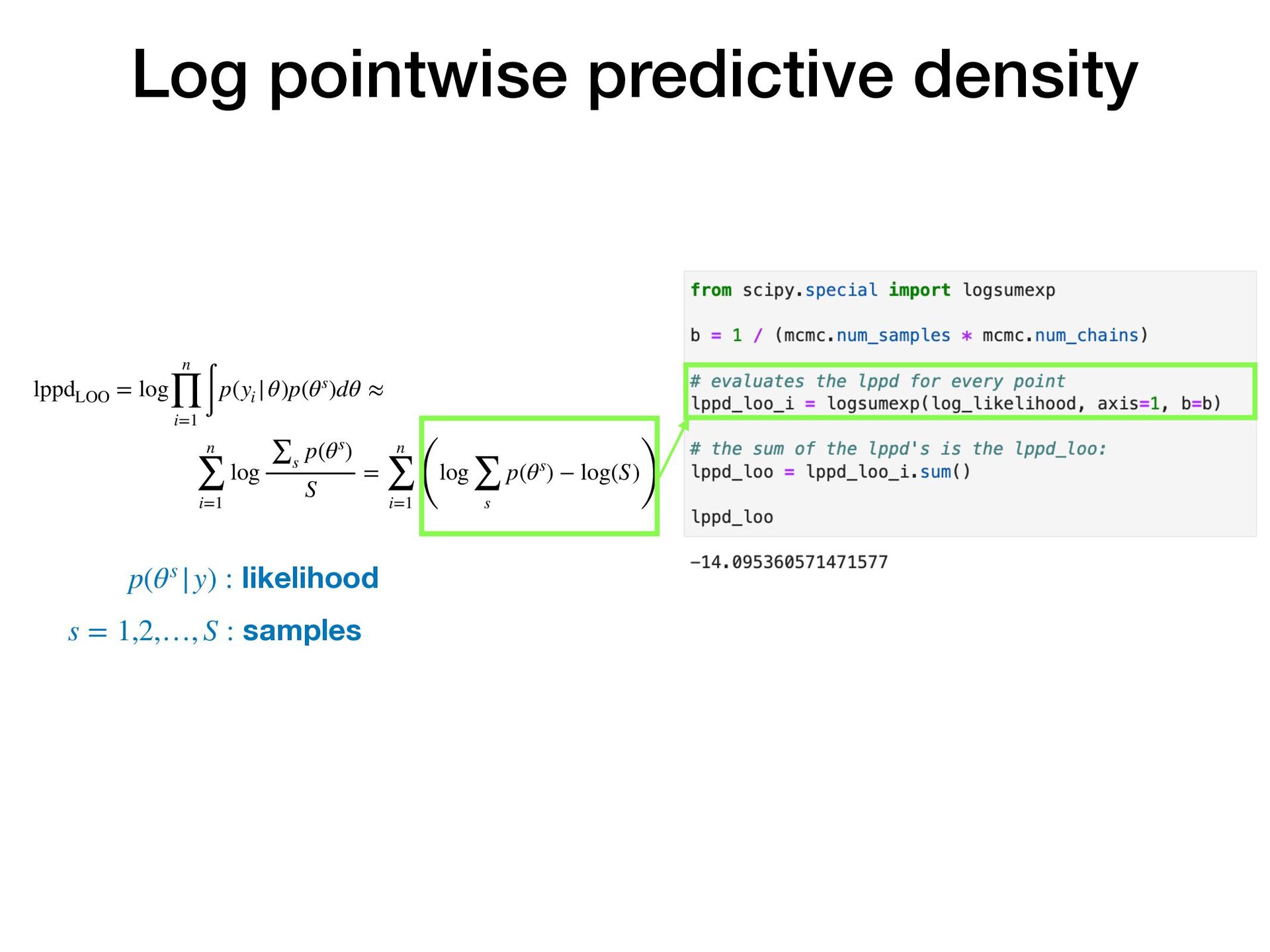
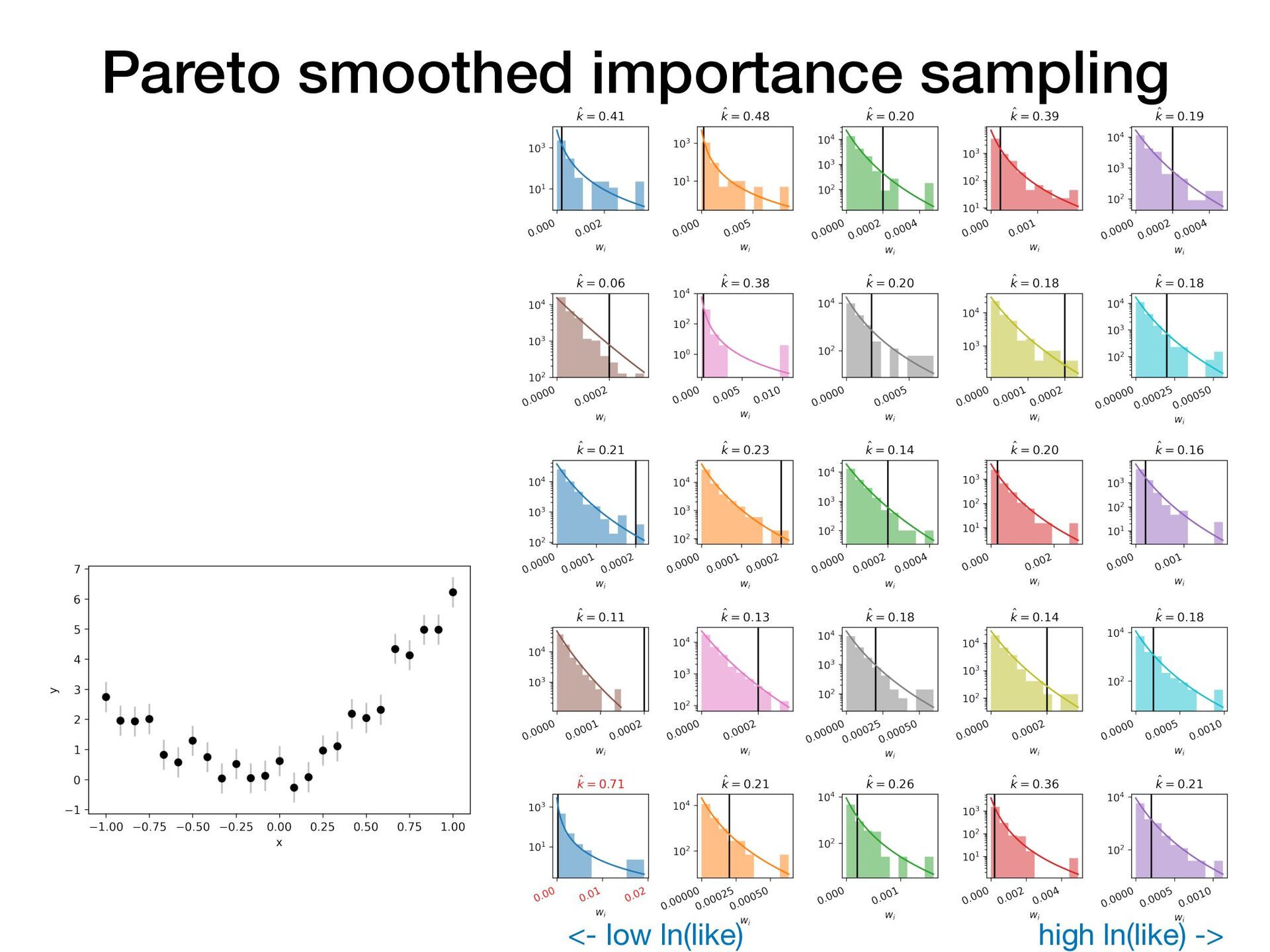
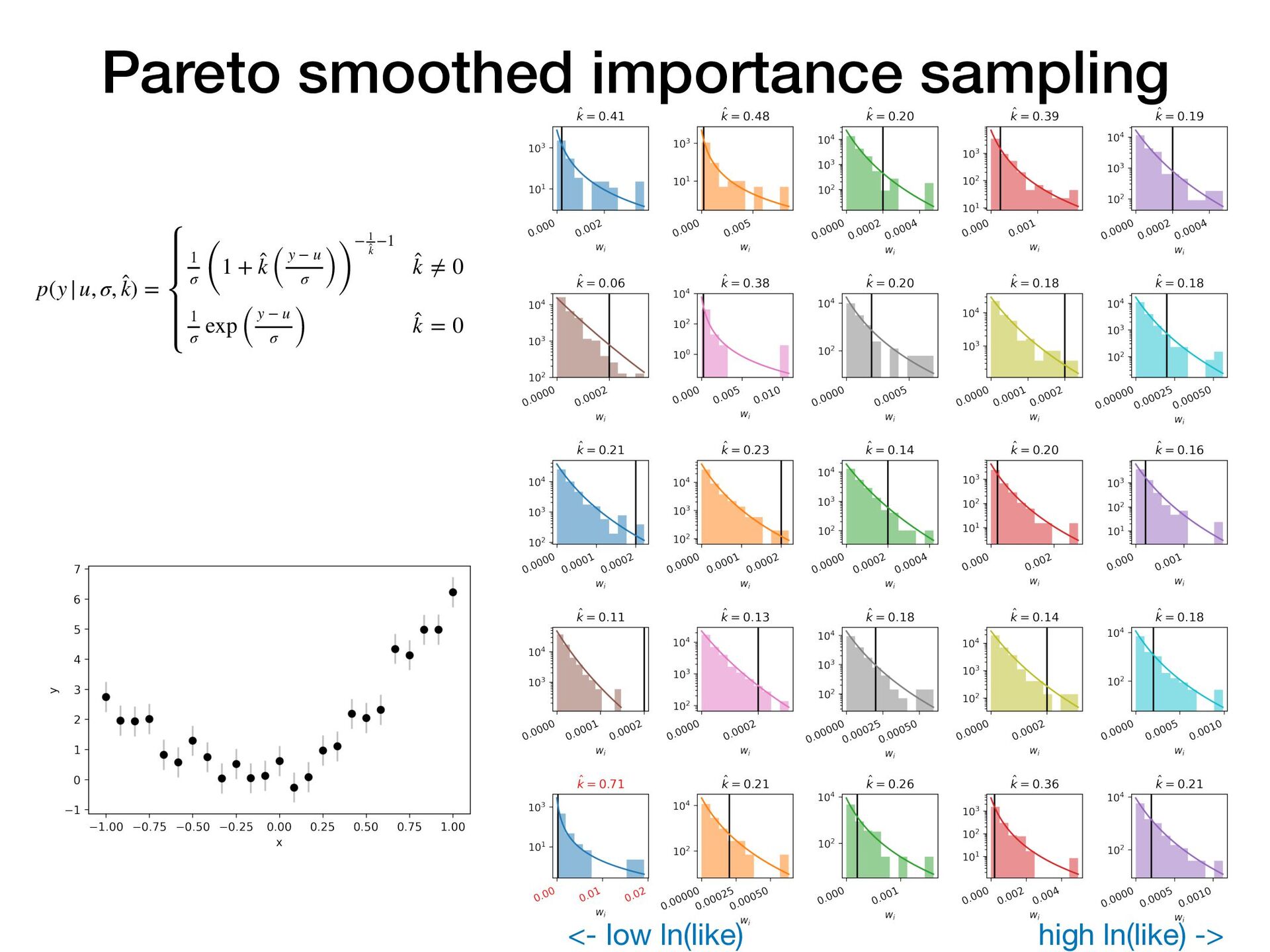
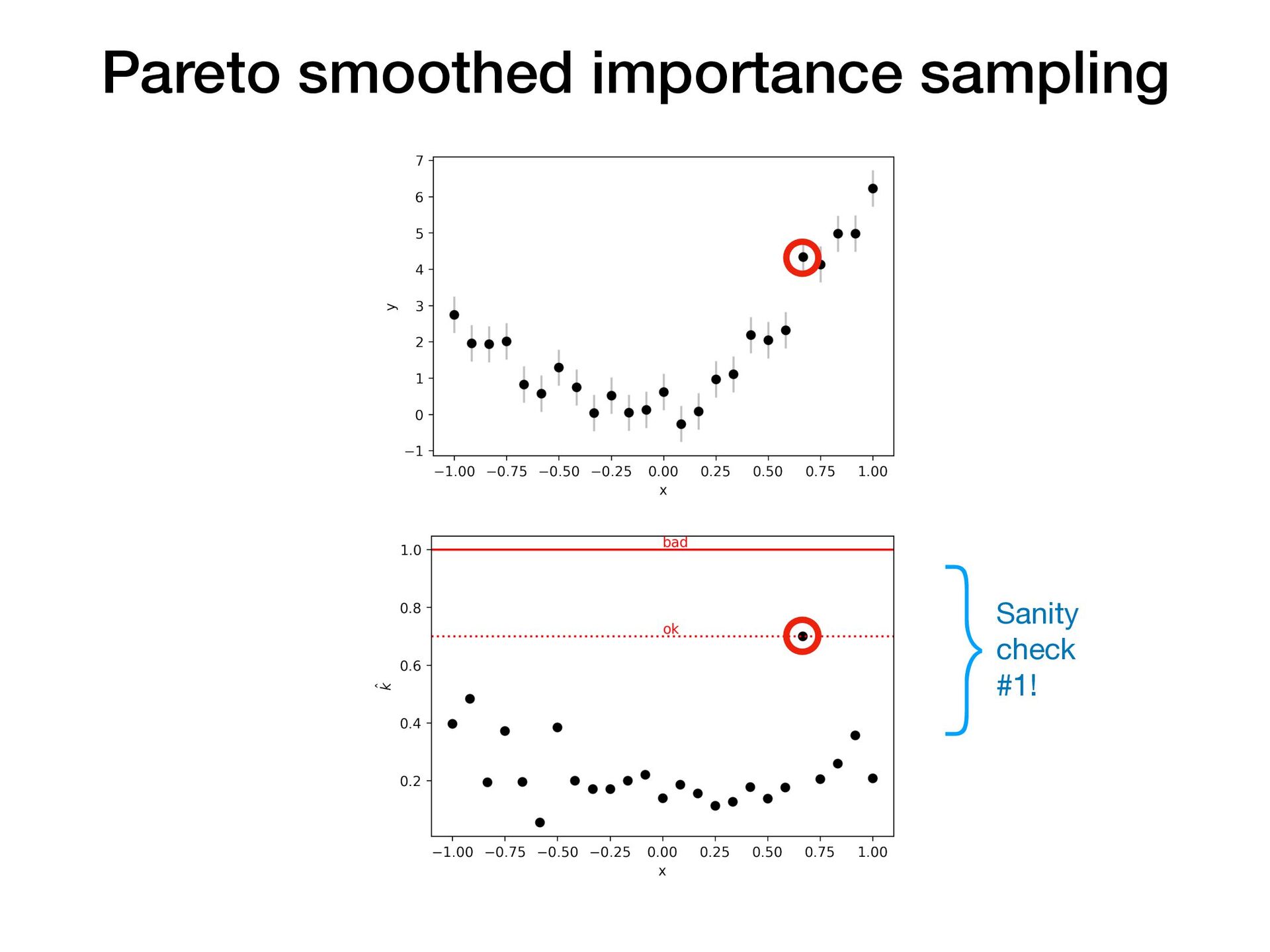
Suppose you have two or more models which fit your data reasonably well. How do you choose which model performs best on unseen data? In this short, practical tutorial, I will introduce Leave-One-Out Cross-Validation (LOO-CV) as a technique for testing a model’s predictive accuracy, and briefly show stacking for model selection. I will motivate the talk around a series of example plots generated by a pedagogical Python notebook which you can experiment with at:
https://gist.github.com/bmorris3/a69842ce9384966feba965eb0d726da6
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}