A review the tooling and practices developed used to support Datadog's hyper-growth, as well as a return of experience on how they are deploying and operating Kafka in Kubernetes.
data modeling, scaling, cost-control and tooling – In charge of PostgreSQL, Kafka, ZooKeeper, Cassandra and Elasticsearch – Team of 4 SREs – @brouberol, @jamiealquiza – We are hiring! https://www.datadoghq.com/careers Who are we?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
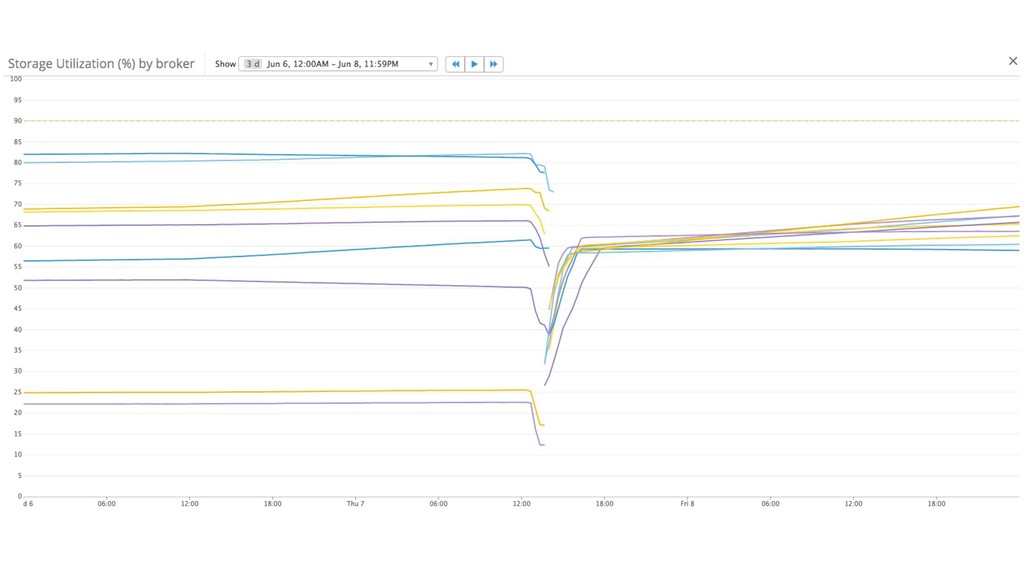{kind=link}
{kind=link}
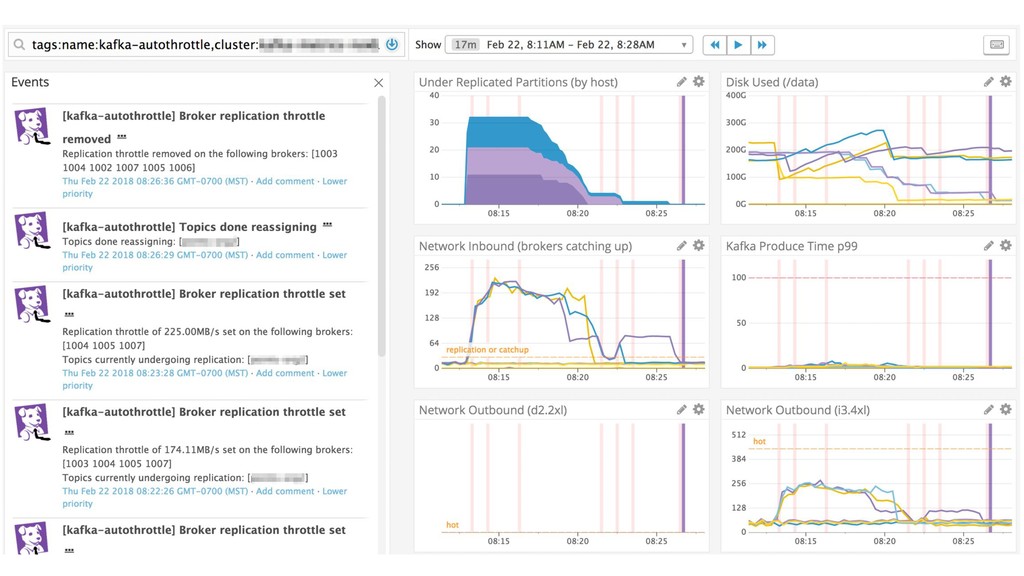{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
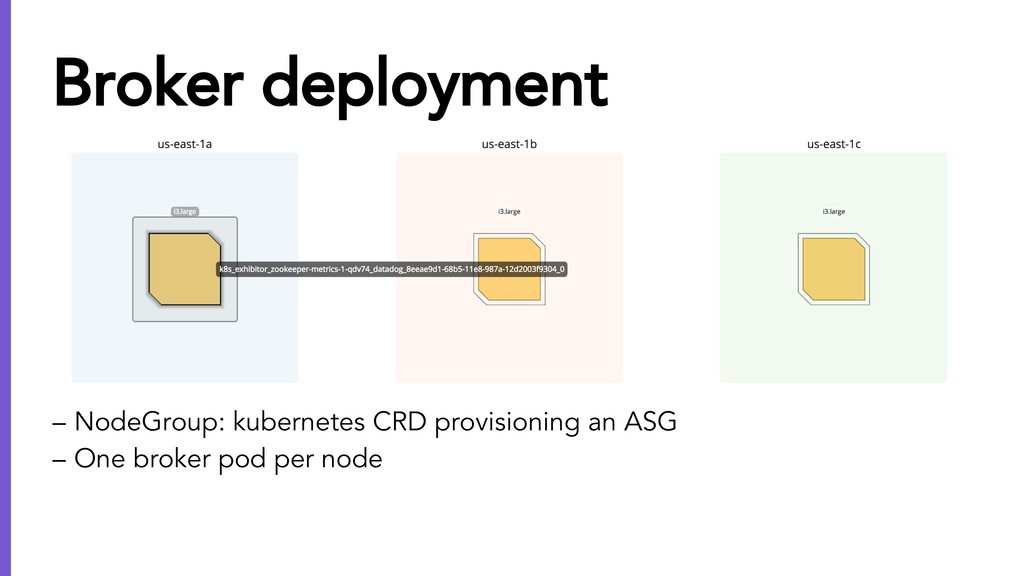{kind=link}
{kind=link}
{kind=link}
{kind=link}
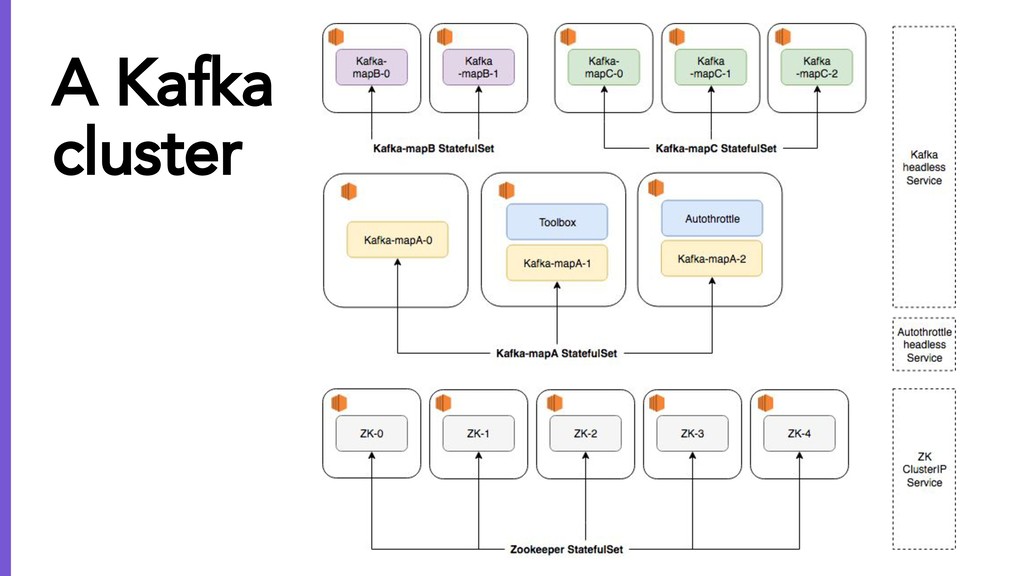{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}