Balthazar Rouberol showcases the tooling his Data Reliability Team team built at Datadog to alleviate operational toil when running large Kafka clusters. He dives into sources of toil and time consumption, tools implemented to alleviate the amount of toil, as well as monitoring and general good practices as well.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
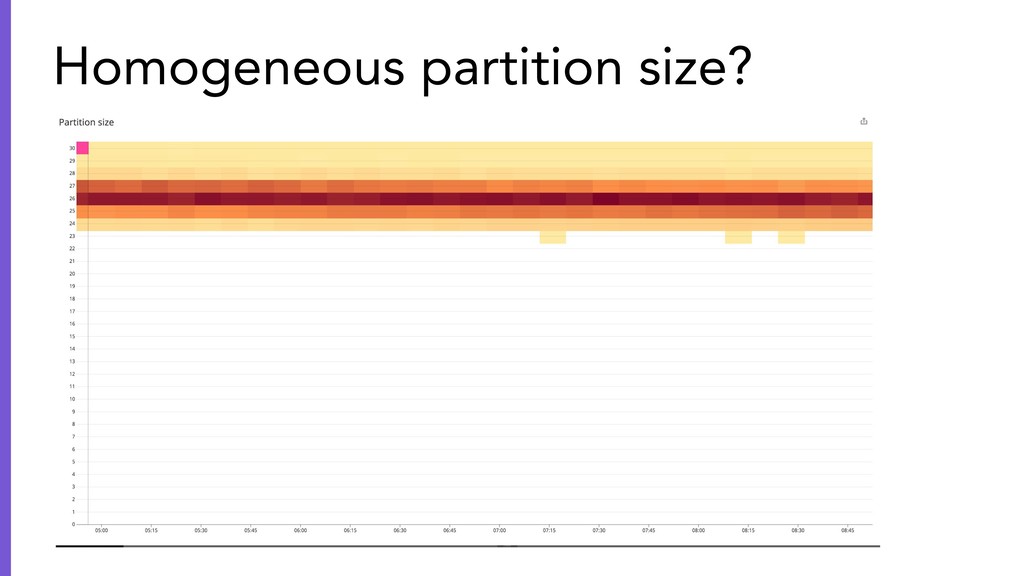{kind=link}
{kind=link}
![Usage: topicmappr [command] Available Commands: help Help about any command](https://files.speakerdeck.com/presentations/ee458d78a35248dc8e881c345a397b37/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
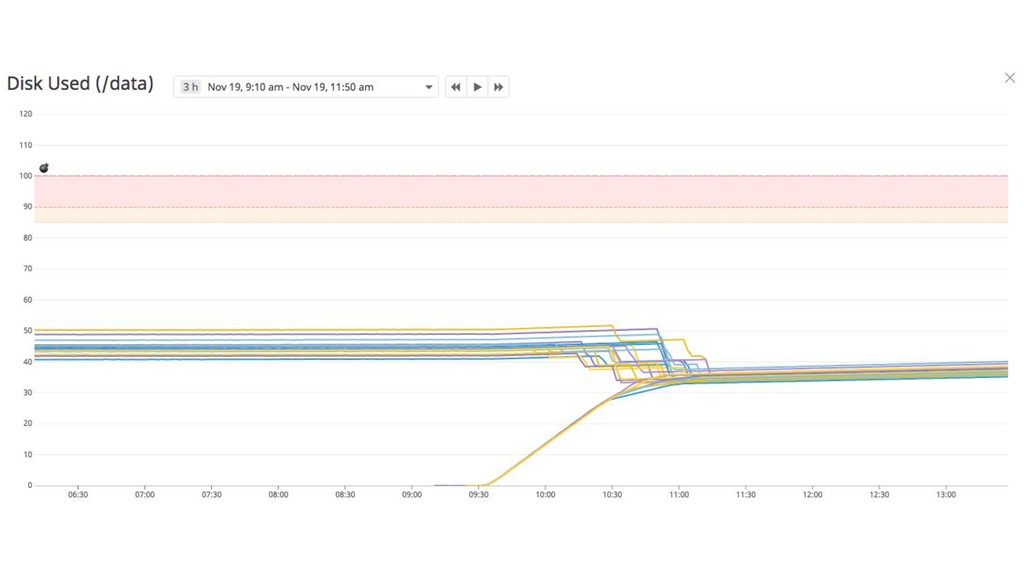{kind=link}
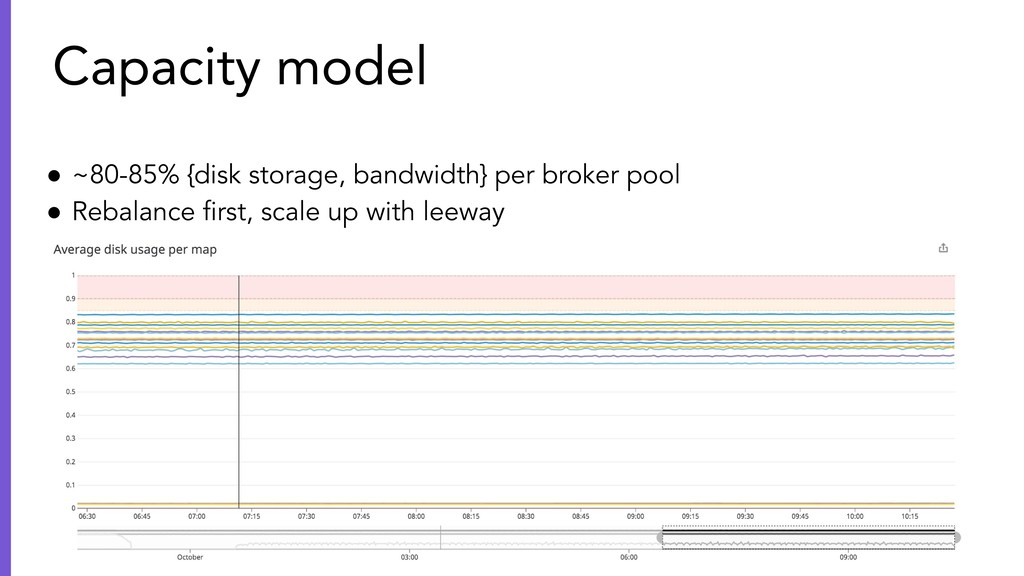{kind=link}
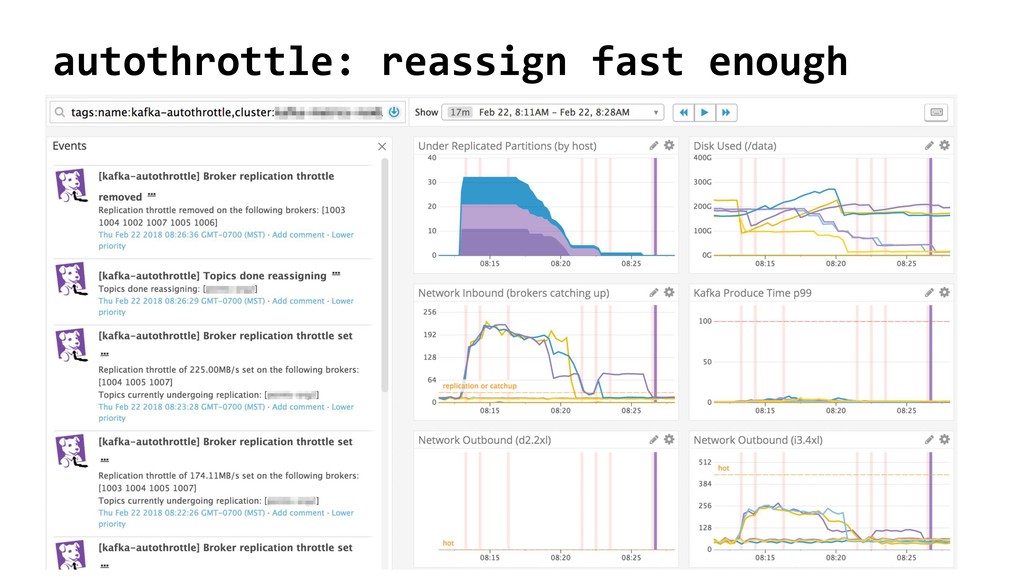{kind=link}
{kind=link}
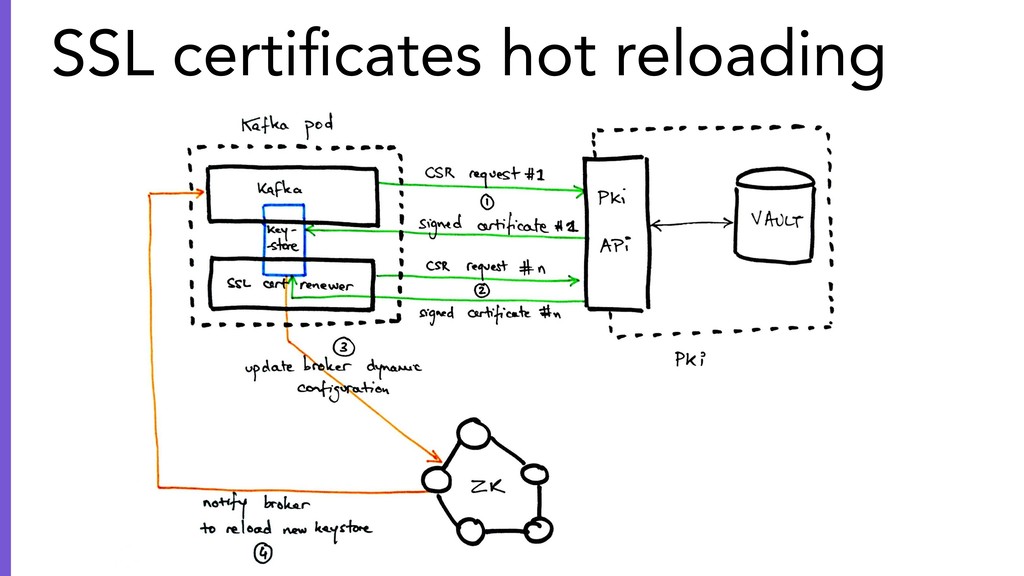{kind=link}
{kind=link}
{kind=link}
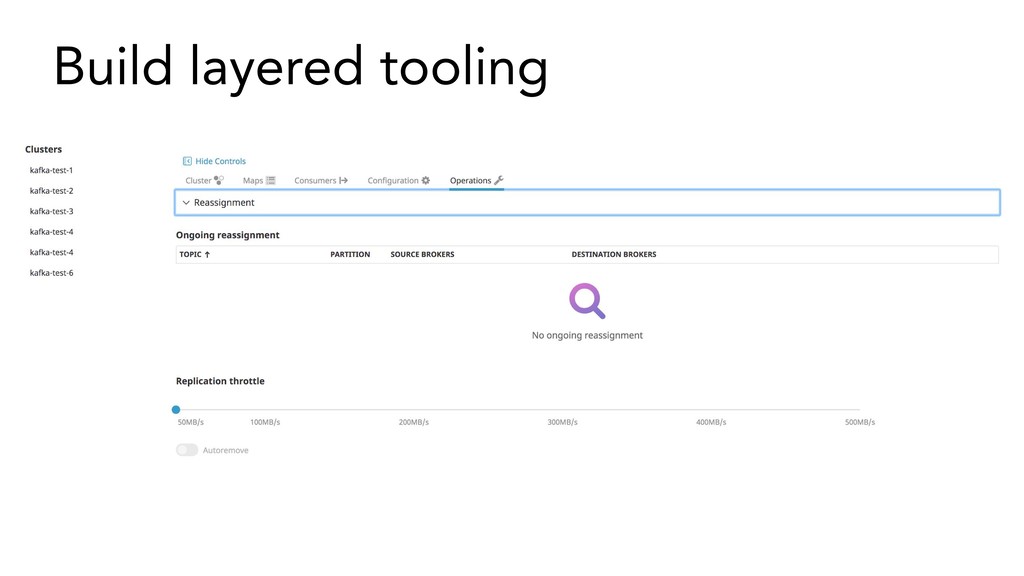{kind=link}
{kind=link}
{kind=link}
{kind=link}
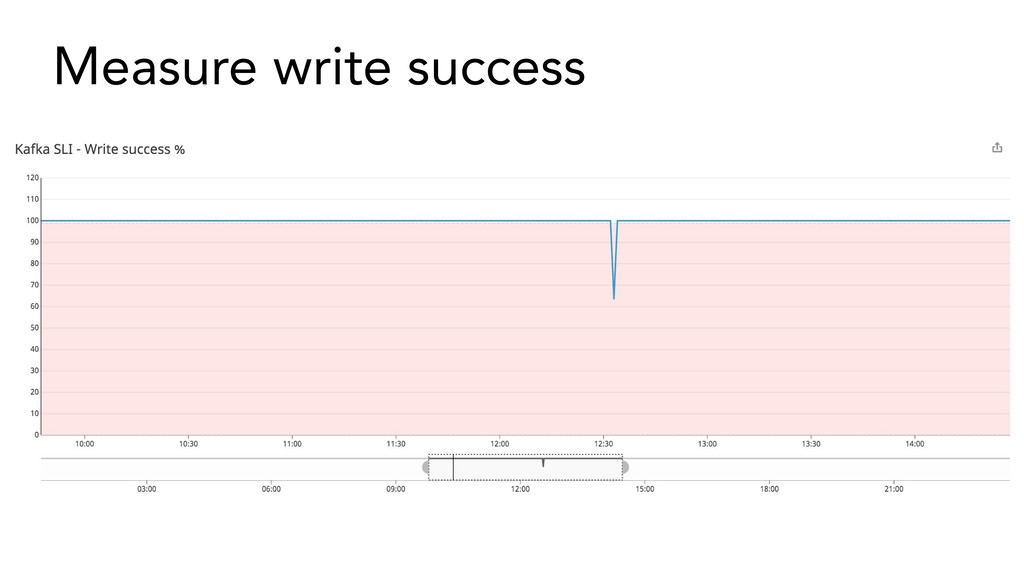{kind=link}
{kind=link}
{kind=link}
{kind=link}