Deploying stateful production applications in Kubernetes, such as Kafka, is often seen as ill-advised. The arguments are that it’s easy to get wrong, requires learning new skills, is too risky for unclear gains, or that Kubernetes is simply too young a project. This does not have to be true, and we will explain why. Datadog having made the choice to migrate its entire infrastructure to Kubernetes, my team was tasked with deploying reliable, production-ready Kafka clusters.
This talk will go over our deployment strategy, lessons learned, describe the challenges we faced along the way, as well as the reliability benefits we have observed.
This presentation will go through:
– an introduction to the tools and practices establised by Datadog
– a brief introduction of Kubernetes and associated concepts
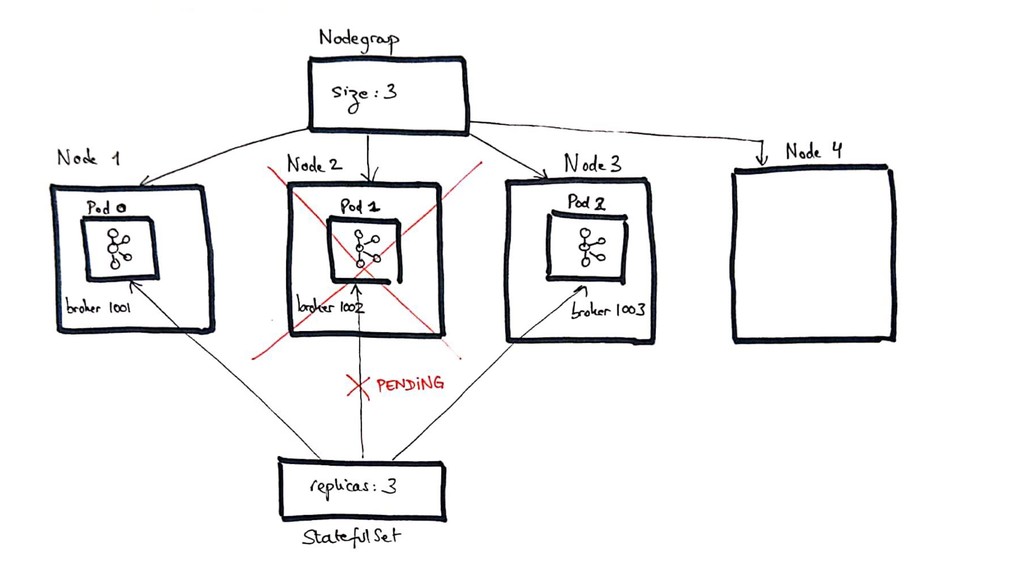
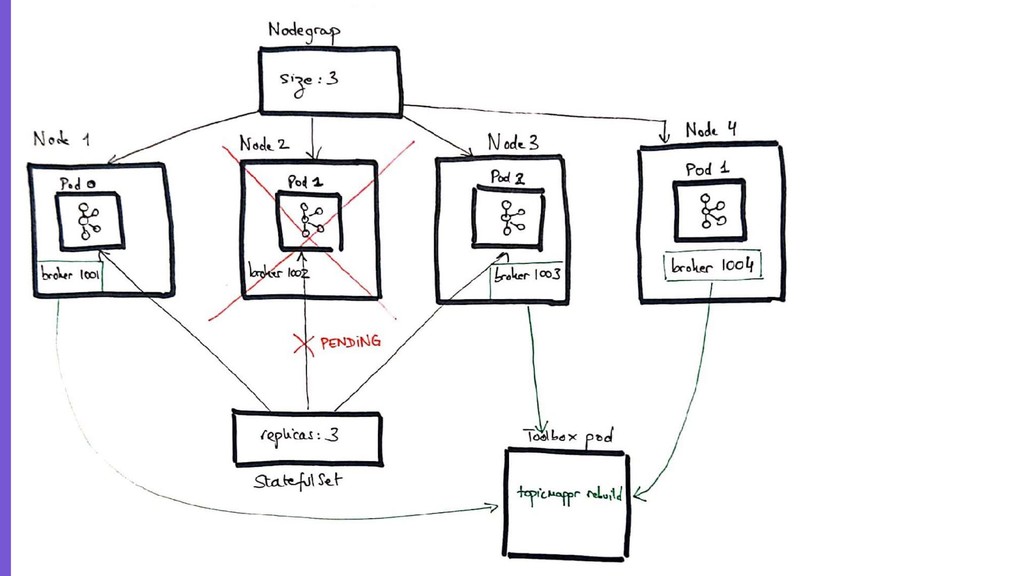
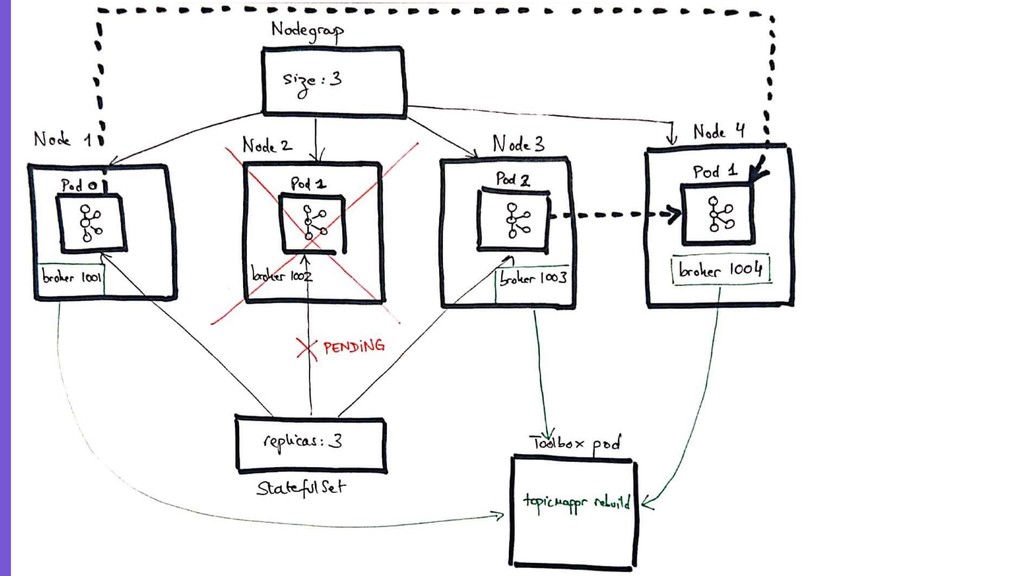
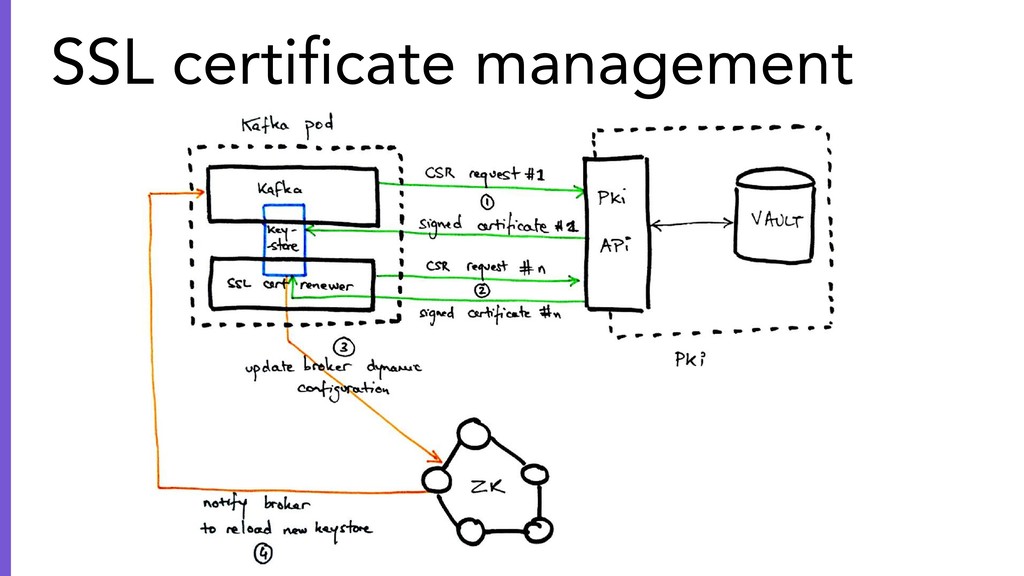
– a deep dive into the deployment and bootstrap strategy of a production-bearing Kafka cluster in Kubernetes
– a walkthrough of some routine operations in a Kubernetes-based Kafka cluster
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
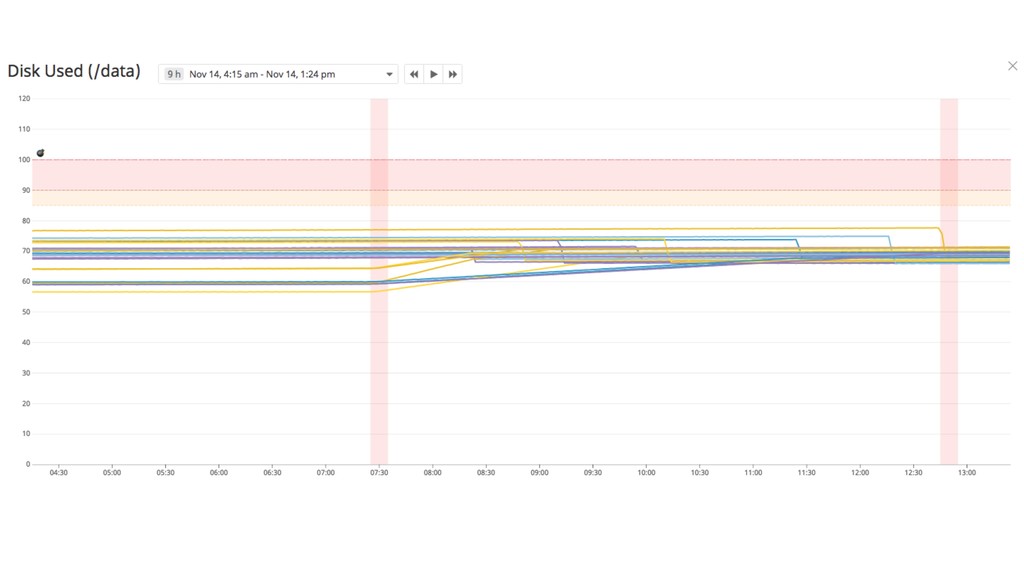{kind=link}
{kind=link}
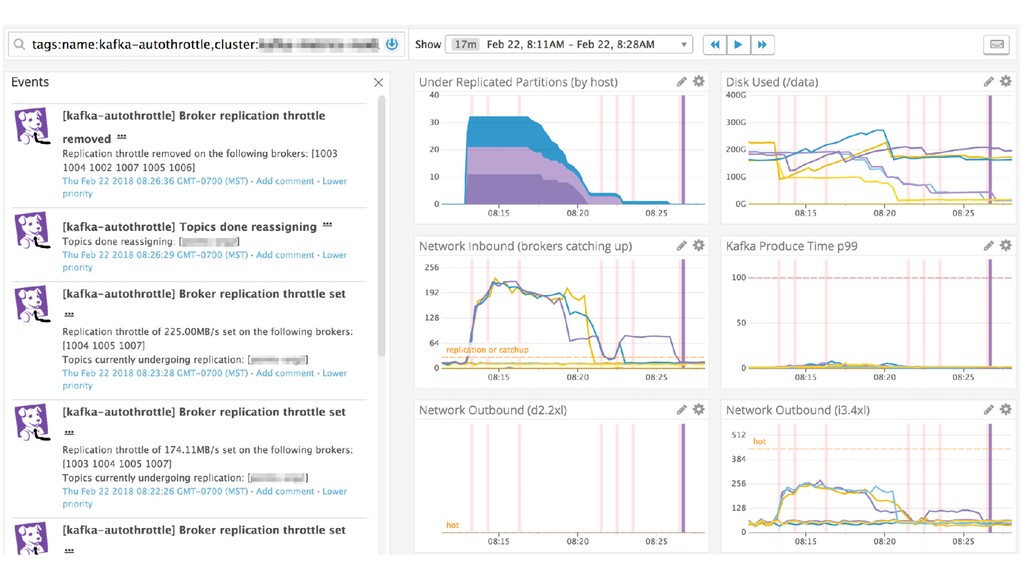{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
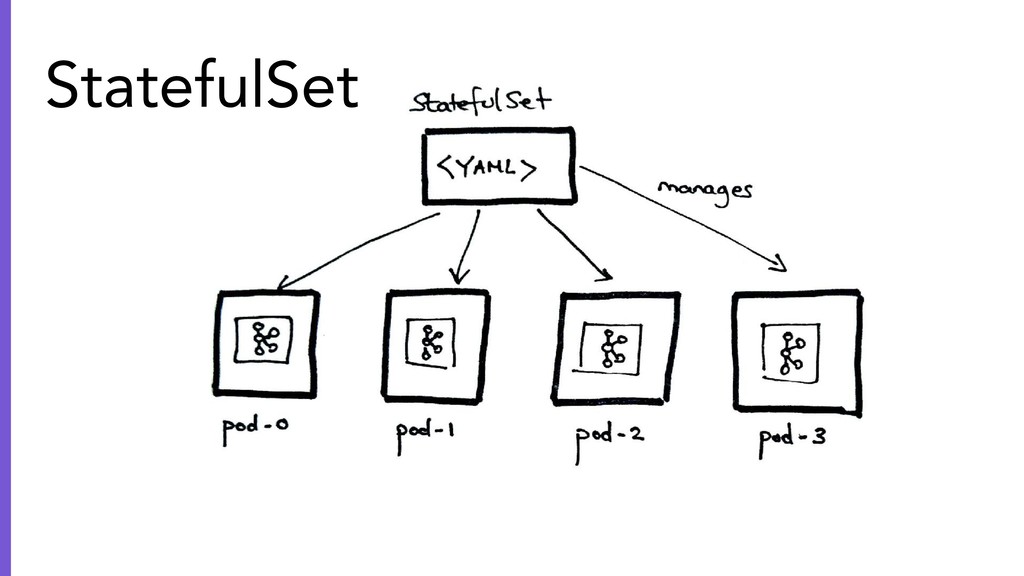{kind=link}
{kind=link}
{kind=link}
{kind=link}
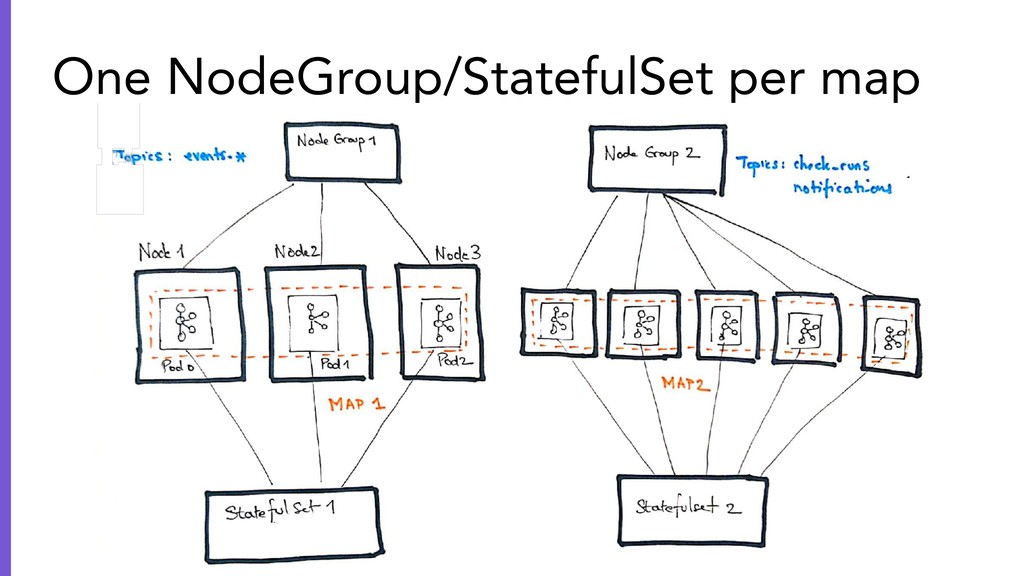{kind=link}
{kind=link}
{kind=link}
{kind=link}
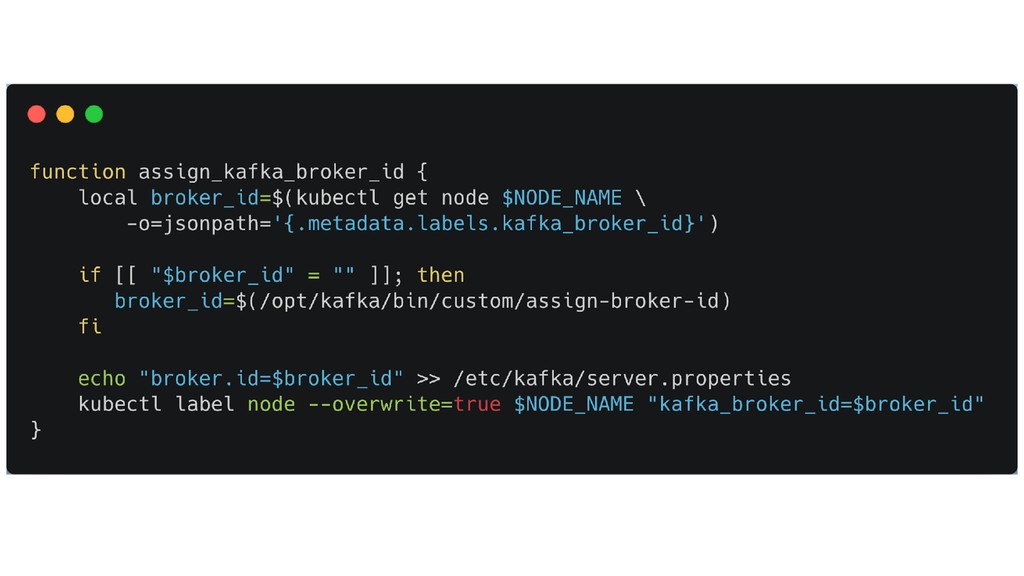{kind=link}
{kind=link}
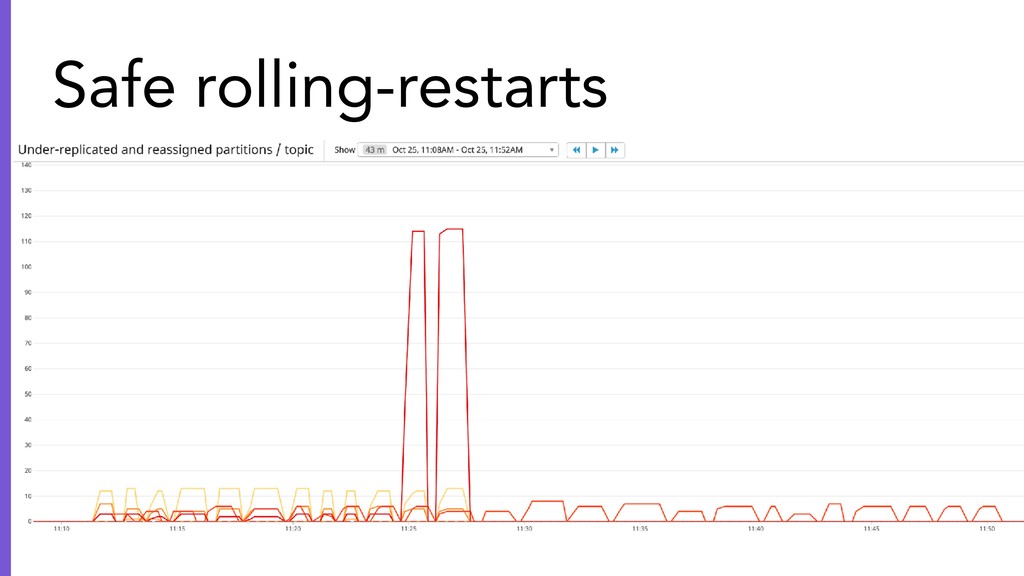{kind=link}
{kind=link}
{kind=link}
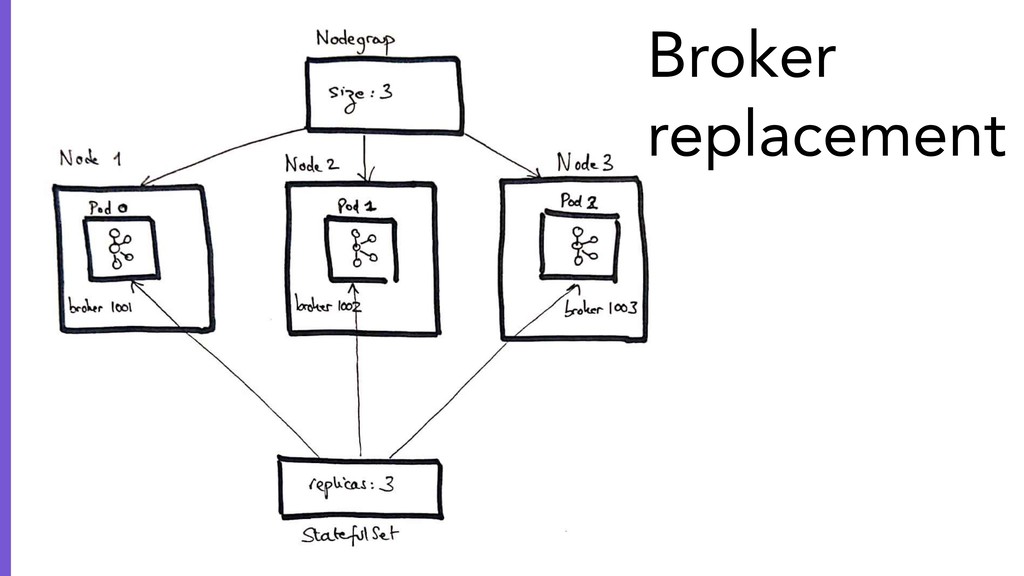{kind=link}
{kind=link}
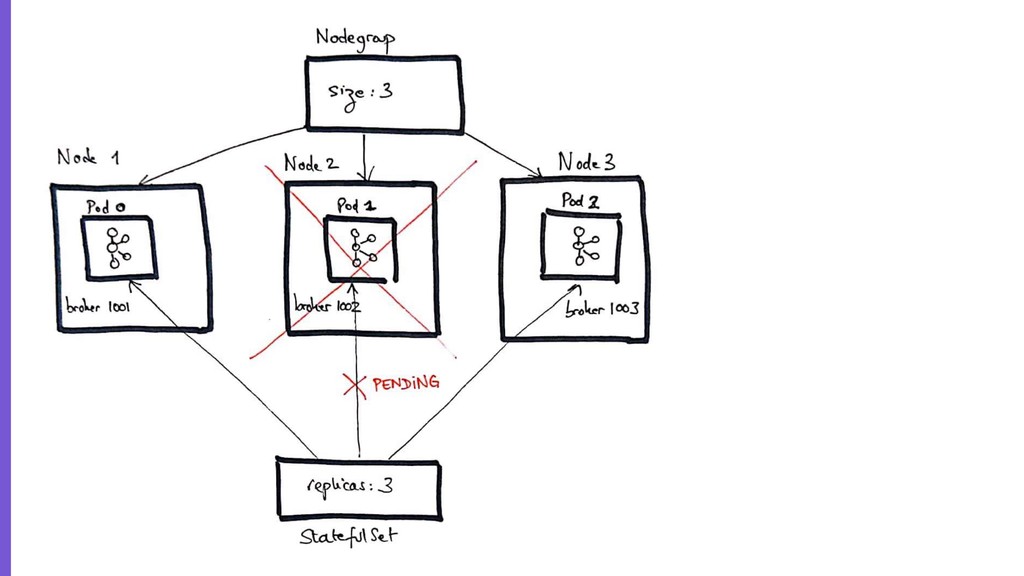{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}