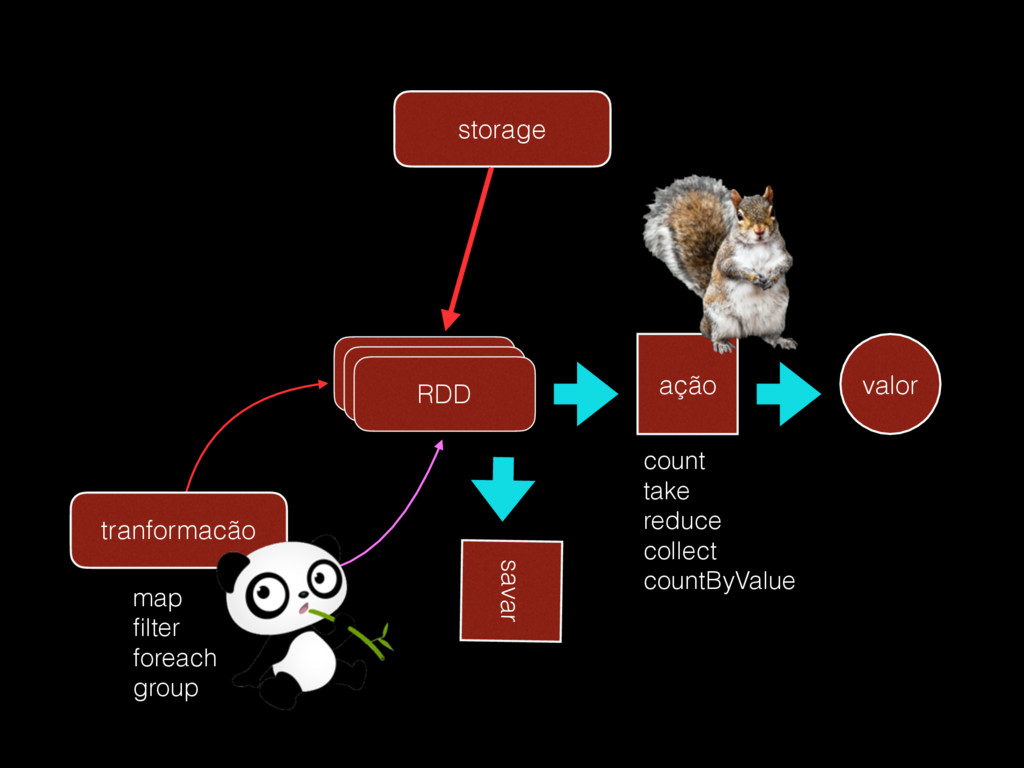
as funções de Map e Reduce; • evita mover dados durante o processamento, • “cachea” dados em memória e processamento proximo do tempo real. • detem dados intermediários em memória, para processar o mesmo conjunto de dados varias vezes • o disco é usado quando a memória acaba. • REPL
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
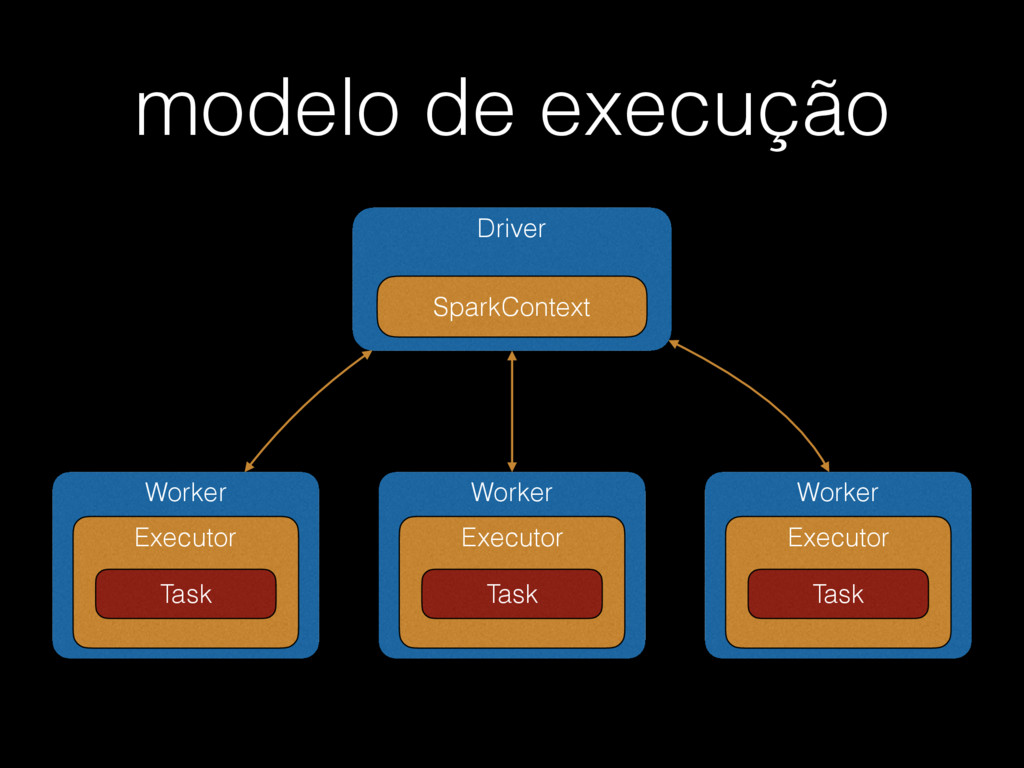{kind=link}
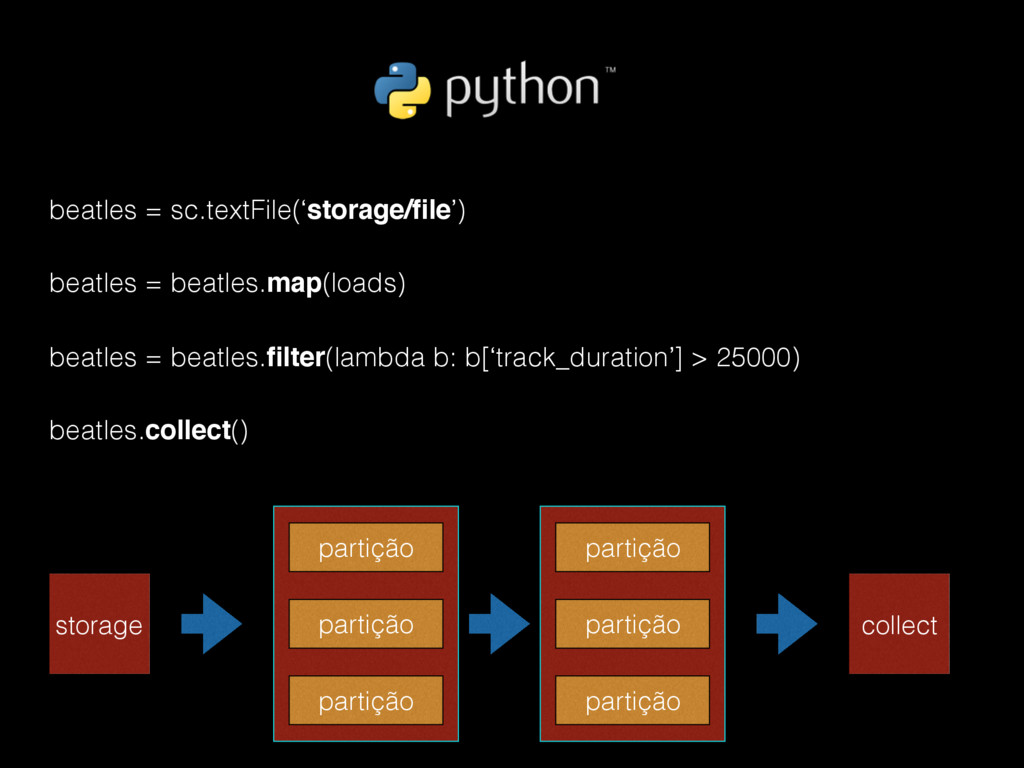{kind=link}
{kind=link}
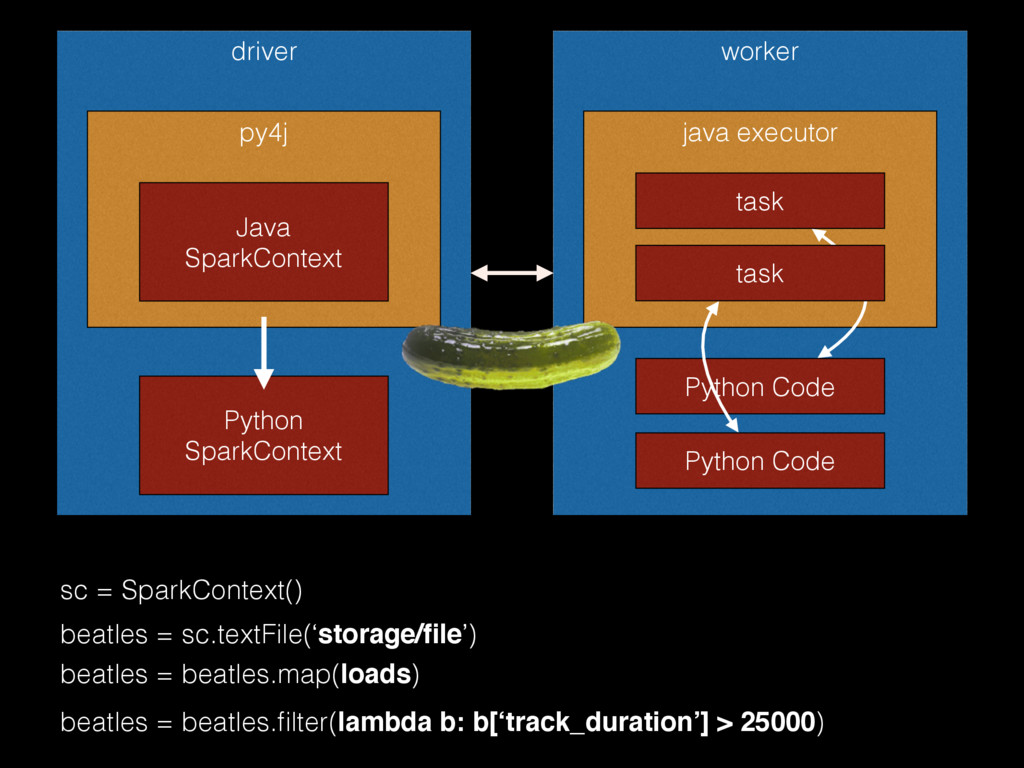{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}