na JVM, se o objeto não couber na memória, as partições que não couberem não serão armazenadas e serão recomputadas em tempo de execução; MEMORY_AND_DISK mesmo que o MEMORY_ONLY mas, se os dados não couberem na memória, serão persistidos em disco. MEMORY_ONLY_SER mesmo que o MEMORY_ONLY mas armazena um objeto serializado em memória. Tende a ser mais eficiente, mas consome mais CPU. MEMORY_AND_DISK_SER mesmo que MEMORY_ONLY_SER, mas, se os dados não couberem na memória, serão persistidos em disco. DISK_ONLY armazena somente em disco MEMORY_ONLY_2
MEMORY_AND_DISK_2 exatamente mesma coisa que as informações acima, porem replica a partição em 2 nós.
![pyspark e computação distribuída @bsao / [email protected]](https://files.speakerdeck.com/presentations/6f477b8be3c04ac6b54ede728efeadbb/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
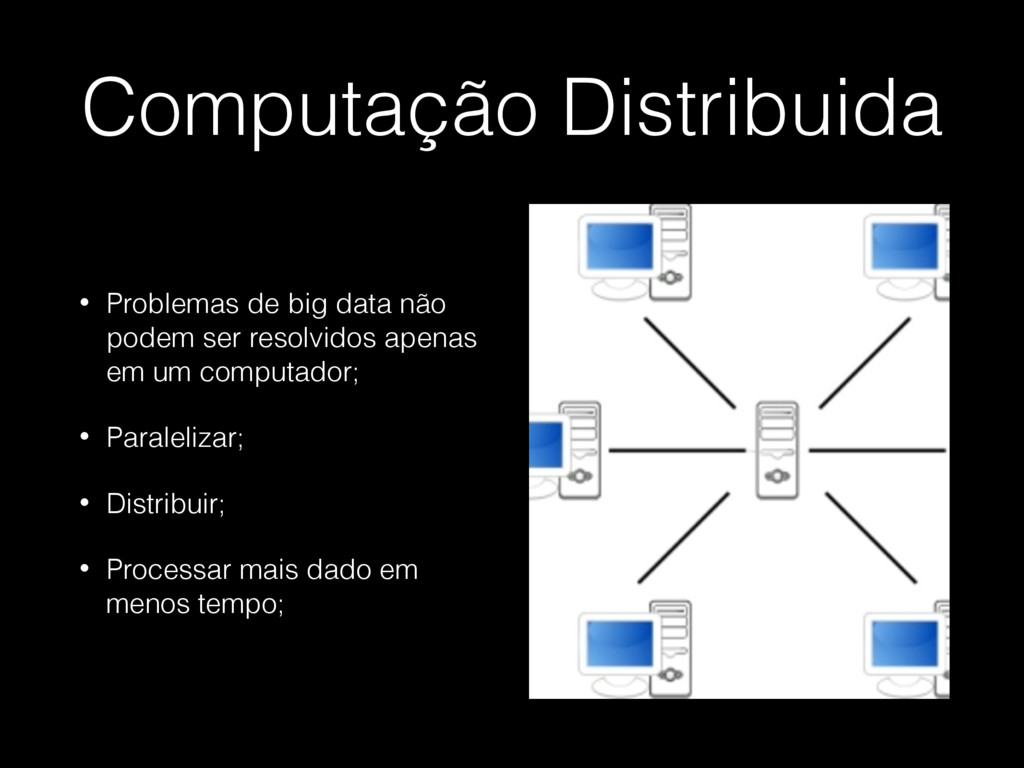{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
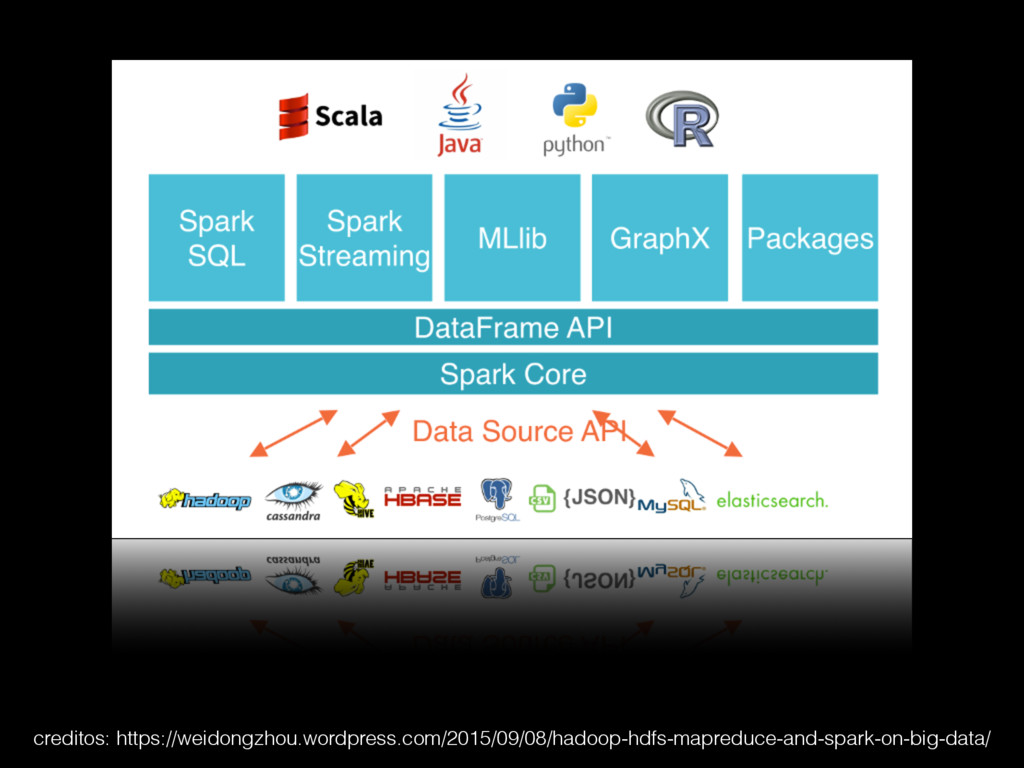{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
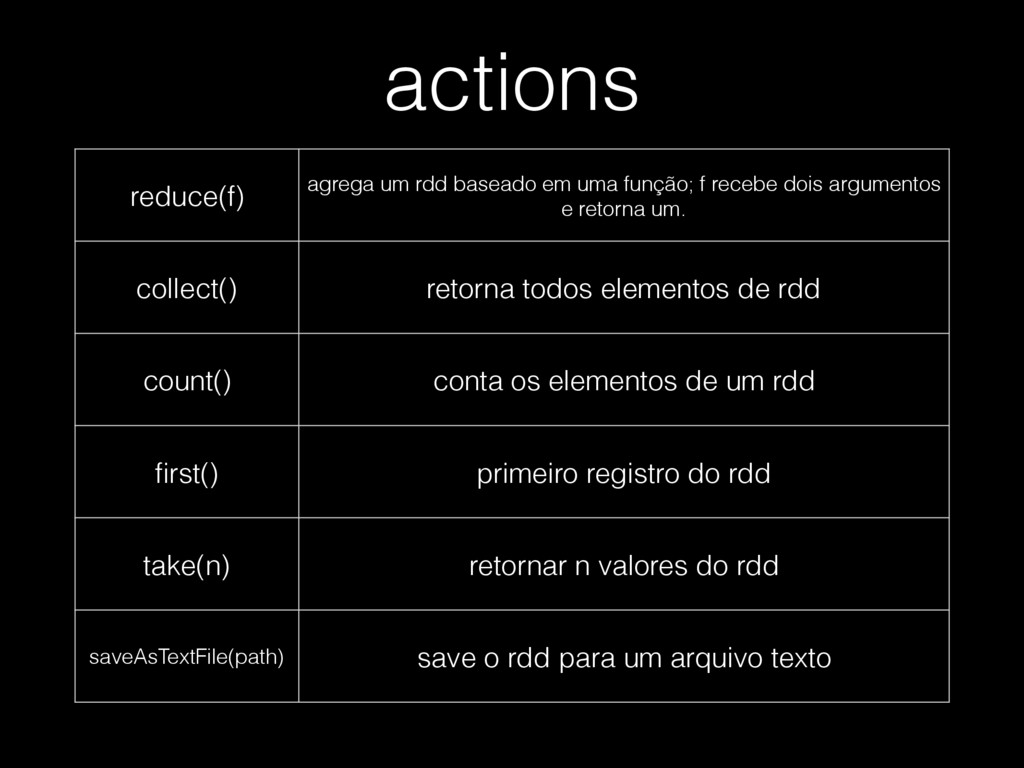{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ac = sc.accumulator(0) rdd = sc.parallelize([1, 2, 3, 4]) def](https://files.speakerdeck.com/presentations/6f477b8be3c04ac6b54ede728efeadbb/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
![@bsao / [email protected] / r0bsao](https://files.speakerdeck.com/presentations/6f477b8be3c04ac6b54ede728efeadbb/slide_45.jpg){kind=link}