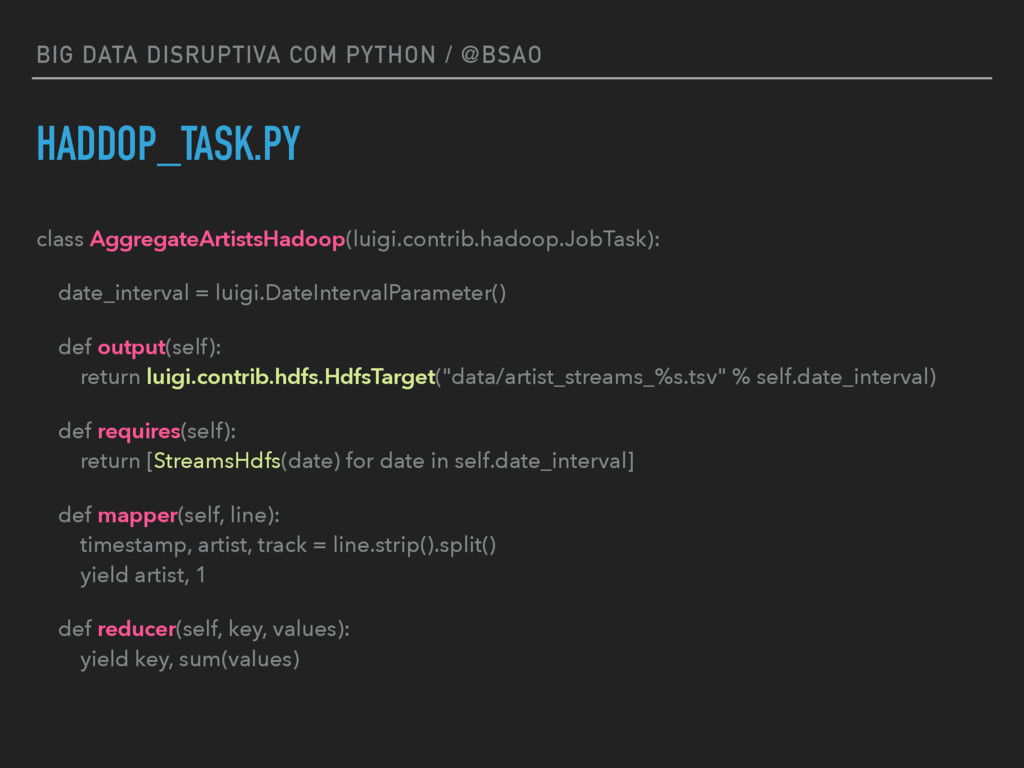
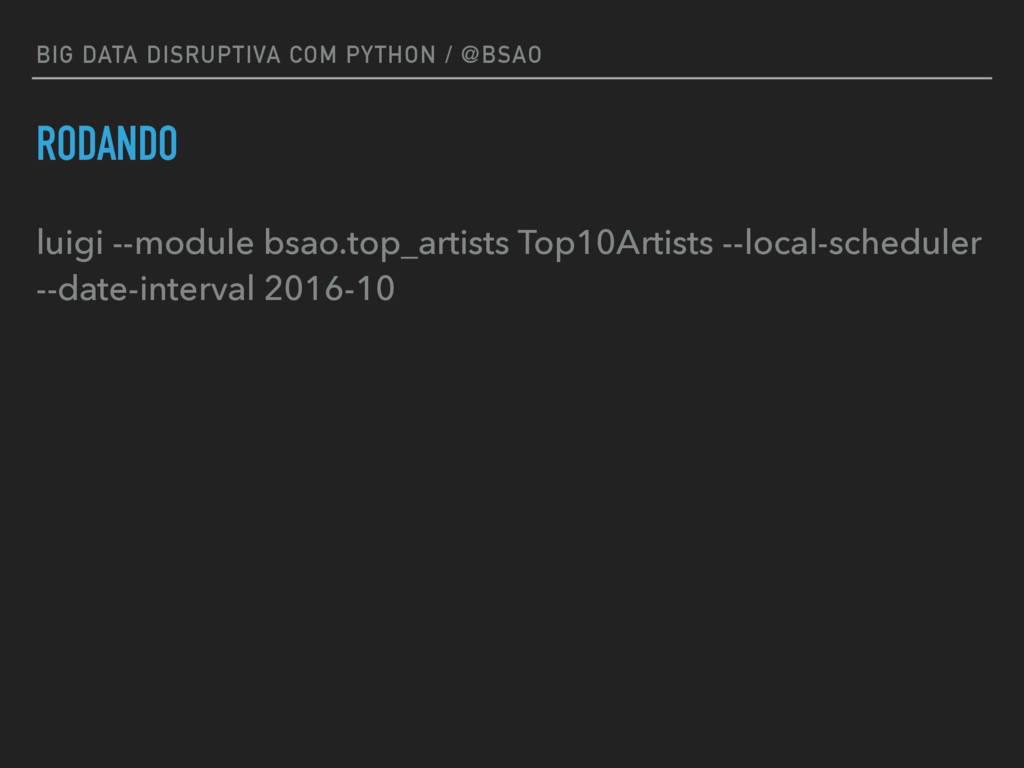
date_interval = luigi.DateIntervalParameter()
def requires(self):
return AggregateArtistsHadoop(self.date_interval)
def output(self):
return luigi.LocalTarget("data/top_artists_%s.tsv" % self.date_interval) def run(self):
top_10 = nlargest(10, self._input_iterator())
with self.output().open('w') as out_file:
for streams, artist in top_10:
print >> out_file, self.date_interval.date_a, self.date_interval.date_b, artist, streams def _input_iterator(self):
with self.input().open('r') as in_file:
for line in in_file:
artist, streams = line.strip().split()
yield int(streams), int(artist)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![OBRIGADO <3 @bsao / [email protected] / telegram: r0bsao BIG DATA](https://files.speakerdeck.com/presentations/6ed3c6f6d59f4932bc3a7cfdcb75ab5d/slide_40.jpg){kind=link}