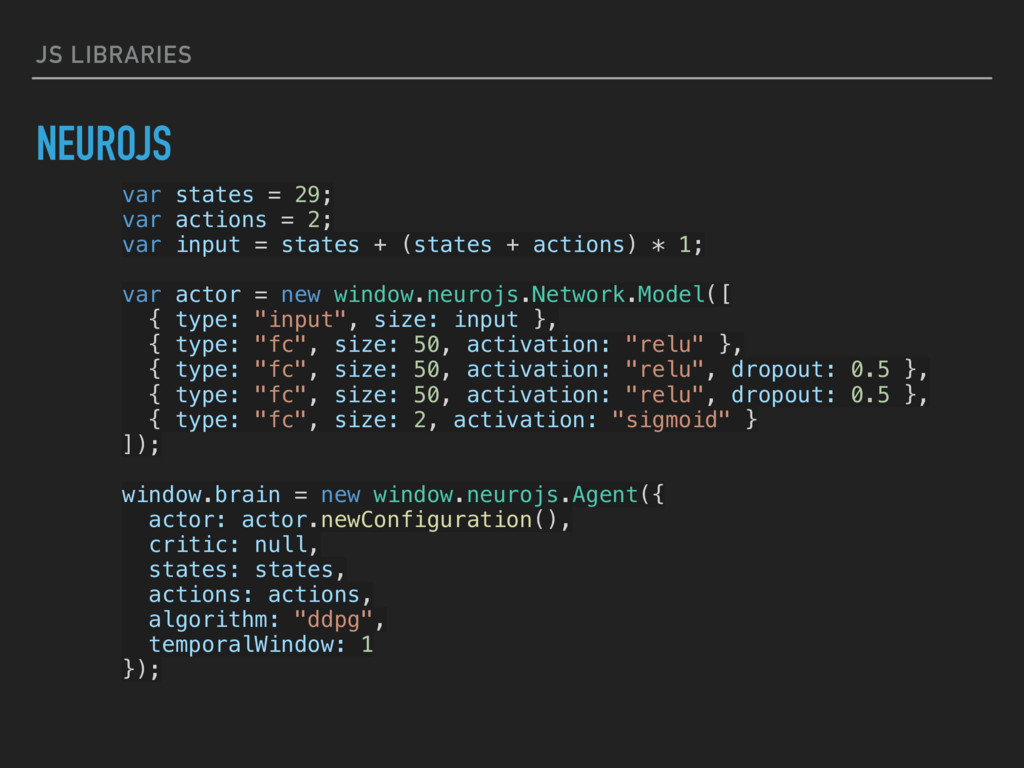
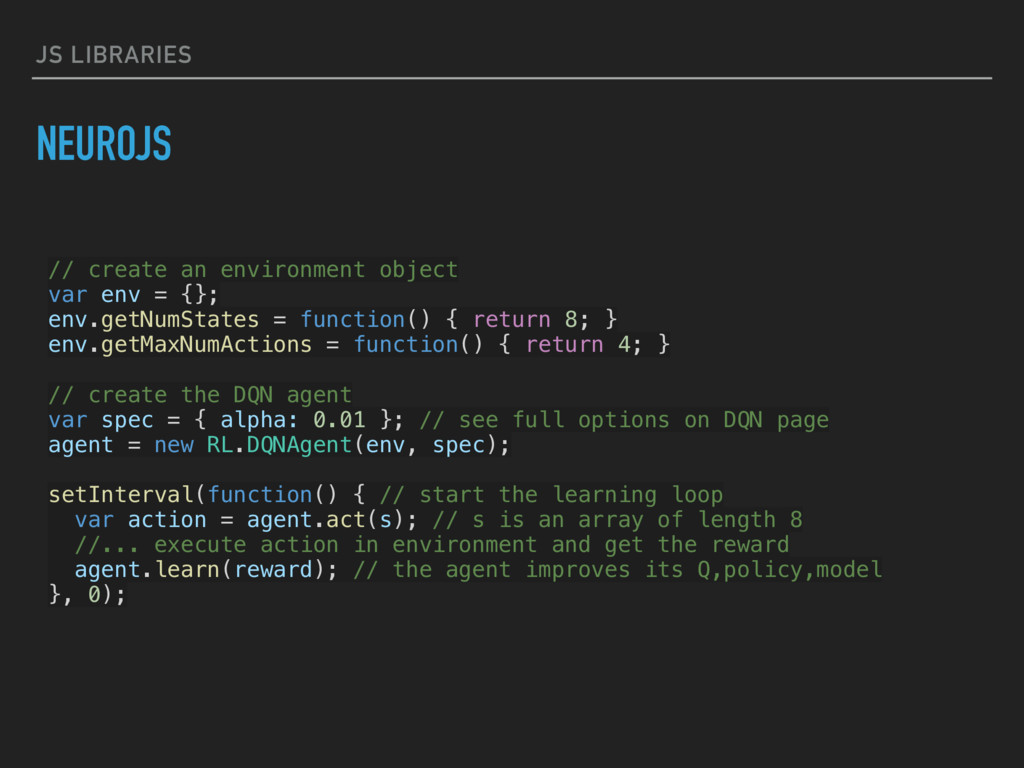
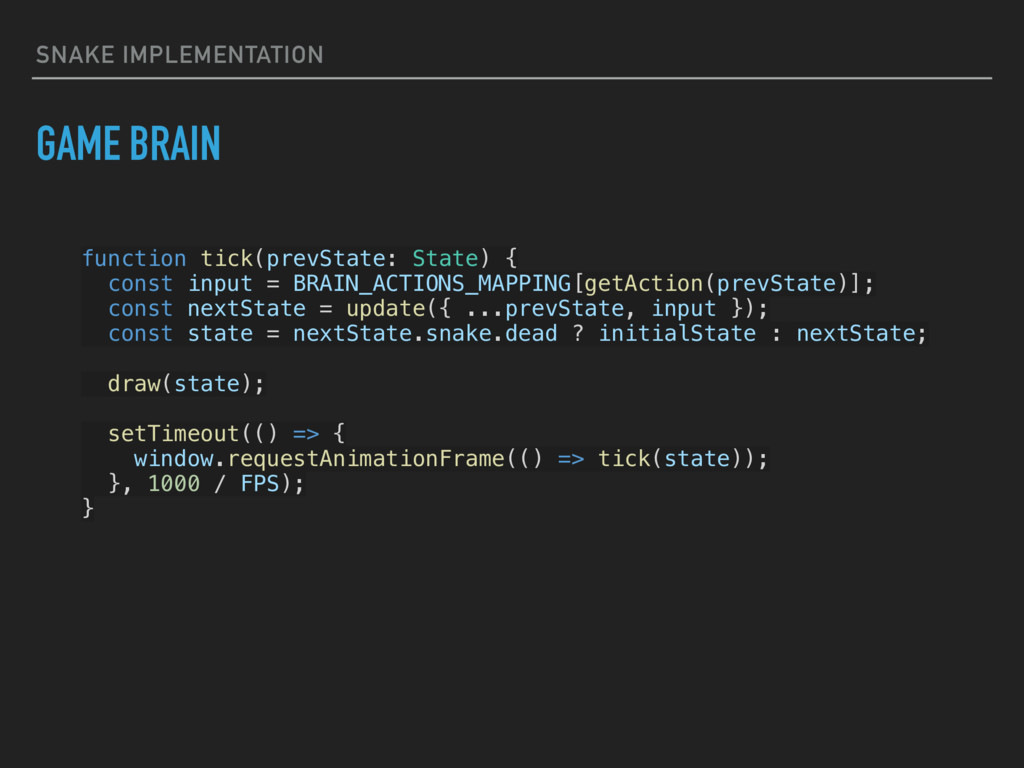
2; var input = states + (states + actions) * 1; var actor = new window.neurojs.Network.Model([ { type: "input", size: input }, { type: "fc", size: 50, activation: "relu" }, { type: "fc", size: 50, activation: "relu", dropout: 0.5 }, { type: "fc", size: 50, activation: "relu", dropout: 0.5 }, { type: "fc", size: 2, activation: "sigmoid" } ]); window.brain = new window.neurojs.Agent({ actor: actor.newConfiguration(), critic: null, states: states, actions: actions, algorithm: "ddpg", temporalWindow: 1 });
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
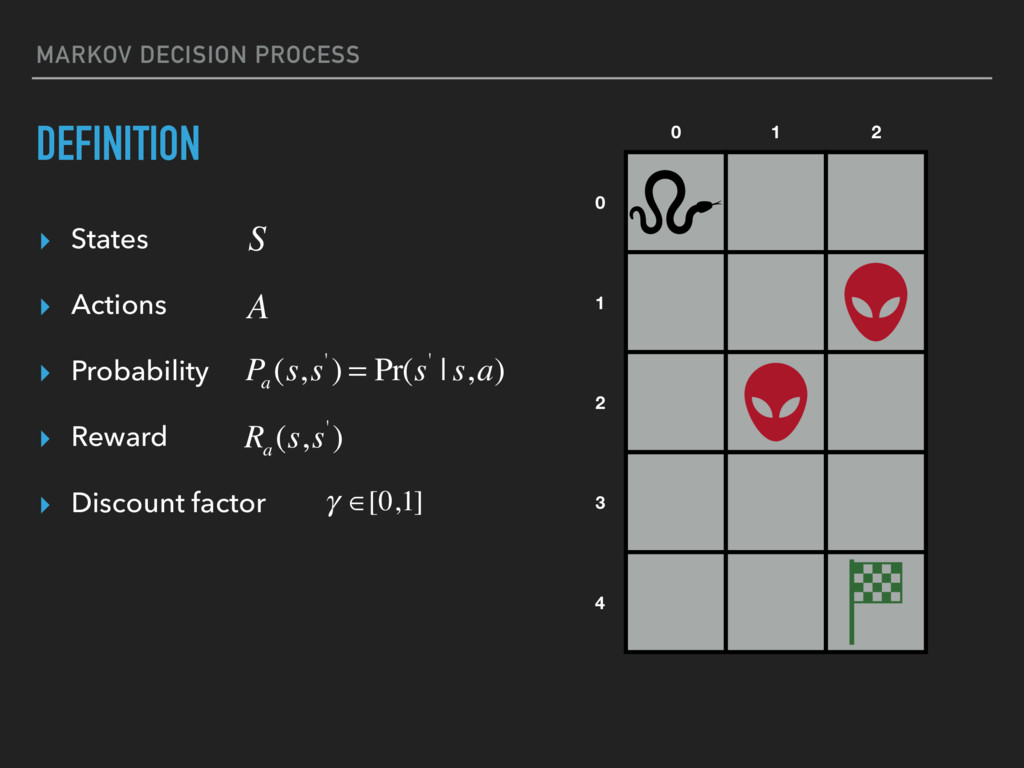{kind=link}
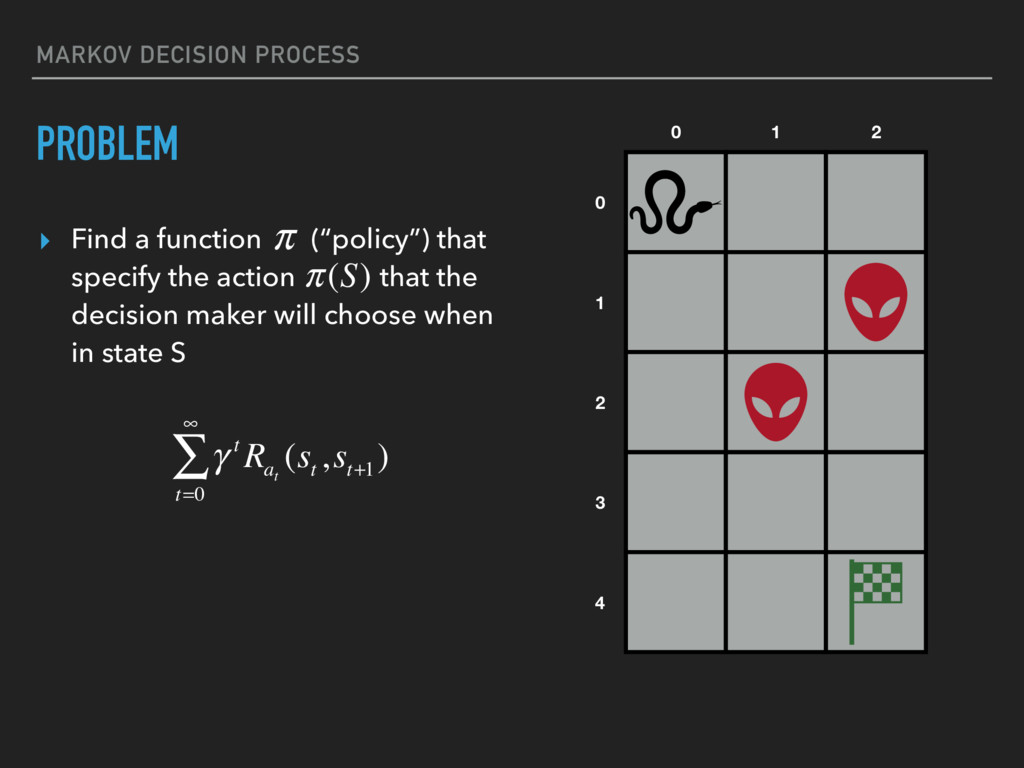{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
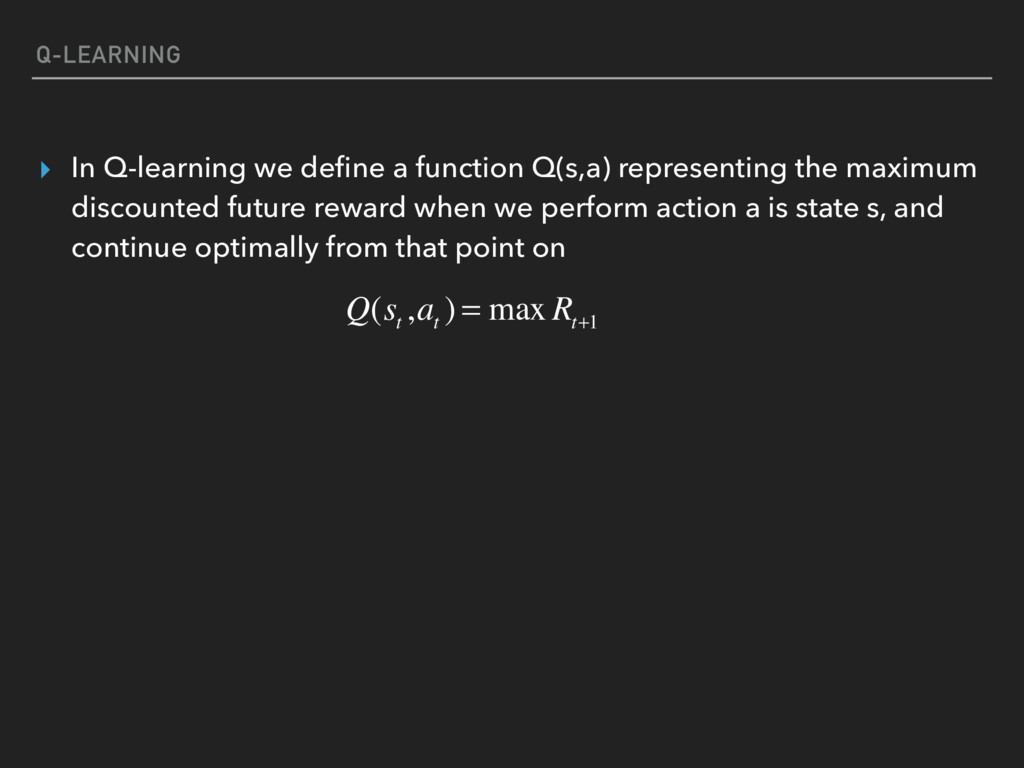{kind=link}
{kind=link}
{kind=link}
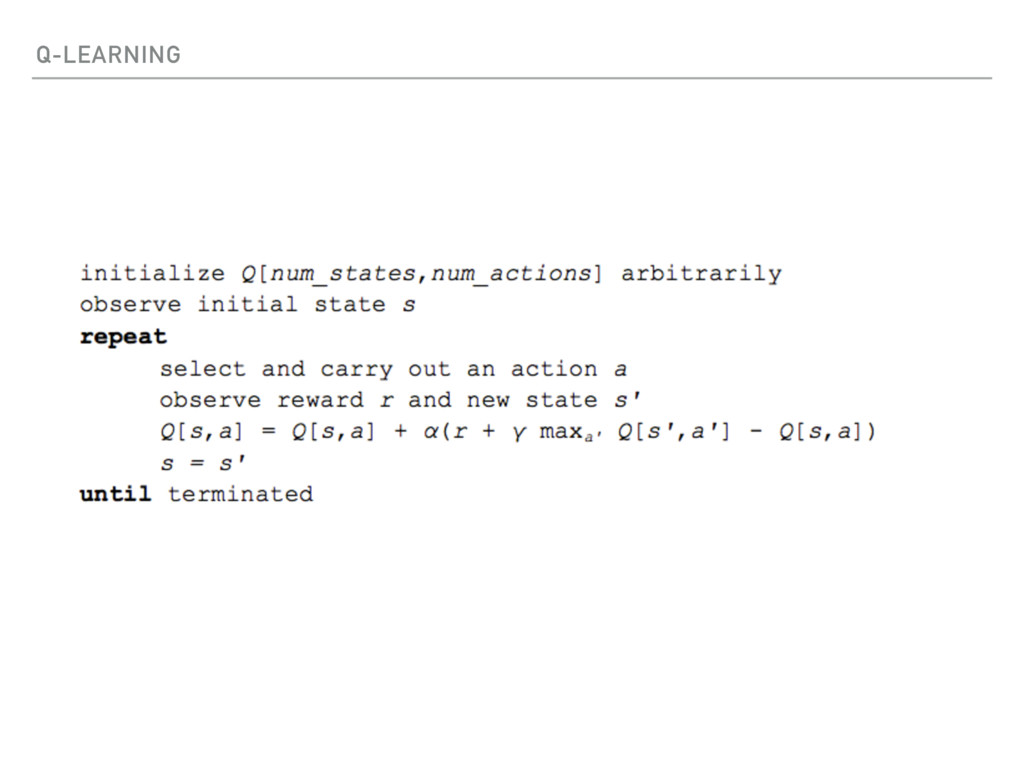{kind=link}
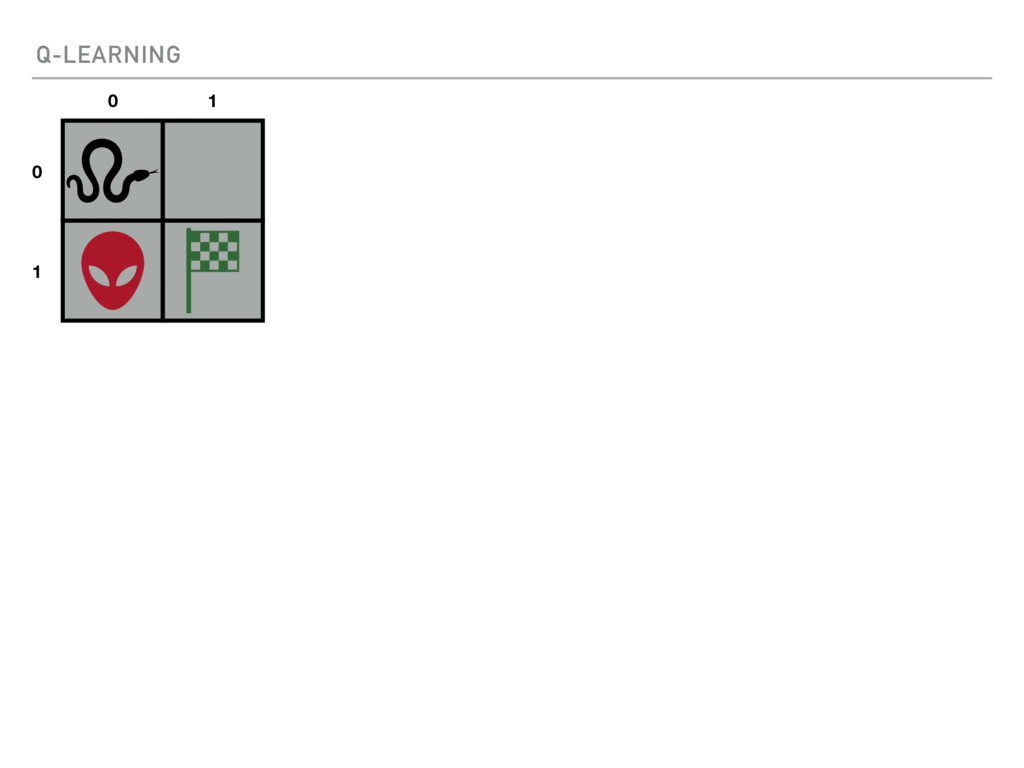{kind=link}
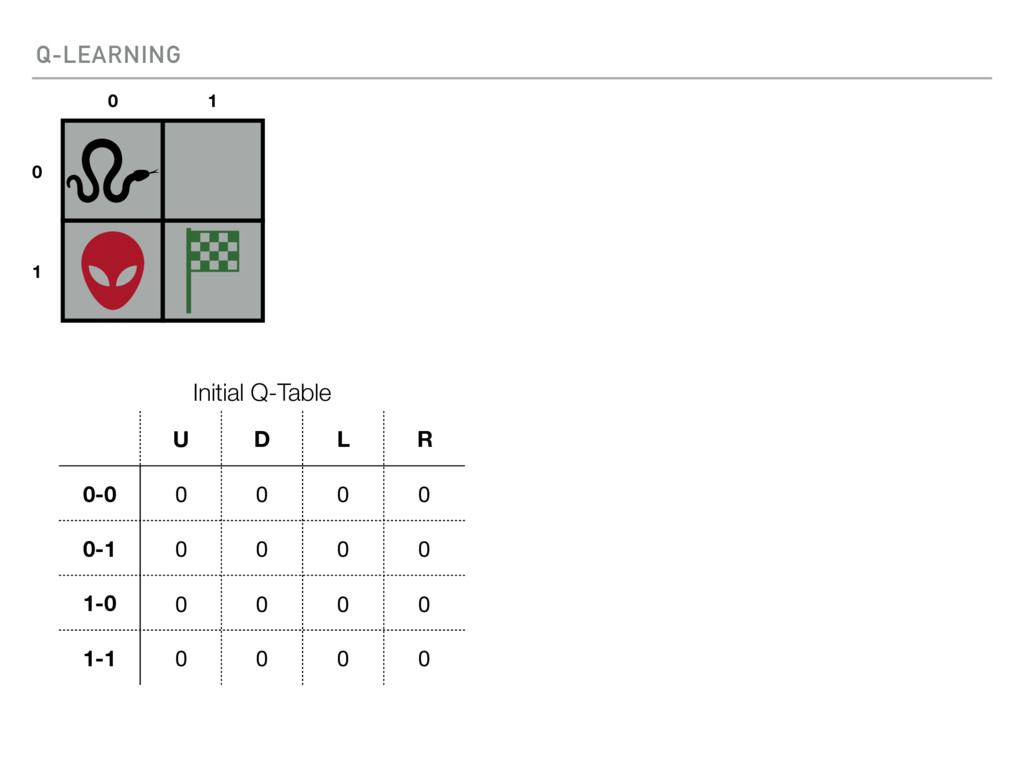{kind=link}
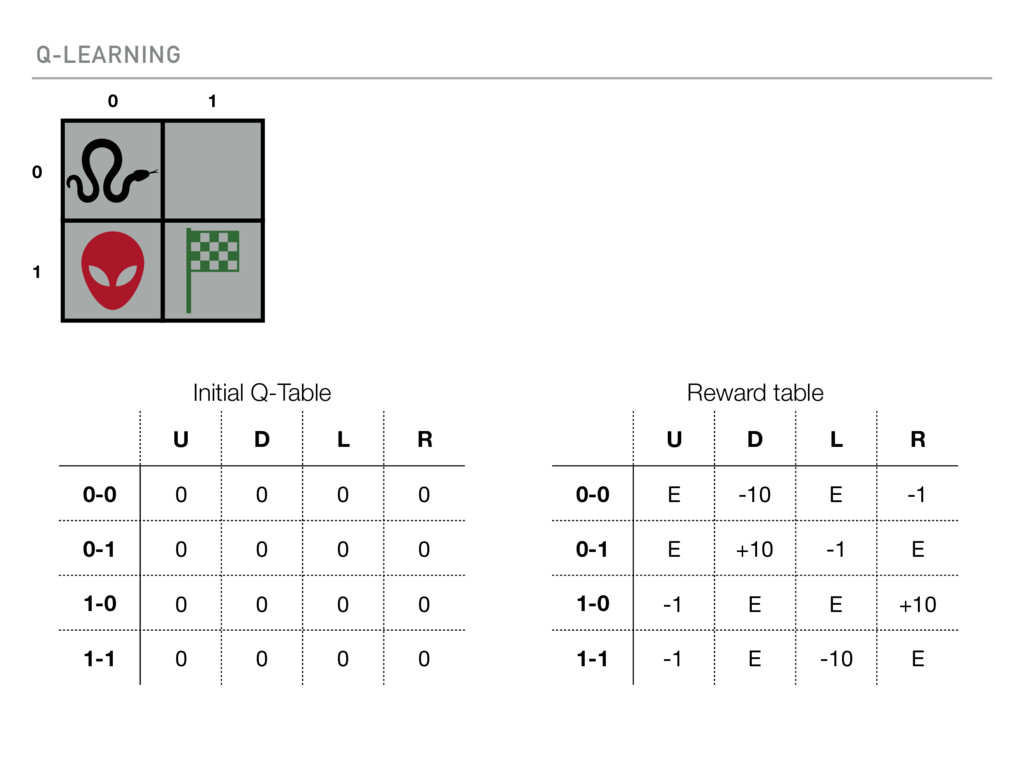{kind=link}
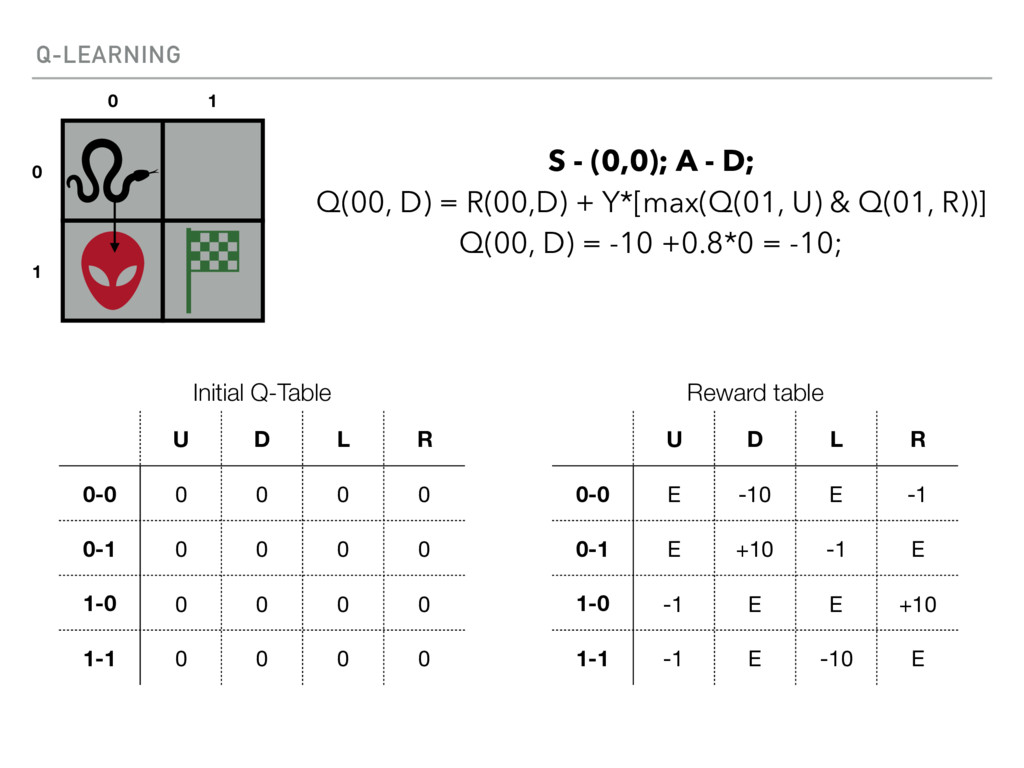{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}