Diffusion Models for Subject-Driven Generation, CVPR, 2023 2. Omri Avrahami et. al., Blended Diffusion for Text-driven Editing of Natural Images, CVPR, 2022 3. Zonghui Guo et. al., Intrinsic Image Harmonization, CVPR, 2021 4. Bor-Chun Chen and Andrew Kae, Toward Realistic Image Compositing with Adversarial Learning, CVPR, 2019 5. Yujun Shen and Bolei Zhou, Closed-Form Factorization of Latent Semantics in GANs, CVPR, 2021 6. Jooyoung Choi et. al., ILVR: Conditioning Method for Denoising Diffusion Probabilistic Models, ICCV, 2021. 7. Bahjat Kawar et. al., Imagic: Text-Based Real Image Editing with Diffusion Models, CVPR, 2023 8. Amir Hertz et. al., Prompt-to-Prompt Image Editing with Cross Attention Control, ArXiv, 2022 9. Alec Radford et. al., Learning Transferable Visual Models From Natural Language Supervision, 10. Robin Rombach et. al., High-Resolution Image Synthesis with Latent Diffusion Models, CVPR, 2022 11. Jonathan Ho & Tim Salimans, CLASSIFIER-FREE DIFFUSION GUIDANCE, NeurIPS, 2021 12. Ben Xue et. al., DCCF: Deep Comprehensible Color Filter Learning Framework for High-Resolution Image Harmonization, ECCV, 2022. 13. Roman Suvorov et. Al., Resolution-robust large mask inpainting with fourier convolutions, ICCV, 2022 14. Xin Zhang et. al., PASTE, INPAINT AND HARMONIZE VIA DENOISING: SUBJECT-DRIVEN IMAGE EDITING WITH PRE-TRAINED DIFFUSION MODEL, ArXiv, 2023. 15. Junhong Gou et. al., Taming the Power of Diffusion Models for High-Quality Virtual Try-On with Appearance Flow, MM, 2023 32
{kind=link}
![Background Text-based conditionで編集するモデルでは、 (手元にある)参照したい画像の情報を完全に反映することはできない (全ての特徴を詳細に述べること/生成に反映すること は難しい) Dreambooth[1] (CVPR’23) Text driven](https://files.speakerdeck.com/presentations/2f2962d99ce64d6eaac1a1bd4207a7a4/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Related work : Semantic image editing GANの潜在空間のdisentanglement[5] Iterativeにreference画像の特徴を取り込む (ILVR[6]) 7](https://files.speakerdeck.com/presentations/2f2962d99ce64d6eaac1a1bd4207a7a4/slide_6.jpg){kind=link}
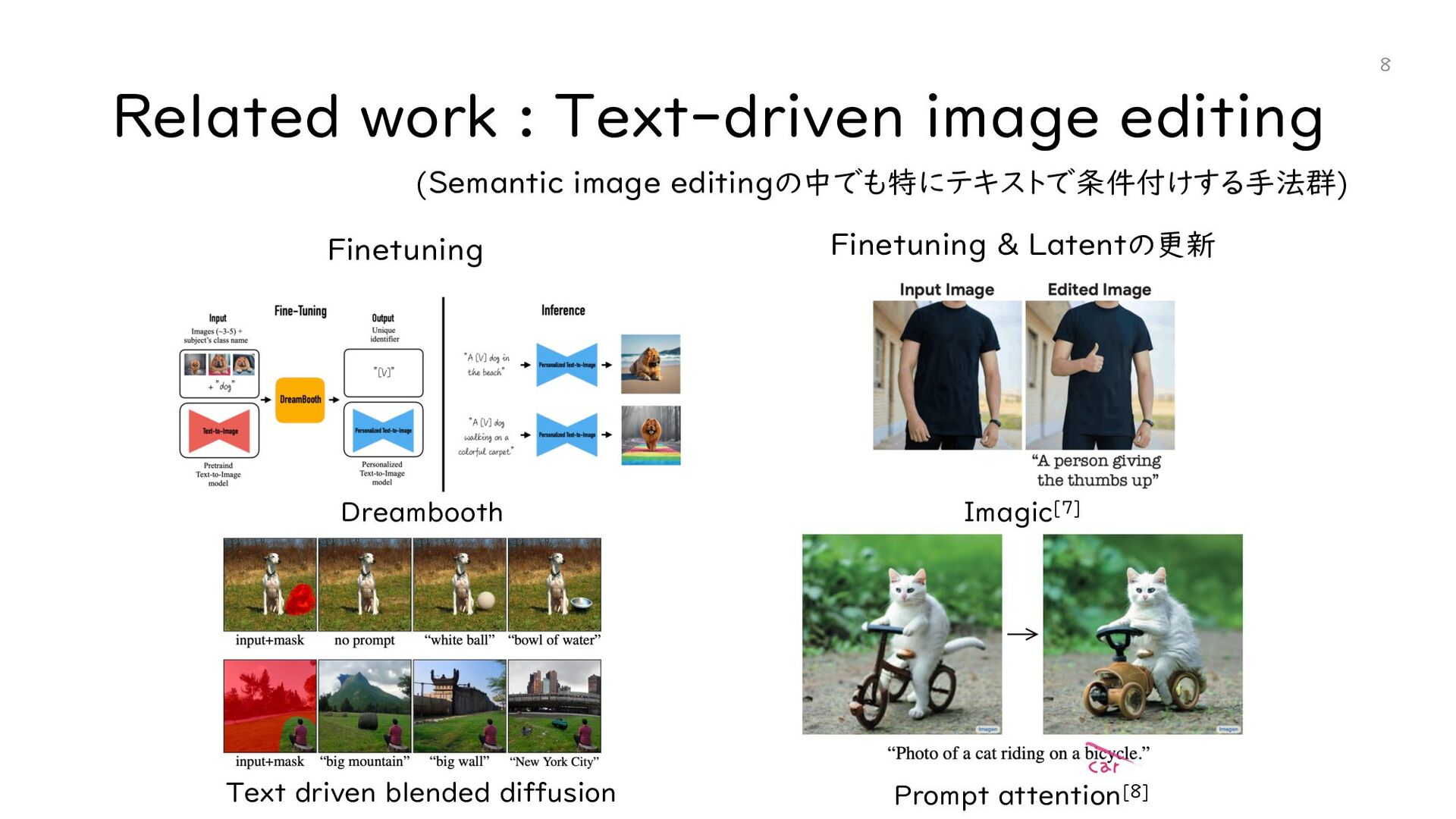{kind=link}
![Preliminaries : CLIP[9] • 大量の画像/テキストのペアで contrastive learningを行い 画像・テキストを同じ特徴空間に埋め込む • Text](https://files.speakerdeck.com/presentations/2f2962d99ce64d6eaac1a1bd4207a7a4/slide_8.jpg){kind=link}
![Preliminaries : Stable diffusion • Latent-diffusion model[10]を採用した テキストベース画像生成モデル • TextをCLIP](https://files.speakerdeck.com/presentations/2f2962d99ce64d6eaac1a1bd4207a7a4/slide_9.jpg){kind=link}
{kind=link}
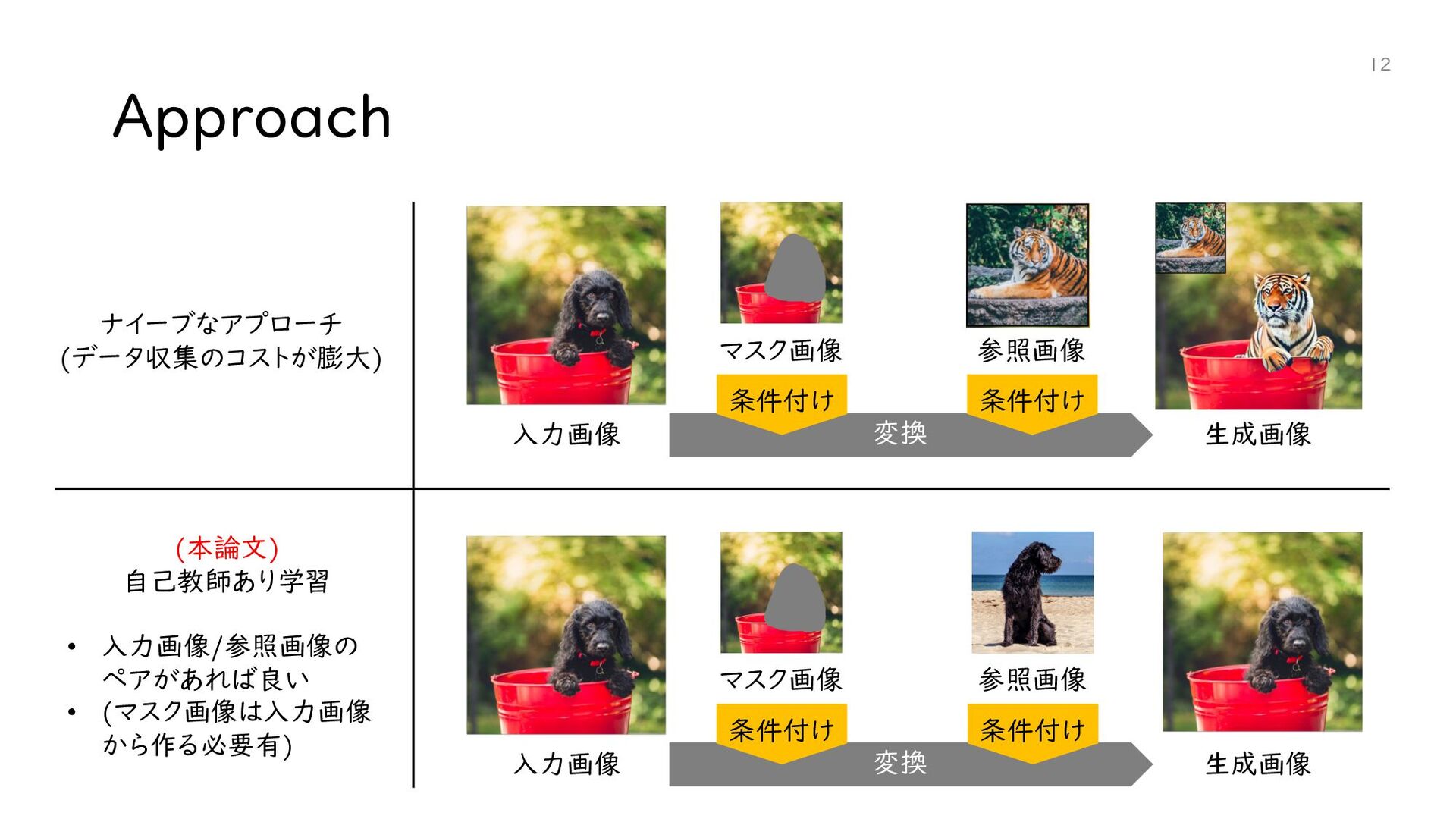{kind=link}
{kind=link}
{kind=link}
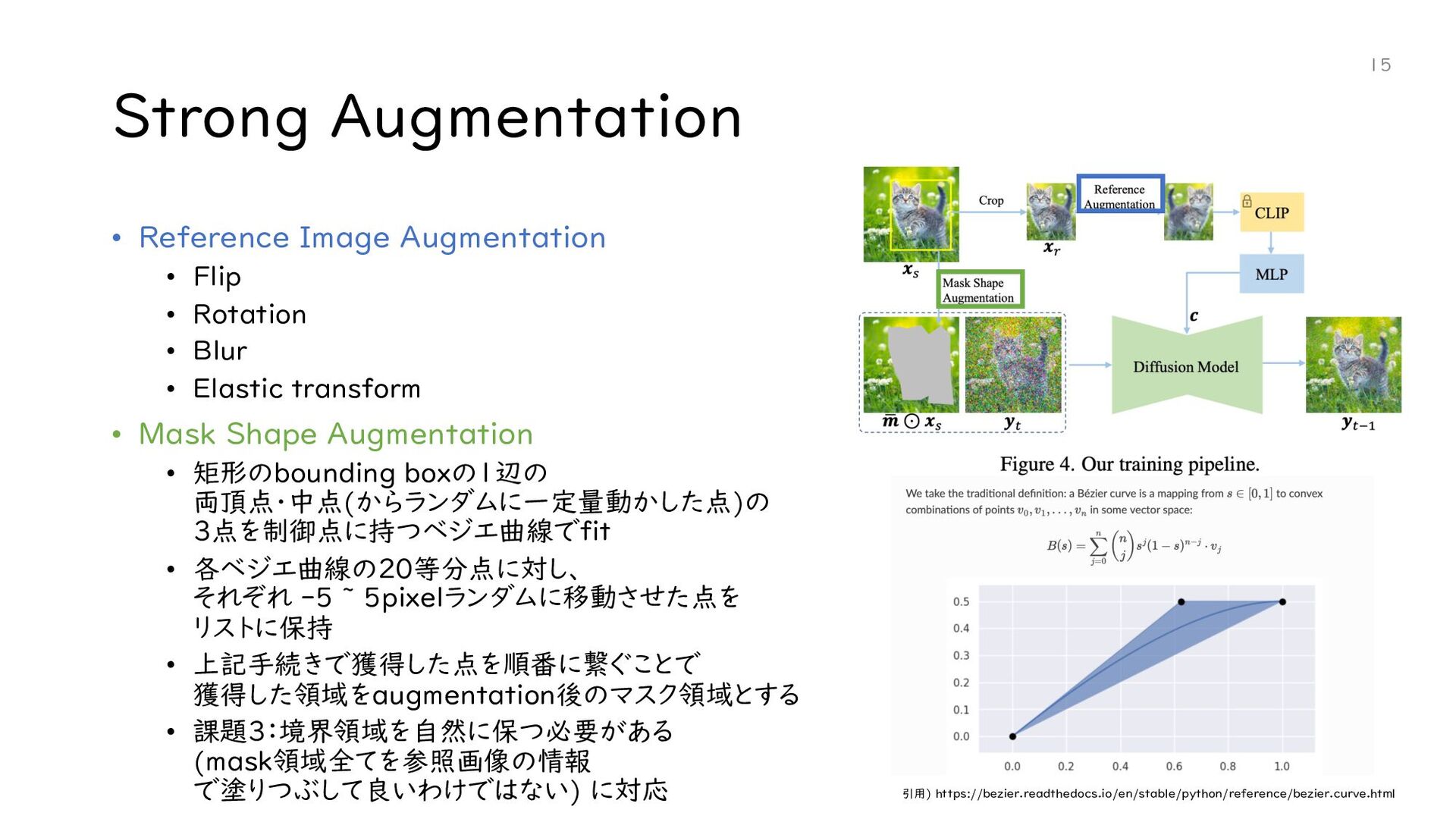{kind=link}
![Classifier-free sampling[11] 𝑠: guidance scale 生成画像にconditionの情報の反映具合を調整するための方法 • 学習時 : 一定の確率(数値実験では20%)](https://files.speakerdeck.com/presentations/2f2962d99ce64d6eaac1a1bd4207a7a4/slide_15.jpg){kind=link}
{kind=link}
![Baselines • Blended Diffusion[2] • CLIP lossに基づいたguidanceを行う方法 • “a photo](https://files.speakerdeck.com/presentations/2f2962d99ce64d6eaac1a1bd4207a7a4/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
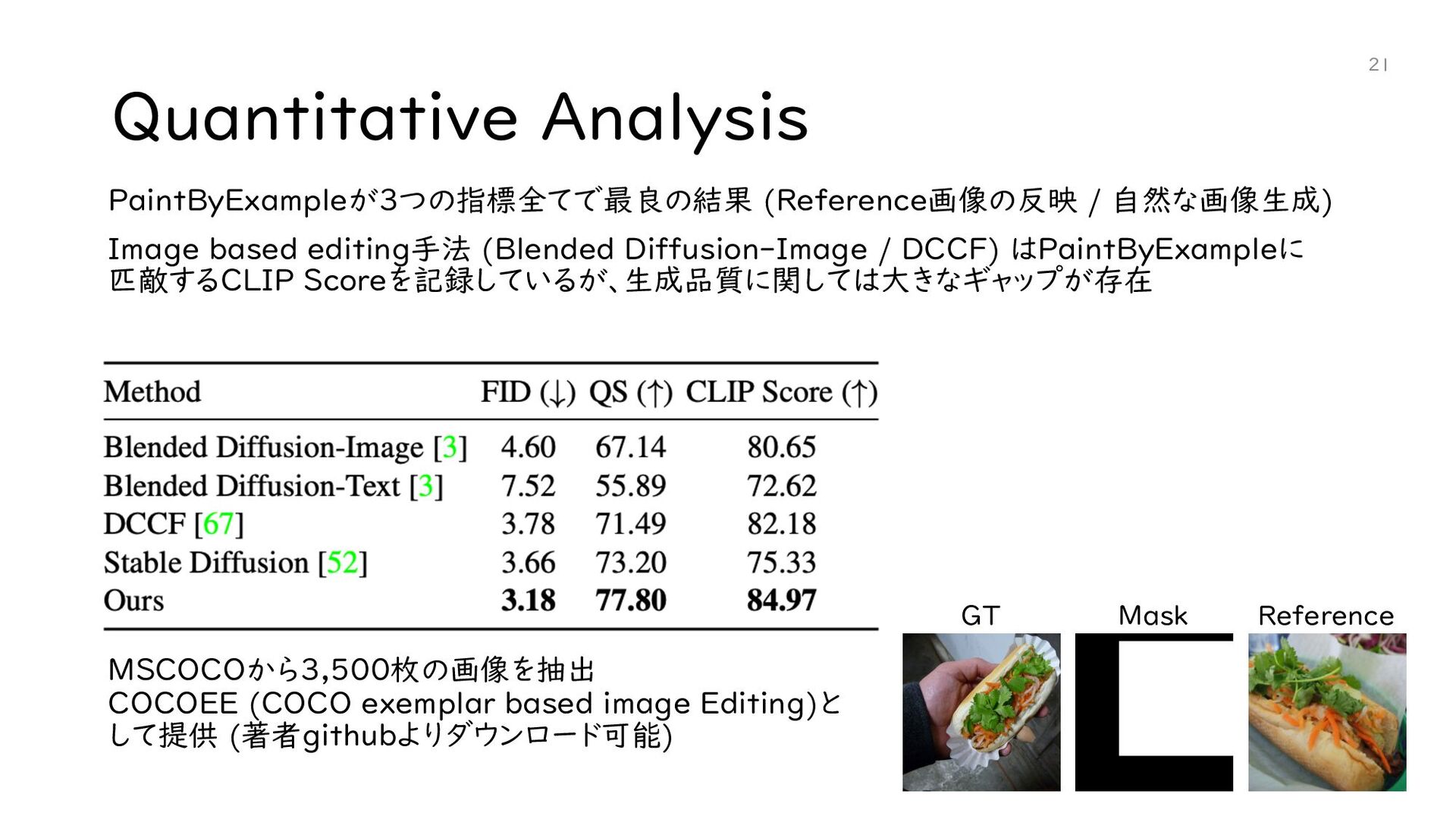{kind=link}
{kind=link}
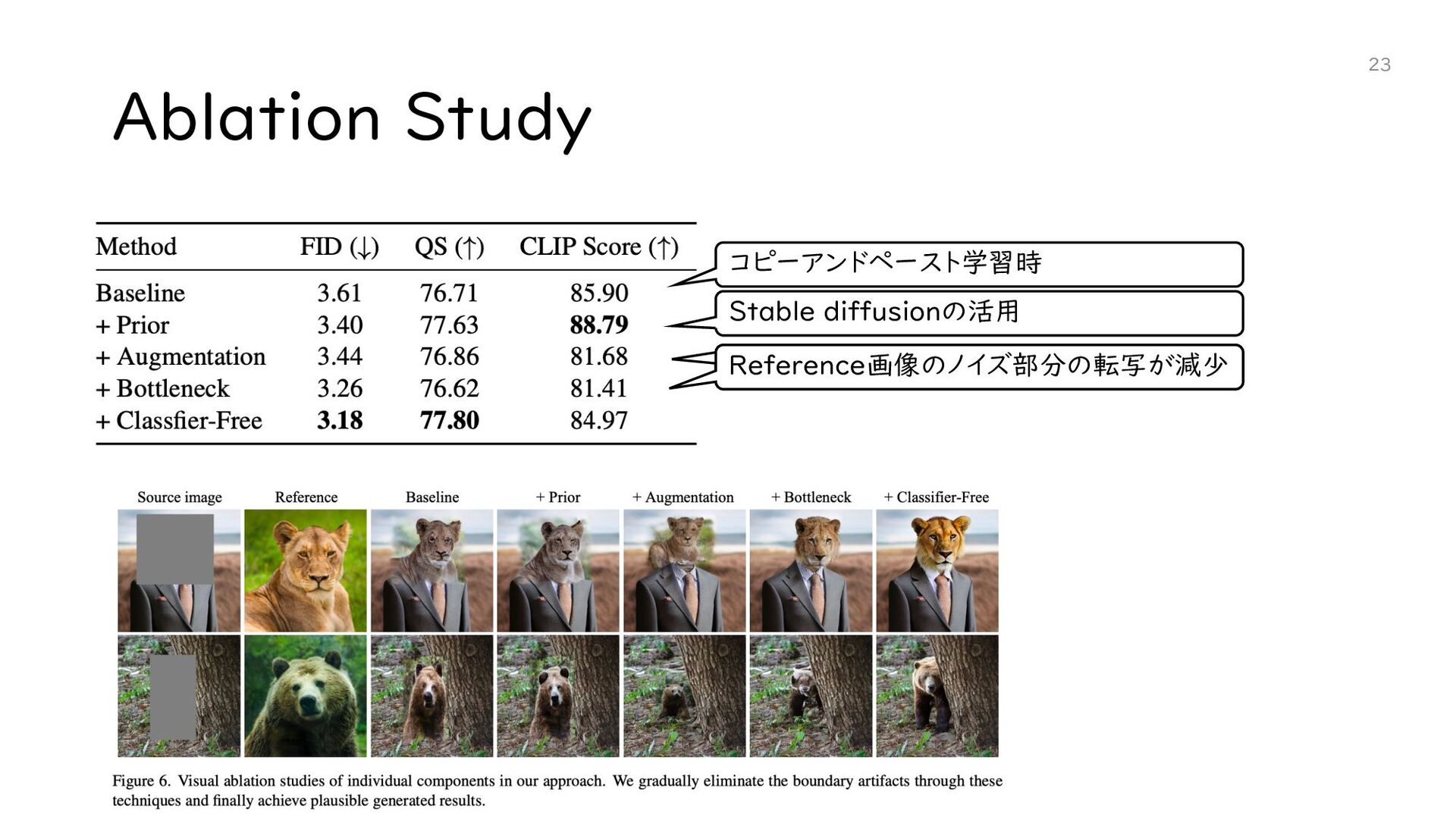{kind=link}
{kind=link}
{kind=link}
{kind=link}
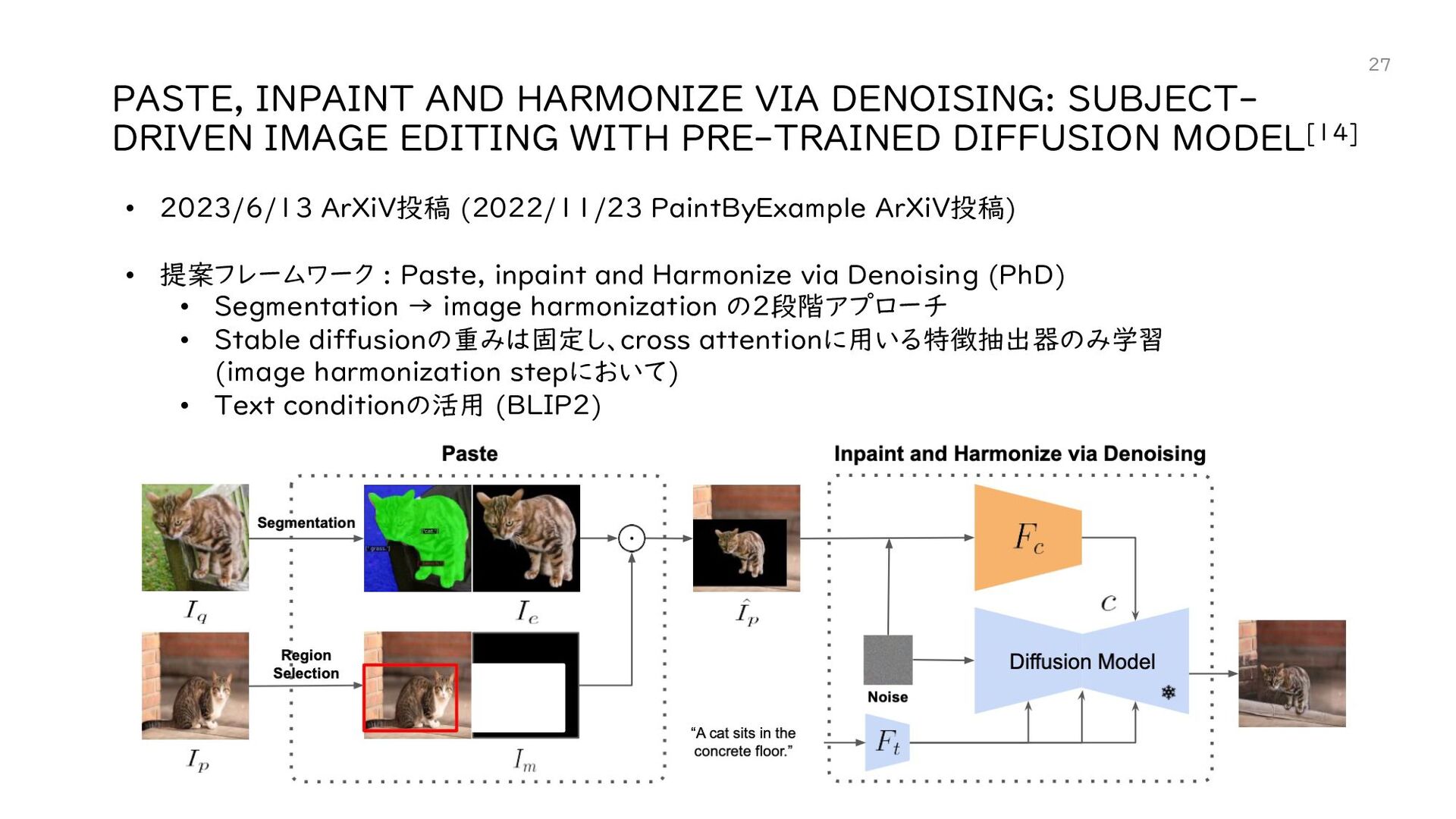{kind=link}
{kind=link}
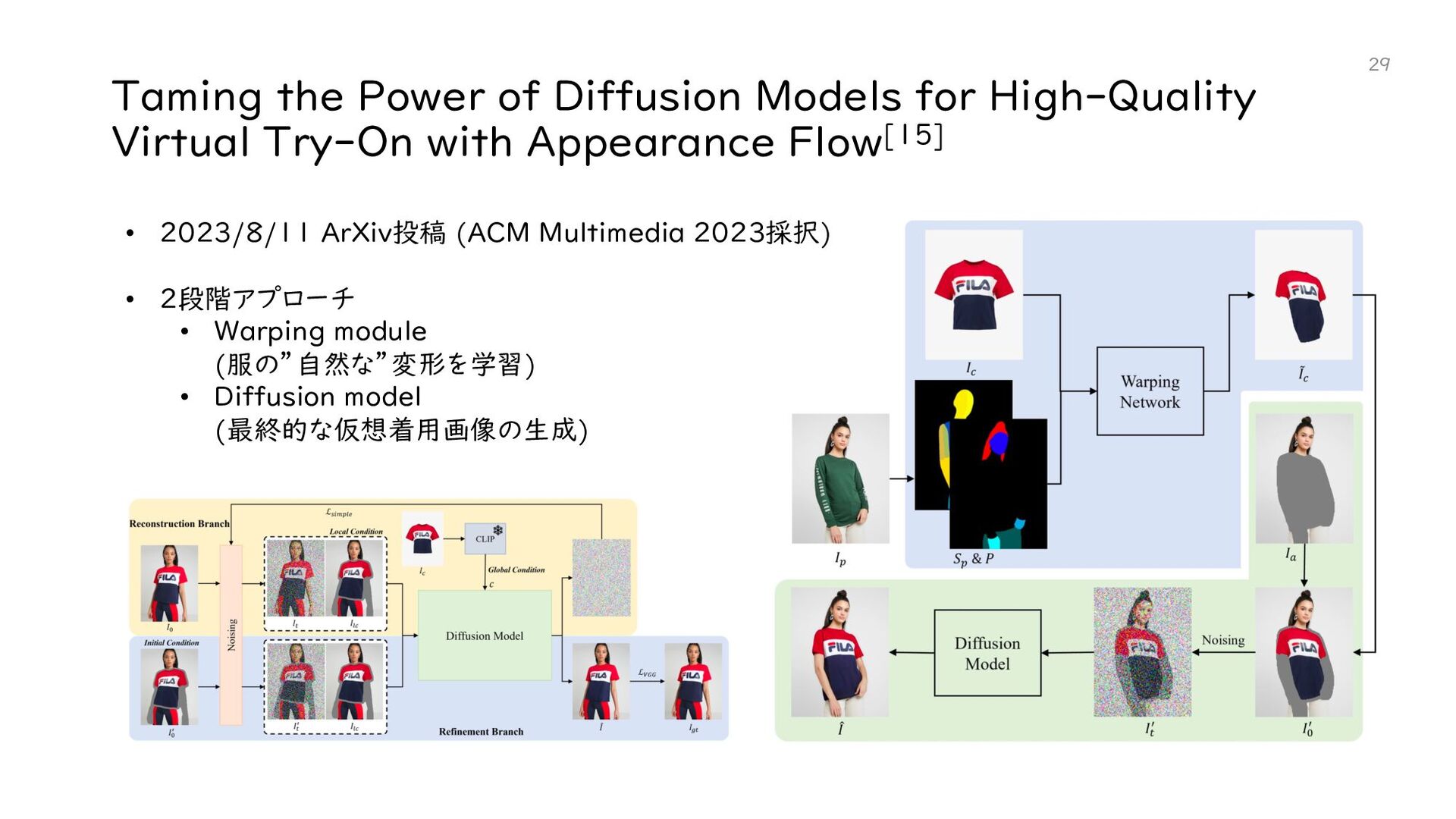{kind=link}
{kind=link}
{kind=link}
{kind=link}