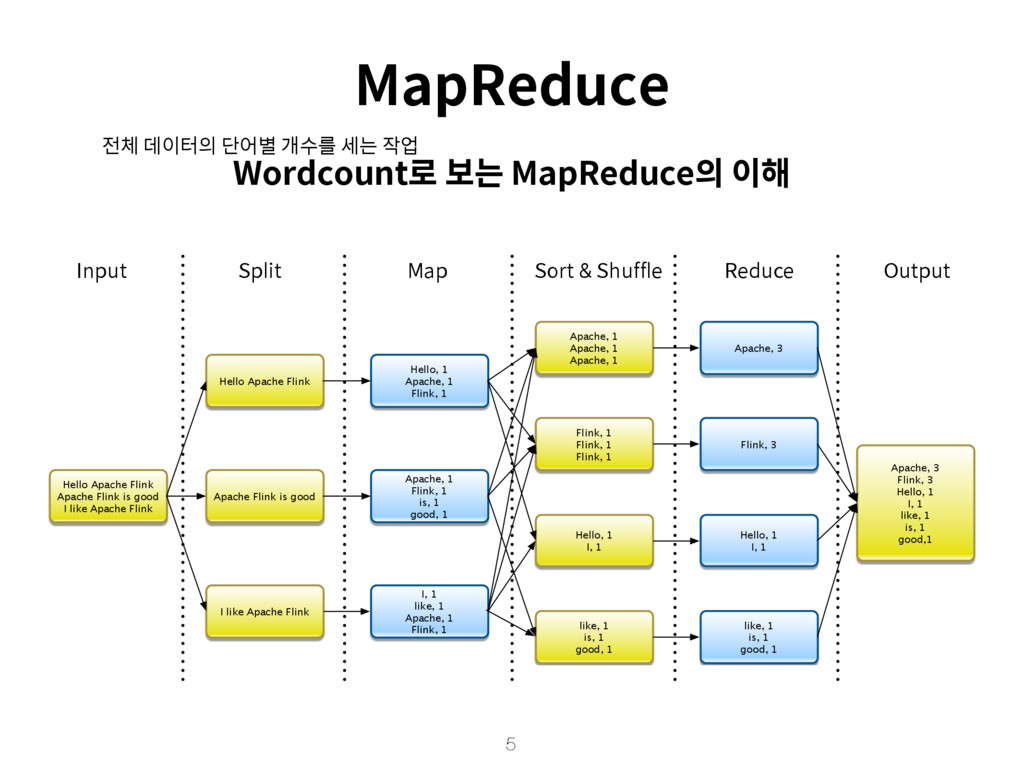
세는 작업 Hello Apache Flink Apache Flink is good I like Apache Flink Hello, 1 Apache, 1 Flink, 1 Apache, 1 Flink, 1 is, 1 good, 1 I, 1 like, 1 Apache, 1 Flink, 1 Apache, 1 Apache, 1 Apache, 1 Flink, 1 Flink, 1 Flink, 1 Hello, 1 I, 1 like, 1 is, 1 good, 1 Hello Apache Flink Apache Flink is good I like Apache Flink Apache, 3 Flink, 3 Hello, 1 I, 1 like, 1 is, 1 good, 1 Apache, 3 Flink, 3 Hello, 1 I, 1 like, 1 is, 1 good,1 Input Split Map Sort & Shuffle Reduce Output
![Introduction to Apache Flink 2015. 12. 22. 박치완 <[email protected]>](https://files.speakerdeck.com/presentations/33efb9ae8a8c402da9f9ea4b9595bdac/slide_0.jpg){kind=link}
![2 발표자 소개 박치완 <[email protected]> 대용량 데이터 처리에 관심이 많은](https://files.speakerdeck.com/presentations/33efb9ae8a8c402da9f9ea4b9595bdac/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
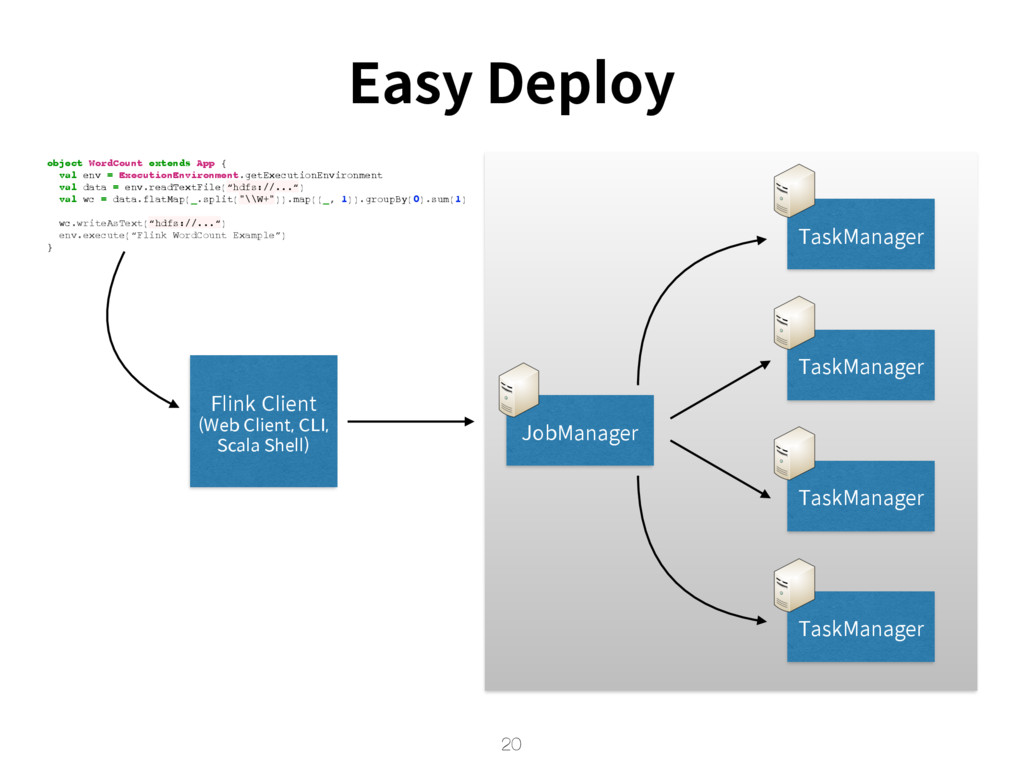{kind=link}
{kind=link}
{kind=link}
{kind=link}
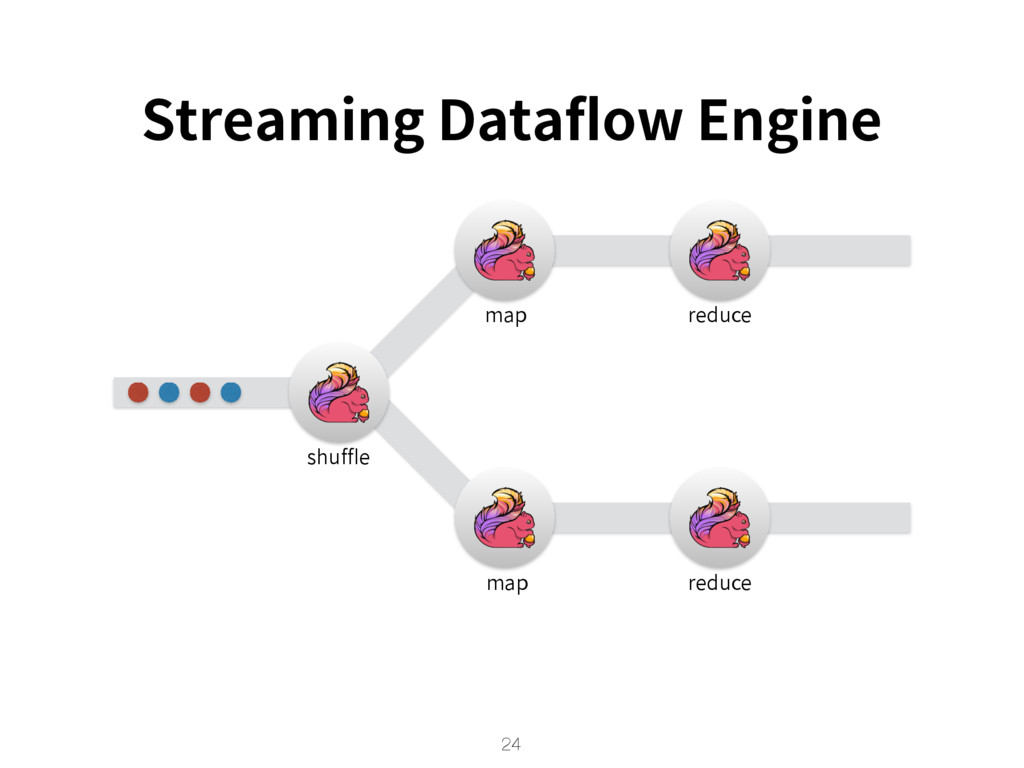{kind=link}
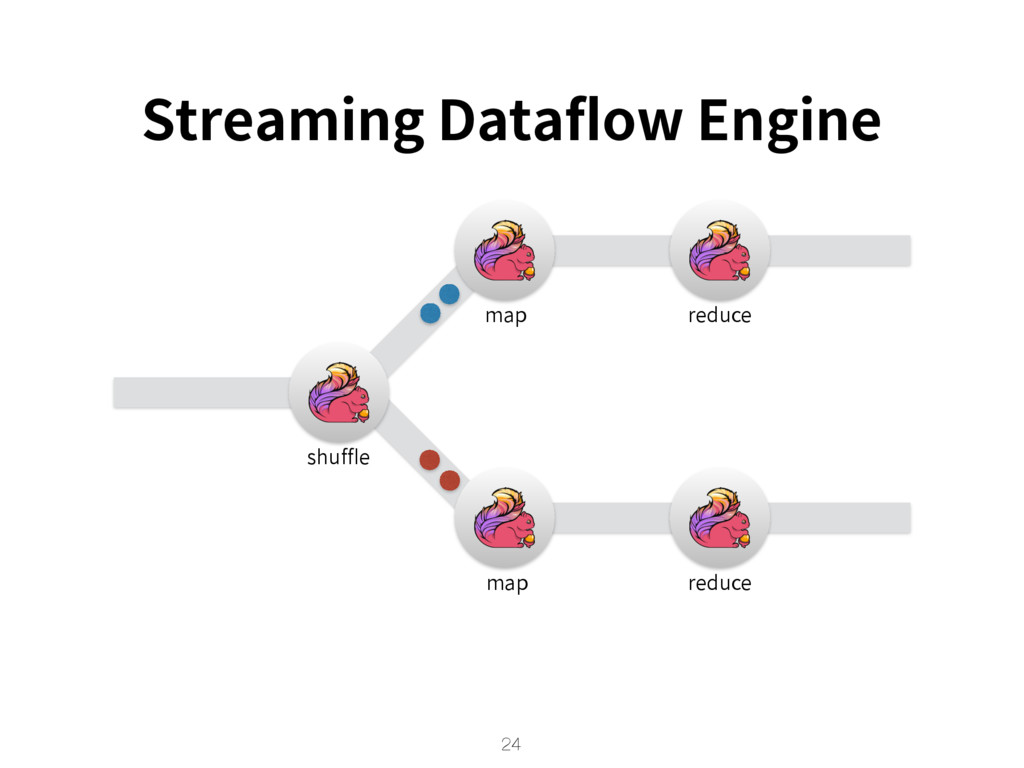{kind=link}
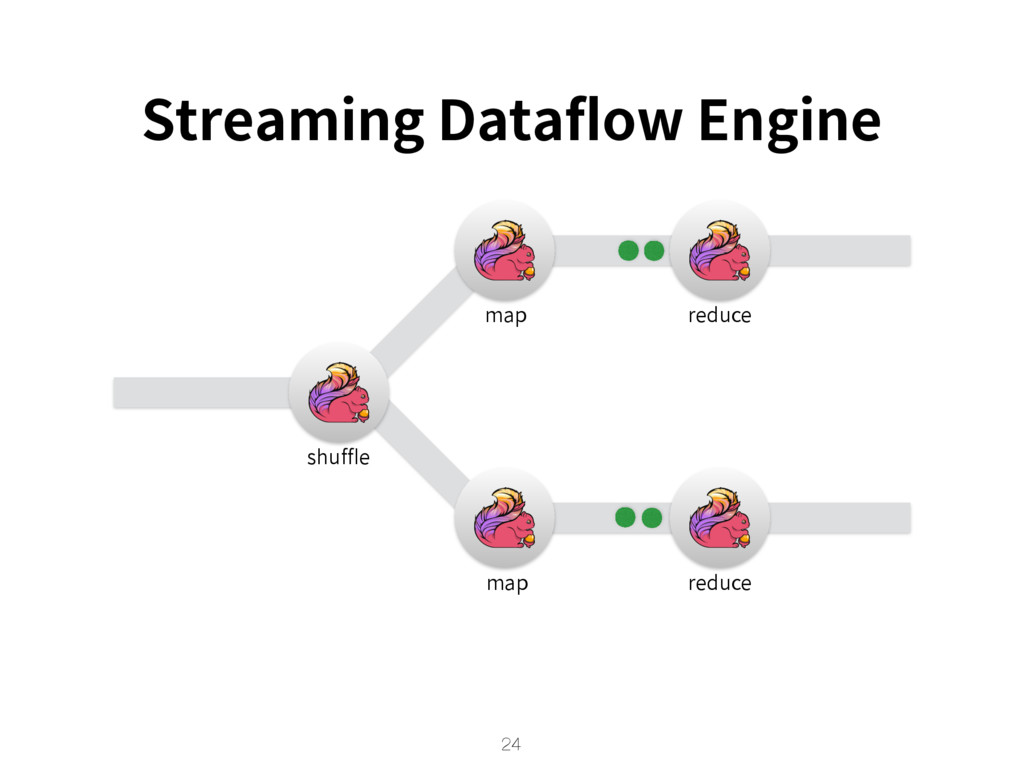{kind=link}
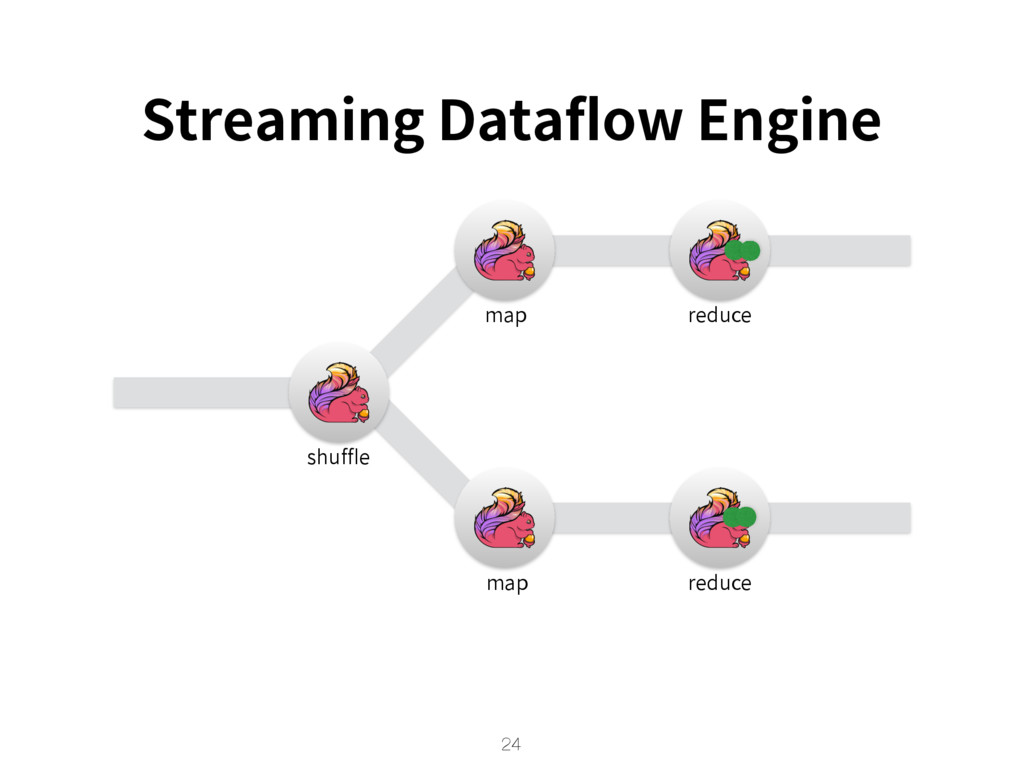{kind=link}
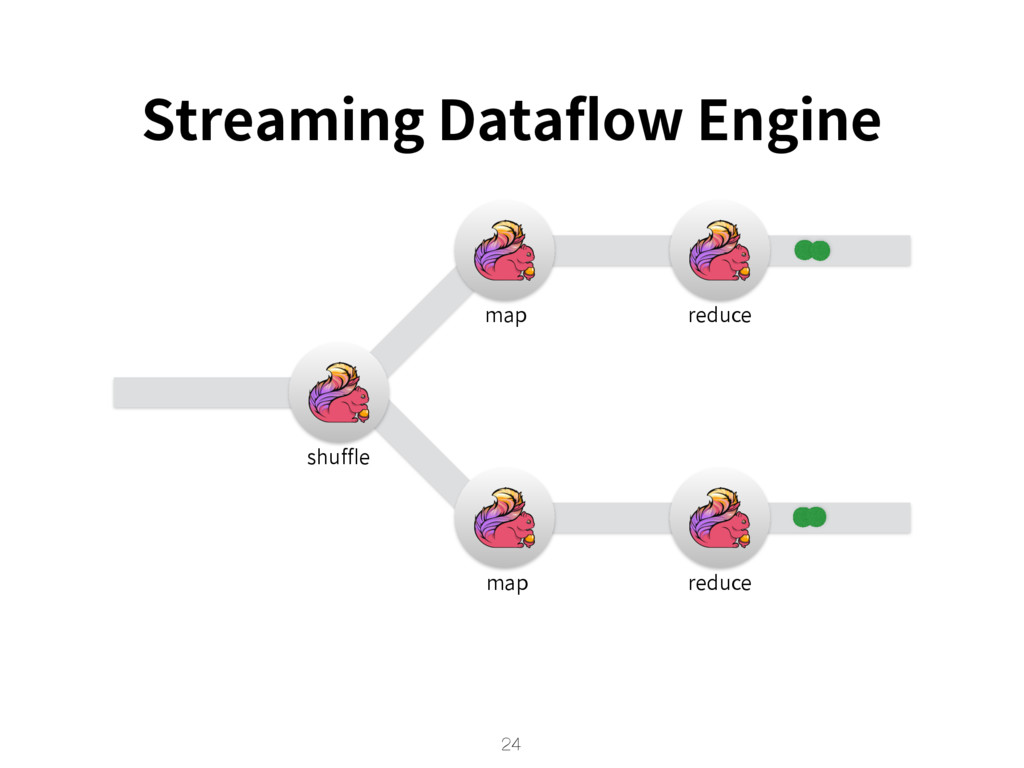{kind=link}
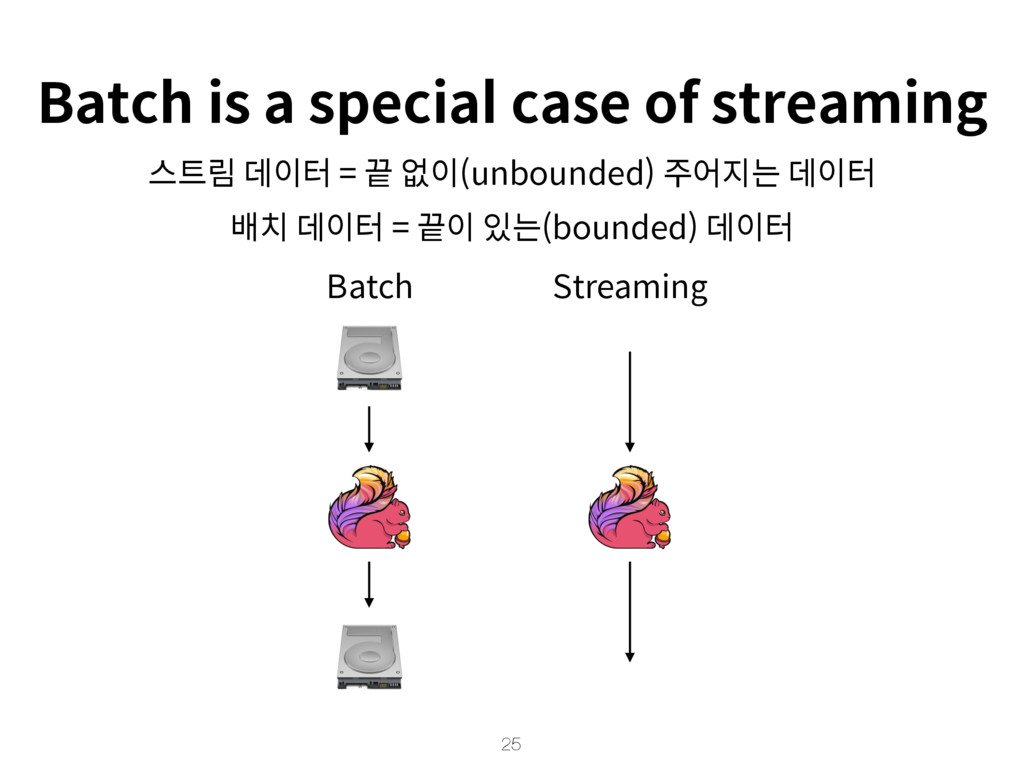{kind=link}
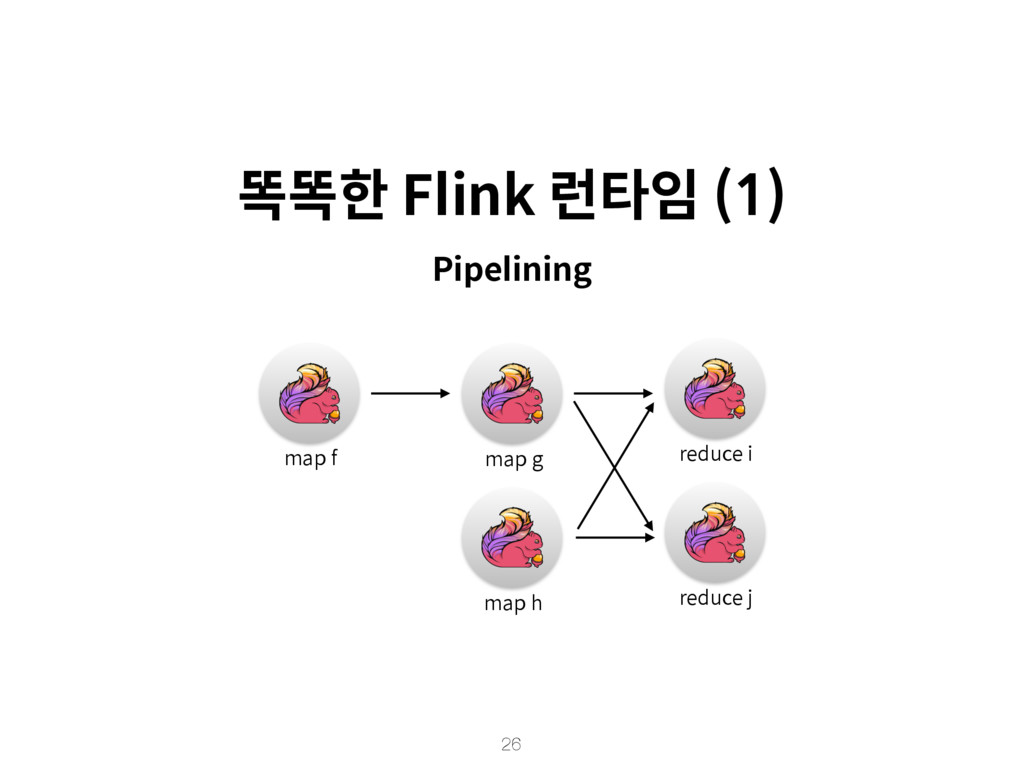{kind=link}
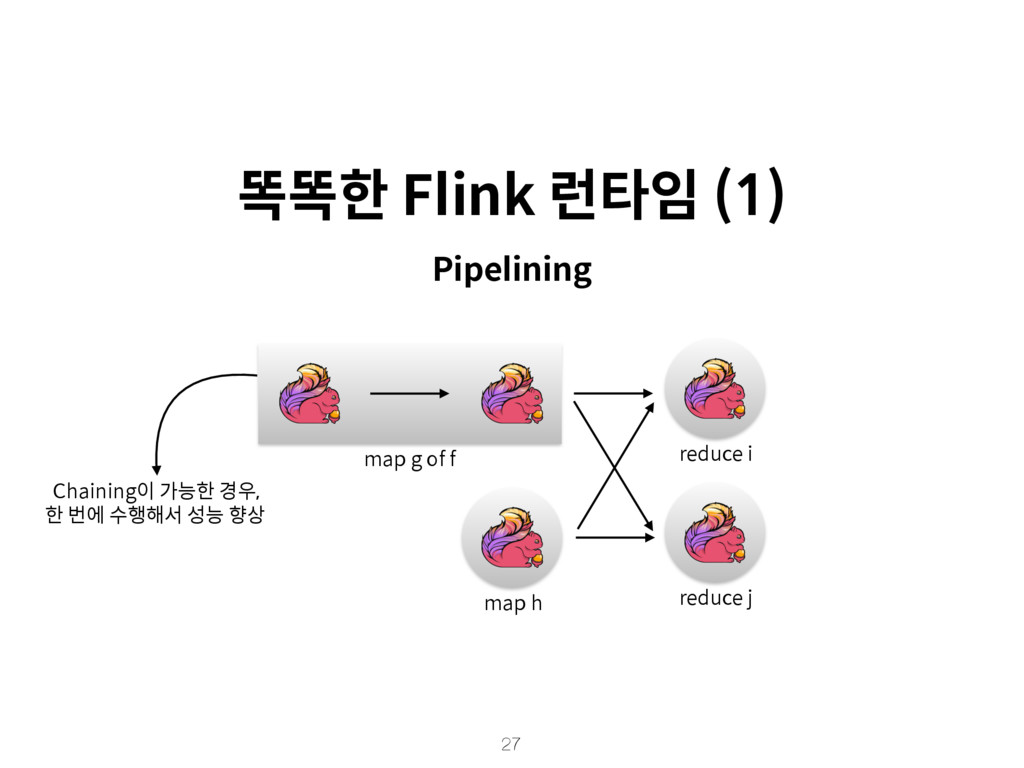{kind=link}
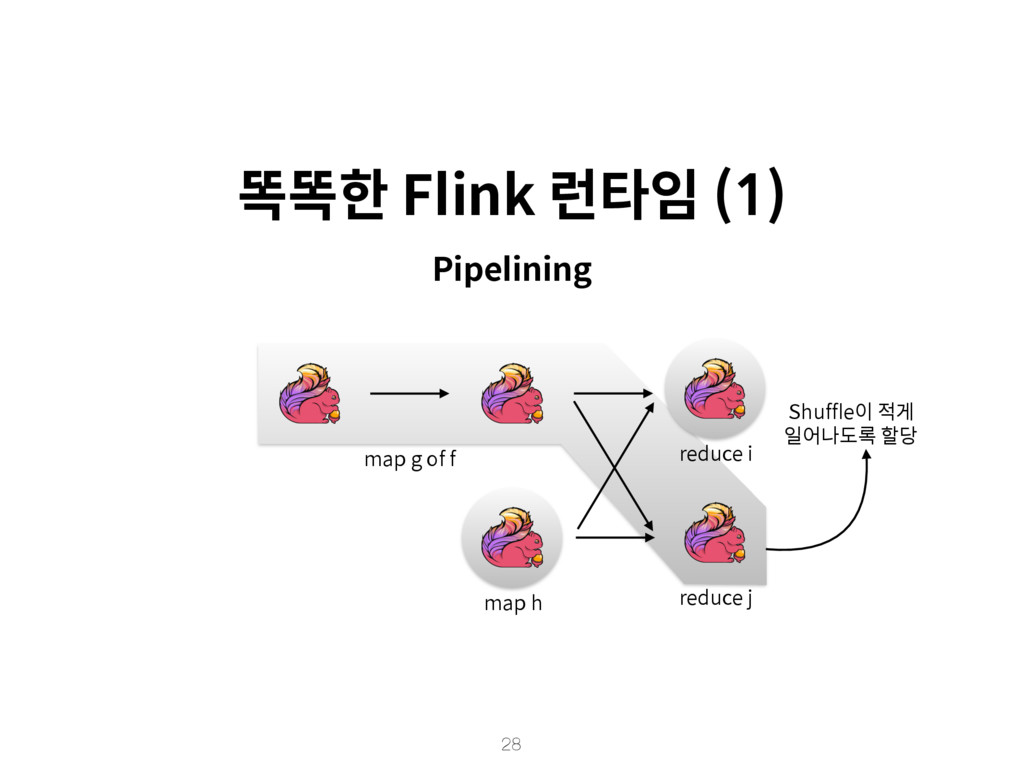{kind=link}
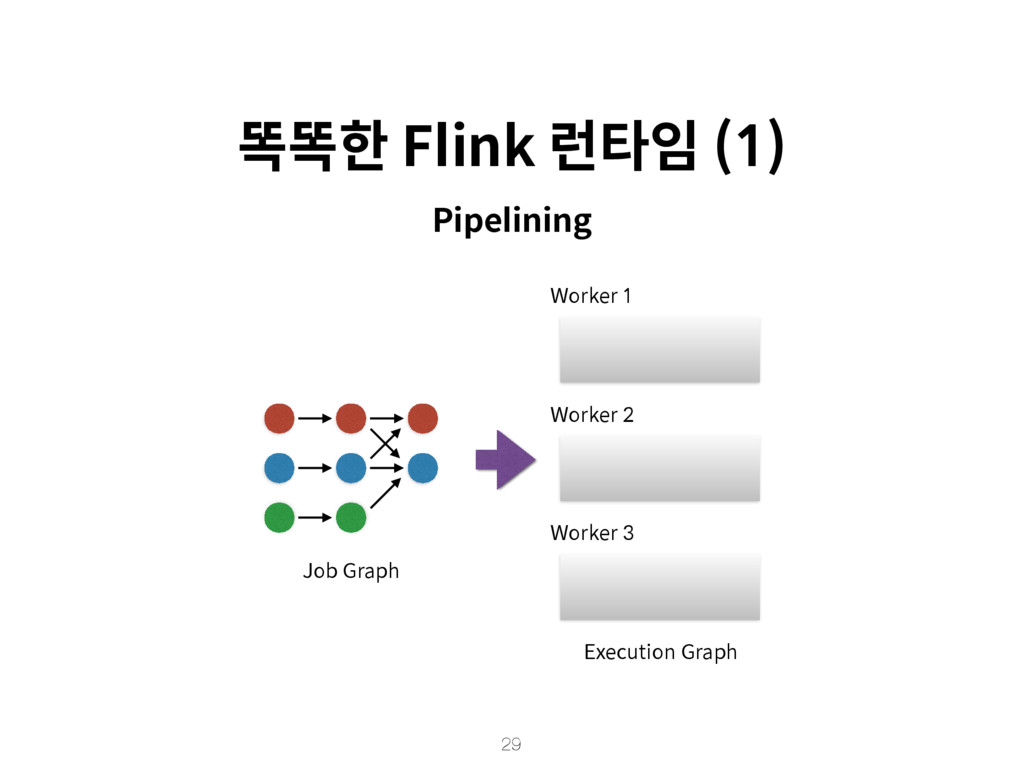{kind=link}
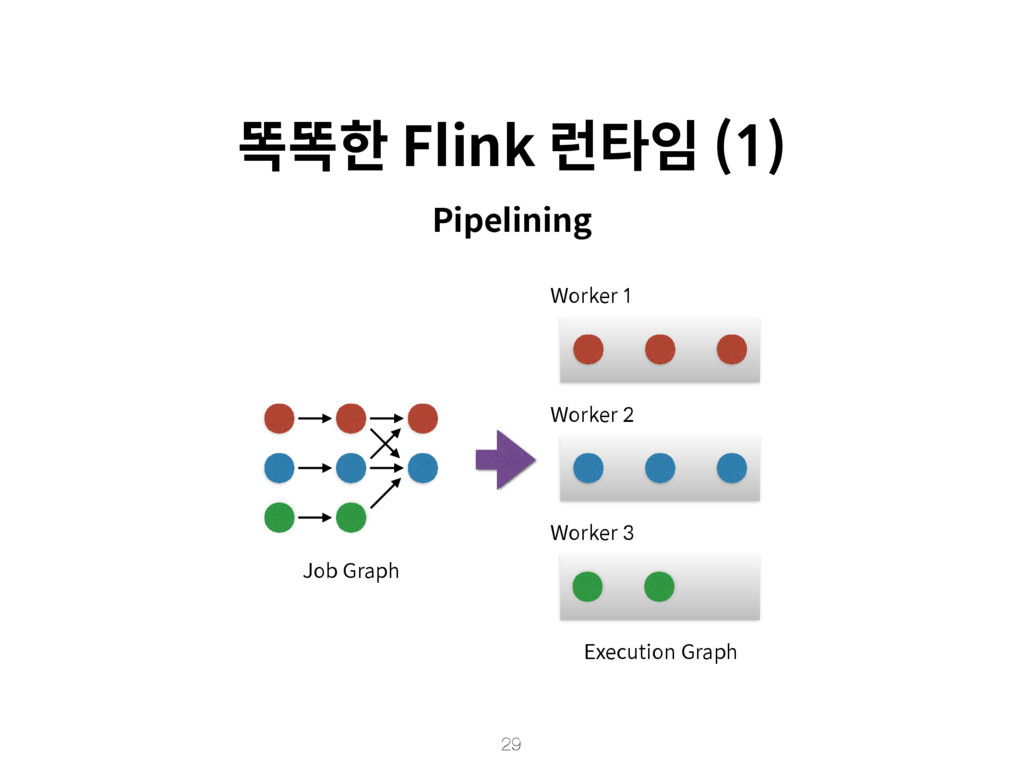{kind=link}
{kind=link}
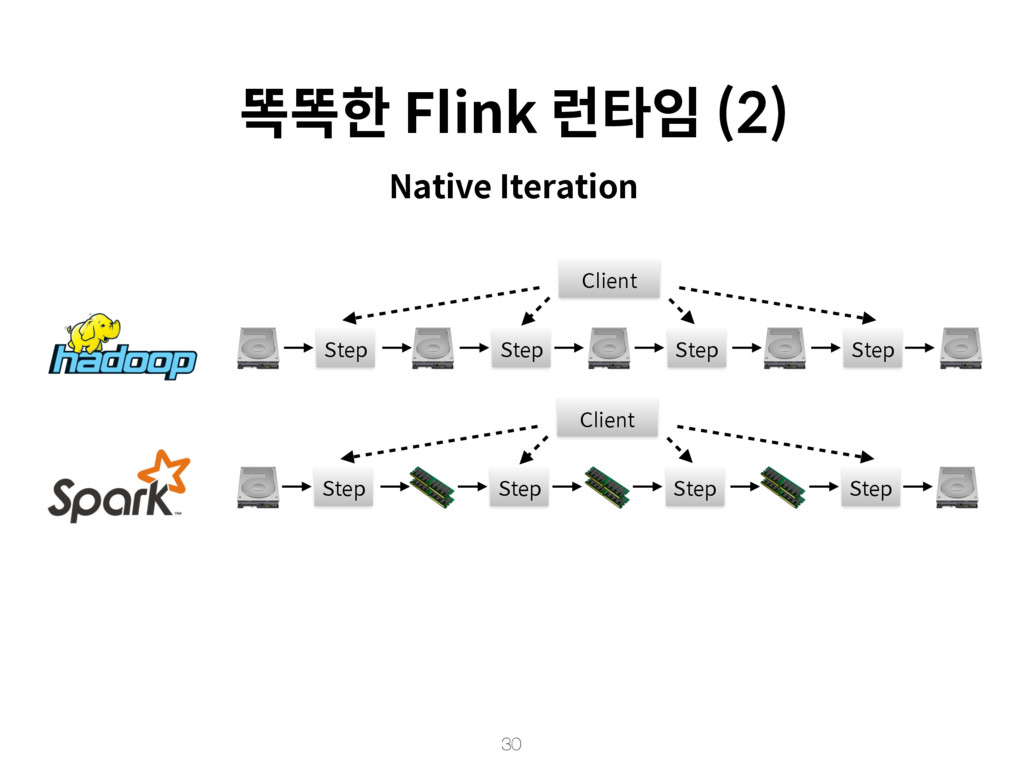{kind=link}
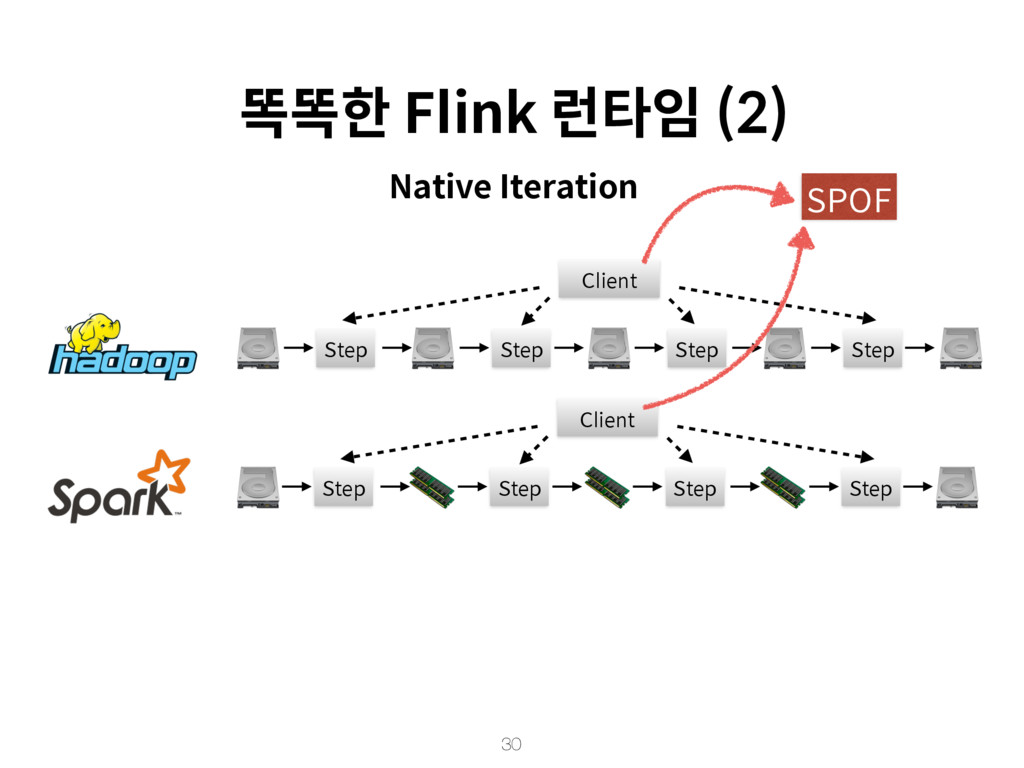{kind=link}
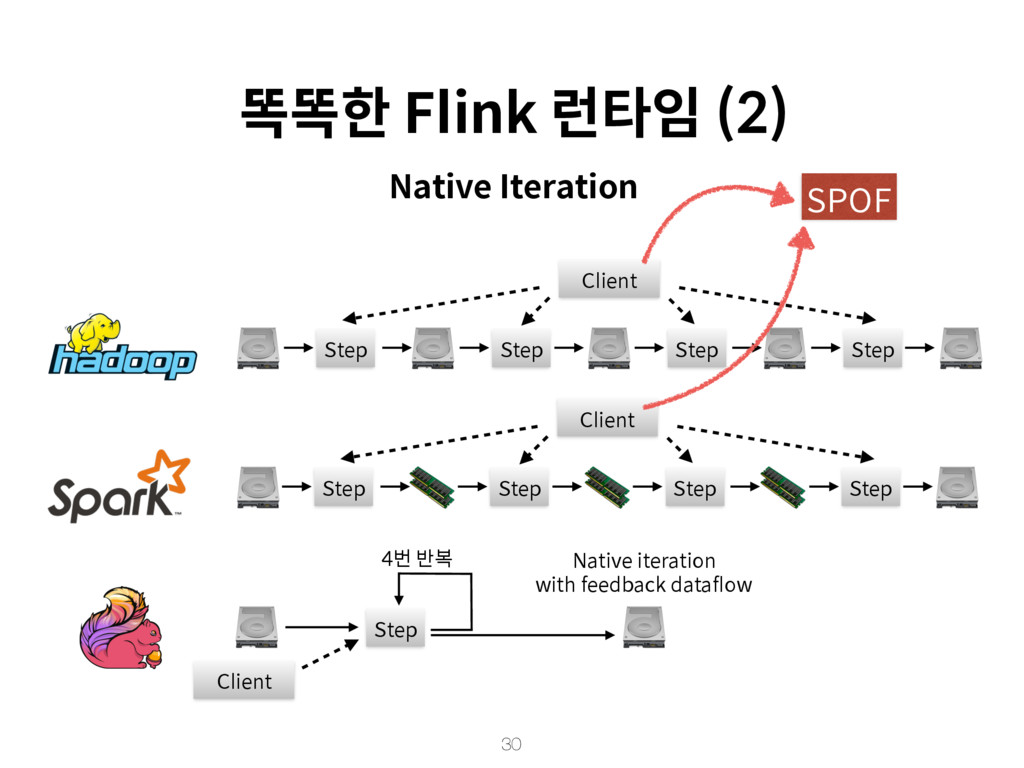{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
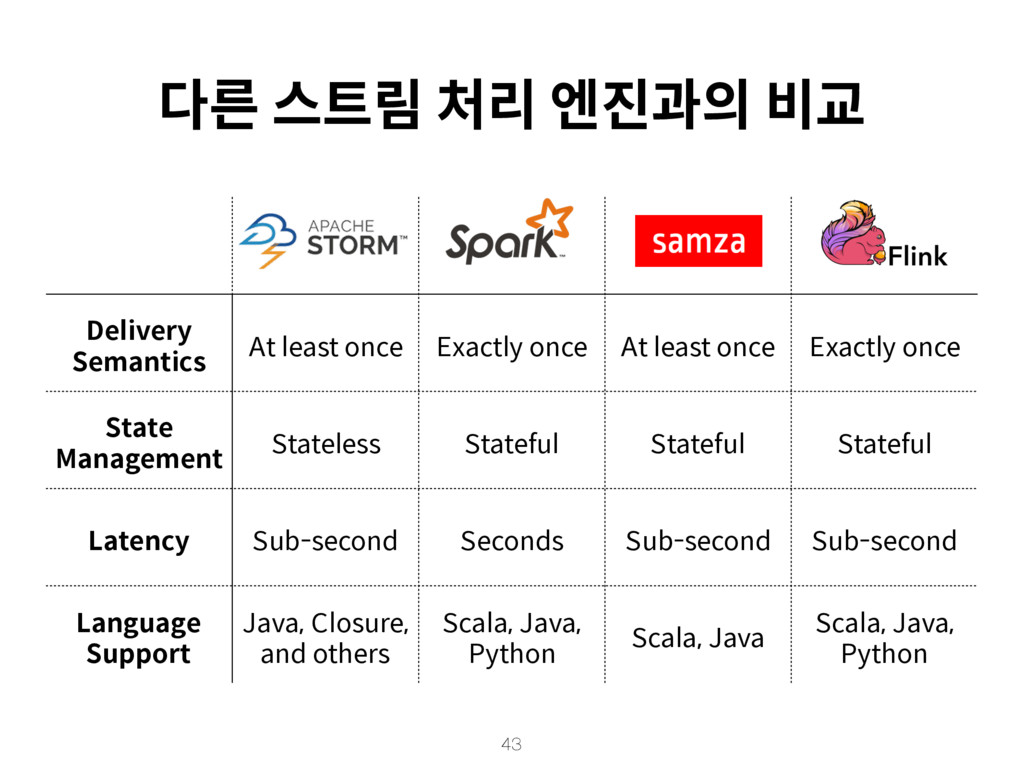{kind=link}
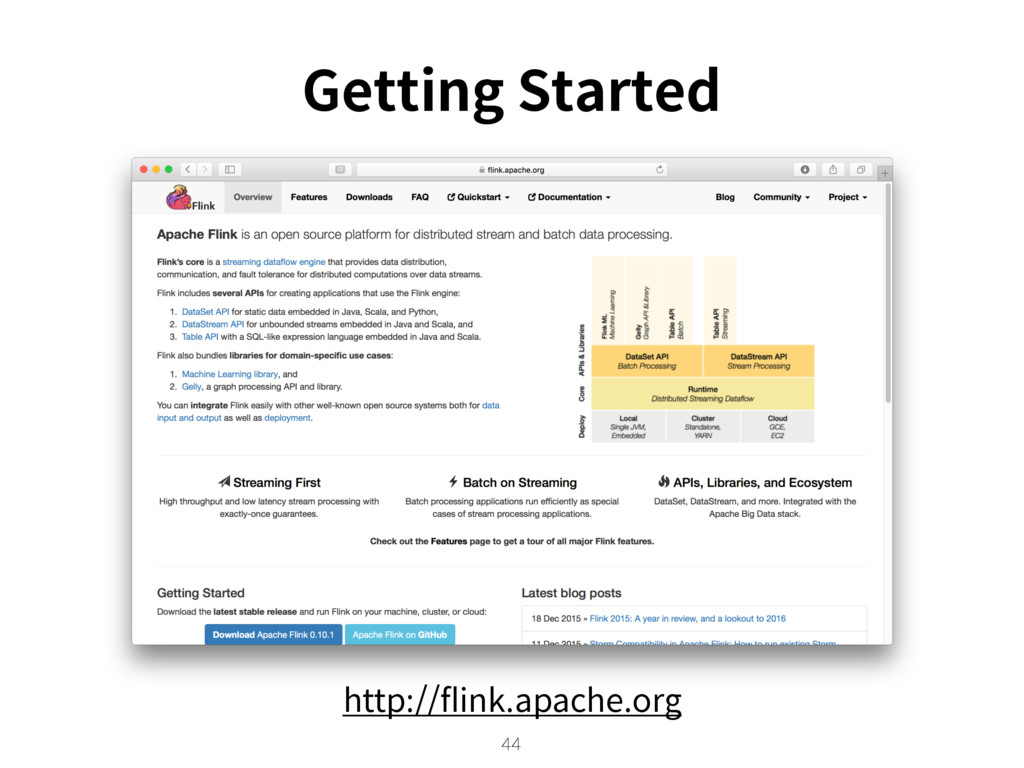{kind=link}
{kind=link}