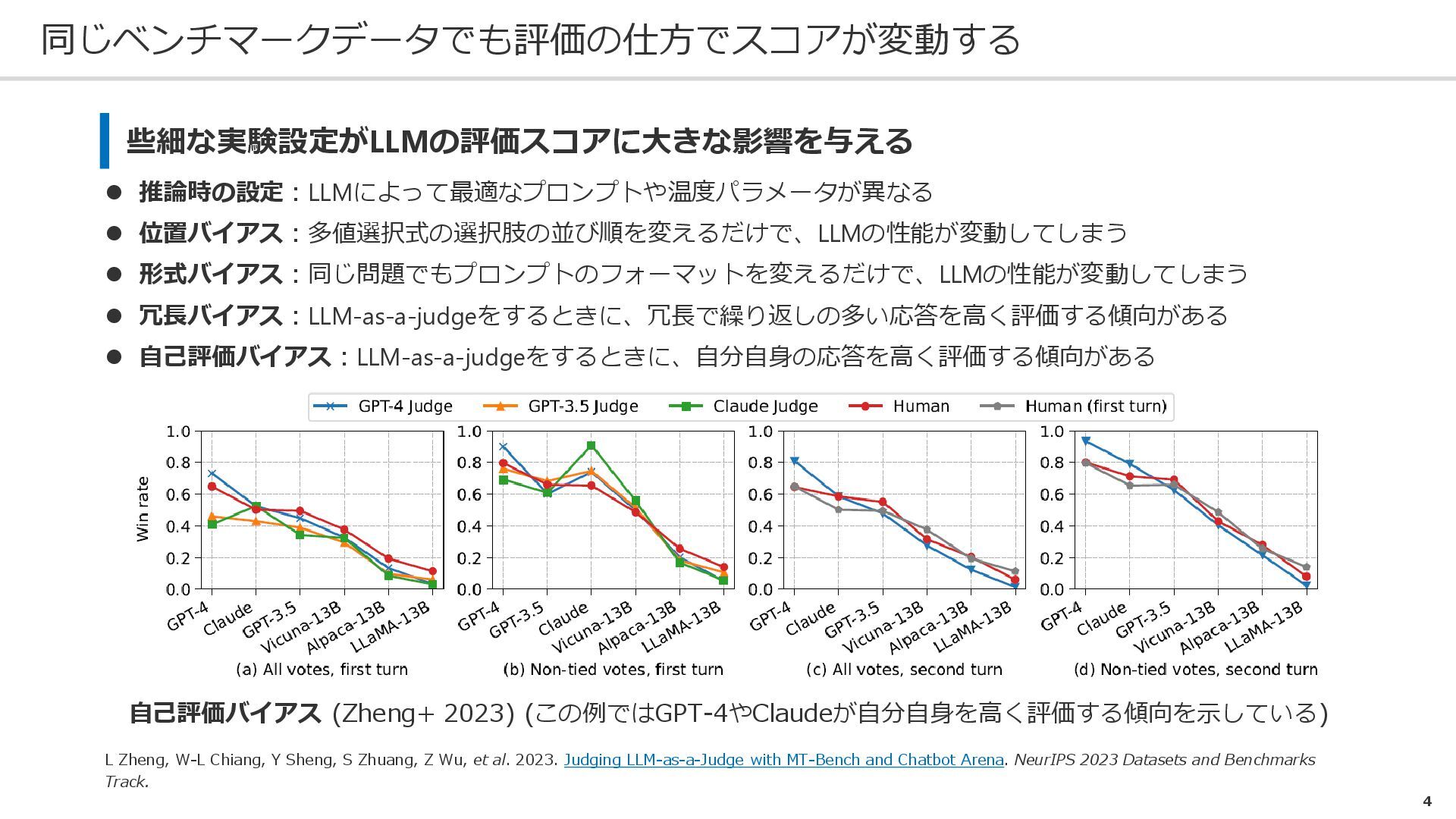
自己評価バイアス:LLM-as-a-judgeをするときに、自分自身の応答を高く評価する傾向がある 自己評価バイアス (Zheng+ 2023) (この例ではGPT-4やClaudeが自分自身を高く評価する傾向を示している) L Zheng, W-L Chiang, Y Sheng, S Zhuang, Z Wu, et al. 2023. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. NeurIPS 2023 Datasets and Benchmarks Track. 4
L Hou, A C Stickland, J Petty, R Y Pang, J Dirani, J Michael, S R Bowman. 2024. GPQA: A Graduate-Level Google-Proof Q&A Benchmark. Conference on Language Modeling (COLM). [2] OpenAIが公開しているsimple-evalsとLlama 3.3 70B Instructのリリースノートを基にグラフ化
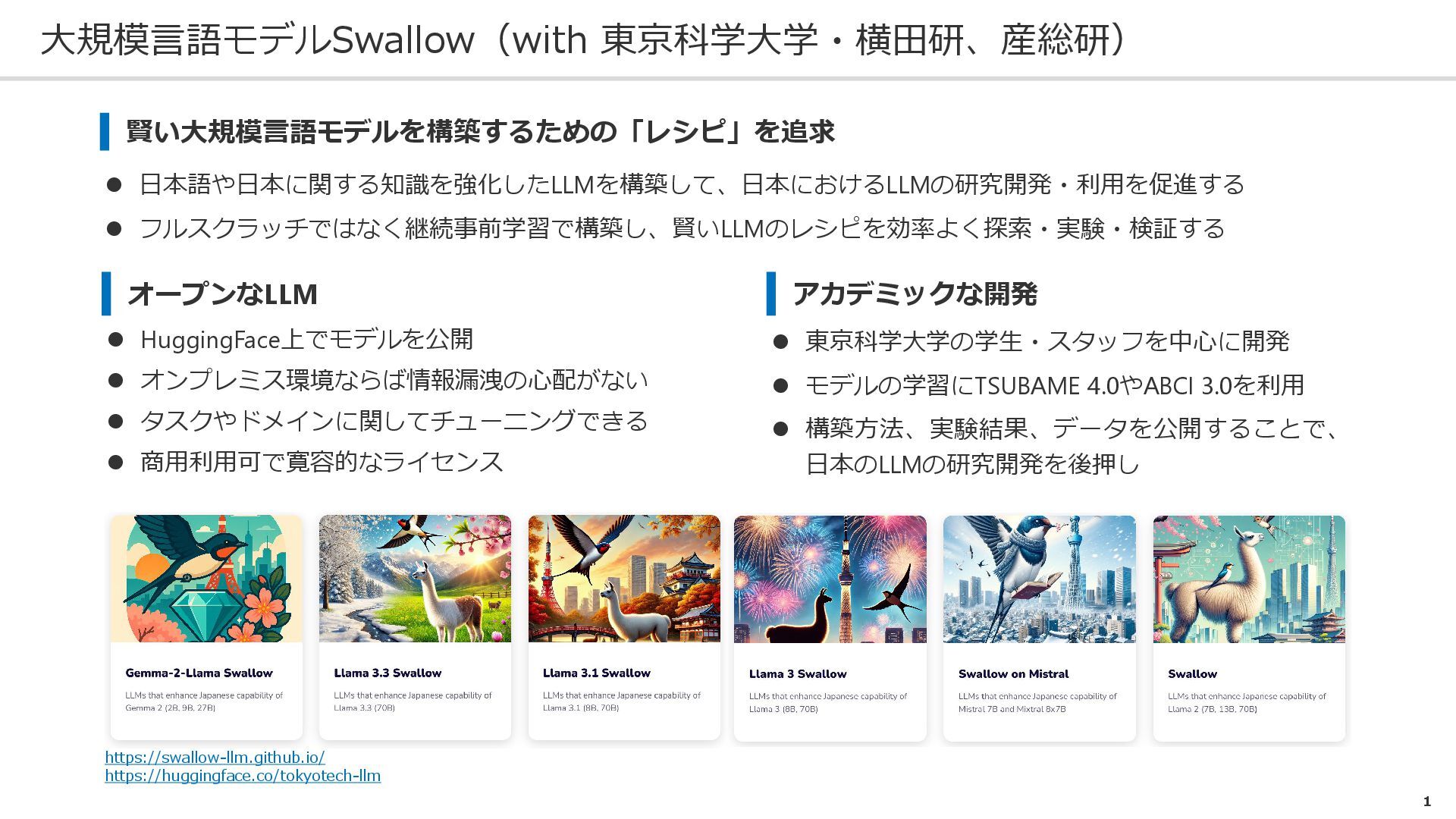
![進化する大規模言語モデル評価 Swallowプロジェクトにおける実践と知見 岡崎 直観 東京科学大学 情報理工学院情報工学系 [email protected] https://www.nlp.c.titech.ac.jp/](https://files.speakerdeck.com/presentations/fa4fd69e3b804a51ba1e346026e1b808/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
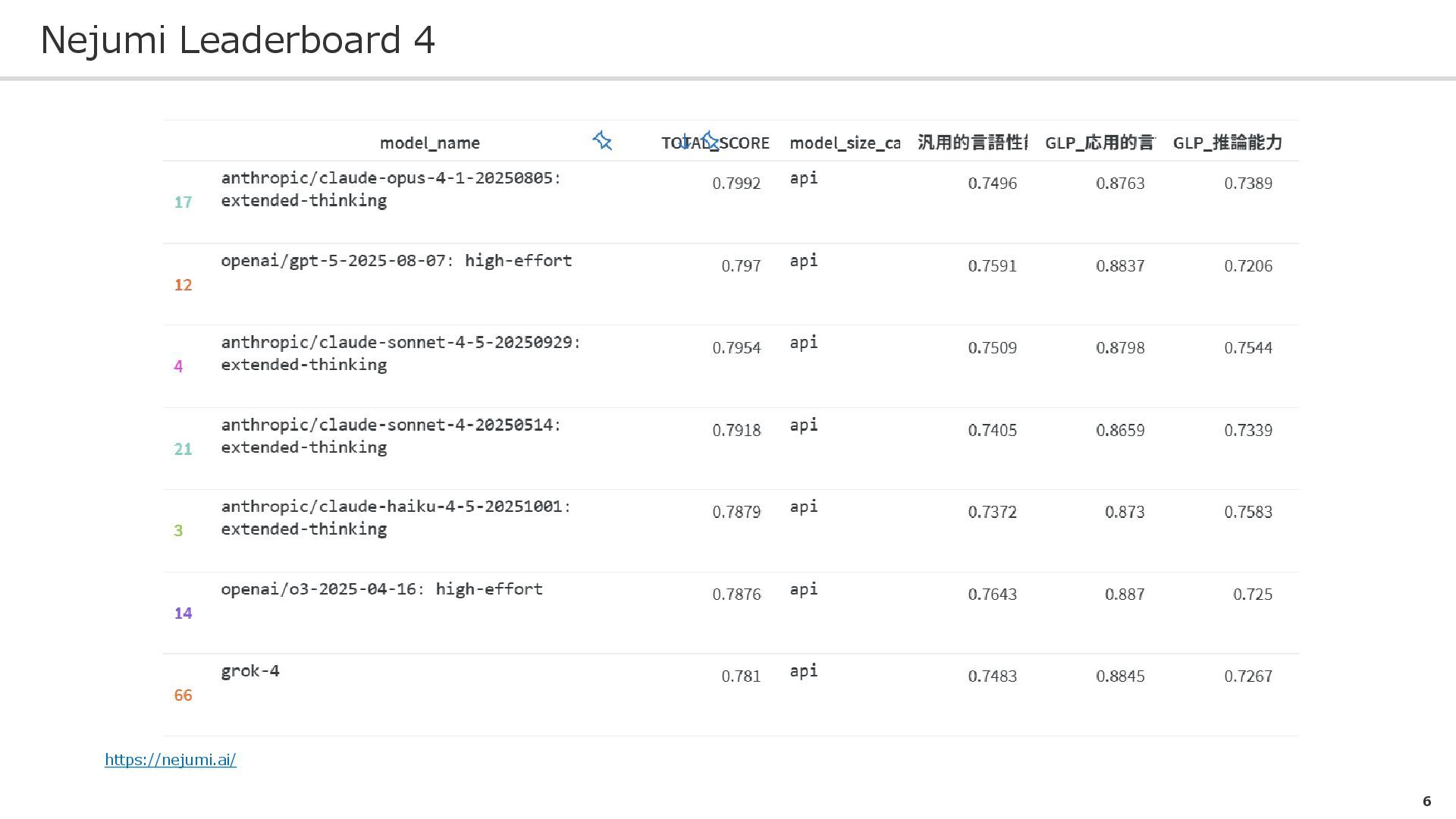
![代表的な日本語LLM評価フレームワーク Nejumi Leaderboard 4[1,2] LLM-jp-eval[3,4] Swallow-evaluation[5,6] Swallow-evaluation-instruct[7,8] [1] https://nejumi.ai/ [2]](https://files.speakerdeck.com/presentations/fa4fd69e3b804a51ba1e346026e1b808/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
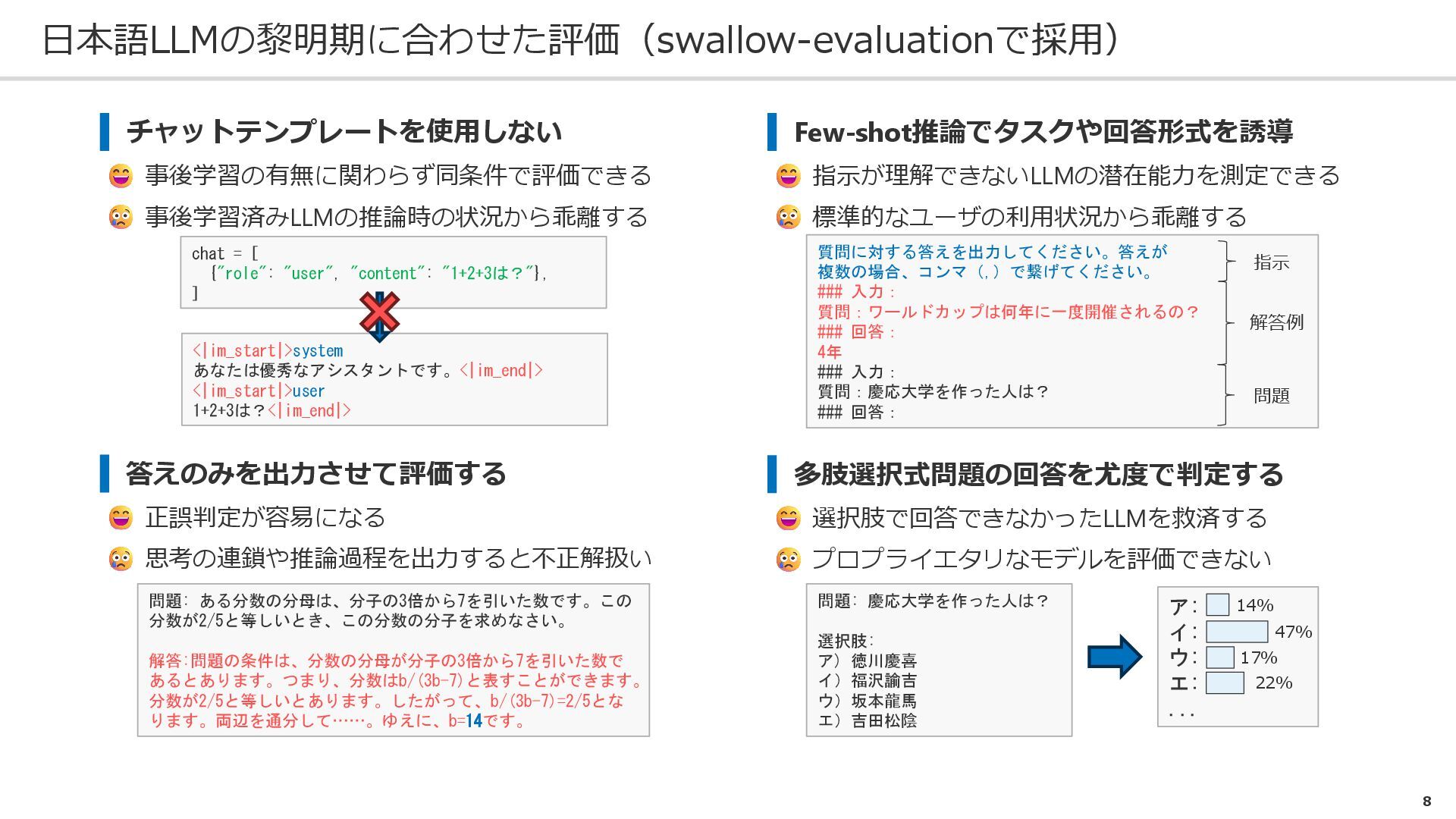{kind=link}
{kind=link}
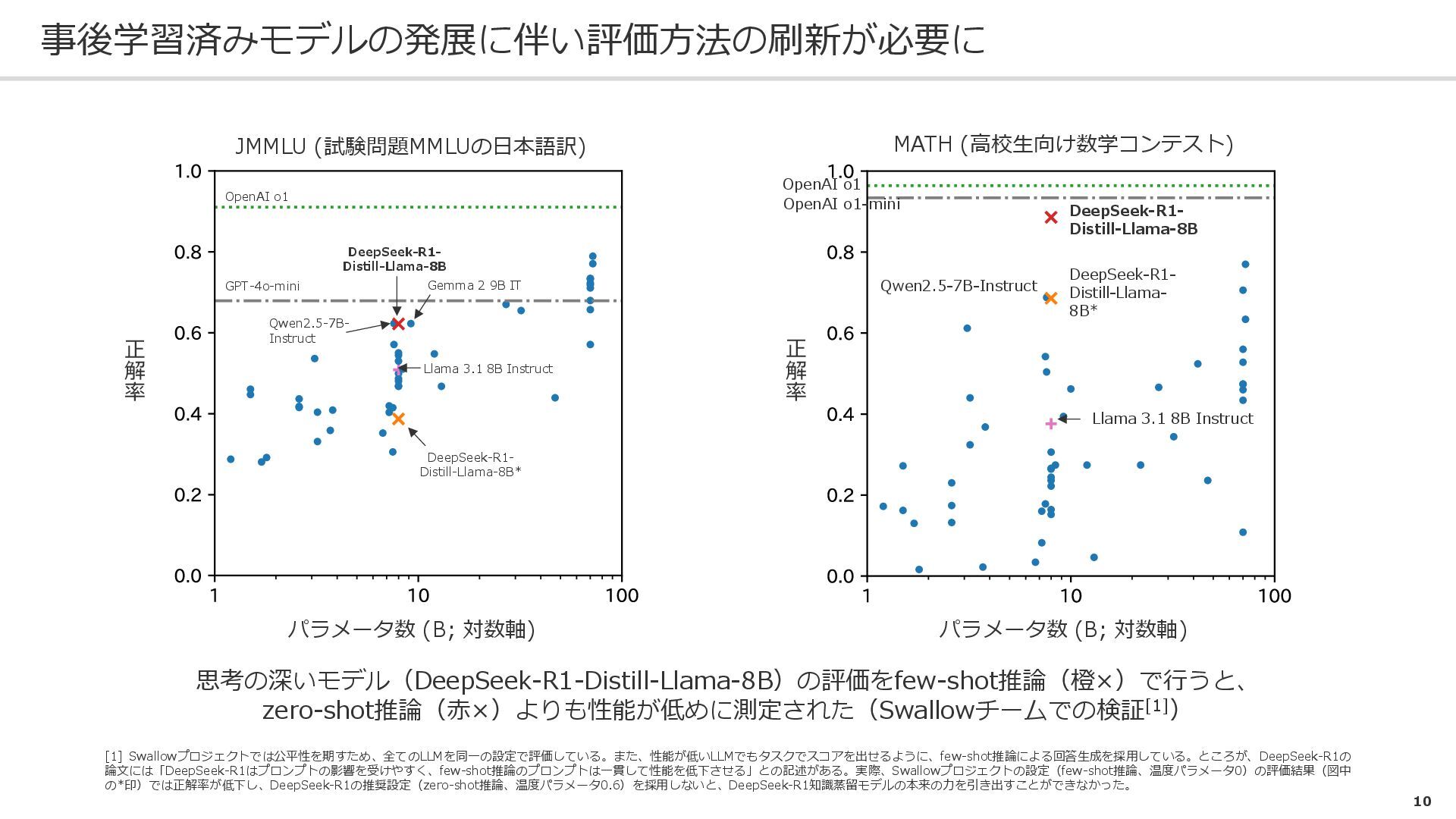{kind=link}
![LLMの性能向上と高難易度ベンチマーク (GPQA) 11 大学院レベルの科学 (GPQA) の正解率[1,2] [1] D Rein, B](https://files.speakerdeck.com/presentations/fa4fd69e3b804a51ba1e346026e1b808/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
![GPT-OSS 120B[1] (推論モードはmedium) をMATH-100[2]で評価する例 以下の数学の問題を、わかりやすく、論理的に解いてください。 出力の最後の行は、次の形式にしてください。 回答: $¥boxed{{ANSWER}}$ `ANSWER` には、問題の答えに対する最終的な数式または数値が](https://files.speakerdeck.com/presentations/fa4fd69e3b804a51ba1e346026e1b808/slide_14.jpg){kind=link}
{kind=link}
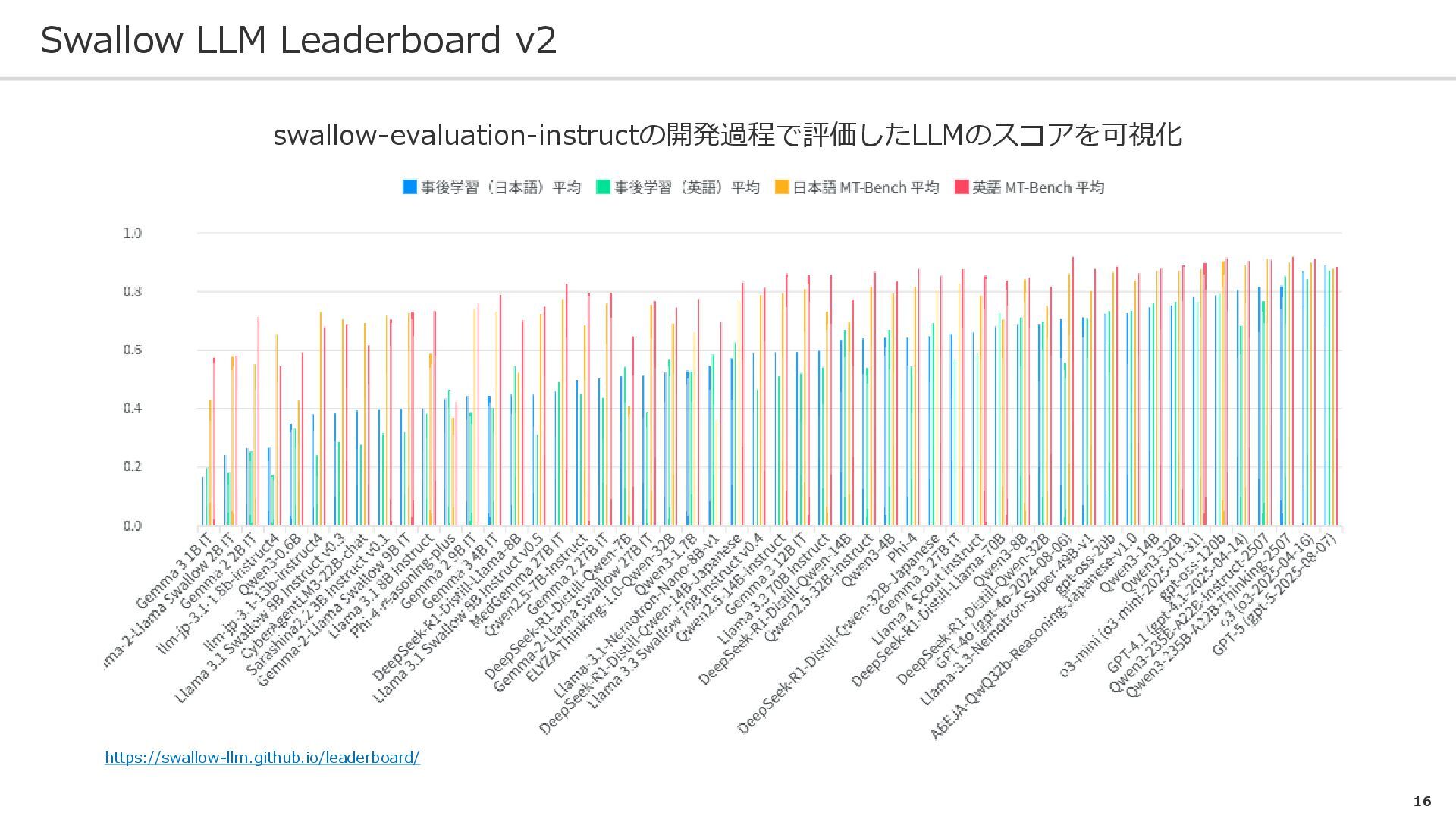{kind=link}
{kind=link}
{kind=link}