in a scientific publication is not the scholarship itself, it is merely advertising of the scholarship. The actual scholarship is the complete software development environment and the complete set of instructions which generated the figures. Buckheit and Donoho (paraphrasing John Claerbout) WaveLab and Reproducible Research, 1995
to solve a problem • An interface to facilitate coding / creating • A way to communicate your work • A way to share your work • A way to pack it all for replication • A way to do all of this relatively easily and accessibly
Facilitate the use of open-source tools? ◦ Make it easier to use, share, and reproduce? ◦ Make connections between languages or tools? ◦ Make them more accessible to the world?
computational tools to solve a problem • An interface to facilitate coding / creating • A way to communicate your work • A way to share your work • A way to pack it all for replication A way to do all of this relatively easily and accessibly?
infrastructure is needed to facilitate people working in the cloud? • Full-stack solutions are too rigid, don’t generalize well • Fully-generic solutions are too complex to expect adoption • It needs to be open-source so that others can build on this work.
cloud providers / hardware Declarative high level primitives that allow you to be as high level or low level as needed Utilize features of underlying hardware when you want (GPUs, SSDs, etc) easily
entity Fast paced releases that miraculously keep backwards compatibility Has worked to foster a warm, welcoming environment for contributors and users
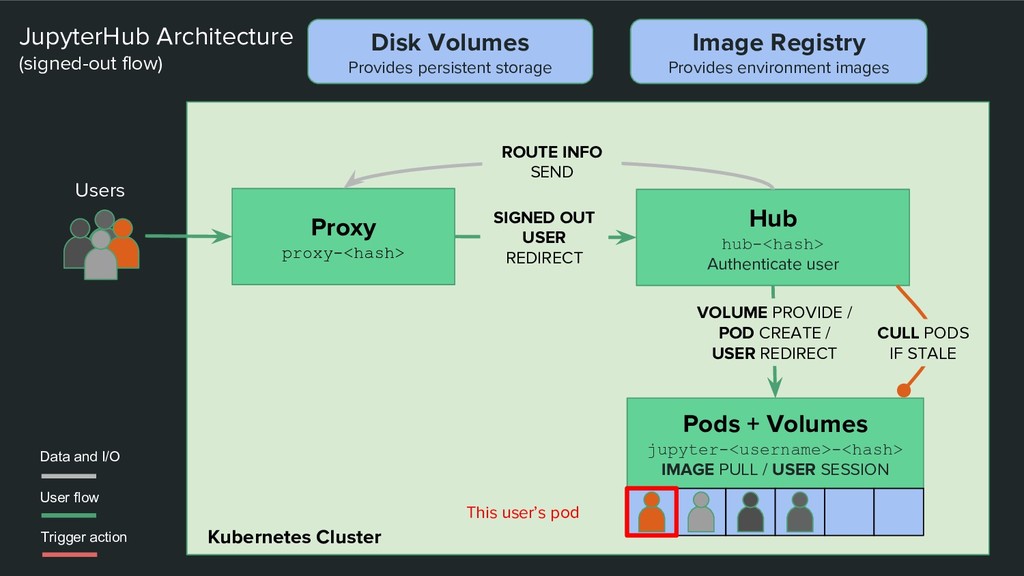
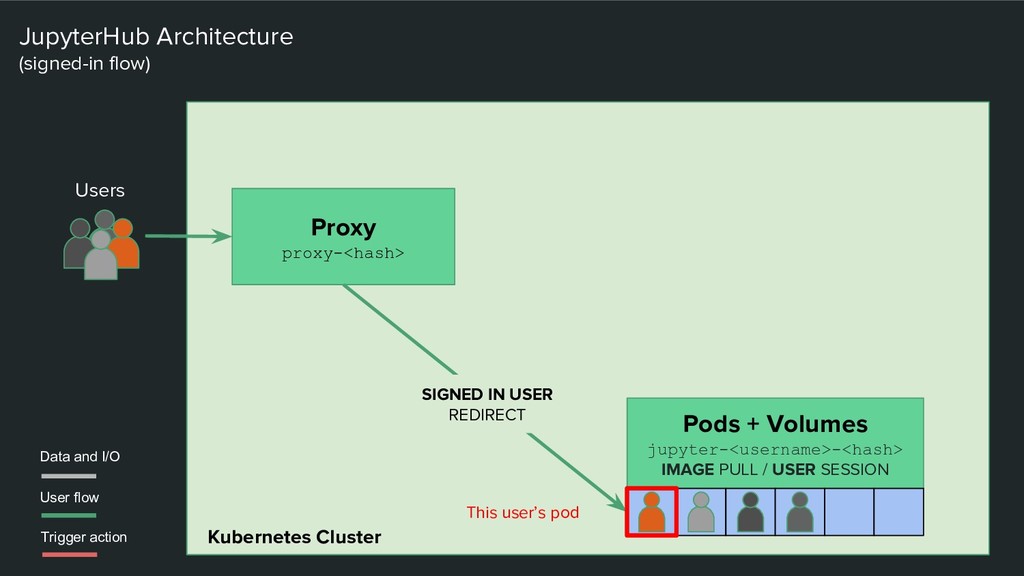
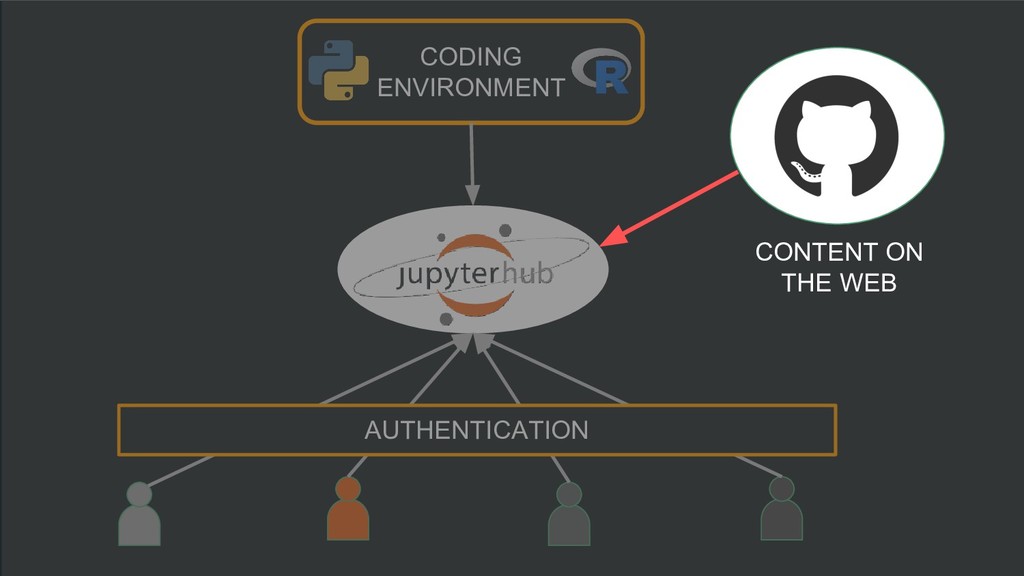
/ POD CREATE / USER REDIRECT JupyterHub Architecture (signed-out flow) SIGNED OUT USER REDIRECT ROUTE INFO SEND Data and I/O User flow Users Pods + Volumes jupyter-<username>-<hash> IMAGE PULL / USER SESSION This user’s pod Disk Volumes Provides persistent storage Image Registry Provides environment images CULL PODS IF STALE Trigger action
utilize… ◦ ...shared hardware/compute for running code ◦ ...shared data storage for big datasets ◦ ...shared environments for doing work ◦ ...shared workflows, ideas, and results
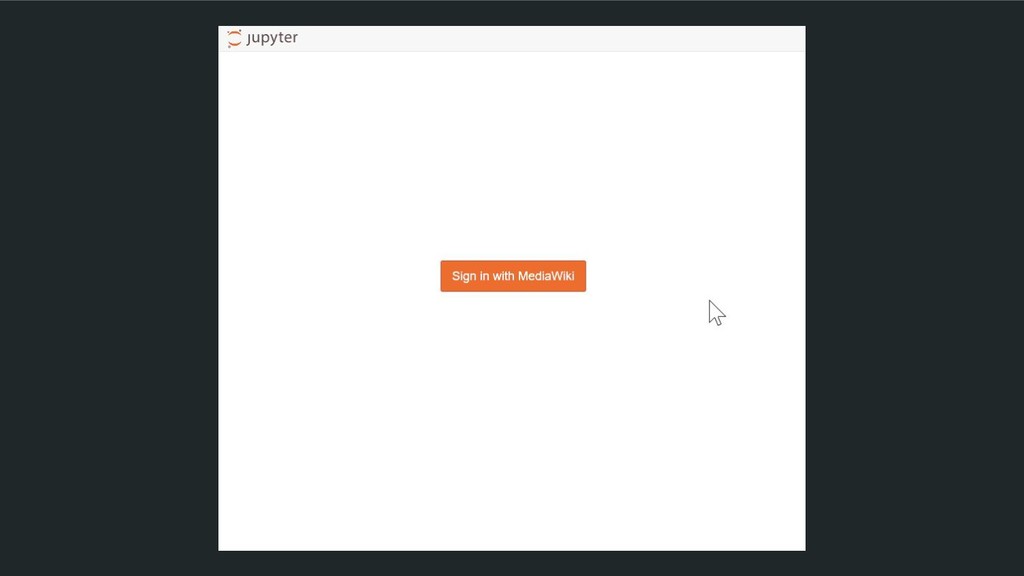
databases + data dumps with a Jupyter Notebook interface ipynb - users can import functions from other users’ notebooks across wikimedia 2.8 million edits to wikimedia projects
PAWS required a lot of manual one-off customization • We can’t assume that researchers will spend this much time deploying JupyterHub • Fortunately...Kubernetes has a solution to this!
needs a pre-built Docker image. Creating the image can be hard to learn, debug, etc Most languages already have a way to specify dependencies Could we programmatically generate an environment?
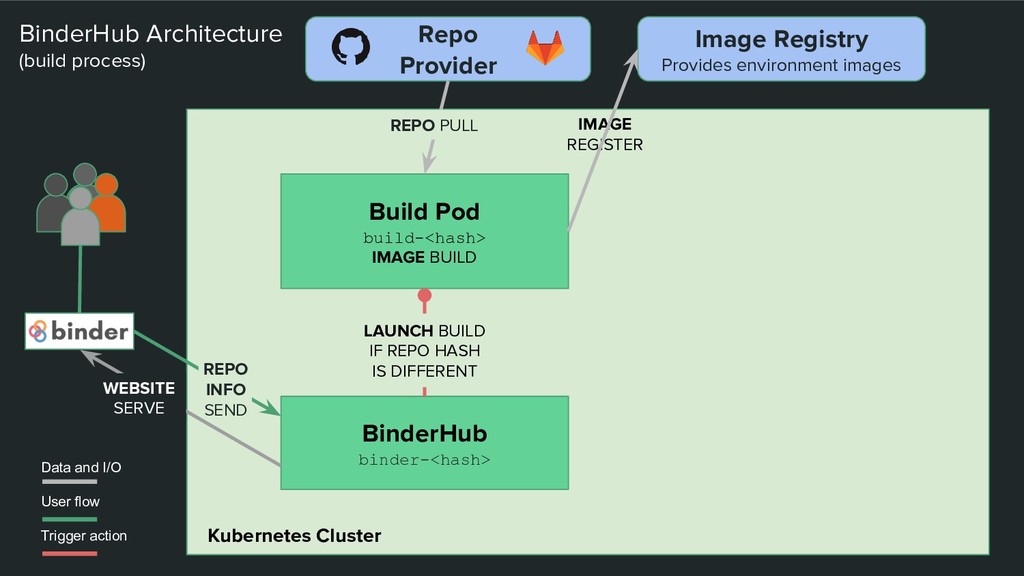
Build Pod build-<hash> IMAGE BUILD REPO PULL LAUNCH BUILD IF REPO HASH IS DIFFERENT Users Data and I/O User flow Trigger action Image Registry Provides environment images REPO INFO SEND IMAGE REGISTER WEBSITE SERVE
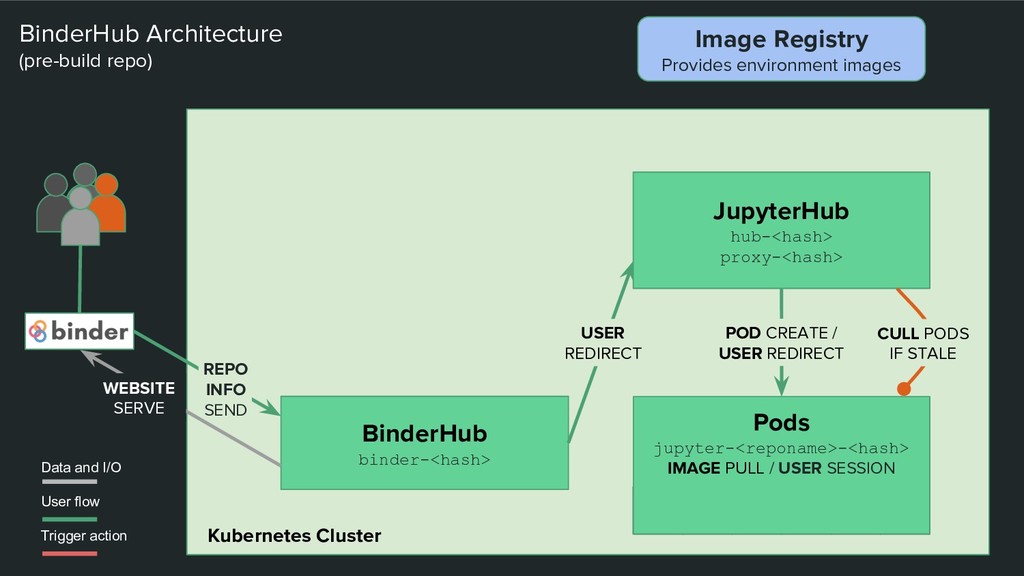
Architecture (pre-build repo) USER REDIRECT Users Data and I/O User flow Trigger action Image Registry Provides environment images JupyterHub hub-<hash> proxy-<hash> REPO INFO SEND WEBSITE SERVE CULL PODS IF STALE Pods jupyter-<reponame>-<hash> IMAGE PULL / USER SESSION
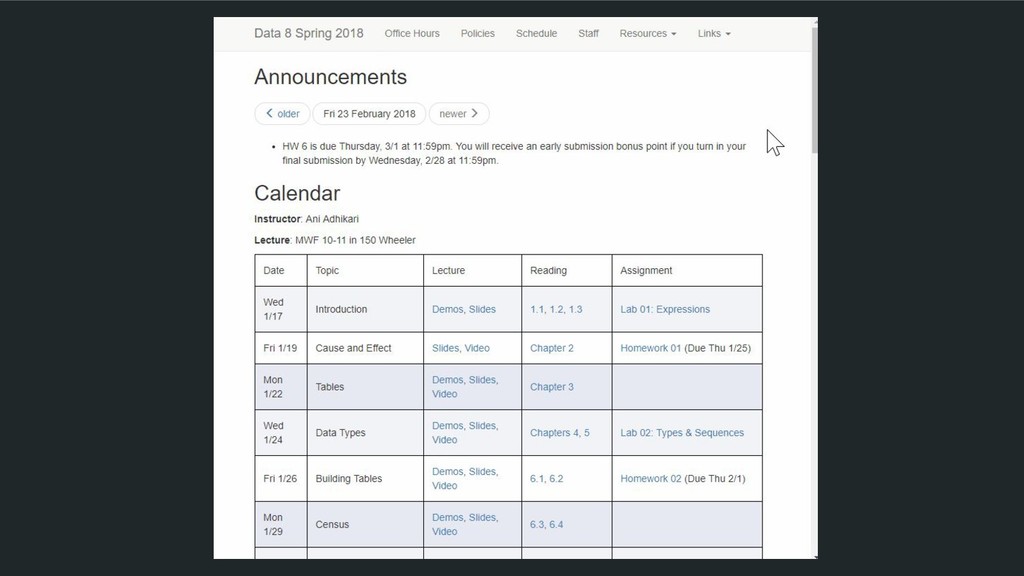
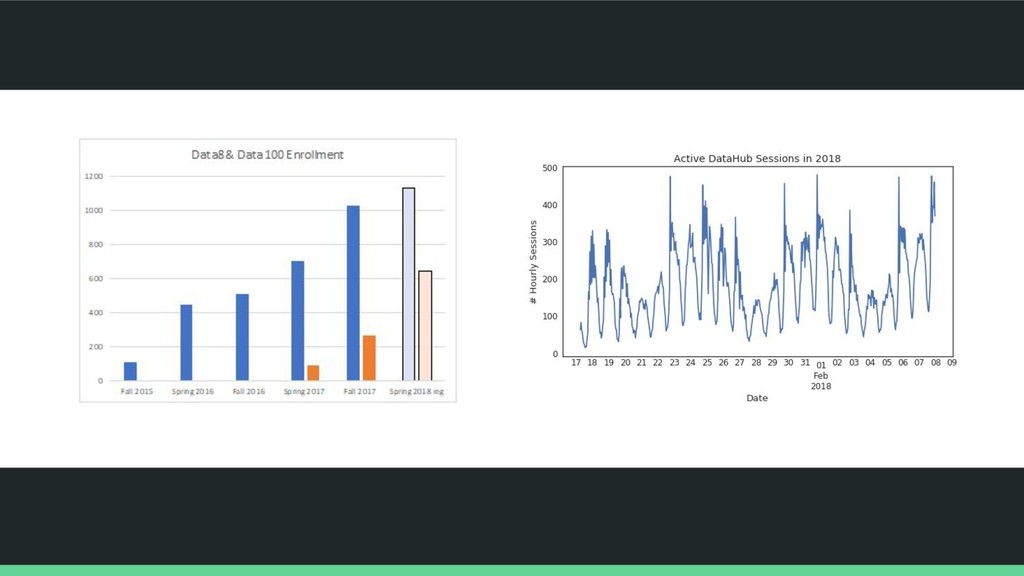
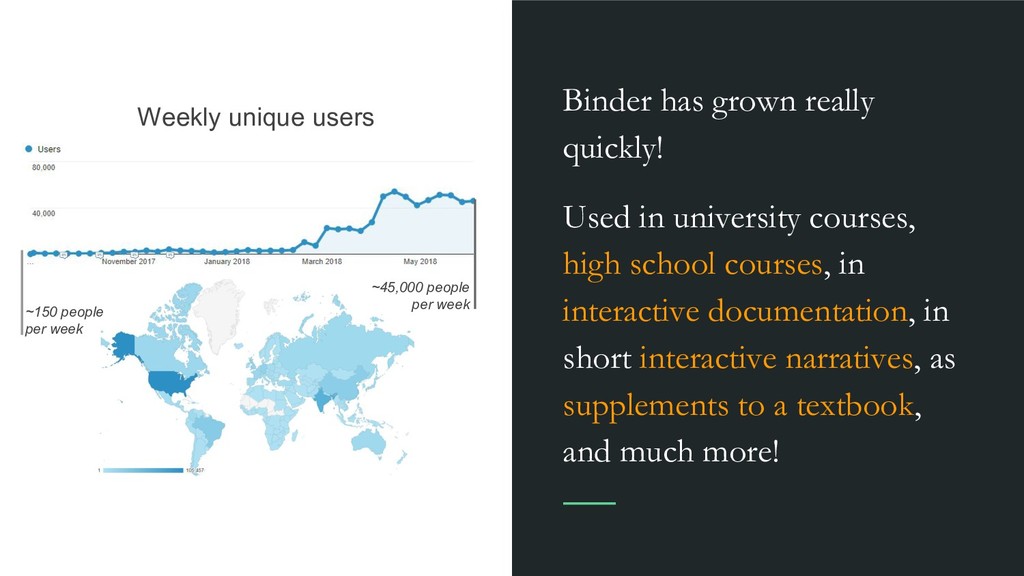
school courses, in interactive documentation, in short interactive narratives, as supplements to a textbook, and much more! Weekly unique users ~150 people per week ~45,000 people per week
to solve a problem • An interface to facilitate coding / creating • A way to communicate your work • A way to share your work • A way to pack it all for replication • A way to do all of this relatively easily and accessibly
to solve a problem • An interface to facilitate coding / creating • A way to communicate your work • A way to share your work • A way to pack it all for replication • A way to do all of this relatively easily and accessibly • A bunch of other cool stuff...
facilitate teaching? What’s different when you’re in the cloud? Researchers: How to efficiently collaborate via the cloud? Communicators: How to convey more complex information or reach new audiences?
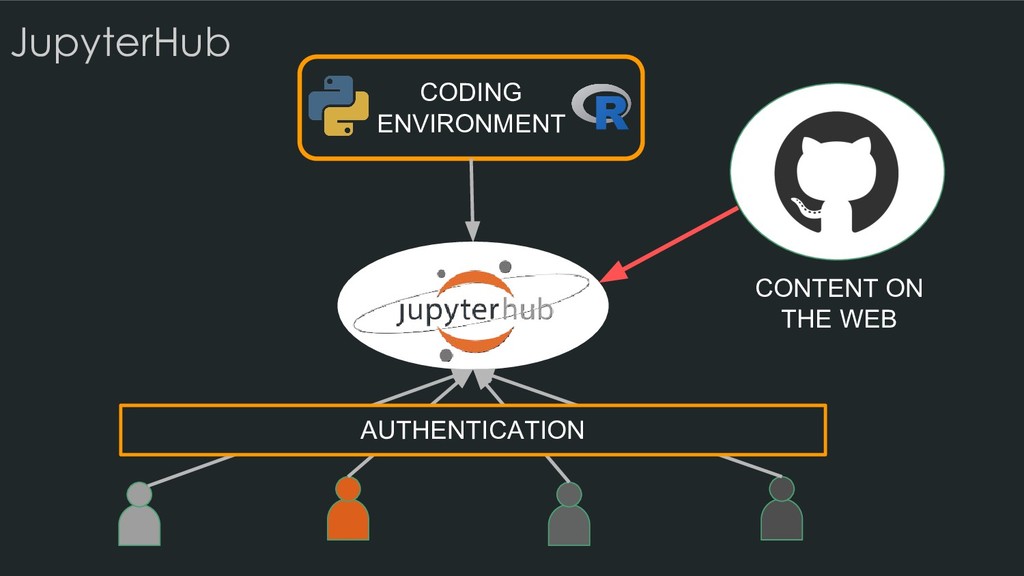
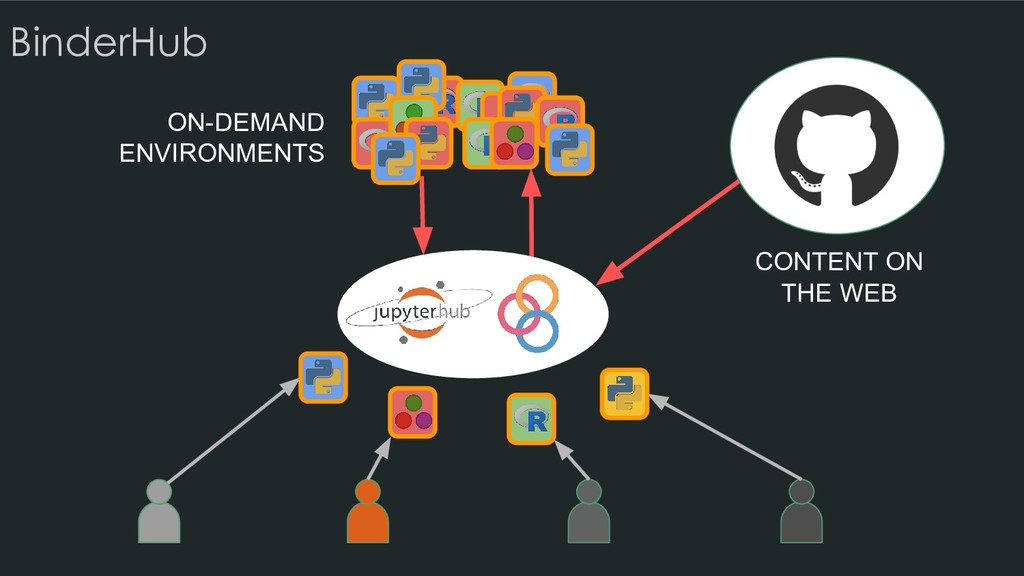
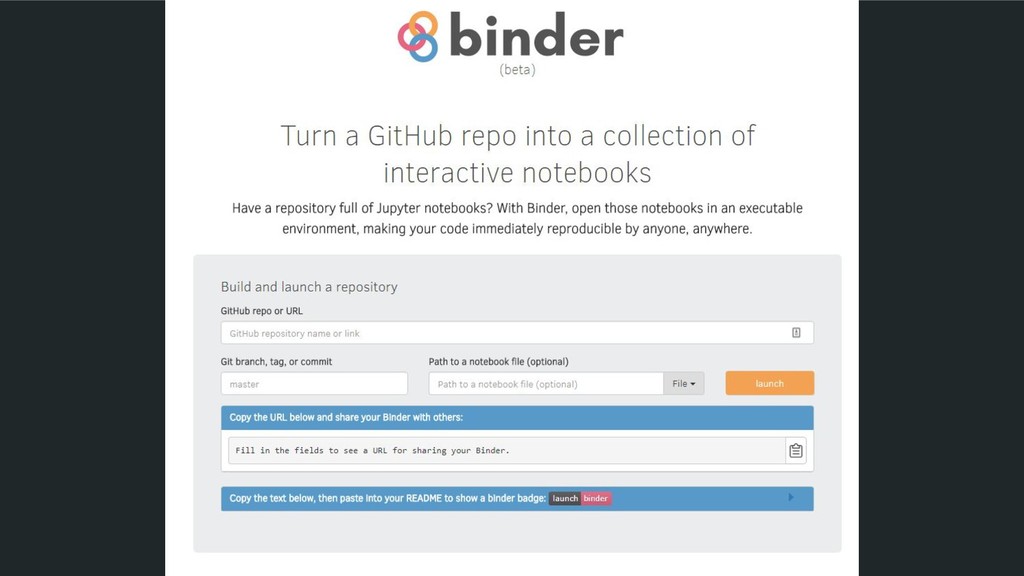
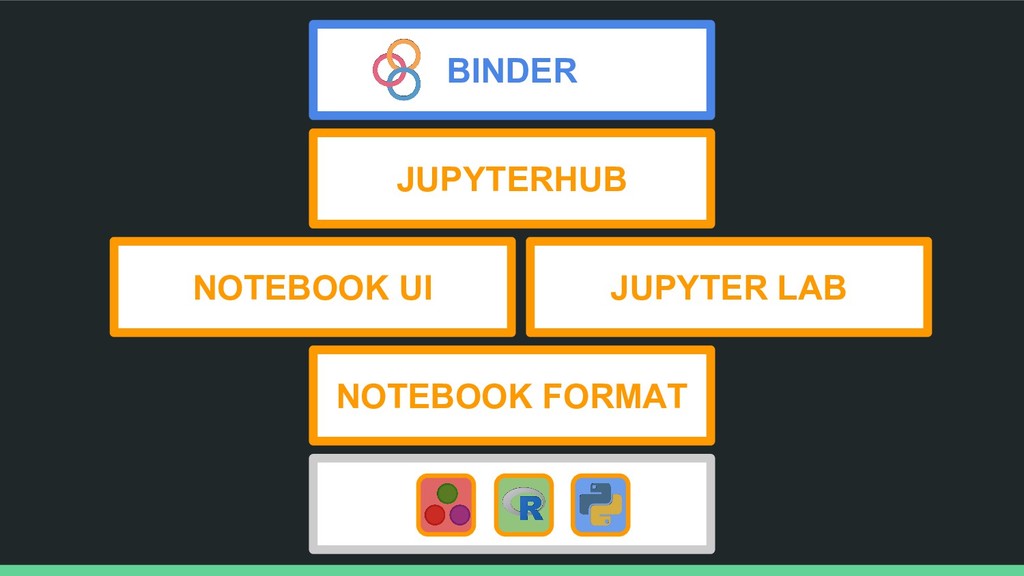
• Jupyter makes connections between open-source tools • The Notebook format interweaves narrative, code, and results • The Notebook Interface and JupyterLab presents your work in a readable and interactive way • JupyterHub lets you serve multiple notebook sessions in the cloud • Binder lets you create sharable, interactive code repositories
list groups.google.com/forum/#!forum/jupyter groups.google.com/forum/#!forum/binderhub Deploy your own JupyterHub z2jh.jupyter.org Deploy your own BinderHub binderhub.readthedocs.io
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}