“Works on my machine”: The cry of developers who can’t reproduce a bug because their development environment is incompatible with their deployment environment. It’s common because setting up clean environments is slow, tedious, and error-prone.
Meanwhile, debugging errors introduced by incorrect environments is slow, tedious, and error-prone.
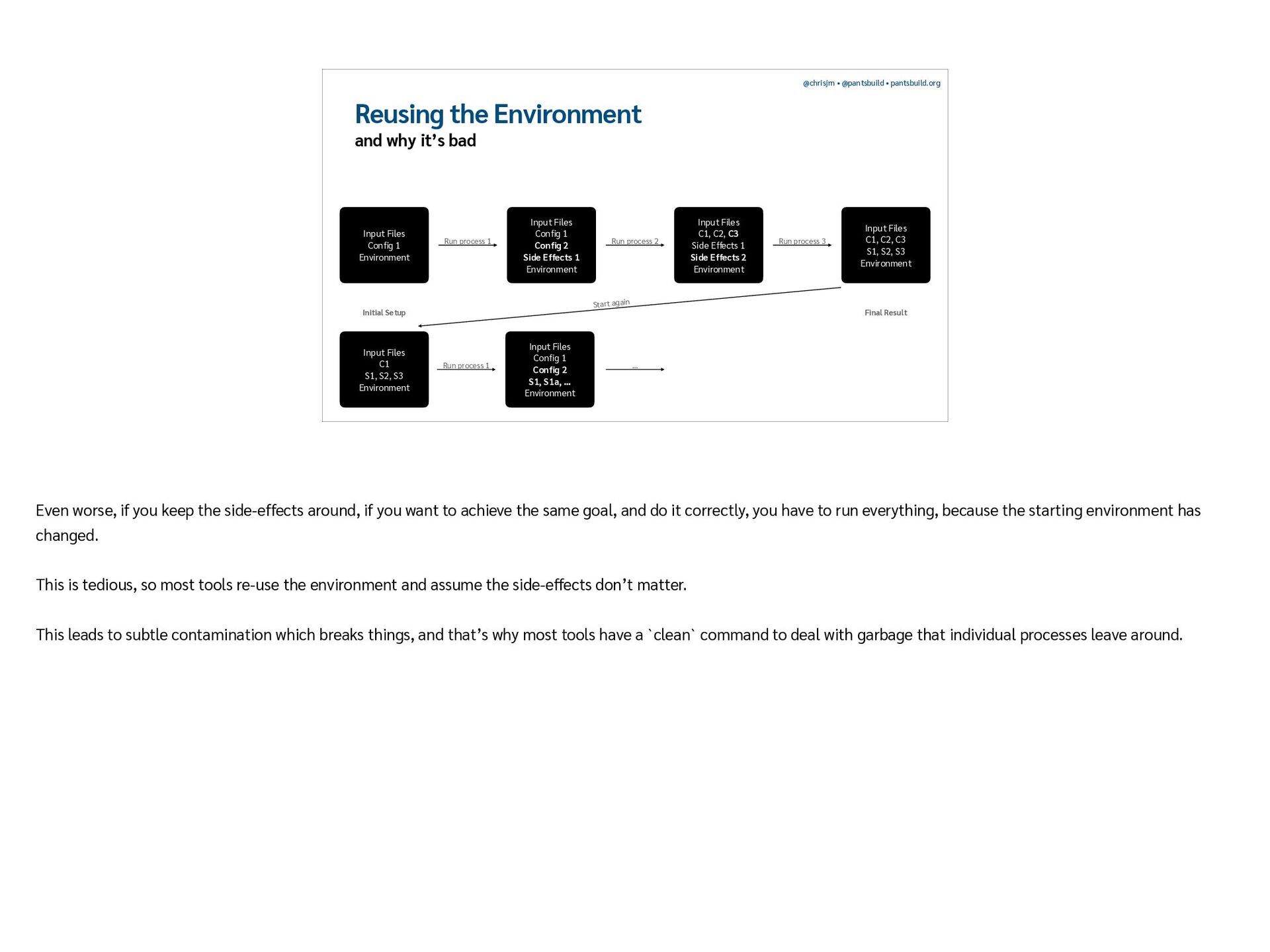
Each step in your CI workflow theoretically only has inputs or outputs, but in reality, files can be left along the way by running tests or compiling extensions. These are side-effects, not inputs for subsequent steps in your workflow, let alone deployment, but if included they can affect correctness.
You can solve this using “hermetic environments”: running every step of your workflow inside a fresh environment, so steps run truly independently of one another. You can do this manually with Docker, but it’s difficult: you have to understand which inputs are necessary for a step, which newly generated files are meaningful outputs, and what should be discarded.
Pantsbuild uses hermetic builds automatically: it understands the inputs each step needs, what outputs it produces, and stores inputs and outputs inside a content-addressable database so it can rapidly build sandboxed environments for subsequent steps of your workflow.
The result is a build process where every step is run in isolation, with only the inputs each process truly needs, and only true outputs made available to each subsequent step. Pants’ workflows are fast but verifiably correct — running against incorrect inputs is not a possible failure case.
In this talk, we’ll explore how Pantsbuild enables truly hermetic builds. We’ll look at other approaches to sandboxing and how they compare to Pants’ approach, and how you can benefit from adding hermetic builds to your project.
You’ll walk away being confident that “works on my machine” means “works everywhere”.
![Christopher Neugebauer • [email protected] @chrisjrn • @pantsbuild Hermetic Environments in](https://files.speakerdeck.com/presentations/b508d7f80f6443179e3669507ac01b0a/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
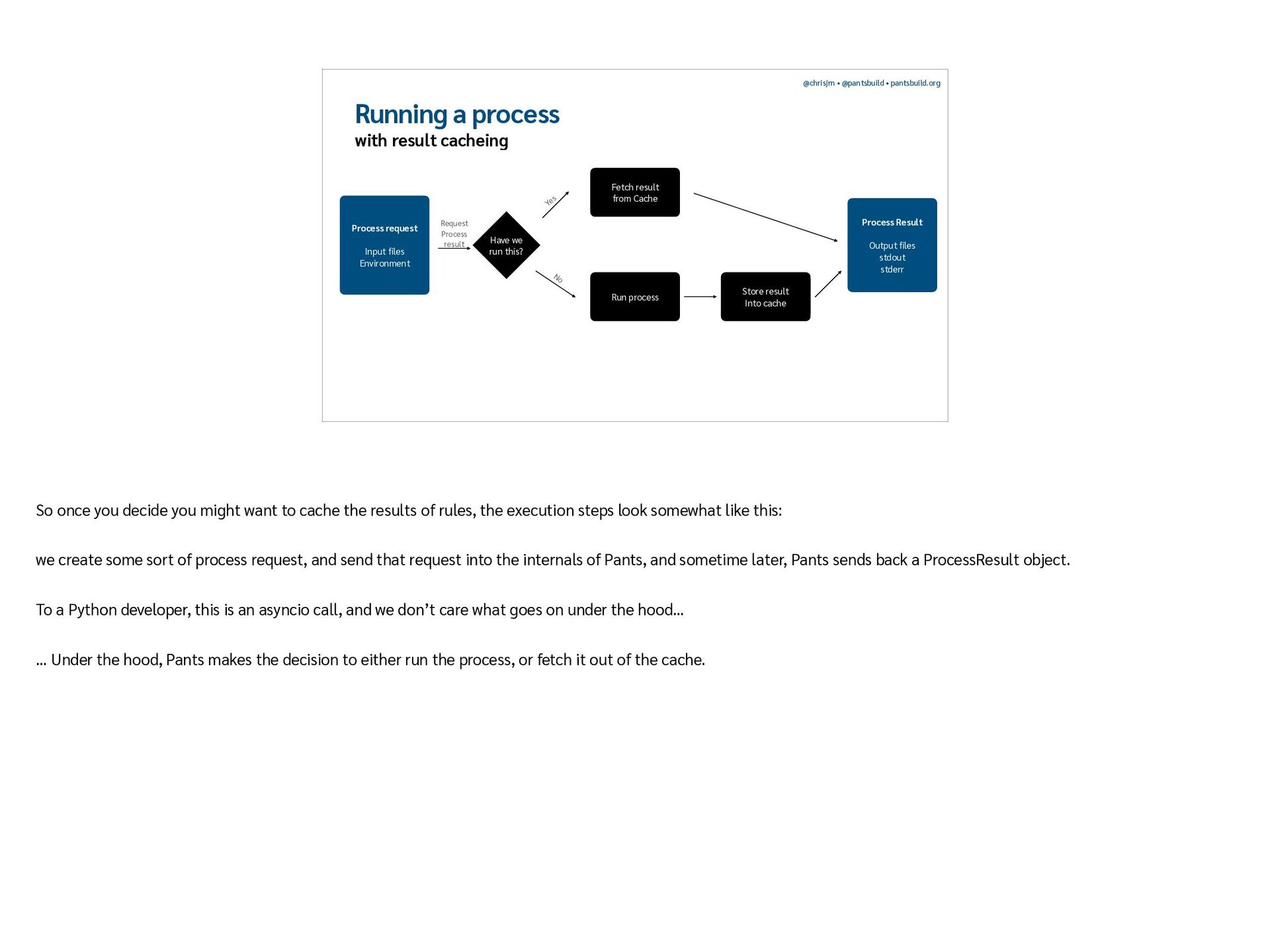
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
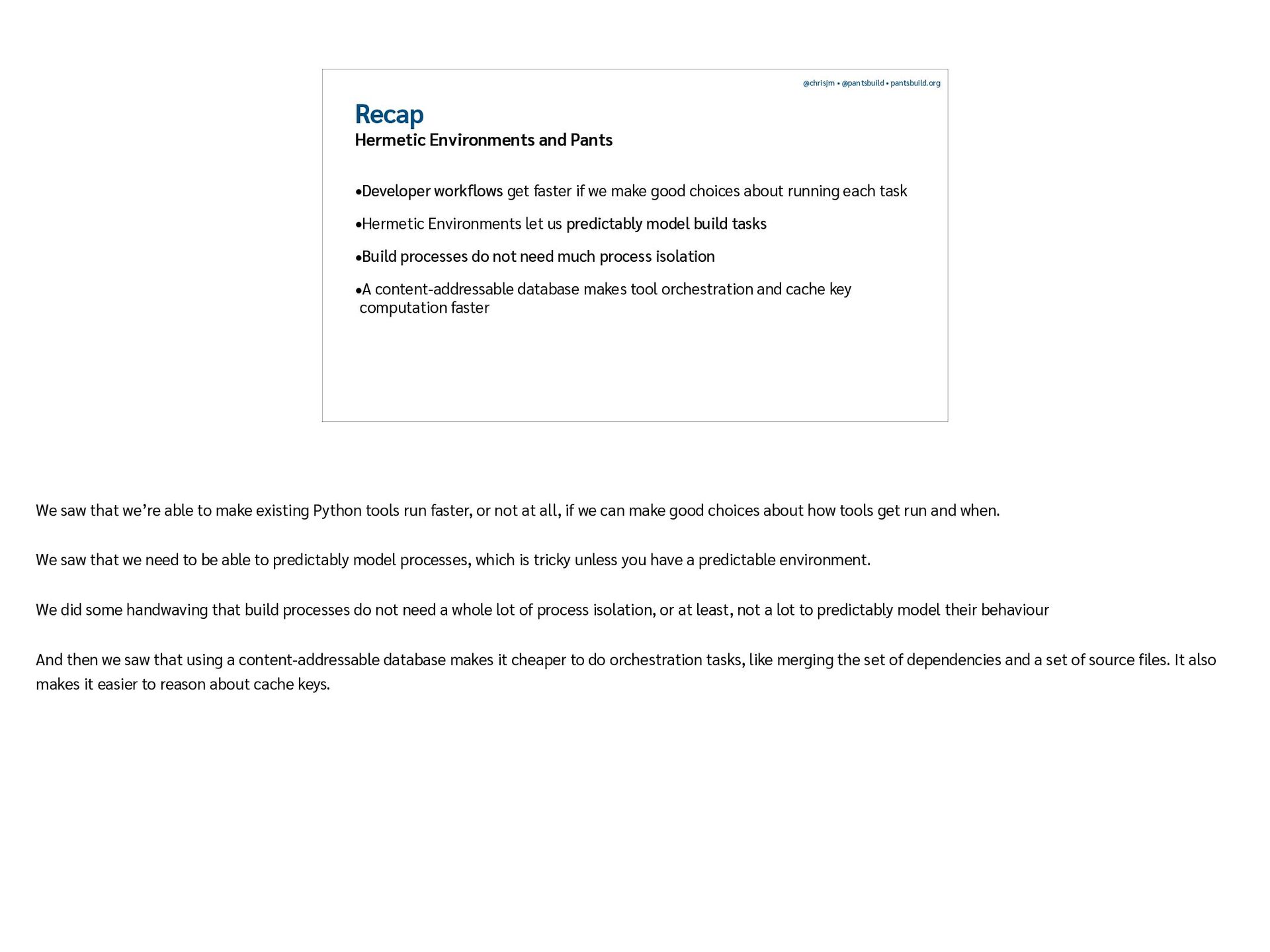{kind=link}
{kind=link}
![Christopher Neugebauer • [email protected] @chrisjrn • @pantsbuild Hermetic Environments in](https://files.speakerdeck.com/presentations/b508d7f80f6443179e3669507ac01b0a/slide_91.jpg){kind=link}