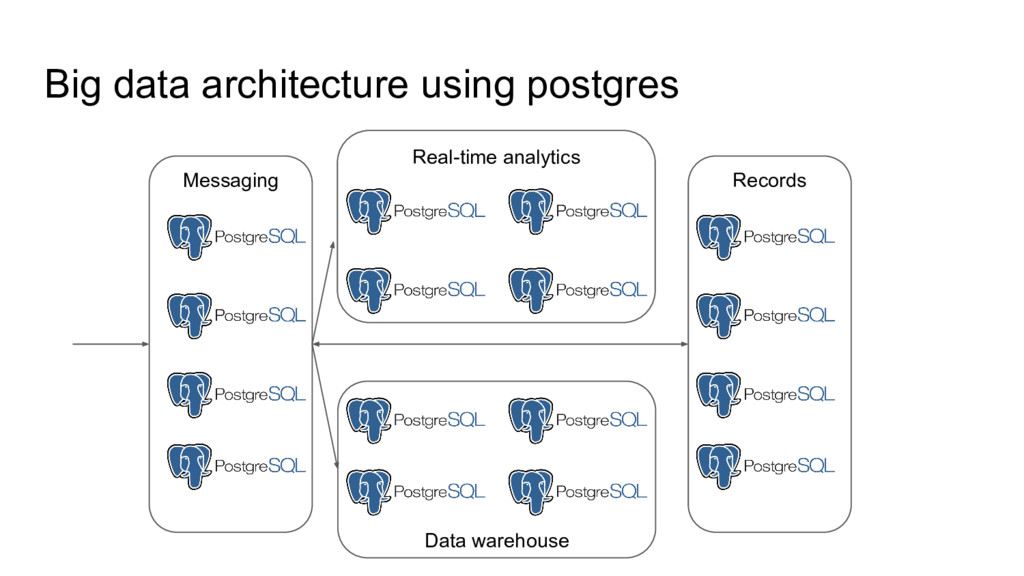
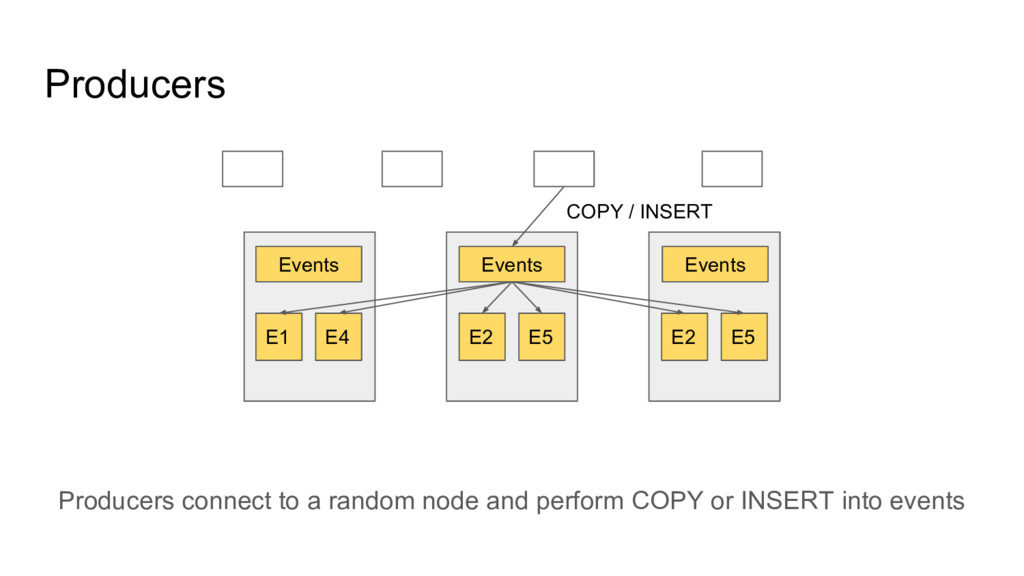
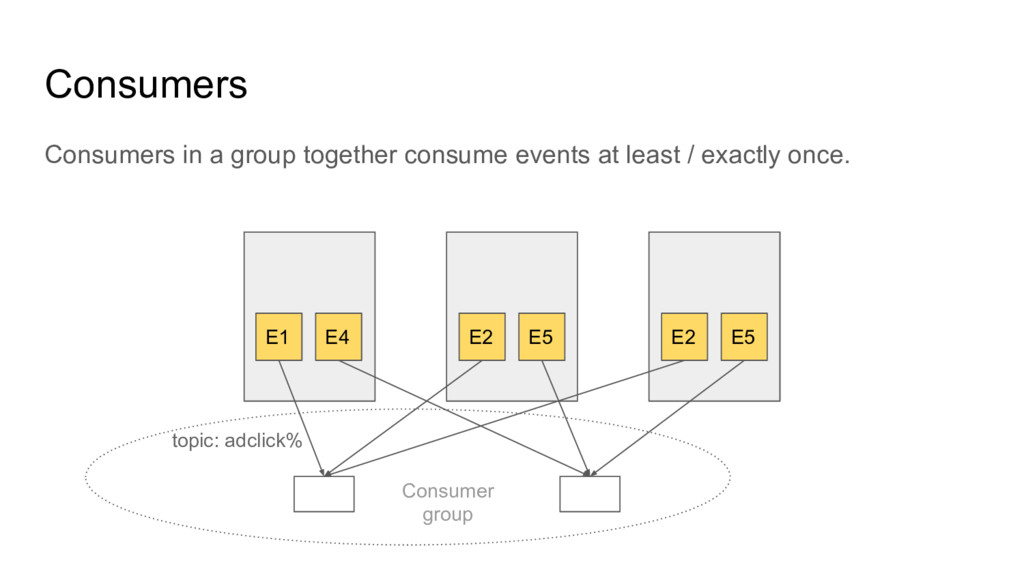
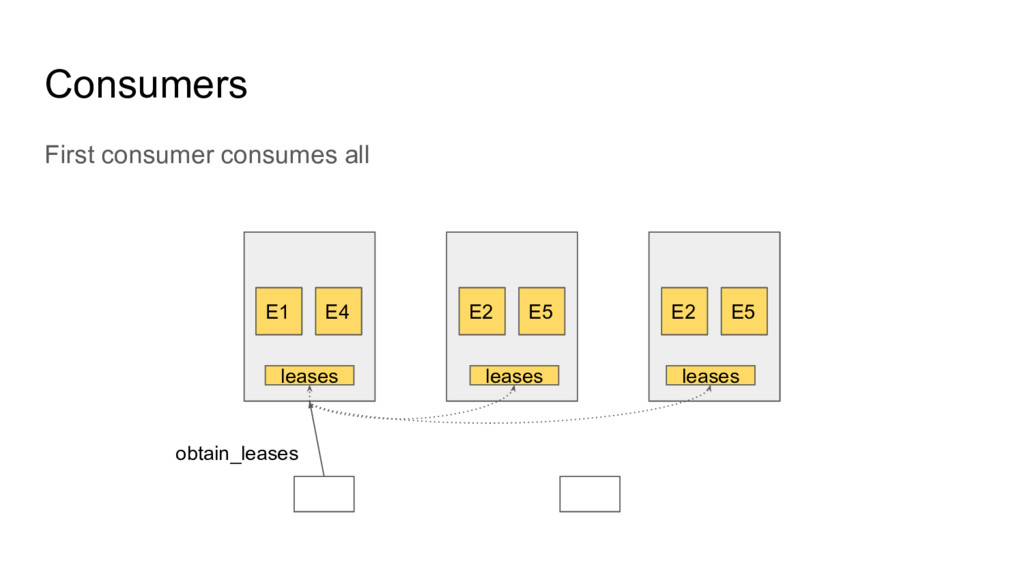
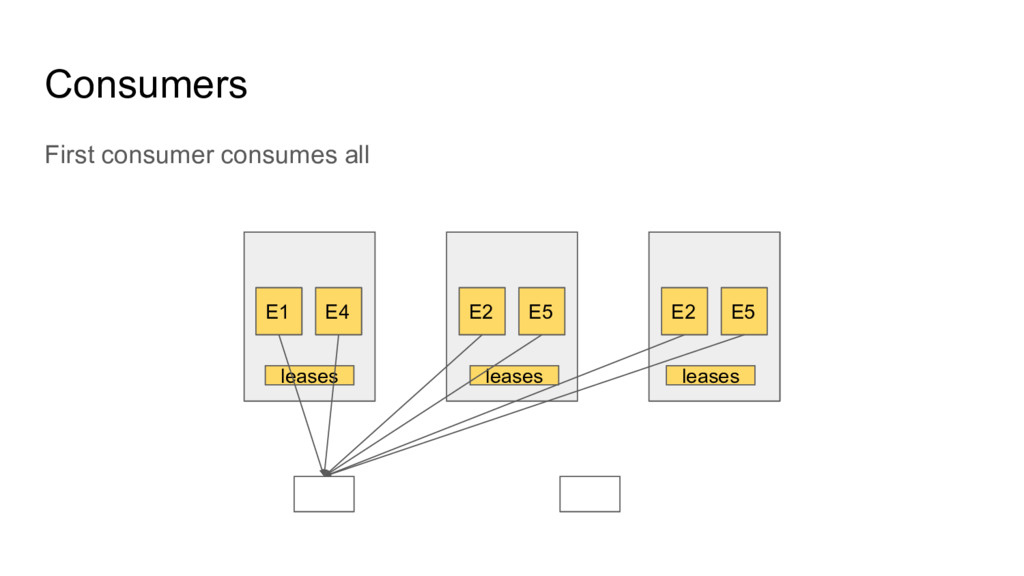
One of the unique things about postgres is that extensions can add new functionality that falls outside the scope of a SQL database. Several postgres extensions add the ability to perform commands or query data on other servers. These extensions can be combined in interesting ways to form advanced distributed systems on top of postgres.
In this talk we will explore how extensions such as dblink, postgres_fdw, pglogical, pg_cron, and citus together with PL/pgSQL can be used as building blocks for distributed systems. We will give several demonstrations of using PostgreSQL as a distributed computing platform, including a MapReduce implementation that can transform very large tables, and a Kafka-like distributed queue.
![Distributed Computing on PostgreSQL Marco Slot <[email protected]>](https://files.speakerdeck.com/presentations/b131286045bd493ea77274f240a45399/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions? [email protected]](https://files.speakerdeck.com/presentations/b131286045bd493ea77274f240a45399/slide_40.jpg){kind=link}