workload for databases. This workload is also known as in-memory databases or Hybrid Transactional Analytical Processing (HTAP). • The real-time analytics workload includes use-cases such as powering customer facing dashboards, behavior analytics (segmentation and funnels), IoT / device analytics, time-series databases, and geospatial analysis.
databases have been built to handle real-time analytics workloads. An example is SAP HANA. • Postgres’ new features and extensions make it appealing and competitive for real-time analytics – while also providing the benefits of open source. • This lightning talk showcases five exciting developments for real-time analytics workloads.
working on JIT compilation using LLVM since Postgres 9.6. These changes improve analytical query performance for in-memory datasets. Diagram from Andres’ FOSDEM presentation: http://anarazel.de/talks/ fosdem-2018-02-03/jit.pdf
powers customer facing dashboards, your analytical queries need to go over hundreds of millions of rows in less than a second. • The HyperLogLog (HLL) extension provides an approximation algorithm to count the number of distinct items with tunable precision. • The TopN extension allows you to store, merge, and serve approximations for order by-group by-limit queries.
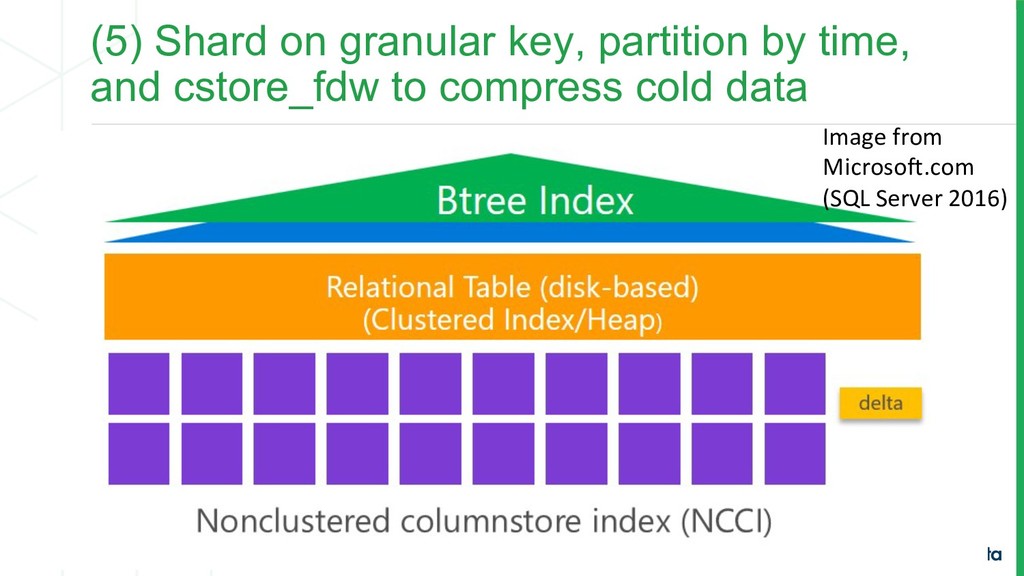
introduced native partitioning. • Real-time analytics data has a time dimension to it. This makes it suitable to partition by time – so that your indexes remain local to your partitions and data expiration becomes simple. • Common pattern: Shard by granular key, such as user_id or device_id. Then partition by time.
pattern in real-time analytics is hot updateable data and cold compressed data. • You update data for the most recent partition for that day. You then “close out” the partition and rotate this data into a cold partition. • With large data sets, you want to compress your cold partitions. CStore foreign data wrapper can sort and compress cold data.
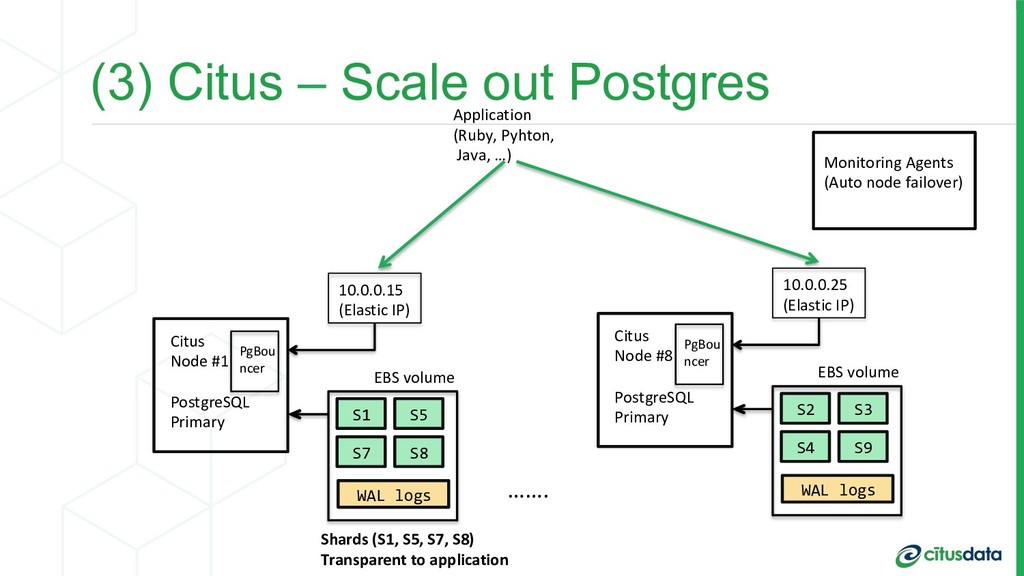
tailored to real- time analytics workloads. • Three years ago at PGCon: • https://www.citusdata.com/blog/2015/08/19/futuristic- pgshard-demo/ (Dynamically changing row and columnar store in Postgres) • The future is today!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}