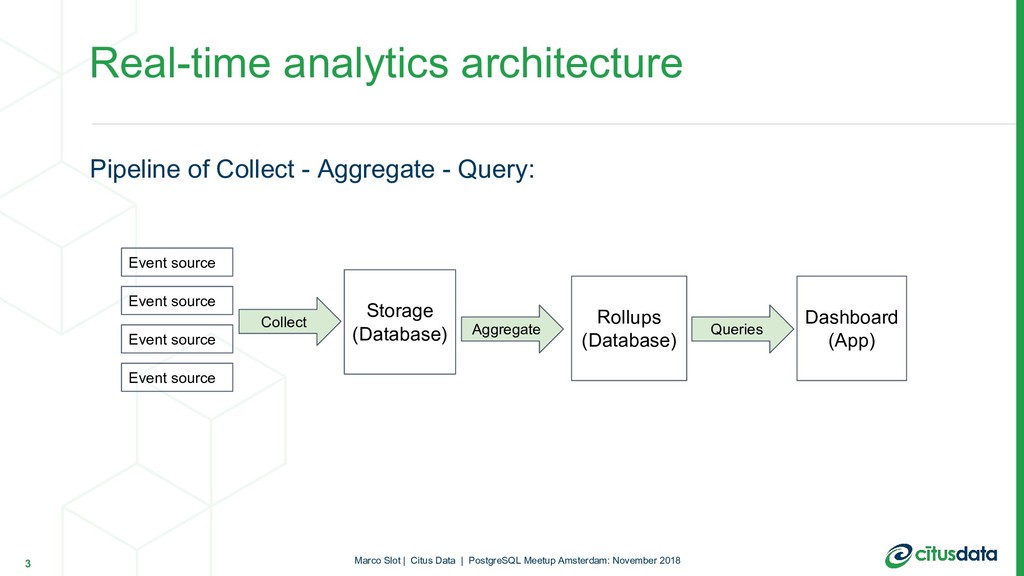
Building a dashboard that provides real-time insights into a large data stream is a challenging problem. The database needs to support high ingest rates, handle low latency (subsecond) analytical queries from many concurrent users, and reflect new data as soon as possible, while keeping data over long periods. This talk will discuss how you can build a scalable real-time analytics pipeline using PostgreSQL with extensions such as HLL and pg_partman, and how you can scale out across many servers using Citus.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}