In applications, it’s typical to have some analytics dashboard highlighting the number of unique items such as unique users or unique visits. While traditional COUNT(DISTINCT) queries work well most of the time for such use cases, it has some drawbacks while working on large data sets which result in large memory requirements and/or slow execution time. It is also not easy to use traditional COUNT(DISTINCT) queries in a distributed environment.
In this talk, we will focus on the HyperLogLog (HLL) algorithm and its PostgreSQL extension postgresql-hll. HLL can provide approximate answers to COUNT(DISTINCT) queries within mathematically provable error bounds. It is not only fast and memory-efficient but also has very interesting properties which especially shine in a distributed environment. In this talk, Burak Y. from Citus Data (also maintainer of postgresql-hll extension) will talk about internals of HLL and how it estimates cardinality; Jarred from IronNet Cybersecurity will showcase HLL in PostgreSQL with real world examples and use cases from his experience of running HLL in production. We promise that at the end of this session, you will fall in love with this fun little data structure as the newest tool in your data science and analytics tool belt.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
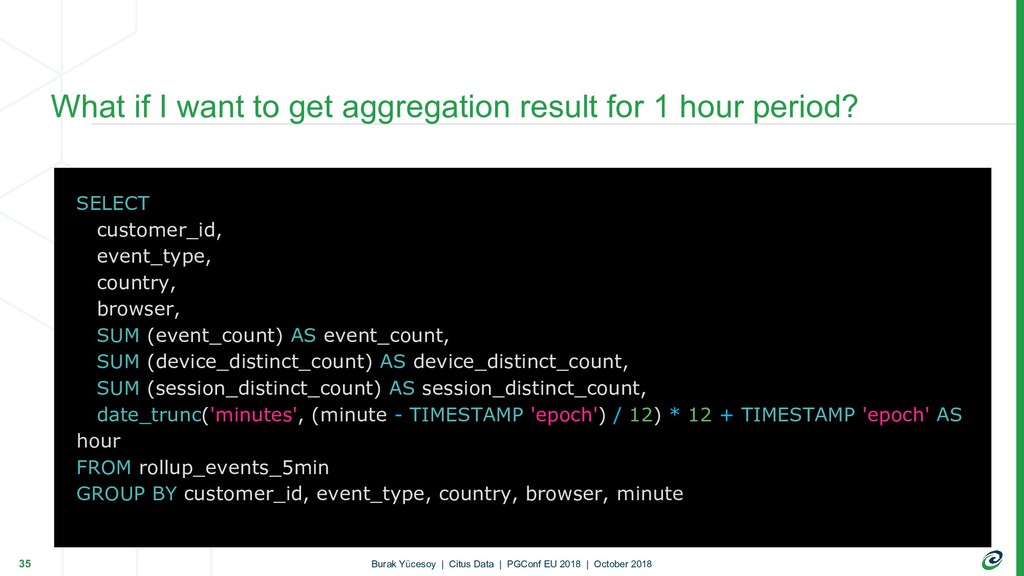{kind=link}
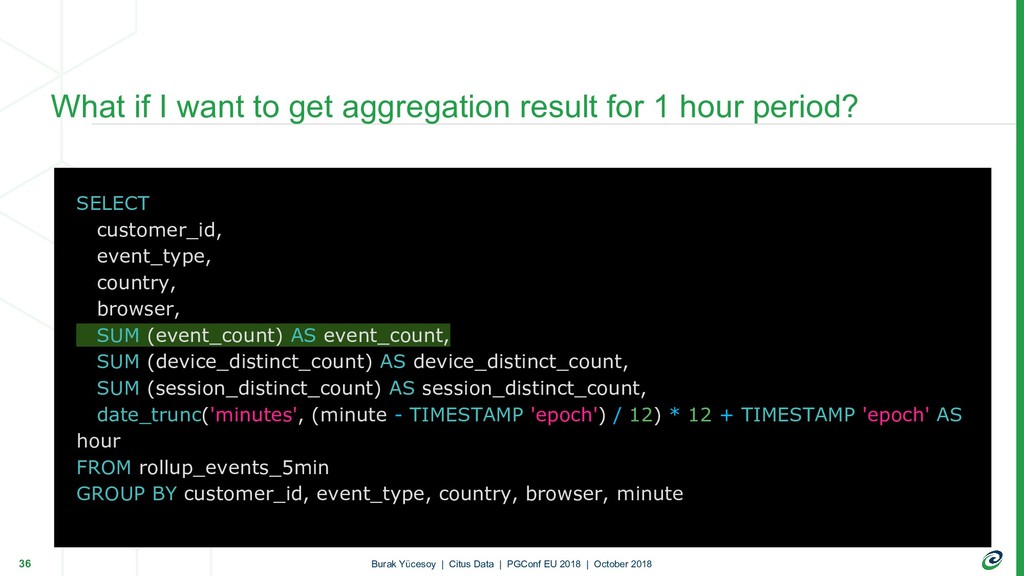{kind=link}
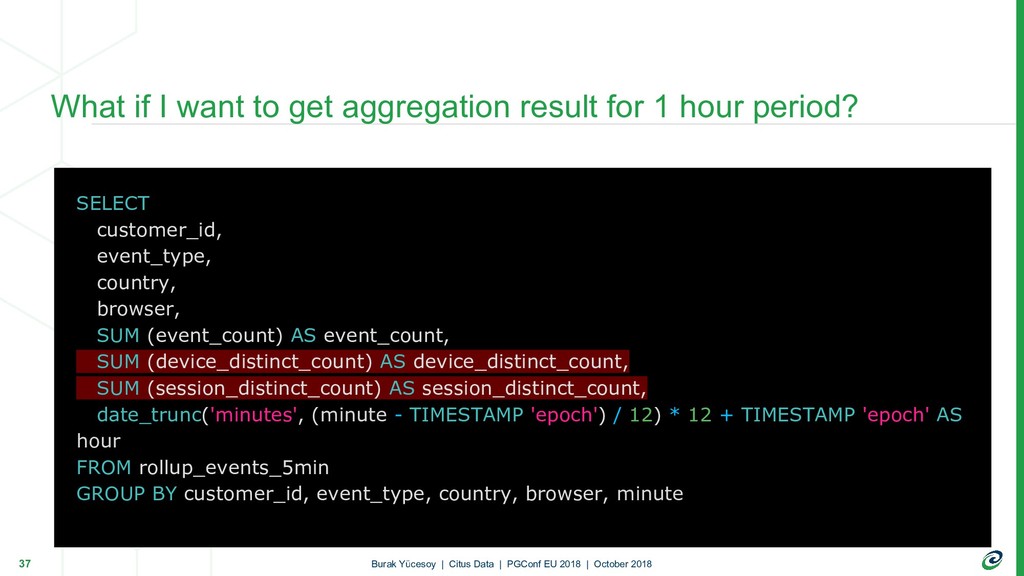{kind=link}
{kind=link}
{kind=link}
{kind=link}
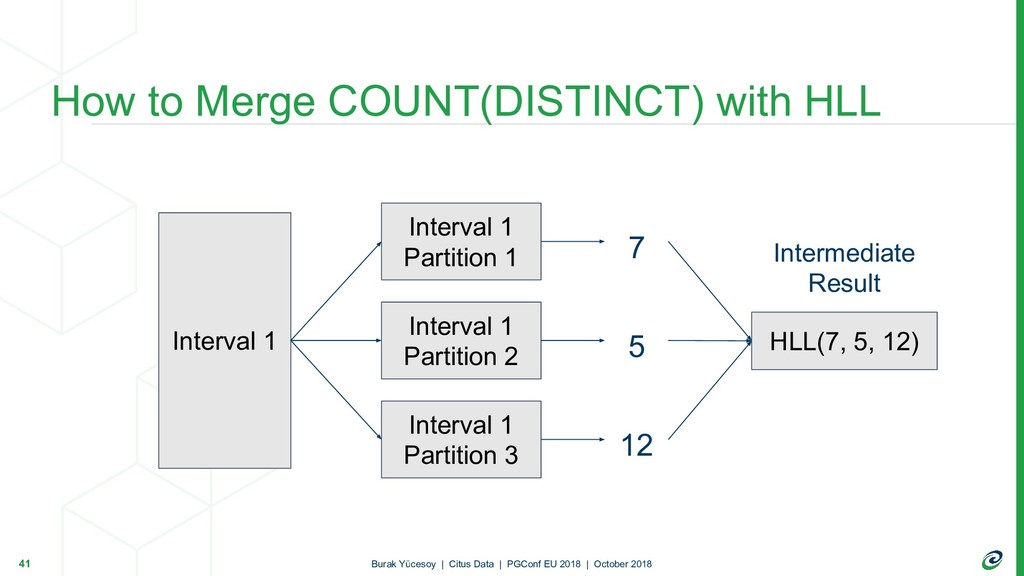{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}