【Apache Iceberg実践 ! ベストプラクティス】BigQueryのデータを低コストでSnowflakeから読めるようにするためにIcebergを使う / Using Iceberg for Cost-Effective BigQuery Data Access from Snowflake
• BigQuery から incremental sync するコネクタが提供されている • すでに Openflow を運⽤しているなら良い選択肢だが、BigQuery からのデータ取得のためだけに構 築‧運⽤するのは過剰 Snowflake Openflow SnowflakeからBigQueryをReadする選択肢 ref. About the Openflow Connector for Google BigQuery | Snowflake Documentation ref. Snowflake Openflow Unlocks Full Data Interoperability, Accelerating Data Movement for AI Innovation
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
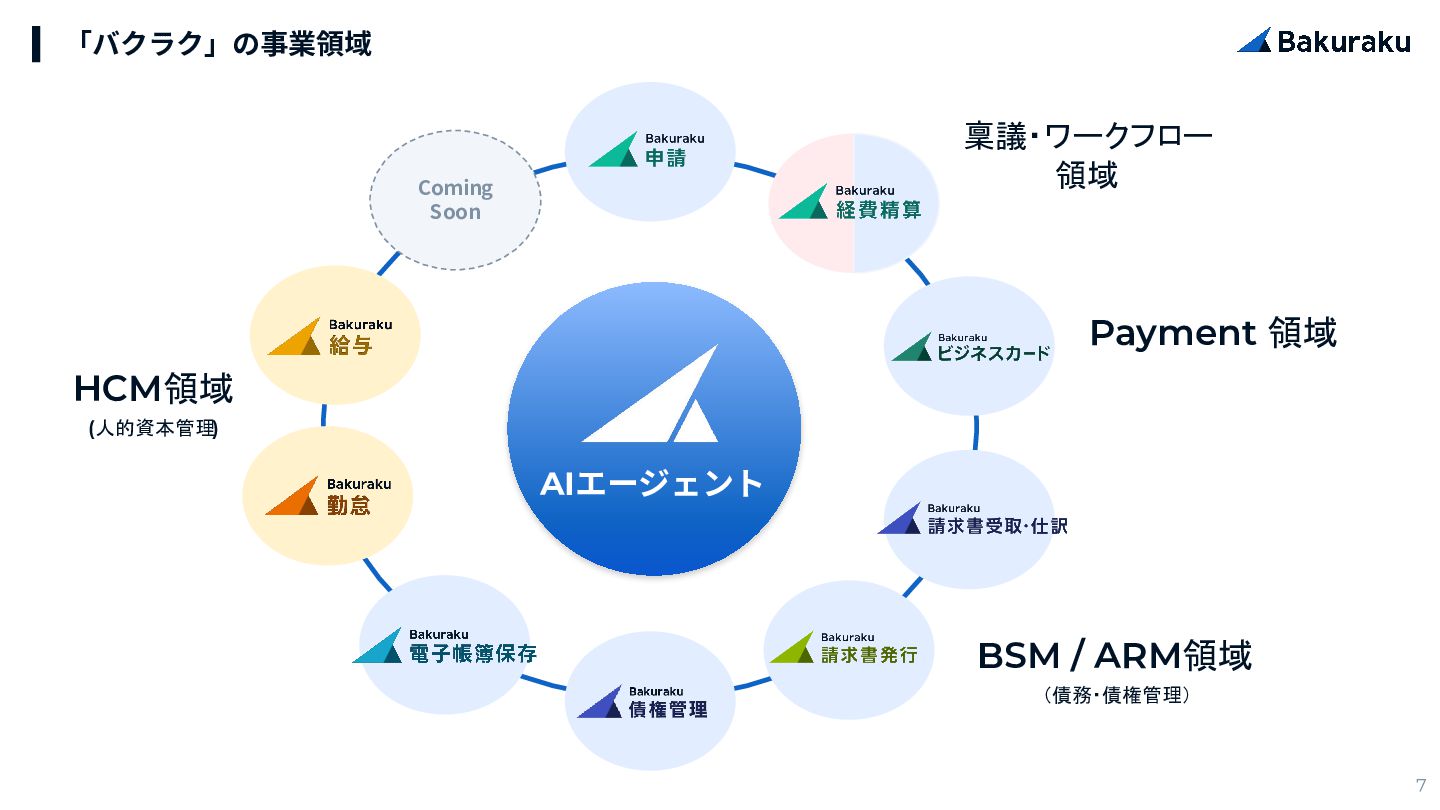{kind=link}
{kind=link}
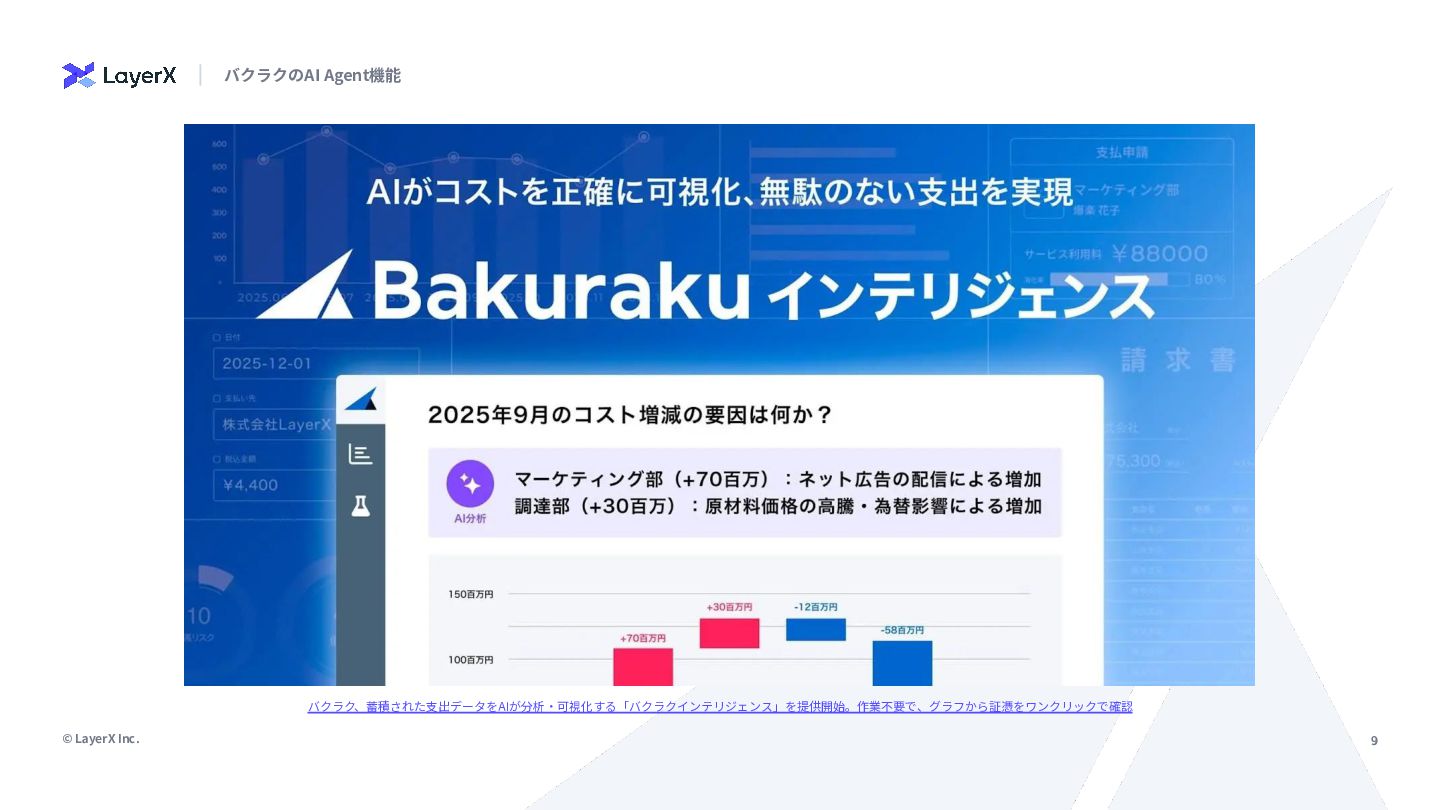{kind=link}
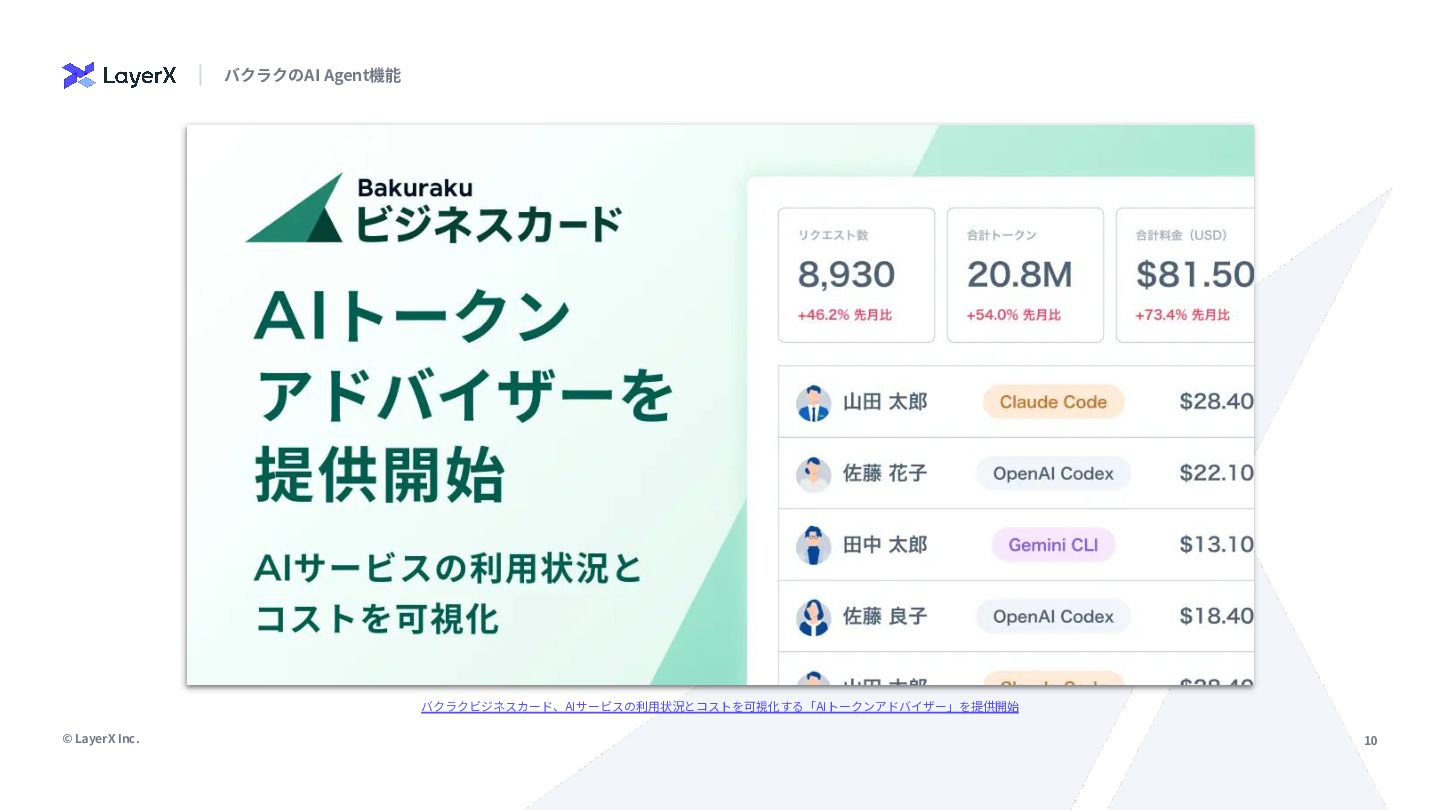{kind=link}
{kind=link}
{kind=link}
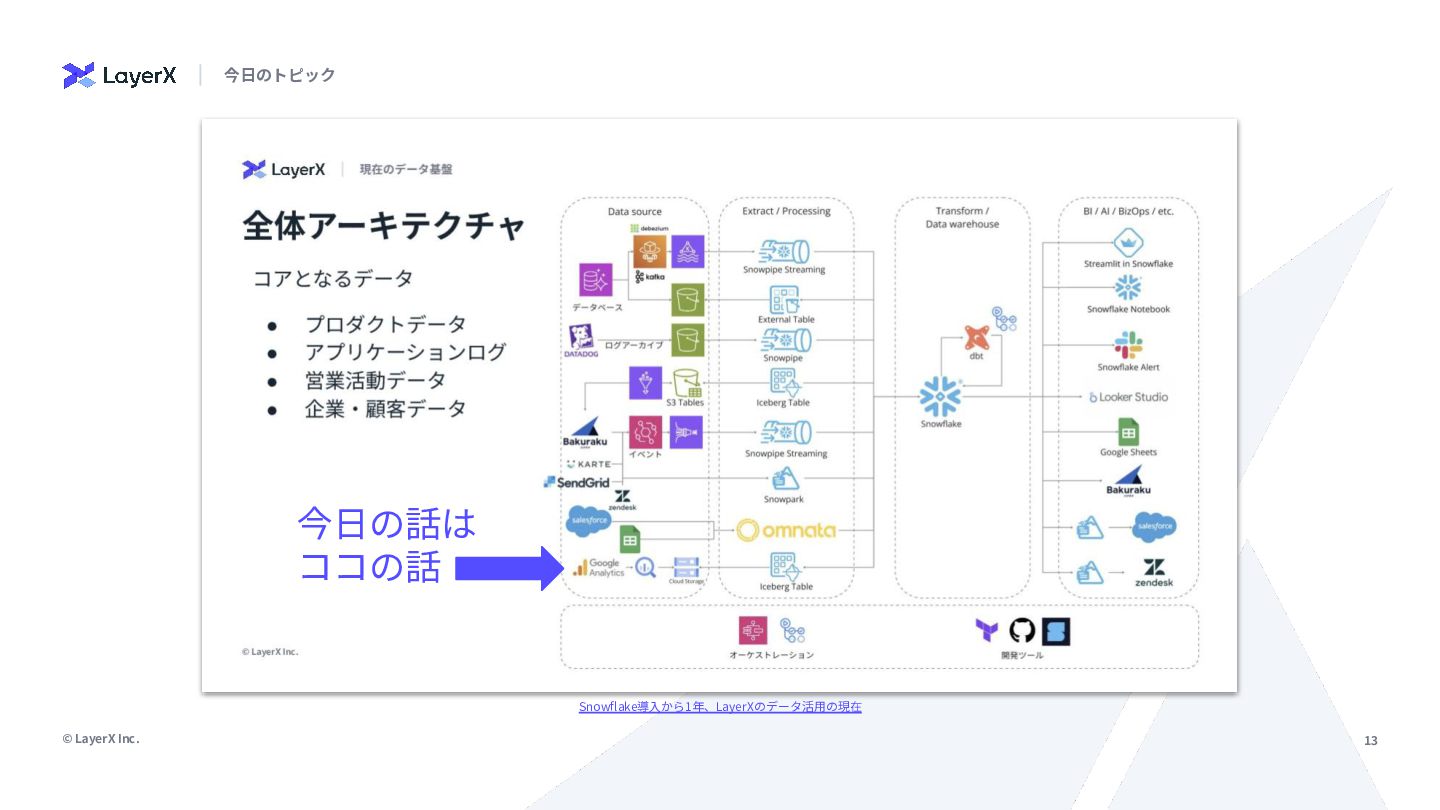{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}