"updated_at": "2025-11-12 03:11:00", "record": {"id": 5, "name": "taro", ...}} {"op" :"u", "updated_at": "2025-11-12 04:11:00", "record": {"id": 2, "name": "jiro-x", ...}} {"op" :"c", "updated_at": "2025-11-12 04:11:00", "record": {"id": 6, "name": "saburo", ...}} {"op" :"u", "updated_at": "2025-11-12 05:11:00", "record": {"id": 6, "name": "saburo-x", ...}} {"op" :"u", "updated_at": "2025-11-12 06:11:00", "record": {"id": 1, "name": "shiro-x", ...}} {"op" :"d", "updated_at": "2025-11-12 07:11:00", "record": {"id": 1, "name": "shiro-x", ...}} {"op" :"c", "updated_at": "2025-11-12 08:11:00", "record": {"id": 7, "name": "goro", ...}} {"op" :"d", "updated_at": "2025-11-12 09:11:00", "record": {"id": 7, "name": "goro", ...}} {"op" :"c", "updated_at": "2025-11-12 10:11:00", "record": {"id": 8, "name": "rokuro", ...}} {"op" :"u", "updated_at": "2025-11-12 11:11:00", "record": {"id": 8, "name": "rokuro-x", ...}} {"op" :"d", "updated_at": "2025-11-12 12:11:00", "record": {"id": 8, "name": "rokuro-x", ...}} {"op" :"u", "updated_at": "2025-11-12 13:11:00", "record": {"id": 3, "name": "nanakuro-x", ...}} {"op" :"u", "updated_at": "2025-11-12 14:11:00", "record": {"id": 3, "name": "nanakuro", ...}}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
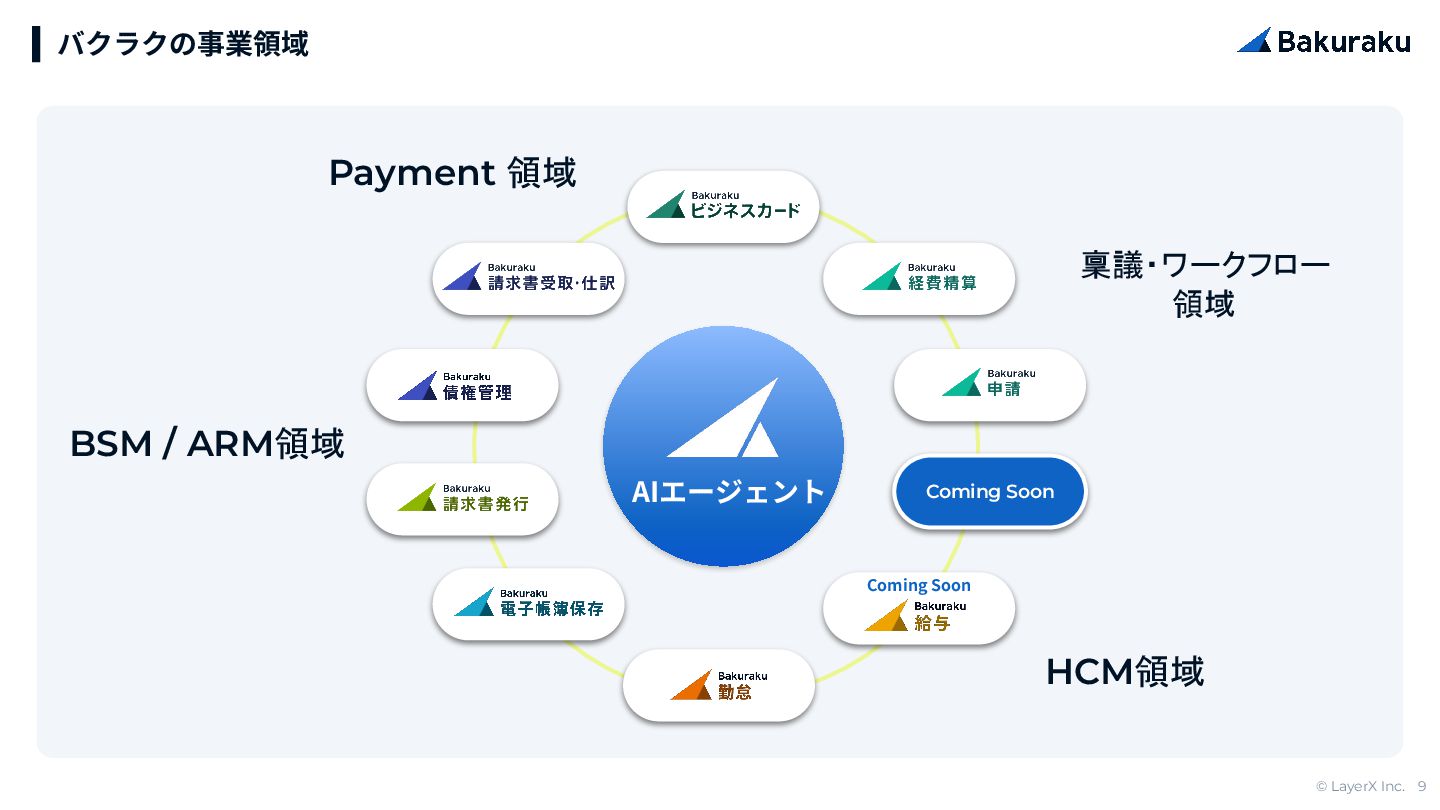{kind=link}
{kind=link}
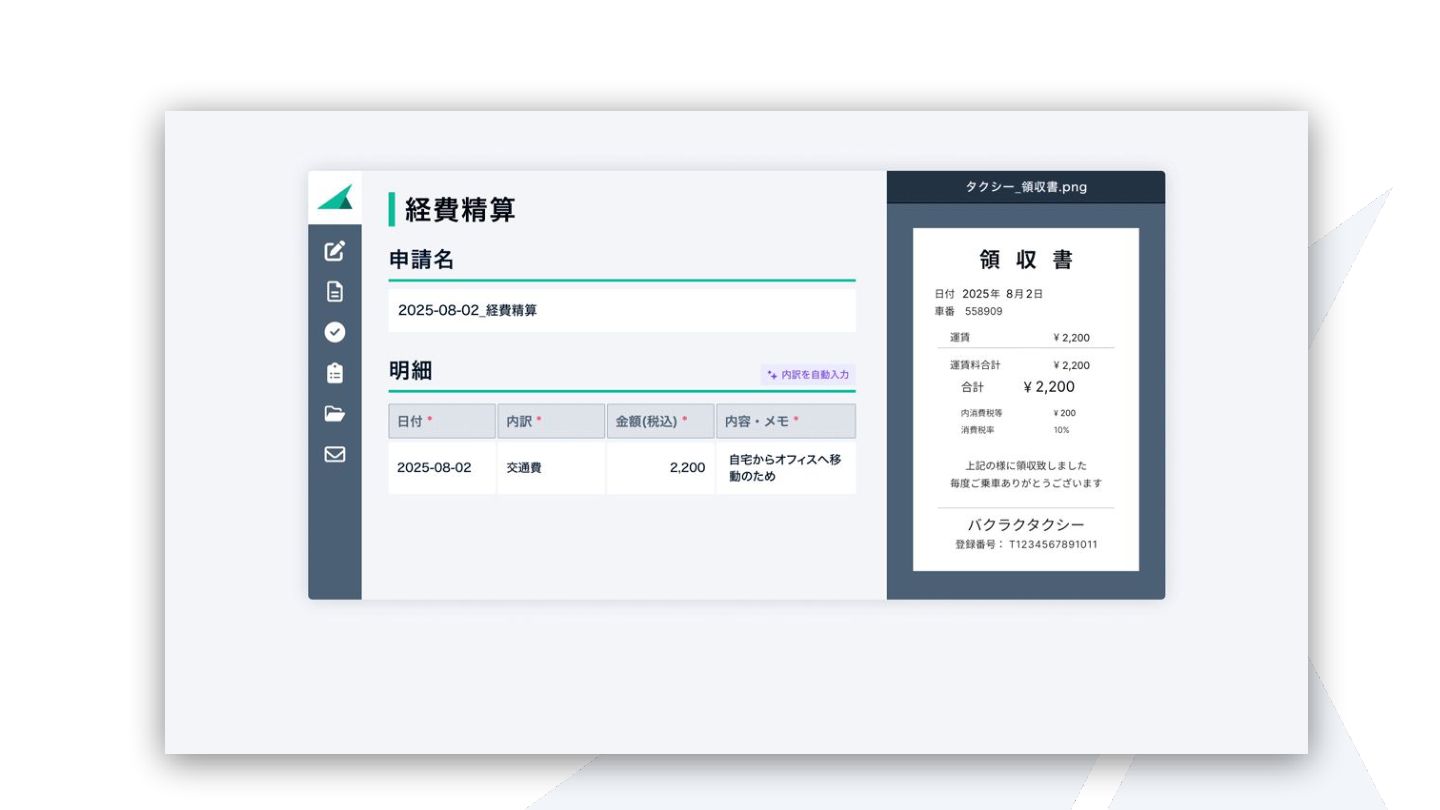{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
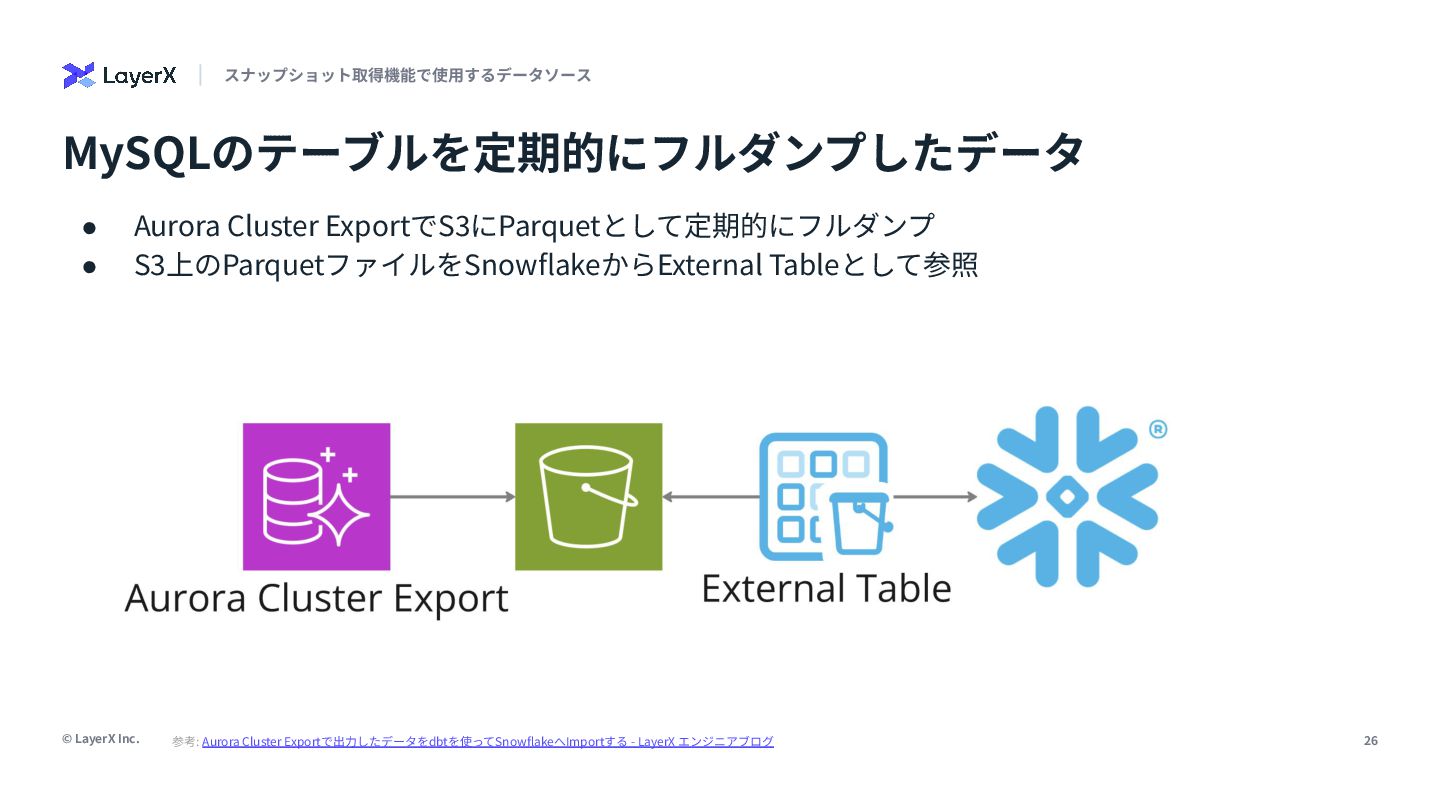{kind=link}
{kind=link}
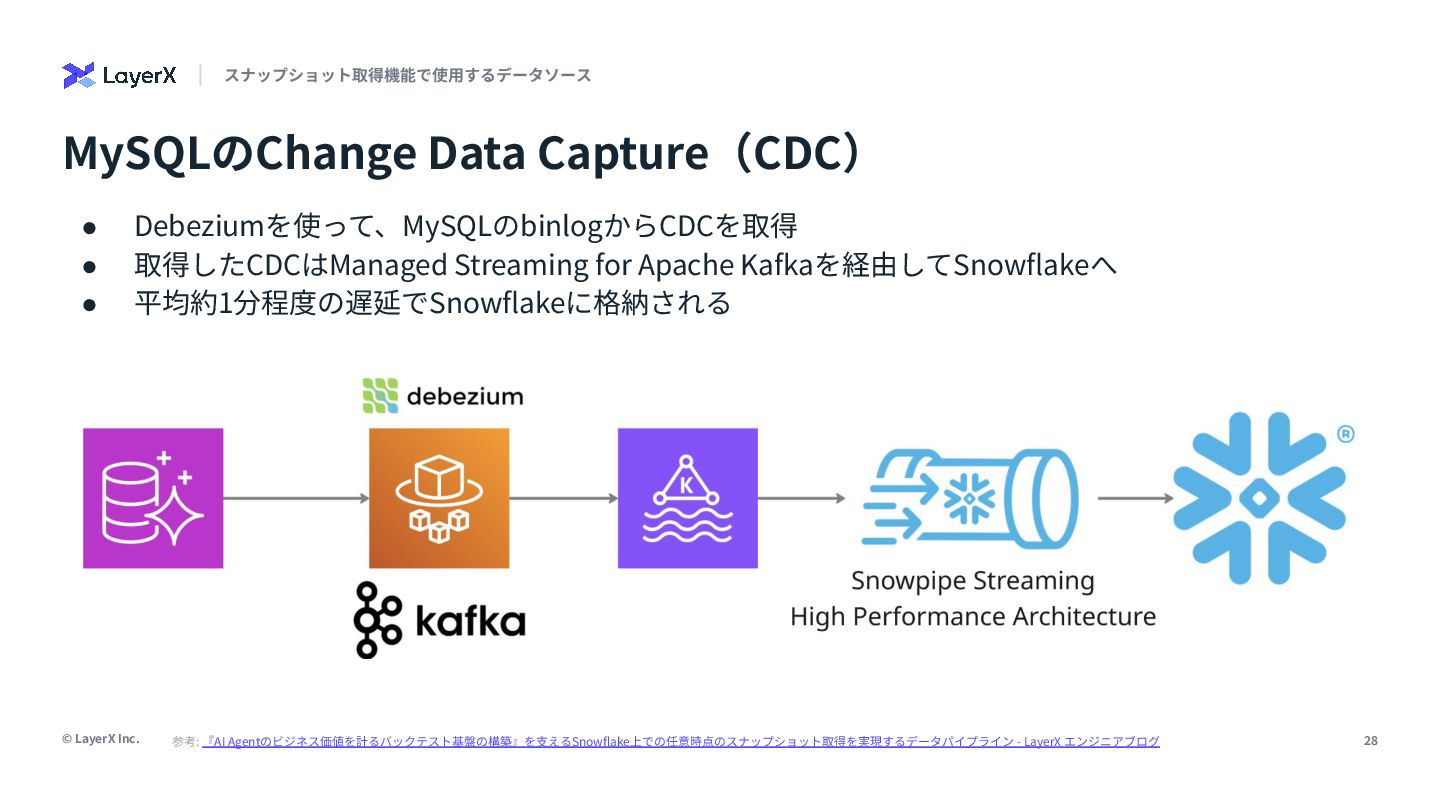{kind=link}
{kind=link}
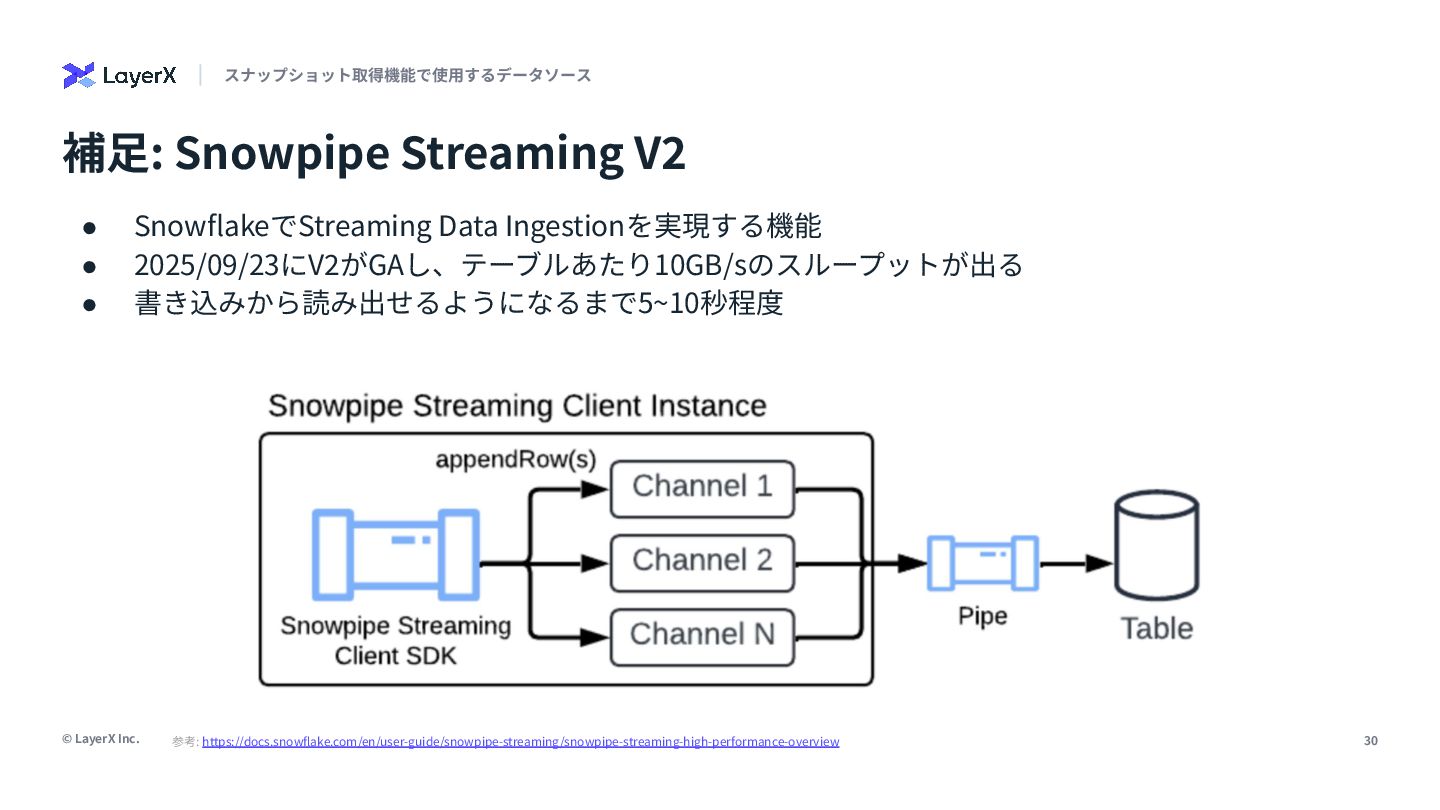{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
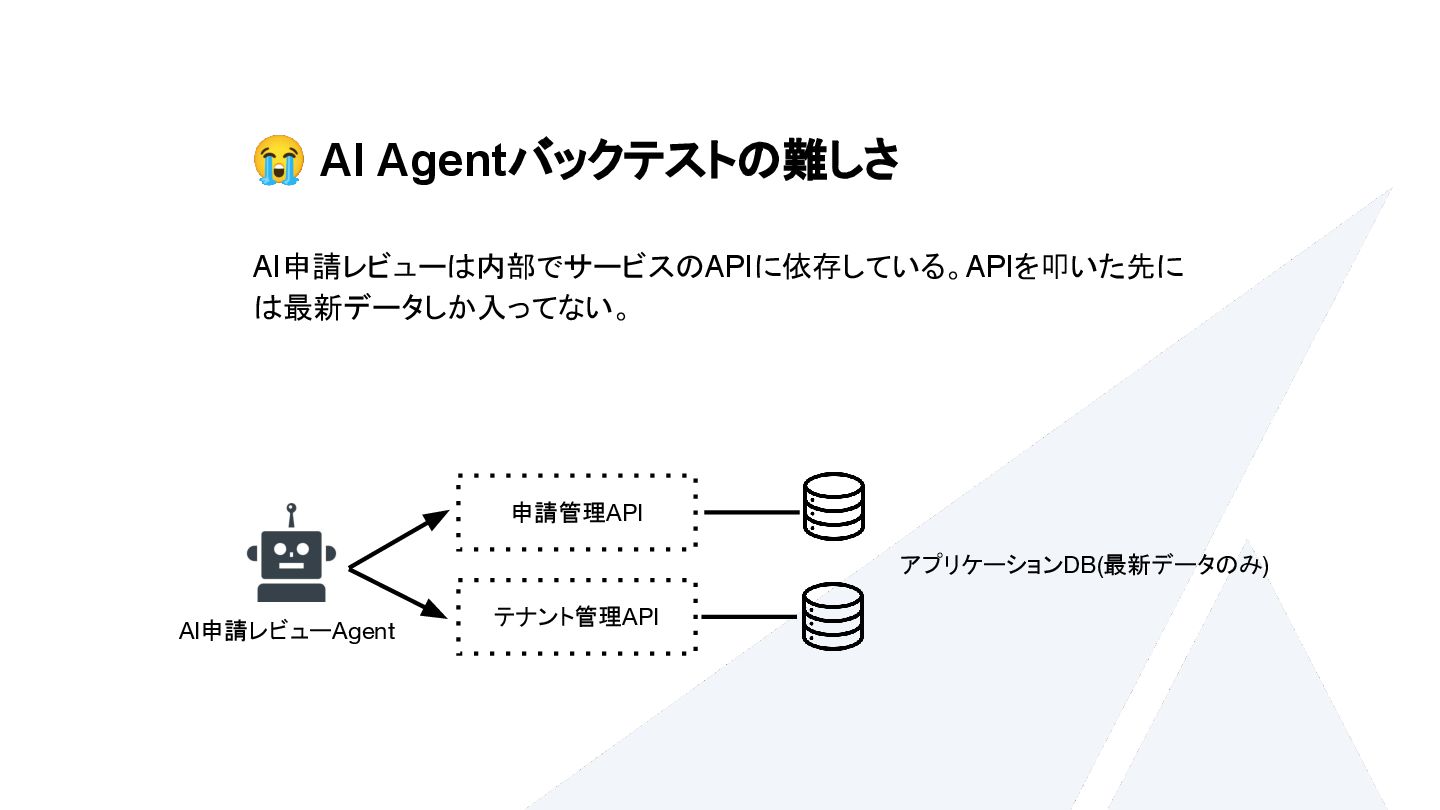{kind=link}
{kind=link}
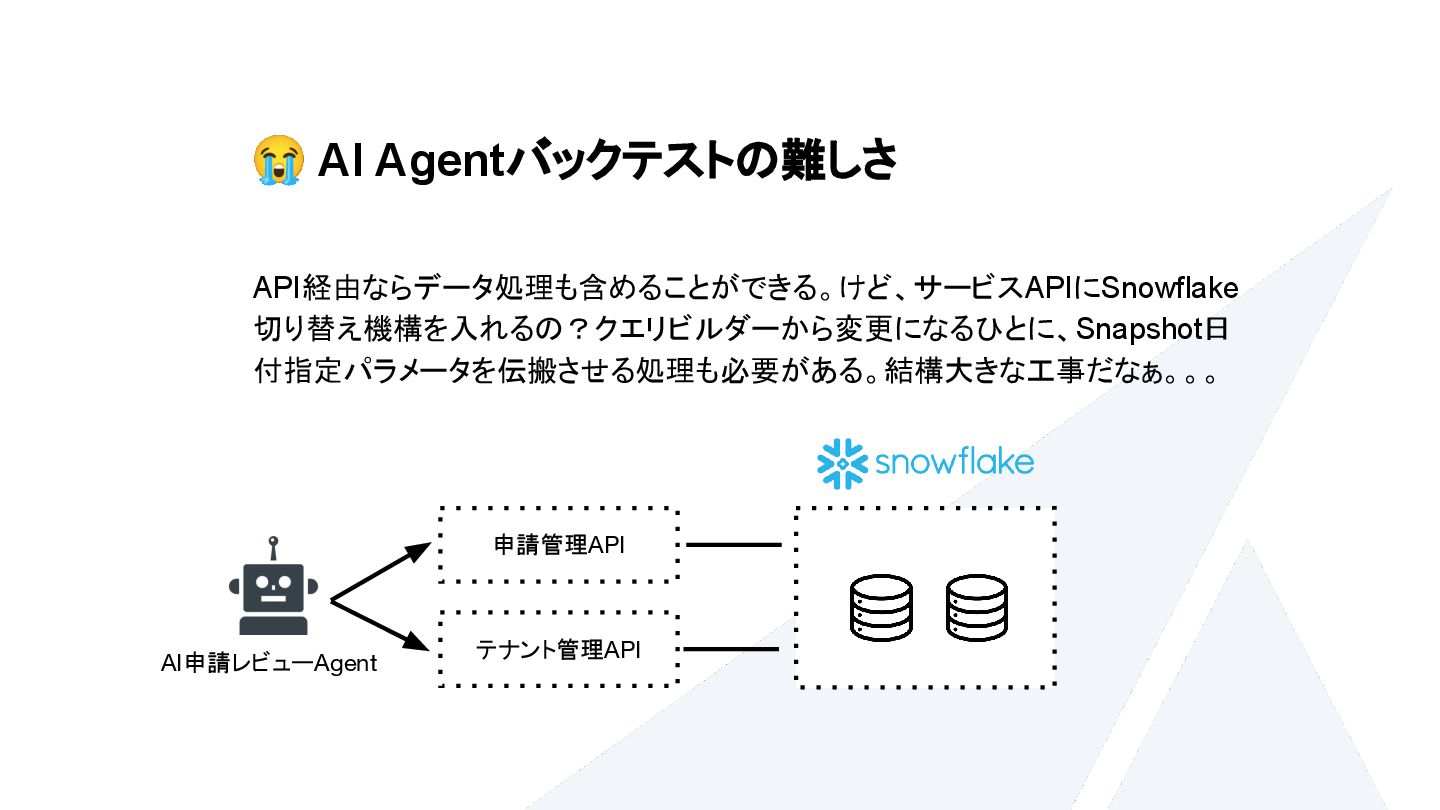{kind=link}
{kind=link}
{kind=link}
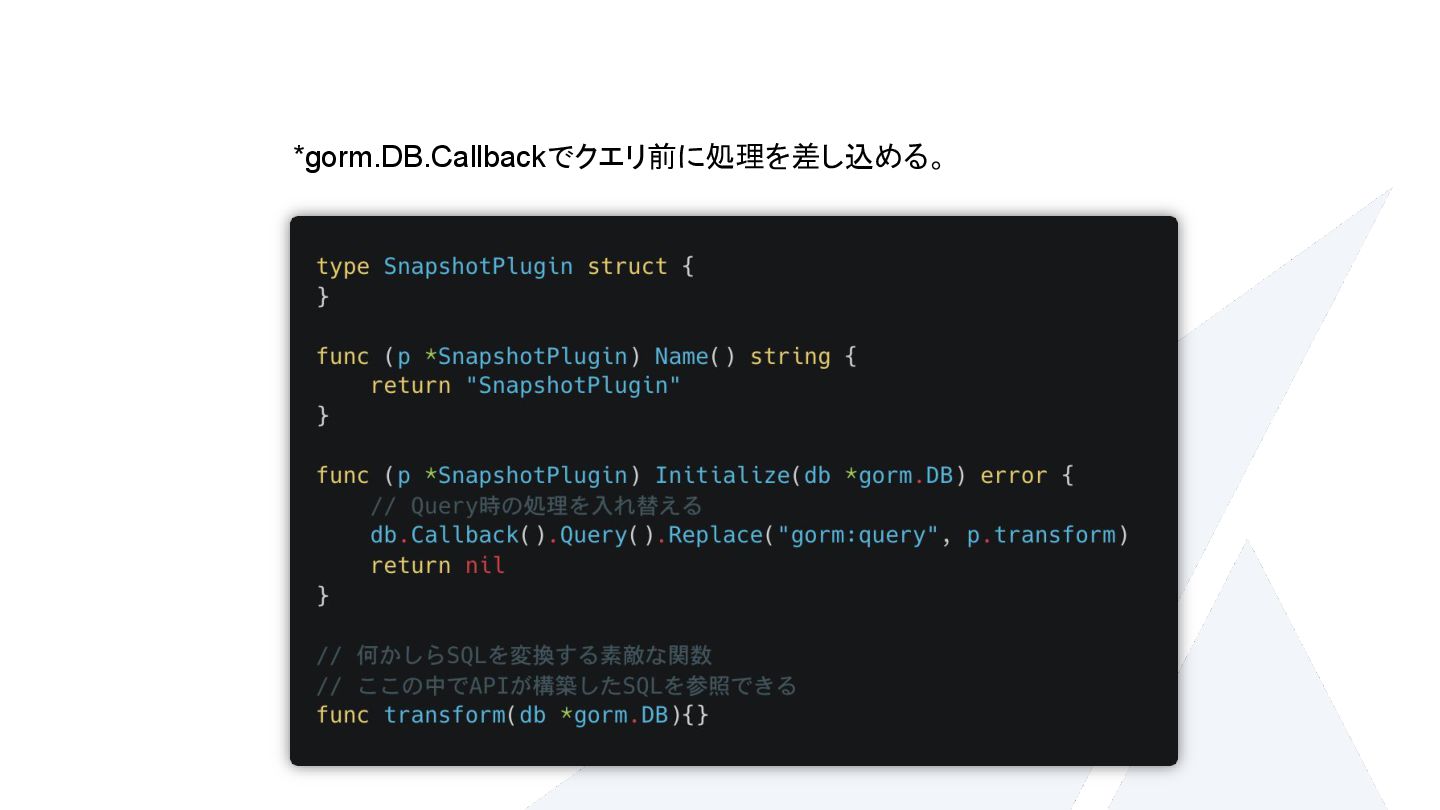{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
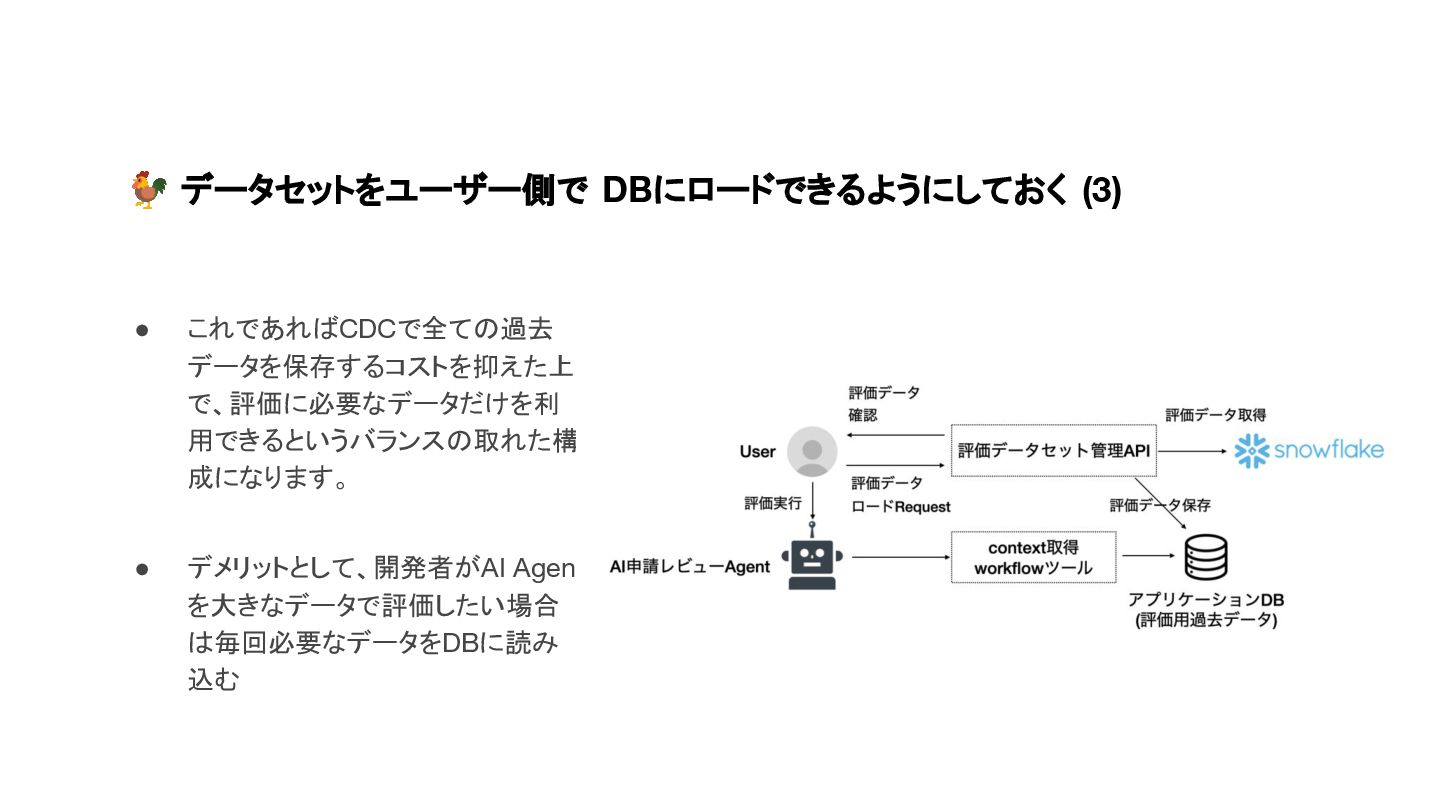{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}