A Comparative Analysis of Different NoSQL Databases on Data Model, Query Model and Replication Model
This was presented in the International Conference on Emerging Research in Computing, held during 02-03 Aug 2013 in Nitte Meenakhsi Institute of Technology, Bangalore, India..
QUERY MODEL AND REPLICATION MODEL By BASAWANTH RAO PRASHANTH K R Centre for Research Christ University, Hosur Road, Bangalore & CLARENCE J M TAURO Centre for Research Christ University, Hosur Road, Bangalore
• Are ACID Properties always desirable? • Basically available, Soft state, Eventually consistent (BASE) • The CAP Theorem • Motives of NoSQL Practitioner • Aim of the study • Validation procedure • Findings • Conclusion
web and business applications “one size fits all” - thinking concerning data-stores has been questioned Apply NoSQL databases for the persistence layer of a collaborative web application
of nothing • CONSISTENCY: Any transaction will take the database from one consistent state to another, with no broken constraints (referential integrity) • ISOLATION: Other operations cannot access the data that has been modified during a transaction that has not been completed • DURABILITY: Ability to recover the committed transaction updates against any kind of system failure
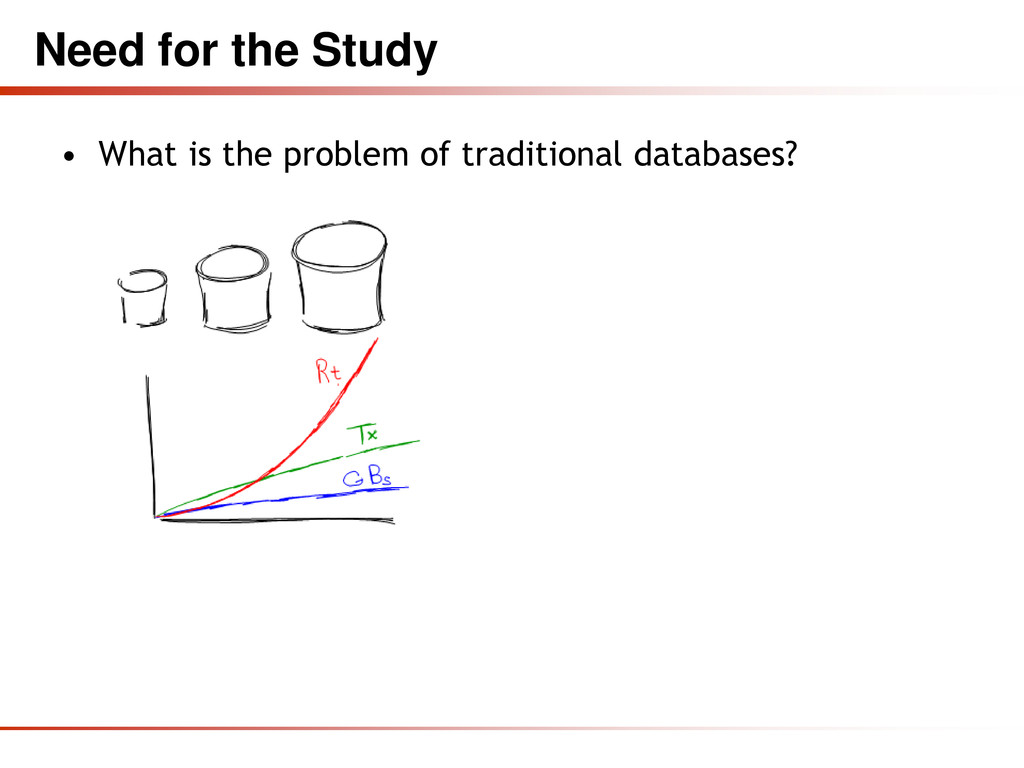
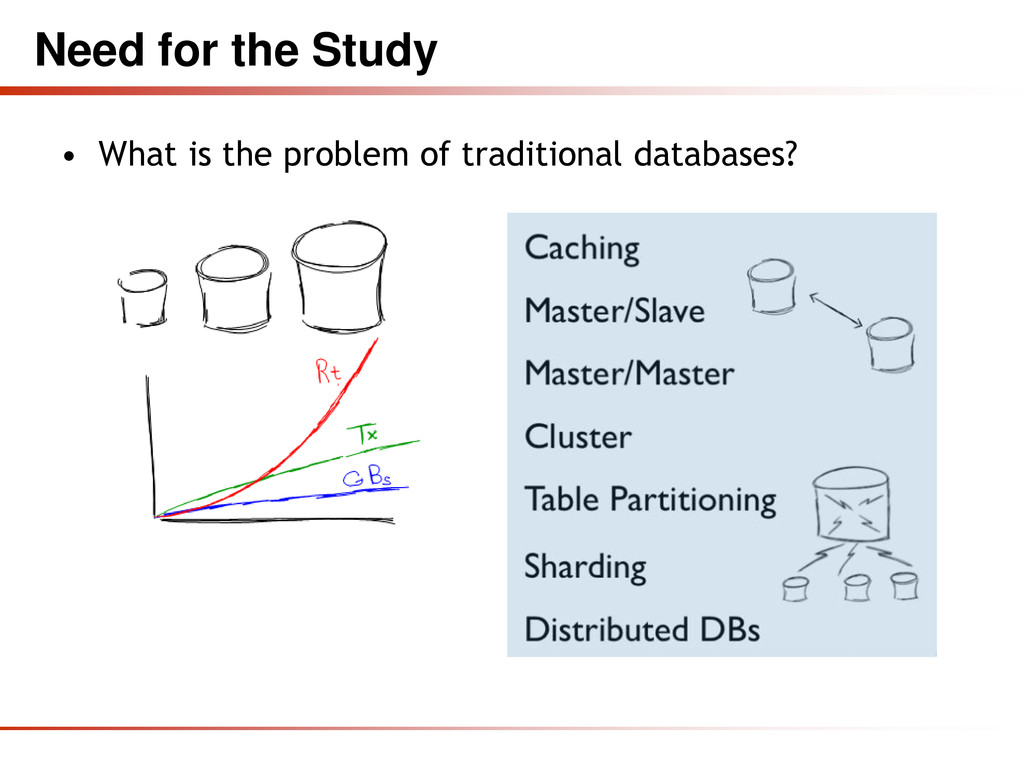
High Throughput • Horizontal Scalability and Running on Commodity Hardware • Avoidance of Expensive Object-Relational Mapping • Complexity and Cost of Setting up Database Clusters • Compromising Reliability for Better Performance • The Current “One size fit’s it all” Databases Thinking Was and Is Wrong
• Analyze few selected databases and to test by benchmarking and categorizing their performance • Develop a framework in order to assist the creation and execution of the benchmarks • Develop prototypes by making use of NoSQL technologies • Apply the developed prototypes for comparing the NoSQL databases with the traditional solutions of relational databases
Analysis of data model, query model, replication model and consistency model. Persistence Layer, Model Driven Development, Object Notations (Not discussed in the presentation)
examined NoSQL databases • Comparison of the range querying capabilities of the examined NoSQL databases • Comparison of the aggregation functionalities • Comparison of the durability properties • The performance of the MongoDB store is compared against the stores for MySQL and the in memory version of HSQL CASE STUDY
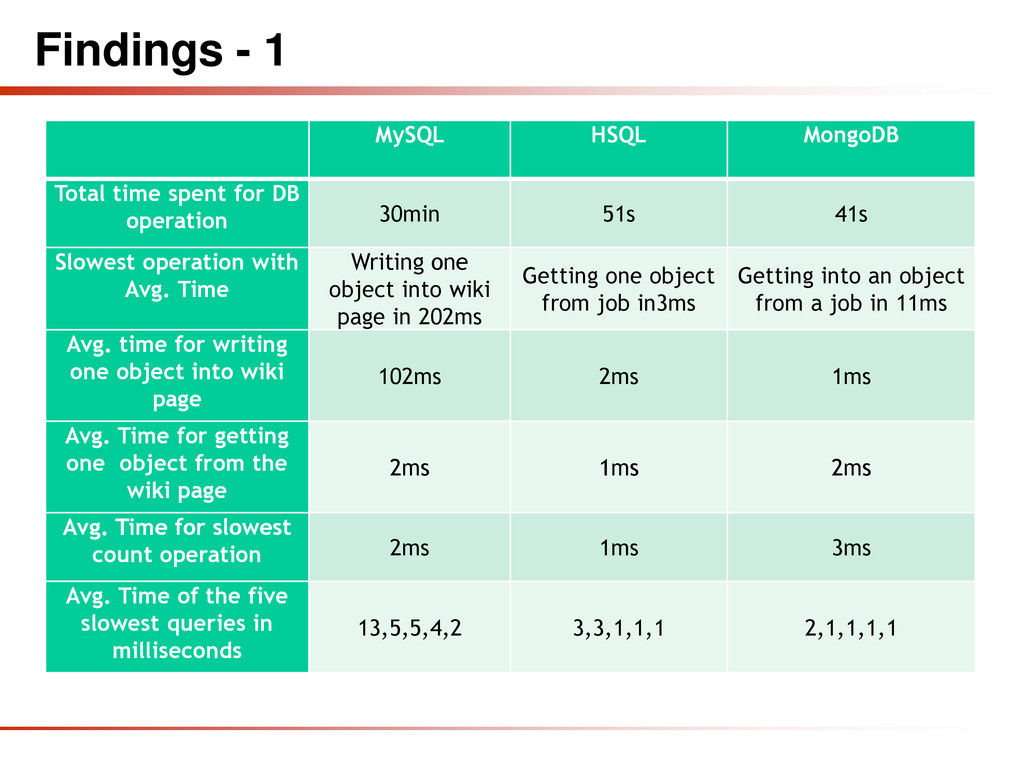
DB operation 30min 51s 41s Slowest operation with Avg. Time Writing one object into wiki page in 202ms Getting one object from job in3ms Getting into an object from a job in 11ms Avg. time for writing one object into wiki page 102ms 2ms 1ms Avg. Time for getting one object from the wiki page 2ms 1ms 2ms Avg. Time for slowest count operation 2ms 1ms 3ms Avg. Time of the five slowest queries in milliseconds 13,5,5,4,2 3,3,1,1,1 2,1,1,1,1
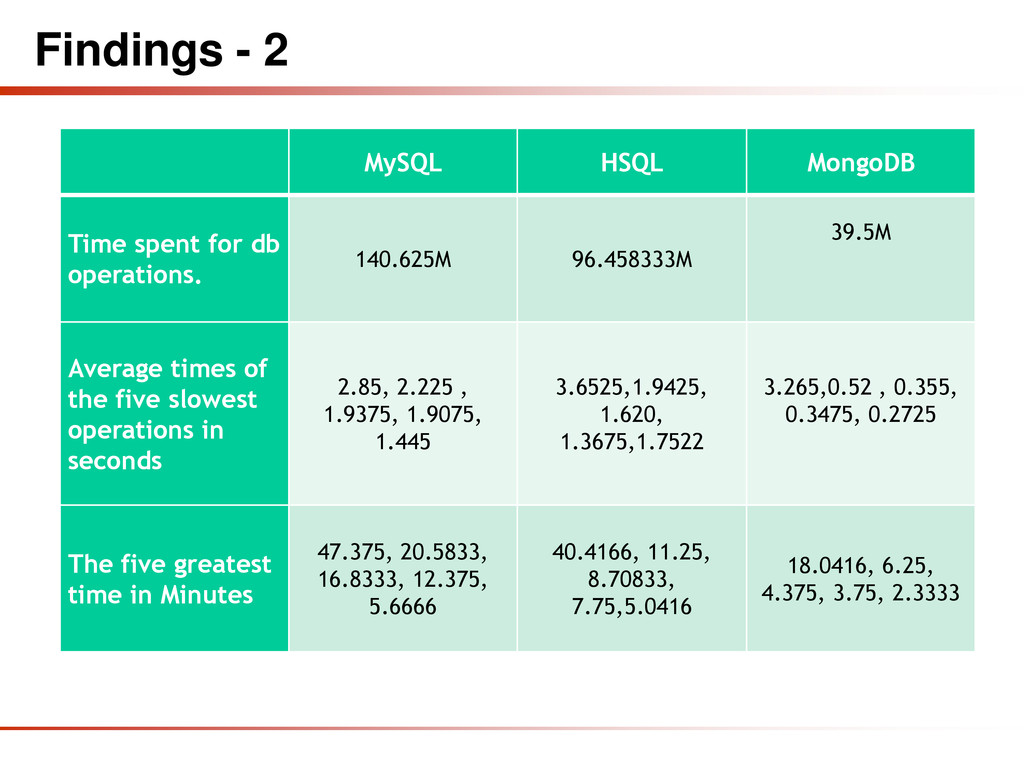
operations. 140.625M 96.458333M 39.5M Average times of the five slowest operations in seconds 2.85, 2.225 , 1.9375, 1.9075, 1.445 3.6525,1.9425, 1.620, 1.3675,1.7522 3.265,0.52 , 0.355, 0.3475, 0.2725 The five greatest time in Minutes 47.375, 20.5833, 16.8333, 12.375, 5.6666 40.4166, 11.25, 8.70833, 7.75,5.0416 18.0416, 6.25, 4.375, 3.75, 2.3333
can contribute to the development of a systematic approach for solving problems of data persistence with an alternative non-relational database • The careful examination of NoSQL databases and their application creates a common set of design patterns that may be reused when modeling data and designing a database
used NoSQL databases. – Still, a large number of NoSQL databases exists; each building on different aspects that could also be studied • The benchmarks could also be extended in order to include different workload scenarios – by varying the percentage of read and write operations but also by using different distributions for selecting objects other than the uniform distribution • Repeat the benchmarks using an infrastructure to that used in a production environment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Objectives of the Study [Other] • Analyze various non-relational databases](https://files.speakerdeck.com/presentations/a8dba980eac201300f986a82ce07c0b0/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}