https://2015.codefest.ru/lecture/1000
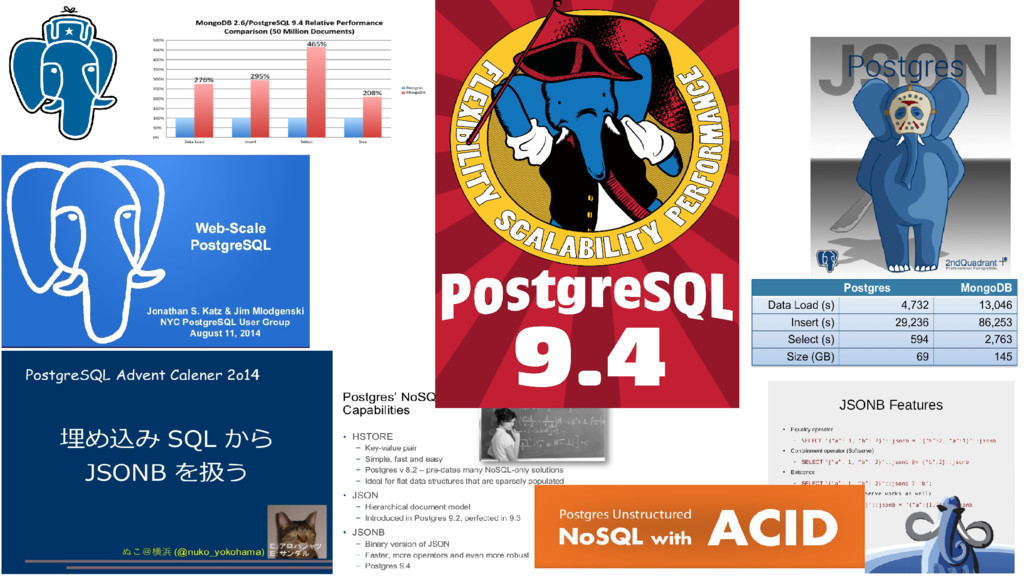
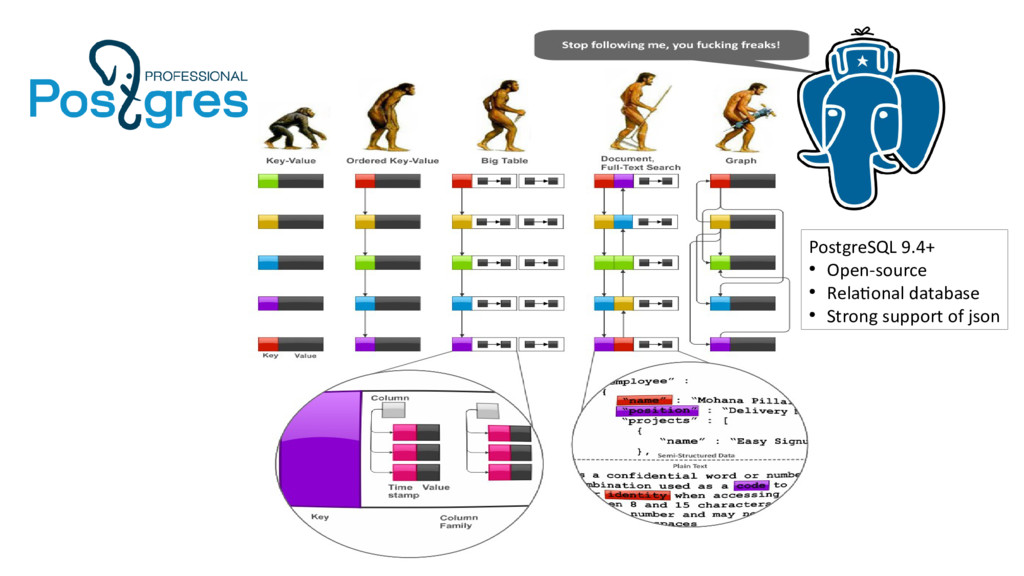
С выходом релиза 9.4 пользователям Постгреса открылись возможности использования NoSQL в реляционной СУБД, а именно — возможность эффективной работы с документно-ориентированной моделью данных, реализованной в виде нового типа данных jsonb.
Уже сейчас можно говорить о shemaless PostgreSQL, более частых релизах проекта без оглядки на изменение схемы данных. Разработчики Node, Python, Go или Ruby теперь могут использовать «быстрый» JSON в надежной базе данных с развитой функциональностью.
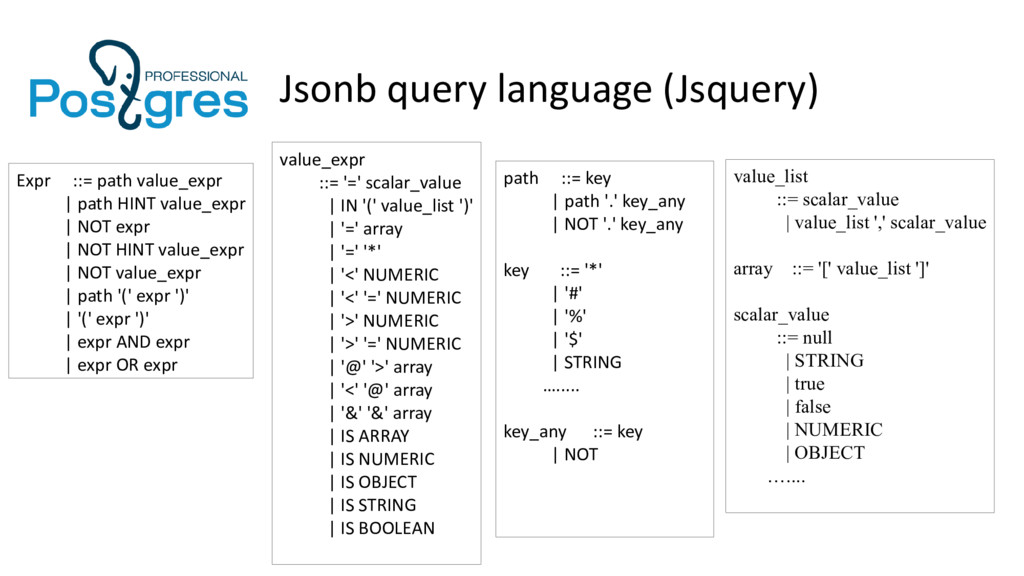
Однако эта первая реализация jsonb содержит небольшой набор операторов и функций, поэтому нами разработан язык запросов jsquery, который поддерживает больше операторов сравнения, поиски в массивах, поиски по ключам и новые индексы для этих операторов. Я расскажу про реализацию и ограничения текущей версии jsquery, покажу примеры использования. Также я остановлюсь на планах по развитию jsquery.
{kind=link}
![Alexander Korotkov [email protected] • Indexed regexp search • GIN compression](https://files.speakerdeck.com/presentations/7e96c8bed4474b80a120d1c265dc0371/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
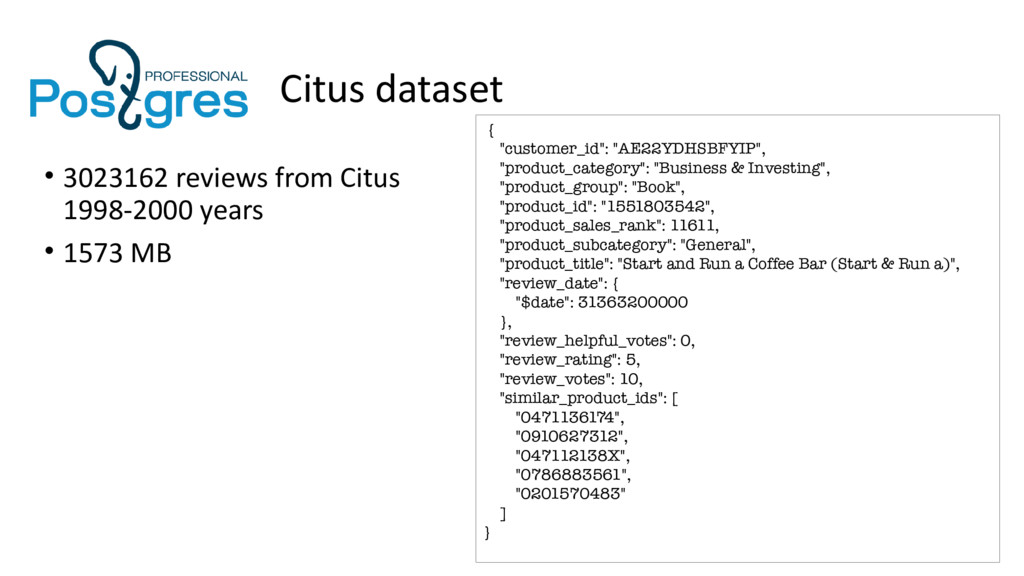
![MongoDB 2.6.0 db.reviews.find( { $and :[ {similar_product_ids: { $in:["B000089778"]}}, {product_sales_rank:{$gt:10000,](https://files.speakerdeck.com/presentations/7e96c8bed4474b80a120d1c265dc0371/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}