11g, 12c Ent/SE/SEone RDS 11g, 12c Ent/SE/SEone 11g, 12c Ent/SE/SEone MySQL on-prem/EC2 5.5, 5.6 5.5, 5.6 RDS 5.5, 5.6 5.5, 5.6 PostgreSQL on-prem/EC2 9.4 9.3以降 RDS 9.4 9.3以降 SQL Server on-prem/EC2 2005, 2008, 2008R2, 2012, 2014 Ent, Std, Workgroup, Developer 2005, 2008, 2008R2, 2012, 2014 Ent, Std, Workgroup, Developer RDS 2008R2, 2012, 2014 Ent, Std, Workgroup, Developer ※1 2008R2, 2012, 2014 Ent, Std, Workgroup, Developer Aurora RDS MySQL互換としてサポート MySQL互換としてサポート ※1:CDC利用不可
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
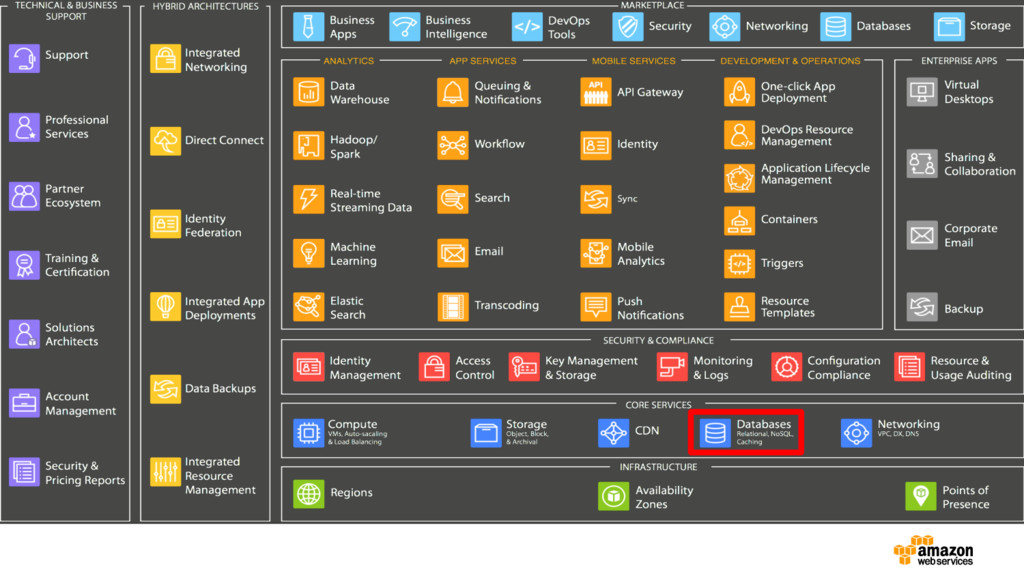{kind=link}
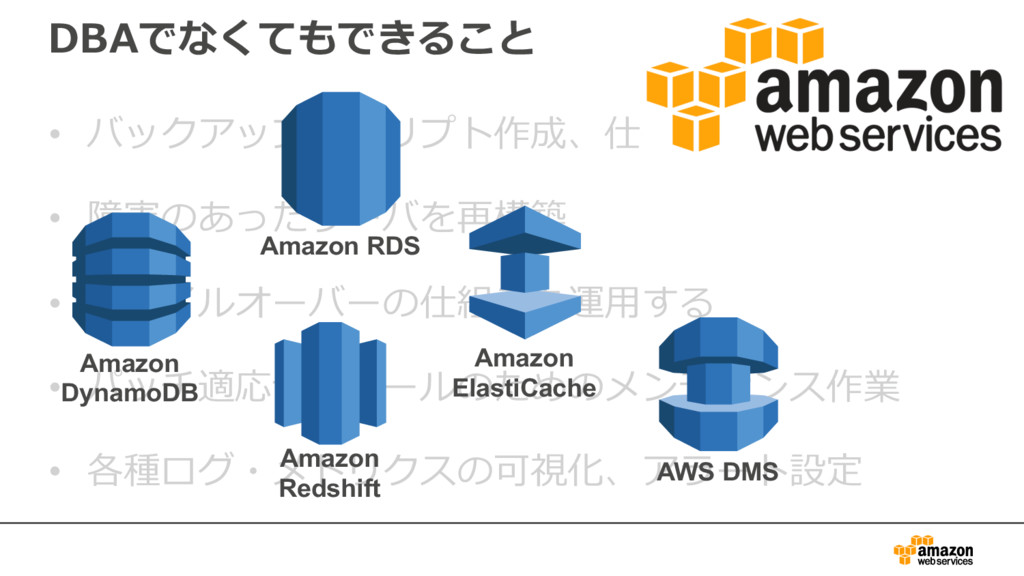{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
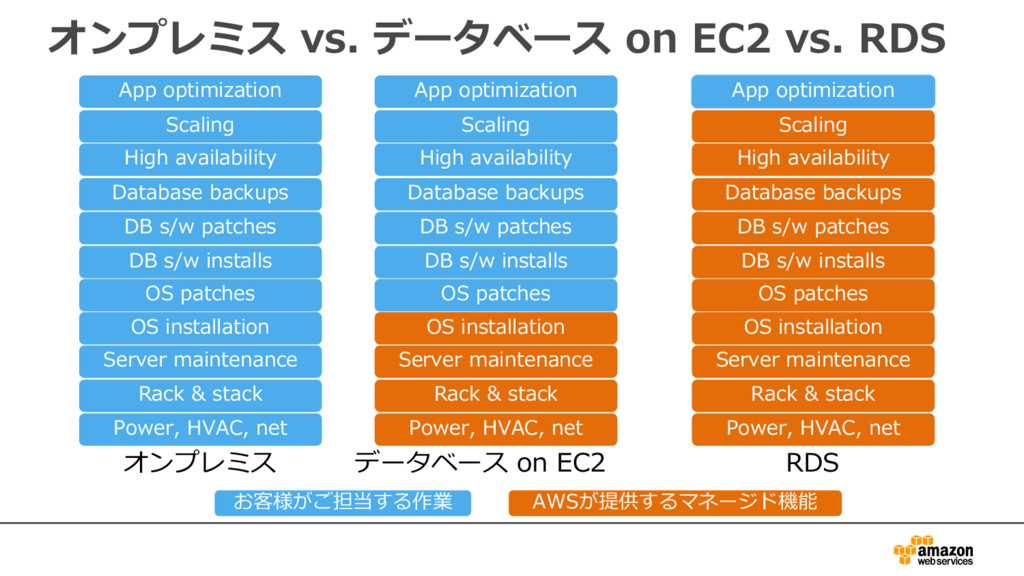{kind=link}
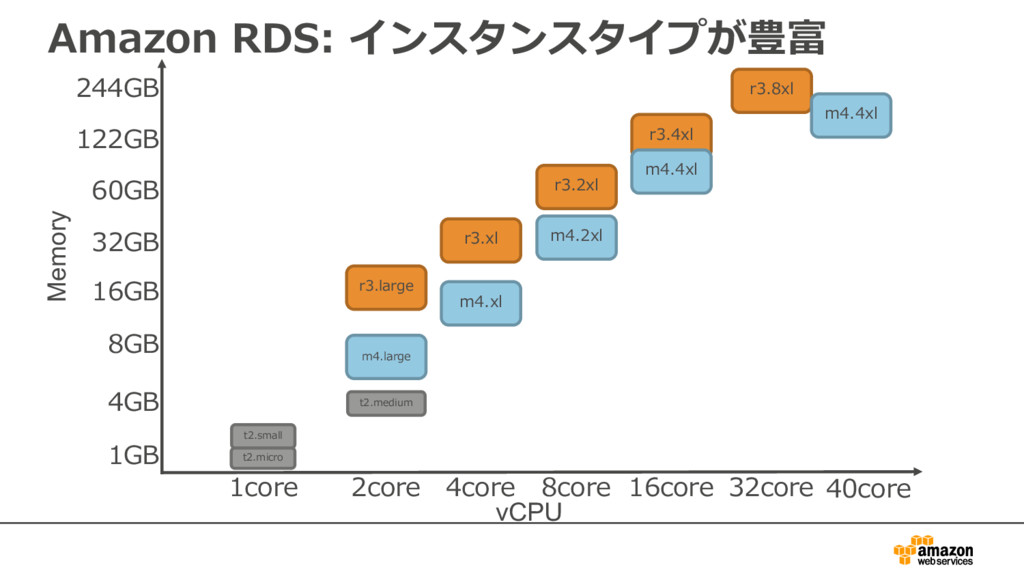{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Routingルール • データベース情報の設定 [databases] dev = host= port=5439 dbname=dev dev.1](https://files.speakerdeck.com/presentations/7a616625b5984000833e62562ddf2736/slide_70.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}