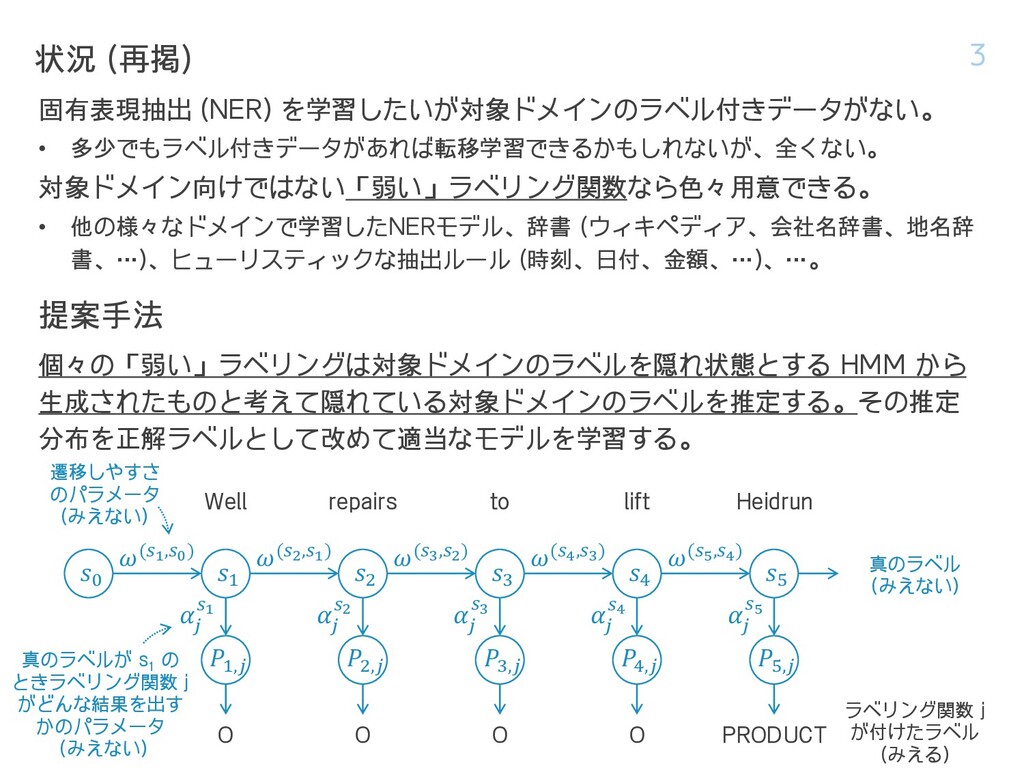
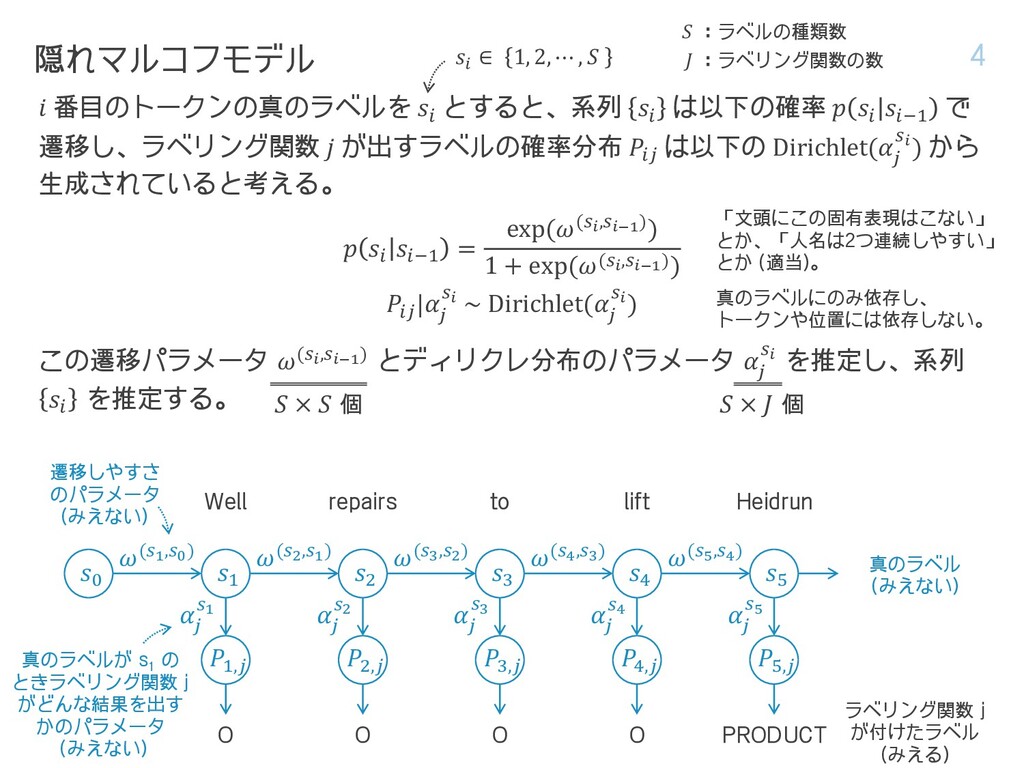
遷移し、ラベリング関数 𝑗 が出すラベルの確率分布 𝑃𝑖𝑗 は以下の Dirichlet(𝛼 𝑗 𝑠𝑖) から 生成されていると考える。 𝑝 𝑠𝑖 𝑠𝑖−1 = exp(𝜔(𝑠𝑖,𝑠𝑖−1)) 1 + exp(𝜔(𝑠𝑖,𝑠𝑖−1)) 𝑃𝑖𝑗 |𝛼 𝑗 𝑠𝑖 ~ Dirichlet(𝛼 𝑗 𝑠𝑖) この遷移パラメータ 𝜔(𝑠𝑖,𝑠𝑖−1) とディリクレ分布のパラメータ 𝛼 𝑗 𝑠𝑖 を推定し、系列 𝑠𝑖 を推定する。 隠れマルコフモデル 4 𝑠0 𝑠1 𝑃1,𝑗 𝛼 𝑗 𝑠1 𝜔(𝑠1,𝑠0) 𝑠2 𝑃2,𝑗 𝛼 𝑗 𝑠2 𝜔(𝑠2,𝑠1) 𝑠3 𝑃3,𝑗 𝛼 𝑗 𝑠3 𝜔(𝑠3,𝑠2) 𝑠4 𝑃4,𝑗 𝛼 𝑗 𝑠4 𝜔(𝑠4,𝑠3) 𝑠5 𝑃5,𝑗 𝛼 𝑗 𝑠5 𝜔(𝑠5,𝑠4) Well repairs to lift Heidrun O O O O PRODUCT 真のラベル (みえない) ラベリング関数 j が付けたラベル (みえる) 遷移しやすさ のパラメータ (みえない) 真のラベルが s 1 の ときラベリング関数 j がどんな結果を出す かのパラメータ (みえない) 𝑆 × 𝑆 個 𝑆 × 𝐽 個 真のラベルにのみ依存し、 トークンや位置には依存しない。 𝑠𝑖 ∈ 1, 2, ⋯ , 𝑆 𝑆 :ラベルの種類数 𝐽 :ラベリング関数の数 「文頭にこの固有表現はこない」 とか、「人名は2つ連続しやすい」 とか (適当)。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![【参考】Transition-Based NER [Lample 2016] 8 スタックLSTM アクション スタック バッファ アウトプット](https://files.speakerdeck.com/presentations/63cb5aaf51a443b49faa8315aa35c6ea/slide_7.jpg){kind=link}
![【参考】LSTM + CRF層モデル [Lample 2016] 9 ニューラルネットによる系列ラベリング (固有表現抽出、品詞タグ付け) では、単に各ステッ プの予測確率最大のラベルを拾ったのでは系列として整合性が取れない場合があるので、各](https://files.speakerdeck.com/presentations/63cb5aaf51a443b49faa8315aa35c6ea/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
![参考文献 12 • [Lample 2016] Guillaume Lample, Miguel Ballesteros, Sandeep](https://files.speakerdeck.com/presentations/63cb5aaf51a443b49faa8315aa35c6ea/slide_11.jpg){kind=link}