Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Speech and Language Processing 5章 ロジスティック回帰
Search
CookieBox26
May 20, 2020
Science
370
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Speech and Language Processing 5章 ロジスティック回帰
CookieBox26
May 20, 2020
More Decks by CookieBox26
See All by CookieBox26
ずんだもんと雪さんとDeepSeek-R1-Zero
cookiebox26
0
1.4k
svm as a constrainted optimization
cookiebox26
0
120
最近のTransformer関連の論文から
cookiebox26
0
320
KDD2021の多変量時系列関連のタイトルいくつか
cookiebox26
0
320
固有表現抽出をドメイン外の弱いラベリングたちから学習する
cookiebox26
0
120
Speech and Language Processing 9章 RNNによる系列の処理
cookiebox26
0
2.3k
LSTM to GRU
cookiebox26
0
300
「統計的因果推論」勉強会 「1. 古典的問題意識」
cookiebox26
0
950
レヴィ過程の経験尤度推定の紹介
cookiebox26
0
670
Other Decks in Science
See All in Science
Van Dare naar Durf
voginip
0
250
AI bij literatuuronderzoek in de wetenschap
voginip
0
200
Kaggle: NeurIPS - Open Polymer Prediction 2025 コンペ 反省会
calpis10000
0
620
生成AIと司法書士の未来.pdf
tagtag
PRO
0
130
ITTF卓球世界ランキングのポイント比を用いた試合結果予測モデルの性能評価 / Performance evaluation of match result prediction models using the point ratio of the ITTF Table Tennis World Ranking
konakalab
0
140
明治薬科大学講義_ビッグデータ解析を支えるデータベース技術とクラウドコンピューティング
ktatsuya
1
130
なぜエネルギーは保存する? 〜自由落下でわかる“対称性”とネーターの定理〜
syotasasaki593876
0
200
Cross-Media Technologies, Information Science and Human-Information Interaction
signer
PRO
3
32k
俺たちは本当に分かり合えるのか? ~ PdMとスクラムチームの “ずれ” を科学する
bonotake
2
2.5k
機械学習 - DBSCAN
trycycle
PRO
0
1.9k
データベース04: SQL (1/3) 単純質問 & 集約演算
trycycle
PRO
0
1.5k
人生を変えた一冊「独学大全」のはなし / Self-study ENCYCLOPEDIA: The Book Which Change My Life #独学大全 #EM推し本
expajp
0
170
Featured
See All Featured
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.6k
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
860
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
Building an army of robots
kneath
306
46k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
Six Lessons from altMBA
skipperchong
29
4.3k
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
Transcript
Speech and Language Processing 5 章 ロジスティック回帰 2020 年 5
月 20 日 三原 千尋 テキスト Dan Jurafsky and James H. Martin. Speech and Language Processing (3rd ed. draft). https://web.stanford.edu/~jurafsky/slp3/
今回の問題設定 以下のような問題設定を考える (2 クラス分類)。 • M 個の正解ラベル付きの訓練用データがある。 (x(1), y(1)), (x(2),
y(2)), · · · , (x(M), y(M)) • 各データは n 個の数値特徴 x(i) j からなる。 x(i) = (x(i) 1 , x(i) 2 , · · · , x(i) n )⊤ • 各正解ラベルは y(i) ∈ {0, 1} である。 • 未知データ x を入れたら P(y = 1|x) を出す箱がほしい。 ※ P(y = 0|x) = 1 − P(y = 1|x) である。 例. ある映画レビューサイトに投稿されたレビューの分類 • x(i) : 訓練用データの i 番目のレビュー文章。 • y(i) ∈ { ネガティブ, ポジティブ } • x(i) j : x(i) に単語 j が登場した回数 (例えば)。 1
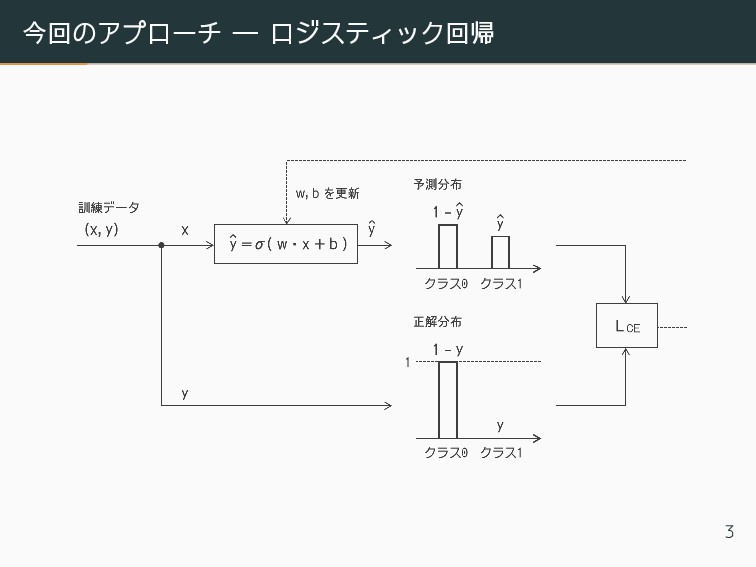
今回のアプローチ ― ロジスティック回帰 今回は先ほどの問題を以下のように解く1。 • 適当な重みベクトル w = (w1, ·
· · , wn)⊤ と適当なバイアス b を用いて以下の z を計算する。 z = w · x + b • z にシグモイド関数 σ(·) を適用して 0 と 1 の間の値にし、 これを y = P(y = 1|x) の予測値とする。 ˆ y = σ(z) = 1/(1 + e−z) • 各訓練データに対してクラスの予測分布を計算し正解分布 との交差エントロピー を計算する。 LCE(ˆ y(i), y(i)) = −y(i) log ˆ y(i) − (1 − y(i)) log(1 − ˆ y(i)) • 訓練データにおける LCE(ˆ y(i), y(i); w, b) の平均値を最小に する ˆ w,ˆ b を確率的勾配降下法 により探索する。 1特徴空間で 2 クラスをうまく仕切る超平面 w · x + b = 0 を探すのに似てい る。但し交差エントロピーが最小になる w, b を選ぶ。 2
今回のアプローチ ― ロジスティック回帰 3
クラス分類器におけるロジスティック回帰の位置付け ナイーブベイズは生成的、ロジスティック回帰は識別的である。 生成的モデル 各クラスがどのような特徴をもつかを学習しよ うとする。 ˆ c = arg maxc
P(d|c)P(c) 識別的モデル クラスどうしを識別する特徴を直接学習しよう とする。 ˆ c = arg maxc P(c|d) テキストの犬と猫の画像の分類器の例でいうと、 • 生成的モデルは、犬がどんな見た目か、猫がどんな見た目かを 学習する。 「犬の画像を描いてみて」といわれたら描ける2。 • 識別的モデルは、犬と猫を識別する特徴を学習する。 「犬の画像 を描いてみて」といわれても描けない3。 2犬にみえるかどうかはさておき、犬らしさを与える特徴を知っている。 3犬も猫ももふもふしていて識別に役立たないので、犬がもふもふしている ことを知らないかもしれない。 4
クラス分類器学習システムの構成要素 一般にクラス分類器学習システムは以下の 4 つの構成要素からなる。 特徴表現 データ i を特徴ベクトル (x(i) 1
, x(i) 2 , · · · , x(i) n )⊤ で 表現する4。 予測クラス 生成関数 特徴ベクトルから予測クラス ˆ y を計算する。ロ ジスティック回帰ではシグモイド関数 やソフト マックス関数を用いる。 目的関数 この目的関数の値を最小化することを目指す。 ロジスティック回帰では交差エントロピー を用 いる。 最適化アル ゴリズム 目的関数の値が最小化になるように特徴表現と 予測クラス生成関数を最適化したいので、それ を実行するアルゴリズムも必要である。この章 では確率的勾配降下法 を導入する。 4ロジスティック回帰の場合は、特徴表現を予め用意しておくことになる。 5
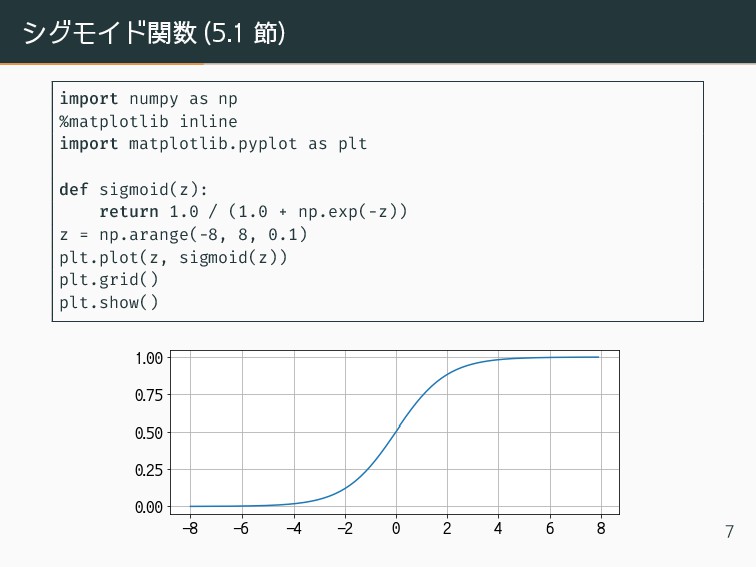
シグモイド関数 (5.1 節) 特徴の線形和を予測値にするのにシグモイド関数をつかう。 シグモイド関数 ˆ y = σ(z) =
1 1 + e−z • 定義域及び値域は (−∞, ∞) → (0, 1) である。 • 特徴の線形和 z = w · x + b に適用することでモデルの出力 が確率の要請を満たすようにできる。 • 予測クラスにするには 0.5 を閾値にする。 • 微分可能である。 dσ(z) dz = − −e−z (1 + e−z)2 = 1 1 + e−z e−z 1 + e−z = σ(z)(1 − σ(z)) • 0 < σ(z) < 1 なので σ(z) の 1 回微分は常に 0 以上 ( σ(z) は狭義 単調増加) であり、σ(z) = 0.5 で最大値 0.25 をとる。 6
シグモイド関数 (5.1 節) import numpy as np %matplotlib inline import
matplotlib.pyplot as plt def sigmoid(z): return 1.0 / (1.0 + np.exp(-z)) z = np.arange(-8, 8, 0.1) plt.plot(z, sigmoid(z)) plt.grid() plt.show() 7
例. 映画レビューのセンチメント分類器 5.1.1 節の映画レビューのセンチメント分類では以下の特徴を用いている。 特徴 意味 x1 ポジティブ単語リストのうち何単語が登場したか x2 ネガティブ単語リストのうち何単語が登場したか
x3 no が含まれていたら 1, そうでなければ 0 x4 1 人称もしくは 2 人称が何回登場したか x5 ! が含まれていたら 1, そうでなければ 0 x6 log( 文章中の単語数 ) import numpy as np def sigmoid(z): return 1.0 / (1.0 + np.exp(-z)) x = [3, 2, 1, 3, 0, np.log(66)] # Fig 5.2 の 文 章 の 特 徴 ベ ク ト ル w = [2.5, -5.0, -1.2, 0.5, 2.0, 0.7] # 学 習 済 み 重 み ベ ク ト ル b = 0.1 # 学 習 済 み バ イ ア ス z = np.dot(x, w) + b print(z, sigmoid(z)) 0.8327583194184977 0.6969378458778216 8
特徴の設計 例えば「そのピリオドは文末を意味するか否か」を学習したいなら、 以下のような特徴が役に立つかもしれない。 特徴 意味 x1 ピリオドが付いている単語が lower case か
(0 or 1) x2 ピリオドが付いている単語が略語リストに含まれるか (0 or 1) 例. Prof. x3 ピリオドが付いている単語が St. かつその前の単語が capital case か (0 or 1) 例. Takeshita St. · · · · · · 特徴を設計するには以下のような方法がある。 • 上の例のように手作業でつくる。 • 例えば訓練データ中のピリオドがつく単語までのバイグラムを すべて抜き出して特徴とする (feature templates)。 • 教師なしで自動的につくる (representation learning → 6, 7 章)。 9
分類モデルの選択 ナイーブベイズとロジスティック回帰どちらがいいのか。 • ナイーブベイズは条件付き独立の仮定 (4.7) が強すぎるので、 互いに相関する特徴が多いときはロジスティック回帰の方が予 測確率の精度がよい傾向がある。 • ポジティブなレビューによく登場する単語
a と単語 b が実はかな り同時に登場しているときポジティブな確率を高く見積もりすぎ る。ロジスティック回帰ならどちらの単語にも重みが分散される。 • とはいえ、ナイーブベイズはクラス判定は正しいことが多い5。 • データセットが小さいときや文章が短いときはナイーブベイズ の方が性能がよい傾向がある6。 • ナイーブベイズは最適化の反復ステップがなく学習が速い。 5テキストには詳細がない。 6テキストには詳細がないが、ロジスティック回帰では訓練データにたまた ま出てくる単語に割り当てた重みが未知データで悪さをすることがあるかも しれない。 10
交差エントロピー (5.3 節) 学習の目的関数を考える。いまあるデータ x に対する予測モデルの 予測が正しい確率は、x の正解ラベルが y =
1 であったら予測確率 ˆ y そのものだし、y = 0 だったら 1 − ˆ y なので、以下のようにかける。 p(y|x) = { ˆ y (y = 1) 1 − ˆ y (y = 0) これは p(y|x) = ˆ yy(1 − ˆ y)1−y とまとめられる。また、予測が正しい 確率を最大化したいなら、log をとっても差し支えない。 log p(y|x) = log [ ˆ yy(1 − ˆ y)1−y ] = y log ˆ y + (1 − y) log(1 − ˆ y) これにマイナスをかけて損失にしたものを交差エントロピーとよぶ。 交差エントロピー LCE(ˆ y(i), y(i)) = −y(i) log ˆ y(i) − (1 − y(i)) log(1 − ˆ y(i)) 11
確率的勾配降下法 (5.4 節) モデルを最適化したい。最適化対象のパラメータをまとめて θ とか く。M 個の訓練データに対する交差エントロピーの平均を最小化す るようなパラメータ ˆ
θ は以下のようにかける (ここで、データとパラ メータであることに着目したいため、LCE の引数を変更している)。 ˆ θ = arg min θ 1 M M ∑ i=1 LCE (y(i), x(i); θ) この ˆ θ を見つける方法として、(1/M) ∑ M i=1 LCE (y(i), x(i); θ) の θ に 関する勾配7(現時点の θ における勾配) の逆方向 (損失を小さくした いから) に θ を少しずつ更新していくことが考えられる8。 θt+1 = θt − η∇θ 1 M M ∑ i=1 LCE (y(i), x(i); θ) 7f : Rn → R のヤコビ行列 ( ∂f/(∂x1 ) ∂f/(∂x2 ) · · · ∂f/(∂xn ) ) の転置の縦 ベクトル。f(x) を最も大きくする方向。∇f(x) とかく。 8η を 学習率 という。 12
確率的勾配降下法 (5.4 節) 便利なことに、ロジスティック回帰の損失は θ に関して凸なの で、どんな θ から出発しても少しずつ進めば ˆ
θ にたどり着く。 23 頁で示す。 13
確率的勾配降下法 (5.4 節) 確率的勾配降下法 (データ 1 つずつ版) 1. θ を適当に初期化する。
2. 訓練データをランダムにシャッフルする。各訓練デー タに対し以下を実行する。 2.1 予測分布と正解分布の交差エントロピーの θ に関する 勾配 g を求める。 2.2 θ を勾配の逆向きに η だけ動かす。 θ ← θ − ηg 3. 収束の条件が満たされていたら θ を出力して終わる。 4. 収束の条件が満たされていなかったら 2. に戻る。 収束の条件としては、θ の更新幅 (勾配 g の大きさ) が閾値 ε より小さくなっ た、評価用データ上で損失が減少しなくなったなどが考えられる。 14
確率的勾配降下法 (5.4 節) しかし、データ 1 つずつの勾配に対し更新すると θ があっちにいっ たりこっちにいったりしやすい。といって、すべての訓練データの 損失の平均に対する勾配を求めるのでは
1 回の更新に時間がかかる。 → 訓練データを m 個ごとのミニバッチ に分けることが多い。 確率的勾配降下法 (ミニバッチ版) 1. θ を適当に初期化する。 2. 訓練データをミニバッチに分けて、ミニバッチをランダムに シャッフルし以下を実行する。 2.1 予測分布と正解分布の交差エントロピーのミニバッチ 上の平均の θ に関する勾配 g を求める。 2.2 交差エントロピーの平均の θ に関する勾配 g を求める。 2.3 θ を勾配の逆向きに η だけ動かす。 θ ← θ − ηg 3. 収束の条件が満たされていたら θ を出力して終わる。 4. 収束の条件が満たされていなかったら 2. に戻る。 15
正則化 (5.5 節) 分類器の学習では、訓練データに適合しすぎることがある。 • 例.訓練データである特徴が片側のクラスにしか現れなかったが、実は たまたまであり、この特徴を用いると未知データへの性能は悪くなる。 このような過学習 を防ぐため、目的関数に正則化項 R(θ)
を付 加し、パラメータの大きさを抑制することがある。 ˆ θ = arg max θ [ M ∑ i=1 log P(y(i)|x(i)) − αR(θ) ] • L2 正則化: R(θ) = ∑ n j=1 θ2 j とし、パラメータ空間におい て原点からのユークリッド距離が小さいパラメータを選ば れやすくする。リッジ回帰とも。 • L1 正則化: R(θ) = ∑ n j=1 |θj| とし、パラメータ空間にお いて原点からのマンハッタン距離が小さいパラメータ (疎 なパラメータ) を選ばれやすくする。ラッソ回帰とも。 16
正則化 (5.5 節) L1 正則化と L2 正則化はベイズ事後分布からの MAP 推定とも解釈 できる。
ˆ θ = arg max θ [ M ∑ i=1 log P(y(i)|x(i)) − αR(θ) ] ⇒ ˆ θ = arg max θ [ exp { M ∑ i=1 log P(y(i)|x(i)) − αR(θ) }] ⇒ ˆ θ = arg max θ [ M ∏ i=1 P(y(i)|x(i)) exp { −αR(θ) } ] L2 正則化 R(θ) = ∑ n j=1 θ2 j だとこう (事前分布が N(0, √ n/2αI))。 ˆ θ = arg max θ M ∏ i=1 P(y(i)|x(i)) n ∏ j=1 exp { − α n θ2 j } L1 正則化 R(θ) = ∑ n j=1 |θj | だとこう (事前分布がラプラス分布)。 ˆ θ = arg max θ M ∏ i=1 P(y(i)|x(i)) n ∏ j=1 exp { − α n |θj | } 17
多クラス分類の場合 (5.6 節) 3 クラス以上に分類したいこともある。 • 例.ネガティブ、ポジティブ、ニュートラル。 • 例.単語の品詞分類。 •
例.semantic labels (18 章)。 その場合は以下のようにすればよい。 • パラメータ wk, bk はクラスの数 K だけ用意する。 • zk = wk · x + bk (k = 1, · · · K) を計算する。 • (z1, · · · , zK) にソフトマックス関数を適用して各クラスの 予測確率にする。 softmax(z1, · · · , zK) = ( ez1 ∑ K k=1 ezk , · · · , ezK ∑ K k=1 ezk ) 18
多クラス分類の場合 (5.6 節) 多クラス分類の目的関数を考える。データ i に対する予測が正しい 確率は以下のようにまとめてかける。ただし、1{y(i) = k} は
y(i) = k ならば 1、y(i) ̸= k ならば 0 をとる指示関数である。 ( ez(i) 1 ∑ K k=1 ez(i) k )1{y(i)=1} · ( ez(i) 2 ∑ K k=1 ez(i) k )1{y(i)=2} · · · ( ez(i) K ∑ K k=1 ez(i) k )1{y(i)=K} これの対数の −1 倍をとって、以下を最小化すればよい9。 L(i)(w1:K , b1:K ) = − K ∑ k=1 1{y = k} log ( ez(i) k ∑ K k′=1 ez(i) k′ ) これの勾配は 25 頁に記す。 9L(i)(w1 , · · · , wK , b1 , · · · , bK ) を L(i)(w1:K , b1:K ) と表記することにする。 19
モデルの解釈 (5.7 節) • モデルがなぜそのような判断をしたのか知りたいことはしばし ばある。それがわかるようなモデルは解釈性があるという。 • ロジスティック回帰に用いる特徴は人間が選択することが多い ので、どんな特徴がクラス予測に効いたかを確認することでモ デルの判断理由を解釈できる。クラスを説明するのに有意な特
徴であったか統計的検定をしたり、重みパラメータの信頼区間 を求めたりすることもできる。 • モデルの判断根拠を分析するだけでなく、ある特徴の効果を分 析することもできる。 • ある言葉 a の効果がネガティブなのかポジティブなのかを 調べたい。単にネガティブなレビューへの登場頻度とポジ ティブなレビューへの登場頻度を調べたのでは、言葉 a が ポジティブなレビューにも現れやすかったとしても、実は ポジティブなレビューにはいつも言葉 b が一緒に現れてい るかもしれない。言葉 a 単体の効果はネガティブな可能性 がある。ので、ロジスティック回帰の重みをみた方がよい。 20
勾配の導出 (5.8 節) ― 2 クラス分類の場合 目的関数の勾配を導出する。まずデータ i の損失の wj
に関する微分 (以下) を計算してみる。z(i) ≡ w · x(i) + b である。 ∂L(i)(w, b) ∂wj ≡ ∂ ∂wj [ −y(i) log σ(z(i)) − (1 − y(i)) log(1 − σ(z(i))) ] シグモイド関数の微分は dσ(z) dz = σ(z) ( 1 − σ(z) ) であったので、 ∂L(i)(w, b) ∂wj = ∂L(i)(w, b) ∂σ(z(i)) ∂σ(z(i)) ∂z(i) ∂z(i) ∂wj = ( − y(i) σ(z(i)) + 1 − y(i) 1 − σ(z(i)) ) σ(z(i)) ( 1 − σ(z(i)) ) x(i) j = {−y(i) ( 1 − σ(z(i)) ) + (1 − y(i))σ(z(i))}x(i) j = − ( y(i) − σ(z(i)) ) x(i) j 同様に、b に関する微分は以下。 ∂L(i)(w, b) ∂b = ∂L(i)(w, b) ∂σ(z(i)) ∂σ(z(i)) ∂z(i) ∂z(i) ∂b = − ( y(i) − σ(z(i)) ) 21
勾配の導出 (5.8 節) ― 2 クラス分類の場合 よって、データ i の損失の w,
b に関する勾配は以下である。 y(i) − σ(z(i)) は正解ラベルと現在の予測の誤差になっている。 この勾配の逆向きに更新するので、(特徴量の符号が正ならば) 誤差 と同じ向きに、誤差が大きいほど大きく更新することがわかる。 ∇w,b L(i)(w, b) = ∂L(i)(w,b) ∂w1 . . . ∂L(i)(w,b) ∂wn ∂L(i)(w,b) ∂b = − ( y(i) − σ(z(i)) ) x(i) 1 . . . x(i) n 1 ミニバッチ (データ数 m) 内のデータの損失の平均の勾配にするには 以下のようにすればよい。 ∇w,b Lbatch (w, b) = ∂Lbatch(w,b) ∂w1 . . . ∂Lbatch(w,b) ∂wn ∂Lbatch(w,b) ∂b = − 1 m m ∑ i=1 ( y(i)−σ(z(i)) ) x(i) 1 . . . x(i) n 1 22
損失の凸性 前々頁より、目的関数のパラメータに関する 1 回微分は以下だったので、 ∂L(i)(w, b) ∂wj = − (
y(i) − σ(z(i)) ) x(i) j 2 回微分は以下となることがわかる。 ∂2L(i)(w, b) ∂wj ∂wk = σ(z(i)) ( 1 − σ(z(i)) ) x(i) j x(i) k よって、ヘッセ行列は以下のようになる。 ∇2 w,b L(i)(w, b) = σ(z(i)) ( 1 − σ(z(i)) ) x(i) 1 x(i) 1 x(i) 1 x(i) 2 · · · x(i) 1 x(i) n x(i) 1 x(i) 2 x(i) 1 x(i) 2 x(i) 2 · · · x(i) 2 x(i) n x(i) 2 . . . . . . ... . . . . . . x(i) n x(i) 1 x(i) n x(i) 2 · · · x(i) n x(i) n x(i) n x(i) 1 x(i) 2 · · · x(i) n 1 = σ(z(i)) ( 1 − σ(z(i)) ) x(i) 1 . . . x(i) n 1 ( x(i) 1 · · · x(i) n 1 ) 23
損失の凸性 ˜ x(i) ≡ (x(i) 1 , x(i) 2 ,
· · · , x(i) n , 1) と定義すると、任意の z ∈ Rn+1 に対して、 z⊤∇2 w,b L(i)(w, b)z = σ(z(i)) ( 1 − σ(z(i)) ) z⊤ ˜ x(i) ˜ x(i)⊤z = σ(z(i)) ( 1 − σ(z(i)) )( z⊤ ˜ x(i) ) 2 ≧ 0 が成り立つので、∇2 w,b L(i)(w, b) は半正定値である。 よって、L(i)(w, b) は凸である。 24
勾配の導出 ― 多クラス分類の場合 多クラス分類の場合も導出する。ただし、重みベクトル wk (k = 1, · ·
· , K) の j 番目の成分を wk,j と表記することにする。 ∂L(i)(w1:K , b1:K ) ∂wk,j ≡ ∂ ∂wk,j − K ∑ k′=1 1{y(i) = k′} log ez(i) k′ ∑ K k′′=1 ez(i) k′′ ここで、s(z(i) k′ ) = ez(i) k′ ∑ K k′′=1 ez(i) k′′ とおくと以下が成り立つ。 ∂L(i)(w1:K , b1:K ) ∂s(z(i) k′ ) = − 1{y(i) = k′} s(z(i) k′ ) ∂s(z(i) k′ ) ∂z(i) k = ezk′ ( ∑ K k′′=1 ezk′′ ) − ezk′ ezk′ ( ∑ K k′′=1 ezk′′ )2 = s(z(i) k ) − s(z(i) k )2 (k′ = k) −ezk′ ezk ( ∑ K k′′=1 ezk′′ )2 = −s(z(i) k )s(z(i) k′ ) (k′ ̸= k) 25
勾配の導出 ― 多クラス分類の場合 前頁の結果を利用すると、多クラス分類の場合の勾配は以下のようになる。 ∂L(i)(w1:K , b1:K ) ∂wk,j =
K ∑ k′=1 ∂L(i)(w1:K , b1:K ) ∂s(z(i) k′ ) ∂s(z(i) k′ ) ∂z(i) k ∂z(i) k ∂wk,j = − 1{y(i) = k} s(z(i) k ) ( s(z(i) k ) − s(z(i) k )2 ) x(i) j + ∑ k′̸=k 1{y(i) = k′} s(z(i) k′ ) s(z(i) k )s(z(i) k′ )x(i) j = −1{y(i) = k} ( 1 − s(z(i) k ) ) x(i) j + ∑ k′̸=k 1{y(i) = k′}s(z(i) k )x(i) j = −1{y(i) = k}x(i) j + ∑ k′ 1{y(i) = k′}s(z(i) k )x(i) j = − ( 1{y(i) = k} − s(z(i) k ) ) x(i) j 1{y(i) = k} − s(z(i) k ) は正解の確率と現在の予測確率の誤差になっている。 26
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}